内核解读之内存管理内存模型
Posted 奇妙之二进制
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了内核解读之内存管理内存模型相关的知识,希望对你有一定的参考价值。
文章目录
1、基本术语
在介绍内存模型之前需要了解一些基本的知识。
1、什么是page frame?
在linux操作系统中,物理内存被分成一页页的page frame来管理,具体page frame size是多少是和硬件以及linux系统配置相关的,4k是最经典的设定,也就是一个page frame表示4K的物理内存。我们针对每一个物理的page frame建立一个struct page的数据结构来跟踪每一个物理页面的使用情况:是用于内核的正文段?还是用于进程的页表?是用于各种file cache还是处于free状态……
2、什么是PFN?
对于一个计算机系统,其整个物理地址空间应该是从0开始,到实际系统能支持的最大物理空间为止的一段地址空间。在ARM系统中,假设物理地址是32个bit,那么其物理地址空间就是4G,在ARM64系统中,如果支持的物理地址bit数目是48个,那么其物理地址空间就是256T。当然,实际上这么大的物理地址空间并不是都用于内存,有些也属于I/O空间(当然,有些cpu arch有自己独立的io address space)。因此,内存所占据的物理地址空间应该是一个有限的区间,不可能覆盖整个物理地址空间。
PFN是page frame number的缩写,所谓page frame,是针对物理内存而言的,把物理内存分成一个个的page size的区域,并且给每一个page 编号,这个号码就是PFN。假设物理内存从0地址开始,那么PFN等于0的那个页帧就是0地址(物理地址)开始的那个page。假设物理内存从x地址开始,那么第一个页帧号码就是(x>>PAGE_SHIFT)。
PAGE_SHIFT表示以2的幂为单位页的大小(例如对于4K大小的页,PAGE_SHIFT等于12)。
Linux内核支持的两种内存模型:
CONFIG_FLATMEM(平坦内存模型)
CONFIG_SPARSEMEM_VMEMMAP(稀疏的内存模型)
2、FLATMEM(平坦内存模型)
如果物理内存空间是一个连续的,没有空洞的地址空间,那么这种计算机系统的内存模型就是Flat memory,如图所示,我们将内存分成一页一页的Page frame,描述page frame的结构体page组成一个数组mem_map,通过将地址转换成页帧号(即该地址对应的page在page数组中的索引)可以取得该地址对应的page,就可以访问任何一页物理内存。
在flat memory的情况下,PFN(page frame number)和mem_map数组index的关系是线性的(有一个固定偏移,如果内存的起始物理地址等于0,那么PFN就是数组index)。
UMA+flat memory的情况:
