谷歌让AI芯片学会“下崽”,下一代TPU就让AI自己设计
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了谷歌让AI芯片学会“下崽”,下一代TPU就让AI自己设计相关的知识,希望对你有一定的参考价值。
月石一 发自 凹非寺
量子位 报道 | 公众号 QbitAI
设计一块AI芯片有多难?
这么说吧,围棋的复杂度10360,而芯片则是102500,你感受一下……

△围棋的复杂度
一般来说,工程师们设计一块芯片,少则需要几周,多则好几个月。
现在,AI生产力来了!
AI自己动手,竟然用6小时就设计出一块芯片。
最近,这项谷歌的研究登上了Nature杂志。

布局时间缩短数倍
小小的一块芯片包括了数十亿个晶体管,由它们组成的数千万个逻辑门就是标准单元,此外还有数千个存储块,称为宏块。
确定它们的位置,也就是布局规划,对芯片设计至关重要。
因为这直接关系到如何布线,进而影响着芯片的处理速度和电源效率。
但是,光是放置宏块这一步就非常耗时,为了给标准单元留出更多空间,每一次迭代都需要几天或几周时间。
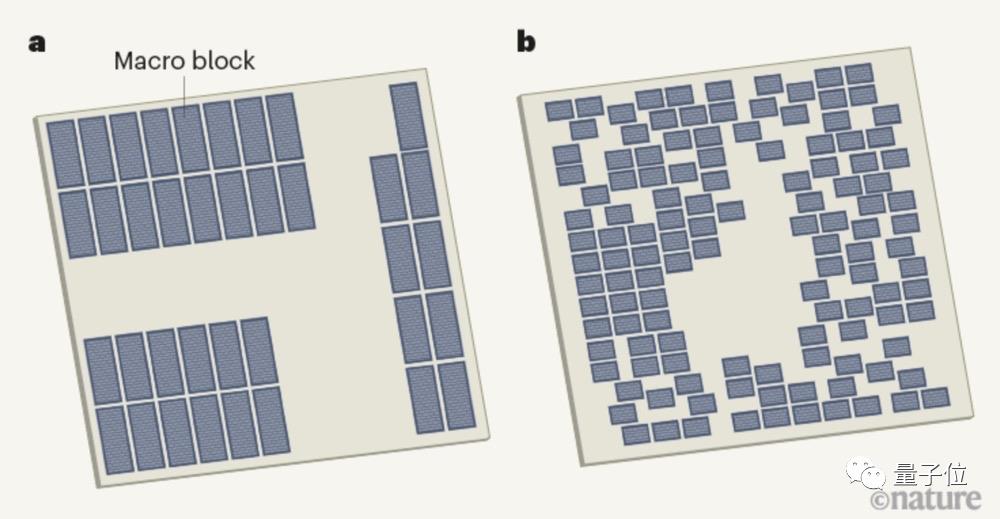
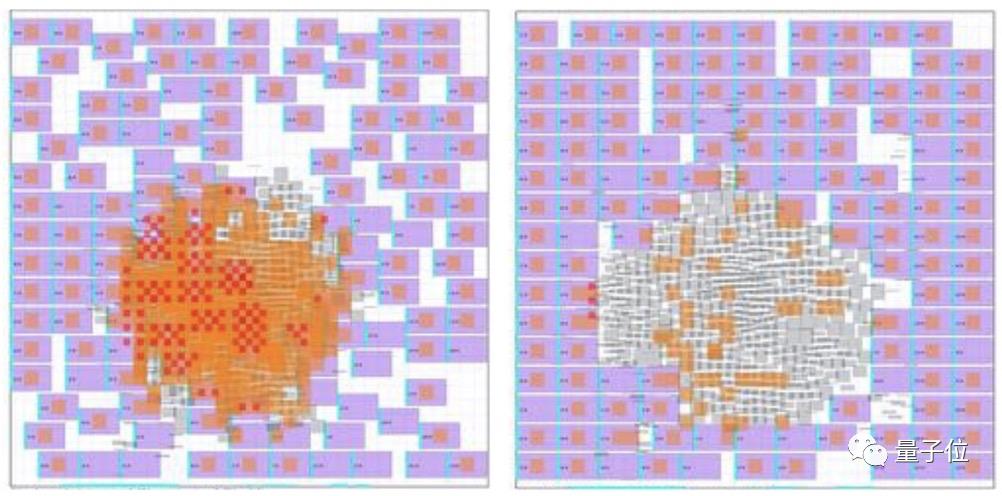
△人类设计和AI设计芯片的平面图(灰色块为宏块)
完成整个布局,则要花费数周甚至数月。
