机器学习与流体动力学:谷歌AI利用「ML+TPU」实现流体模拟数量级加速
Posted 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习与流体动力学:谷歌AI利用「ML+TPU」实现流体模拟数量级加速相关的知识,希望对你有一定的参考价值。
谷歌
AI 最近一项研究表明,利用机器学习和硬件加速器能够改进流体模拟,且不损害准确率或泛化性能。
流体数值模拟对于建模多种物理现象而言非常重要,如天气、气候、空气动力学和等离子体物理学。流体可以用纳维 - 斯托克斯方程来描述,但大规模求解这类方程仍属难题,受限于解决最小时空特征的计算成本。这就带来了准确率和易处理性之间的权衡。
不可压缩流体通常由如上纳维 - 斯托克斯方程来建模。
最近,来自谷歌 AI 的研究人员利用端到端深度学习改进计算流体动力学(CFD)中的近似,以建模二维涡流。对于湍流的直接数值模拟(direct numerical simulation, DNS)和大涡模拟(large eddy simulation, LES),该方法获得的准确率与基线求解器相同,而后者在每个空间维度的分辨率是前者的 8-10 倍,因而该方法
实现了 40-80 倍的计算加速
。在较长模拟中,该方法仍能保持稳定,并泛化至训练所用流以外的力函数(forcing function)和雷诺数,这与黑箱机器学习方法正相反。此外,该方法还具备通用性,可用于任意非线性偏微分方程。

论文地址:https://arxiv.org/pdf/2102.01010.pdf
该研究作者之一、谷歌研究员 Stephan Hoyer 表示:这项研究表明,
机器学习 + TPU 可以使流体模拟加速多达两个数量级,且不损害准确率或泛化性能
。