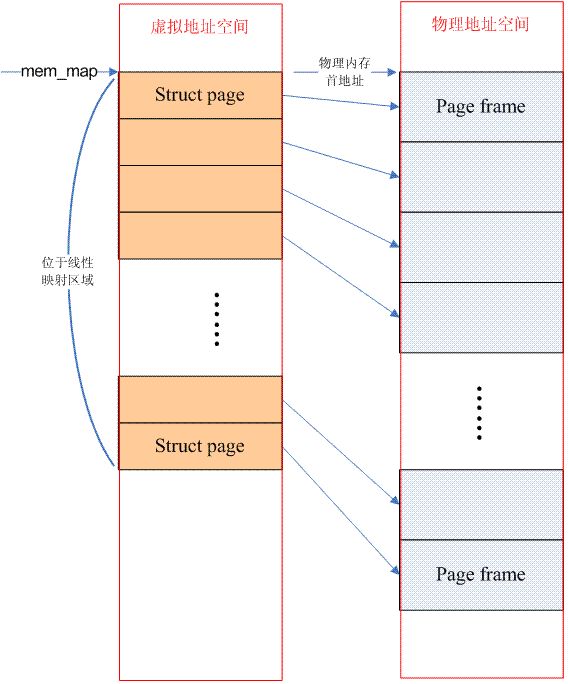
NUMA+flat memory的情况:
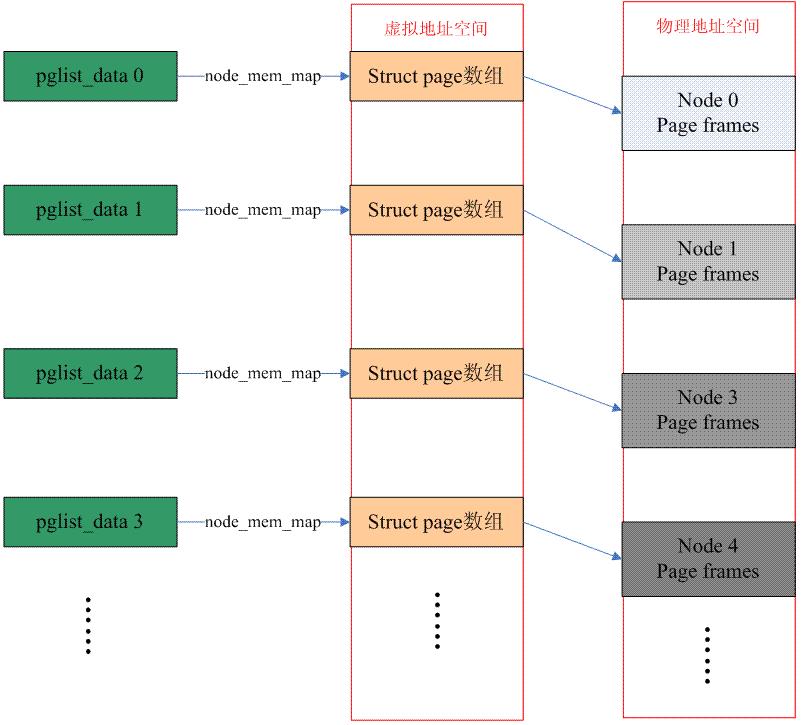
需要强调的是struct page所占用的内存位于直接映射(directly mapped)区间,因此操作系统不需要再为其建立page table。
一个node的内存空间可能是不连续的,即由多段内存组成,单个node的page frames可能是这样的:

平铺式内存组织page的缺点就是,当存在内存空洞时,仍要给page分配内存空间,造成浪费。进一步看,每个page结构体需要占用64字节空间,假设内核配置的页大小为4k,则在没有空洞情况下该结构就需要占用约1.56%(64/4096)的总内存。若内存地址之间的空洞很大,则其浪费的内存将会非常惊人。
同时对于numa系统,cpu访问不同节点内存的速度不同,将page结构体分配到某一个特定节点,则不与该节点绑定的cpu访问这些数据的效率显然也会有问题。
因此作为内核对上述问题的解决方案,稀疏内存模型开始闪亮登场。
3、SPARSEMEM稀疏内存模型
不连续的物理内存肯定是由一块块连续的物理内存组成的,一块连续的物理内存由struct mem_section表示。
如果没有启动64K页大小,一个section size的大小一般是128MB,启用了64K页,一个section的大小是512MB。按照128MB来算,一个section有1024 * 32个页。
arch/arm64/include/asm/sparsemem.h:
/* SPDX-License-Identifier: GPL-2.0-only */
/*
* Copyright (C) 2012 ARM Ltd.
*/
#ifndef __ASM_SPARSEMEM_H
#define __ASM_SPARSEMEM_H
#define MAX_PHYSMEM_BITS CONFIG_ARM64_PA_BITS
/*
* Section size must be at least 512MB for 64K base
* page size config. Otherwise it will be less than
* (MAX_ORDER - 1) and the build process will fail.
*/
#ifdef CONFIG_ARM64_64K_PAGES
#define SECTION_SIZE_BITS 29
#else
/*
* Section size must be at least 128MB for 4K base
* page size config. Otherwise PMD based huge page
* entries could not be created for vmemmap mappings.
* 16K follows 4K for simplicity.