现在,谷歌的研究人员提出了一种具有泛化能力的芯片布局方法。
它能够基于深度强化学习,从之前的布局中进行学习,然后生成新的设计方案。整体架构是这样的:
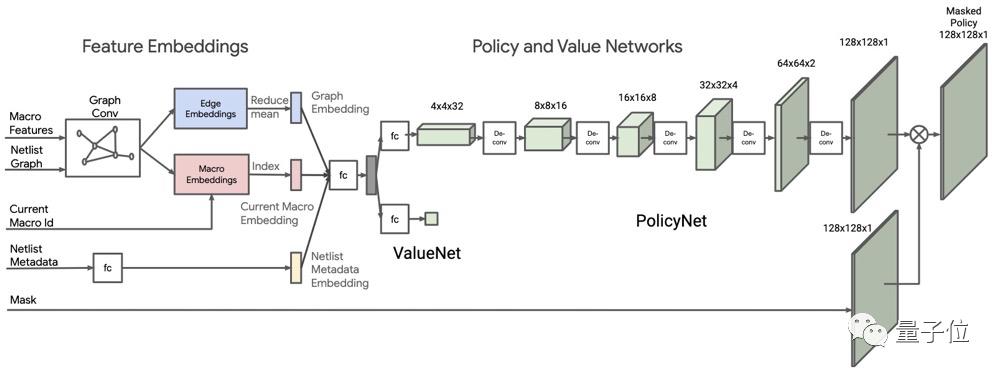
由于AI模型需要学习10万个芯片布局,为了保证速度,研究人员设计了一种奖励机制,基于线路长度和布线拥塞的近似代价函数进行计算。

具体来说,需要将宏和标准单元映射到一个平面画布上,形成具有数百万到数十亿节点的「芯片网表」。
然后,AI模型会对功率、性能和面积(PPA) 等进行优化,并且输出概率分布。
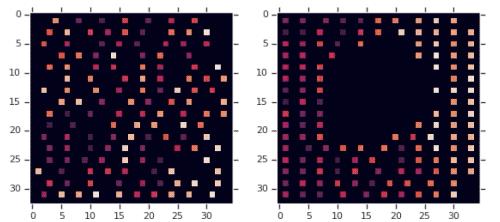
下图分别是零样本生成和基于预训练策略微调的效果,其中每个小矩形代表一个宏块。在预训练策略中,中间留出了用于放置标准单元的空间。
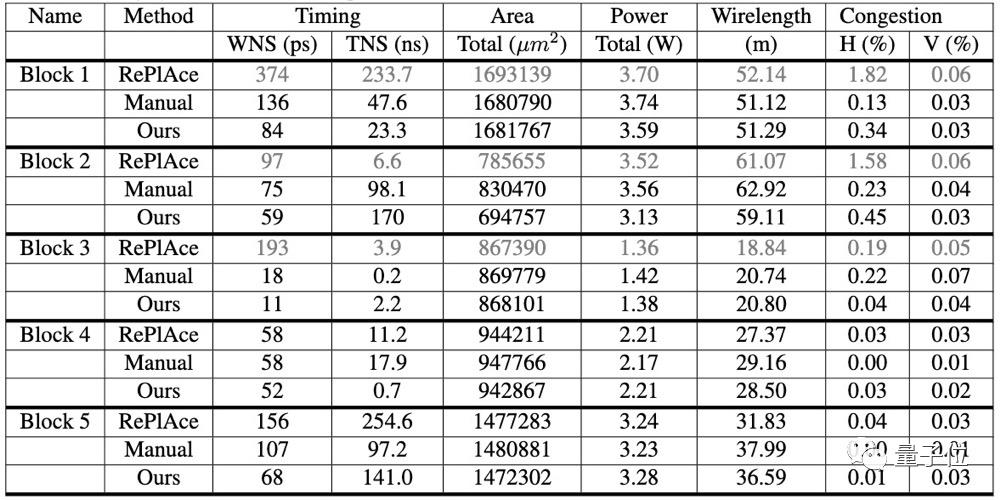
与其他方法相比,谷歌的新方法大大减少了设计时间,只需不到6小时,就能实现性能优化的布局。
谷歌:效果不错,已经用上了
研究团队对不同策略下的布局效果进行了可视化展示,从图中可以看到,预训练策略微调的结果要明显优于零样本生成。
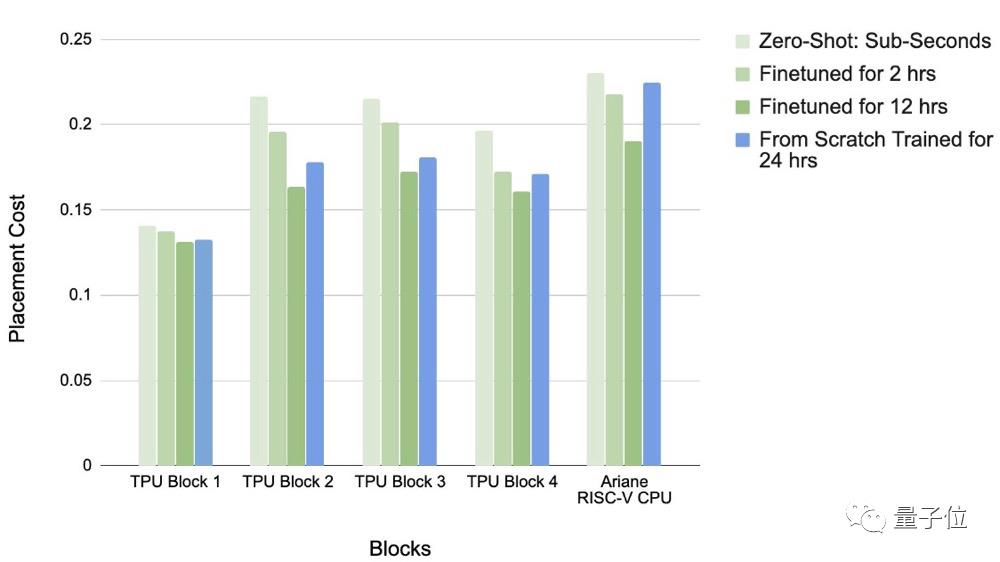
并且,从不同训练时长的效果对比可以看到,在训练2-12小时的情况下,预训练策略要优于零样本生成。