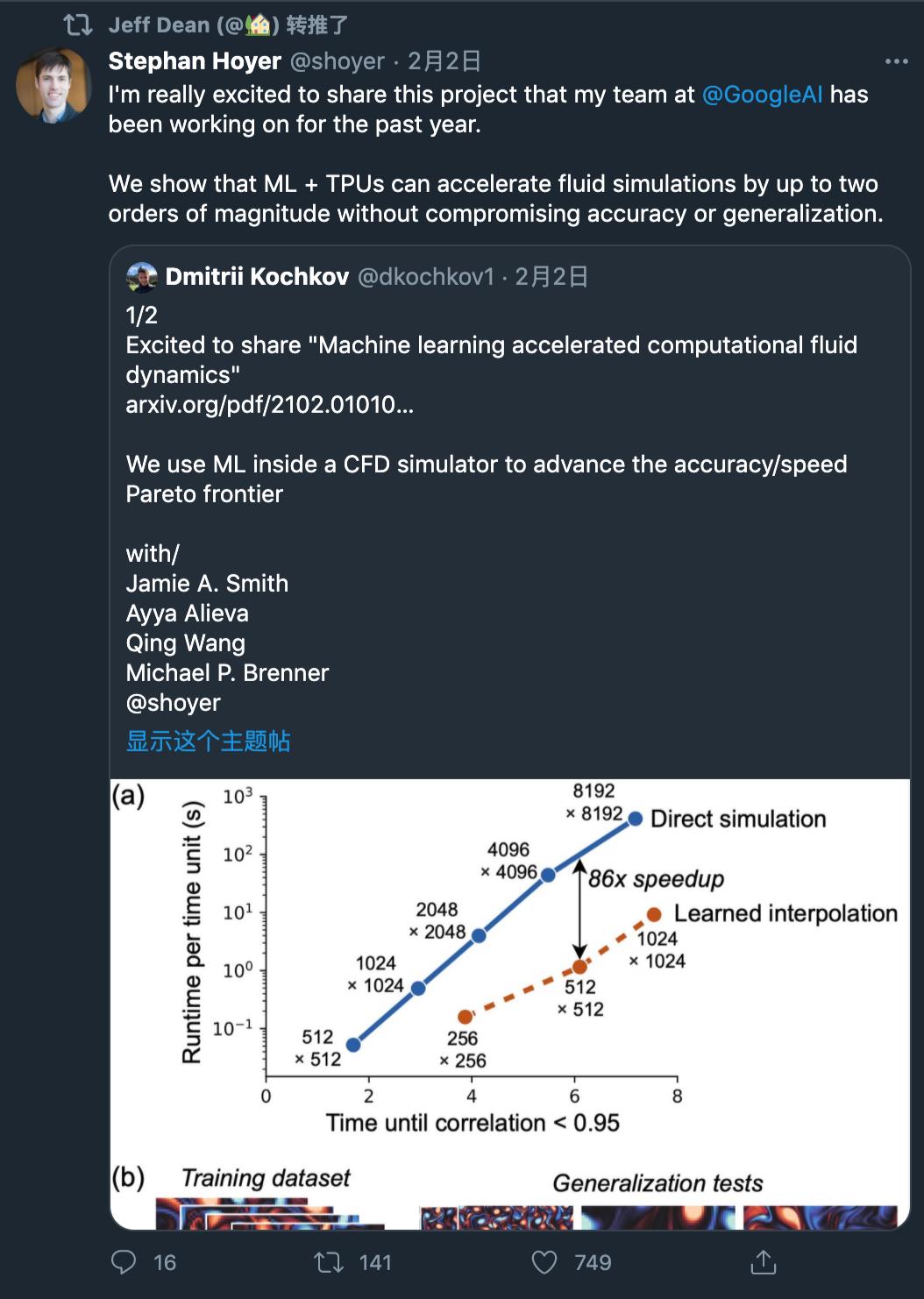
至于效果如何呢?论文共同一作 Dmitrii Kochkov 展示了
该研究提出的神经网络与 Ground truth、基线的效果对比
:
首先是雷诺数 Re=1000 时,在 Kolmogorov 流上的效果对比:
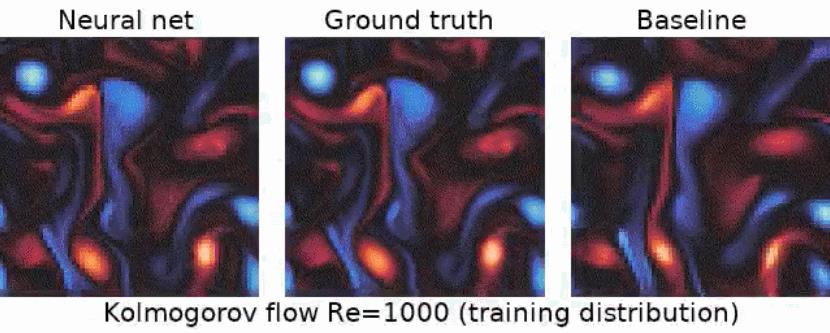
其次是关于衰变湍流(decaying turbulence)的效果对比:

最后是雷诺数 Re=4000 时,在更复杂流上的效果对比:

用非线性偏微分方程描述的复杂物理系统模拟对于工程与物理科学而言非常重要。然而,大规模求解这类方程并非易事。
谷歌 AI 这项研究提出一种方法来计算非线性偏微分方程解的准确时间演化,并且其使用的网格分辨率比传统方法实现同等准确率要粗糙一个数量级。这种新型数值求解器不会对未解决的自由度取平均,而是使用离散方程,对未解决的网格给出逐点精确解。研究人员
将受分辨率损失影响最大的传统求解器组件替换为其学得的组件,利用机器学习发现了一些算法
。
如下图 1a 所示,对于涡流的二维直接数值模拟,该研究提出的算法可以在每个维度的分辨率粗糙 10 倍的情况下维持准确率不变,也就是说获得了 80 倍的计算时间改进。该模型学习如何对解的局部特征进行插值,从而能够准确泛化至不同的流条件,如不同受力条件,甚至不同的雷诺数(图 1b)。
研究者还将该方法应用于涡流的高分辨率 LES 模拟中,获得了类似的性能提升,在网格分辨率粗糙 8 倍的情况下在 Re = 100, 000 LES 模拟中维持逐点准确率不变,实现约 40 倍的计算加速。
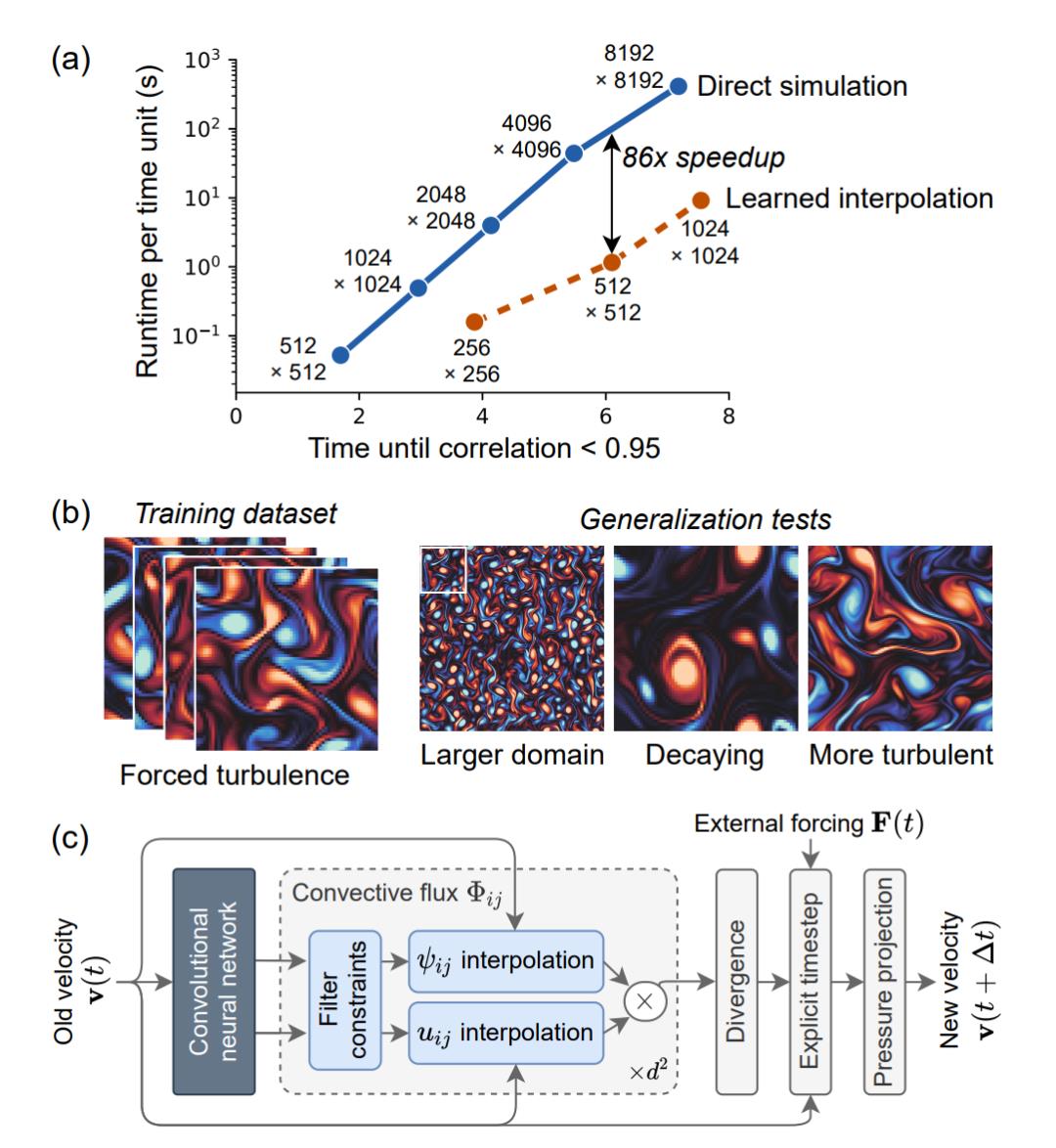