*/
#define SECTION_SIZE_BITS 27
#endif /* CONFIG_ARM64_64K_PAGES */
#endif
下图画了128MB的section示意图:

这样如果某个section的地址都位于空洞中,我们就不需要为其分配page结构体,而且不同section对应的page结构体内存也不必是连续的。此时它们之间的组织关系可变为下图所示的形式:

看起来前面的两个问题都被完美地解决了:
(1)由于不再为空洞建立page结构体,内存浪费处于可控状态。
(2)每个section的page结构体内存可独立分配,这样就可以方便地将其放到最优的numa节点中,内存访问速度的问题也得到解决
极致稀疏内存模式page的mem_section和page的映射关系:
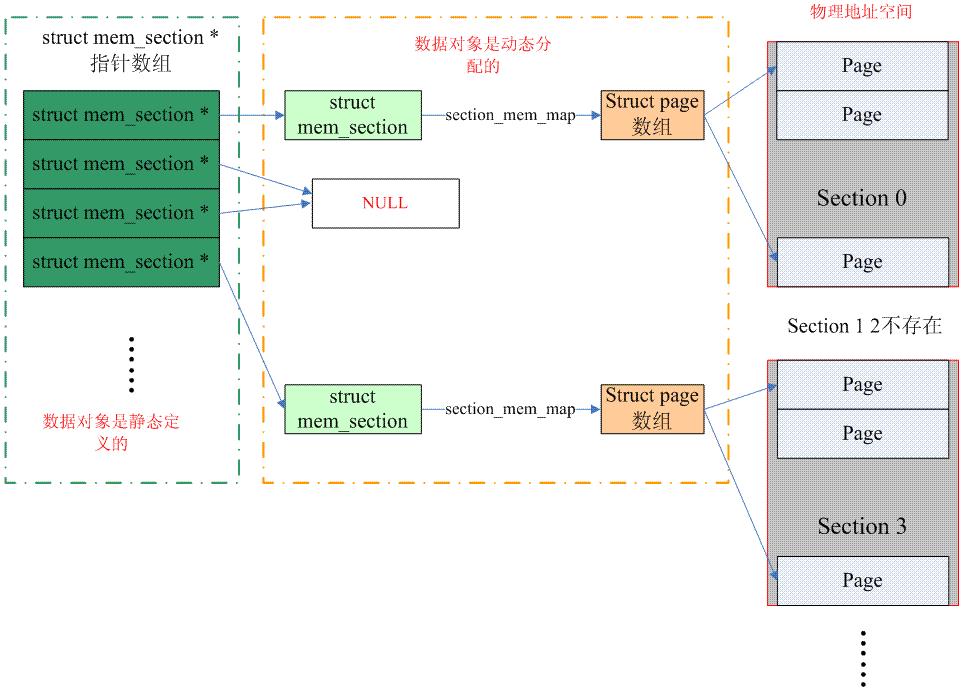
整个连续的物理地址空间是按照一个section一个section来切断的,每一个section内部,其memory是连续的(即符合flat memory的特点),因此,mem_map的page数组依附于section结构(struct mem_section)而不是node结构了(struct pglist_data)。当然,无论哪一种memory model,都需要处理PFN和page之间的对应关系,只不过sparse memory多了一个root和section的概念,
让转换变成了PFN<—>root + section + pfn + in_page_offset<—>page。
sparse内存模型从pfn到page分成了root、section、pfn、页内偏移4级映射。
如果不是极致稀疏内存模式,root = section,下图的蓝色和红色合并。
这个图画的非常精妙(不过有一点小纰漏),这个图画的是极致稀疏内存模式:
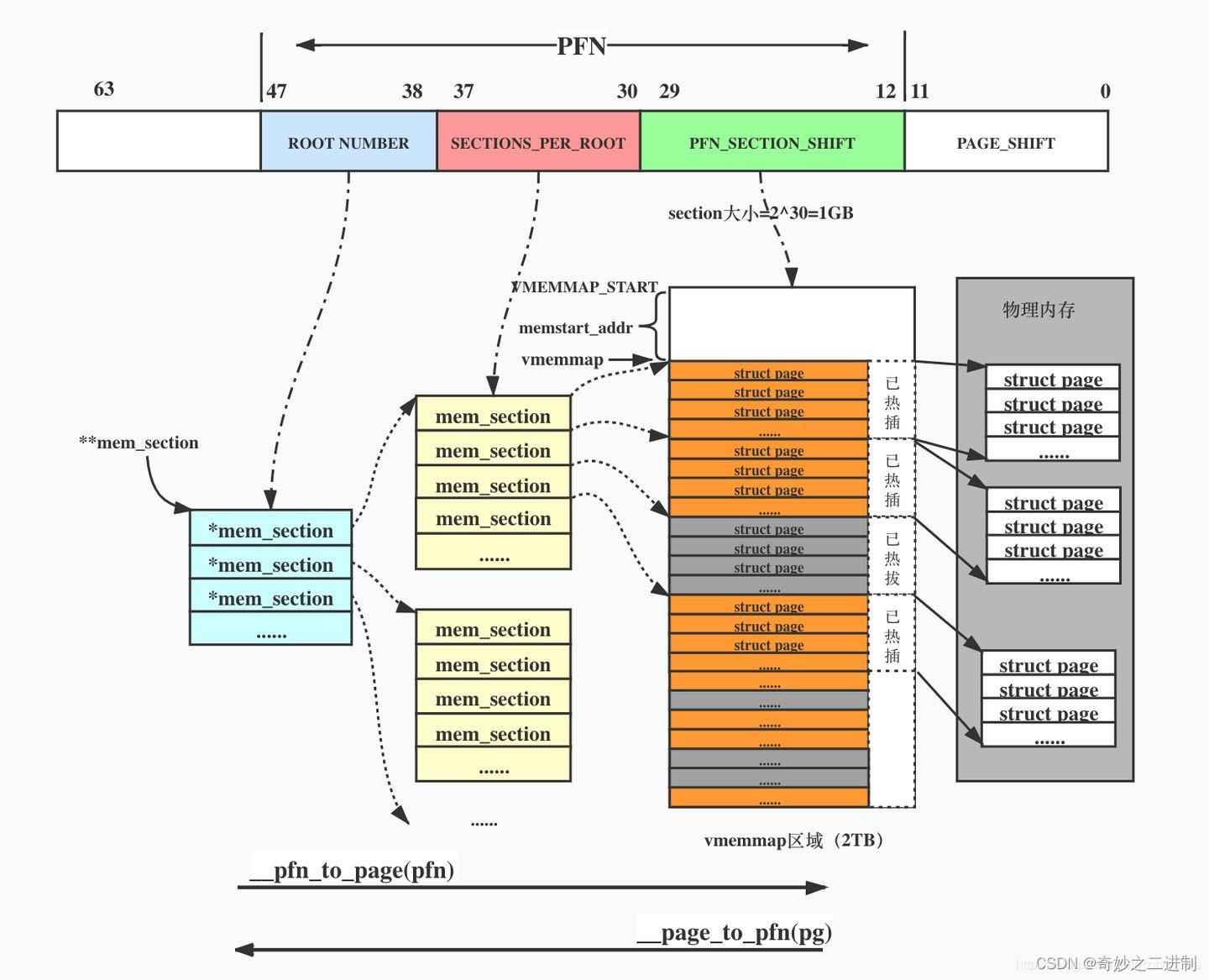
顶层是root,一个root包含SECTIONS_PER_ROOT个sections。
如果不是极致sparse内存模式,所有的mem_section由一个二维数组管理,大小是NR_SECTION_ROOTS * SECTIONS_PER_ROOT,一个root只放一个mem_section,即SECTIONS_PER_ROOT=1,即所有mem_section放在了一个连续的空间。
如果是极致sparse内存模式,用一个page的大小来存放一个root的所有mem_section,也就是一个root有SECTIONS_PER_ROOT个section。
#define SECTIONS_PER_ROOT (PAGE_SIZE / sizeof (struct mem_section))
一个root的sections是连续存放的,即放在一个page内,但root并不需要连续存放,mem_section是个指针数组。
#ifdef CONFIG_SPARSEMEM_EXTREME
extern struct mem_section **mem_section;
#else
extern struct mem_section mem_section[NR_SECTION_ROOTS][SECTIONS_PER_ROOT];