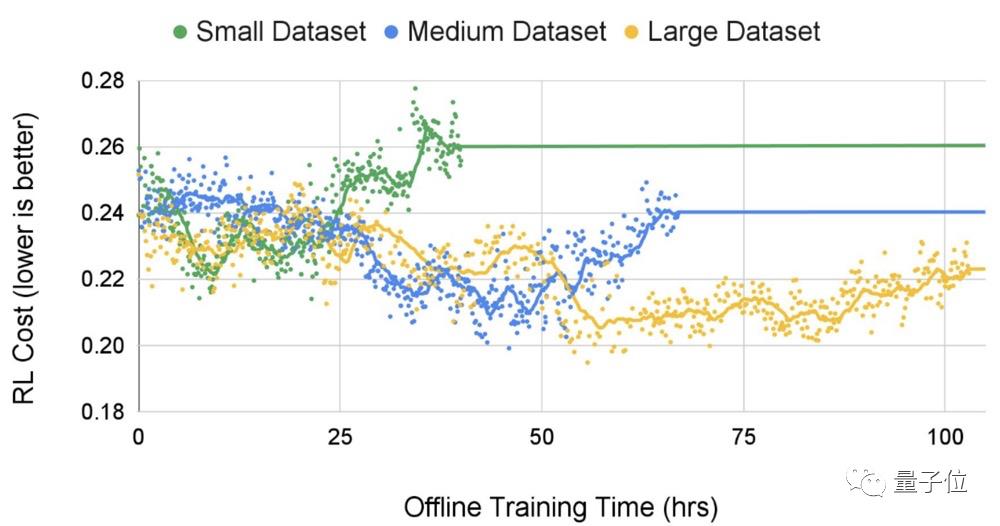
在不同规模的数据集上进行测试,研究人员发现,随着数据集规模的扩大,生成布局的质量和收敛时间的结果更优。

谷歌表示,
这一方法适用于任何类型的芯片。
目前已经被用于生产下一代Google TPU(加速器芯片)。
参考链接:
https://www.nature.com/articles/s41586-021-03544-w
https://www.nature.com/articles/d41586-021-01515-9
https://ai.googleblog.com/2020/04/chip-design-with-deep-reinforcement.html
https://arxiv.org/abs/2004.10746
以上是关于谷歌让AI芯片学会“下崽”,下一代TPU就让AI自己设计的主要内容,如果未能解决你的问题,请参考以下文章
机器学习与流体动力学:谷歌AI利用「ML+TPU」实现流体模拟数量级加速
深度学习硬件:TPU, DSP, FPGA, AI ASIC, Systolic Array 动手学深度学习v2
首个中文Stable Diffusion模型开源;TPU演进十年;18个PyTorch性能优化技巧 | AI系统前沿动态...
绑定TensorFlow,开放TPU,谷歌云想用AI优势换道超车AWS?