图 1:该研究提出方法与结果概览。a)基线(direct simulation)与 ML 加速(learned interpolation)求解器的准确率与计算成本对比情况;b)训练与验证样本图示,展示出该模型强大的泛化能力;c)该研究提出「learned interpolation」模型的单时间步结构,用卷积神经网络控制标准数值求解器对流计算中学得的近似。
研究者使用数据驱动离散化将微分算子插值到粗糙网格,且保证高准确率(图 1c)。具体而言,将求解底层偏微分方程的标准数值方法内的求解器作为可微分编程进行训练,在 JAX 框架中写神经网络和数值方法(JAX 框架支持反向模式自动微分)。这允许对整个算法执行端到端的梯度优化,与密度泛函理论、分子动力学和流体方面的之前研究类似。研究者推导出的这些方法是特定于方程的,需要使用高分辨率真值模拟训练粗糙分辨率的求解器。由于偏微分方程的动态是局部的,因此高分辨率模拟可以在小型域内实施。
该算法的工作流程如下:在每一个时间步中,神经网络在每个网格位置基于速度场生成隐向量,然后求解器的子组件使用该向量处理局部解结构。该神经网络为卷积网络,具备平移不变性,因而允许解结构在空间中是局部的。之后,使用标准数值方法的组件执行纳维 - 斯托克斯方程对应的归纳偏置,如图 1c 灰色框所示:对流通量(convective flux)模型改进离散对流算子的近似;散度算子(divergence operator)基于有限体积法执行局部动量守恒;压力投影(pressure projection)实现不可压缩性,显式时间步算子(explicit time step operator)使动态具备时间连续性,并允许额外时变力的插值。「在更粗糙网格上的 DNS」将传统 DNS 和 LES 建模的界限模糊化,从而得到多种数据驱动方法。