#endif
我们来算下SECTIONS_PER_ROOT是多大。mem_section包含了两个指针,大小是16字节:
struct mem_section
/*
* This is, logically, a pointer to an array of struct
* pages. However, it is stored with some other magic.
* (see sparse.c::sparse_init_one_section())
*
* Additionally during early boot we encode node id of
* the location of the section here to guide allocation.
* (see sparse.c::memory_present())
*
* Making it a UL at least makes someone do a cast
* before using it wrong.
*/
unsigned long section_mem_map;
struct mem_section_usage *usage;
#ifdef CONFIG_PAGE_EXTENSION
/*
* If SPARSEMEM, pgdat doesn't have page_ext pointer. We use
* section. (see page_ext.h about this.)
*/
struct page_ext *page_ext;
unsigned long pad;
#endif
/*
* WARNING: mem_section must be a power-of-2 in size for the
* calculation and use of SECTION_ROOT_MASK to make sense.
*/
;
一个page按照4k(2的12次方)计算,SECTIONS_PER_ROOT需要 12 - 4 = 8 位来表示,所以上面画的图是对的。另外,上图有个小纰漏,section的位数应该是27,因为画的是4K的页大小,如果是29,页大小是64K。
SECTIONS_SHIFT表示为了描述MAX_PHYSMEM_BITS位的物理内存,需要SECTIONS_SHIFT位来描述SECTIONS。
换言之,如果一个物理地址的高SECTIONS_SHIFT位用来
#ifdef CONFIG_SPARSEMEM
#include <asm/sparsemem.h>
#define SECTIONS_SHIFT (MAX_PHYSMEM_BITS - SECTION_SIZE_BITS)
#else
#define SECTIONS_SHIFT 0
#endif
NR_MEM_SECTIONS表示为了描述MAX_PHYSMEM_BITS位的物理内存所需的section个数。
#define NR_MEM_SECTIONS (1UL << SECTIONS_SHIFT)
以上是关于内核解读之内存管理内存模型的主要内容,如果未能解决你的问题,请参考以下文章