该研究主要关注两种 ML 组件:learned interpolation 和 learned correction。此处不再赘述,详情参见原论文。
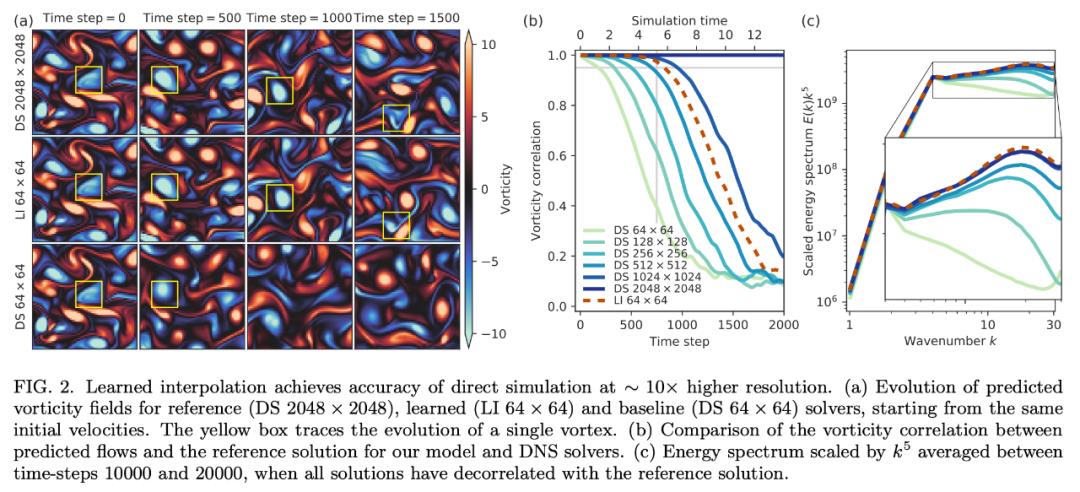
一旦网格分辨率无法捕捉到解的最小细节,则 DNS 的准确率将快速下降。而该研究提出的 ML 方法极大地缓解了这一效应。下图 2 展示了
雷诺数 Re = 1000 的情况下在 Kolmogorov 流上训练和评估模型的结果
。
而就
计算效率
而言,10 倍网格粗糙度的情况下,learned interpolation 求解器取得与 DNS 同等准确率的速度也要更快。研究者在单个谷歌云 TPU v4 内核上对该求解器进行了基准测试,谷歌云 TPU 是用于机器学习模型的硬件加速器,也适用于许多科学计算用例。在足够大的网格大小(256 × 256 甚至更大)上,该研究提出的神经网络能够很好地利用矩阵乘法单元,每秒浮点运算的吞吐量是基线 CFD 求解器的 12.5 倍。因此,尽管使用了 150 倍的算术运算,该 ML 求解器所用时间仍然仅有同等分辨率下传统求解器的 1/12。三个维度(两个空间维度和一个时间维度)中有效分辨率的 10 倍提升,带来了 10^3/12 ≈ 80 倍的加速。
此外,研究者还考虑了
三种不同的泛化测试
:大型域规模;非受迫衰减涡流;较大雷诺数的 Kolmogorov 流。
首先,研究者将同样的力泛化至较大的域规模。该 ML 模型得到了与在训练域中同样的性能,因为它们仅依赖流的局部特征(参见下图 5)。
然后,研究者将在 Kolmogorov 流上训练的模型应用于衰减涡流。下图 3 表明,在 Kolmogorov 流 Re = 1000 上学得的离散模型的准确率可以匹配以 7 倍分辨率运行的 DNS。
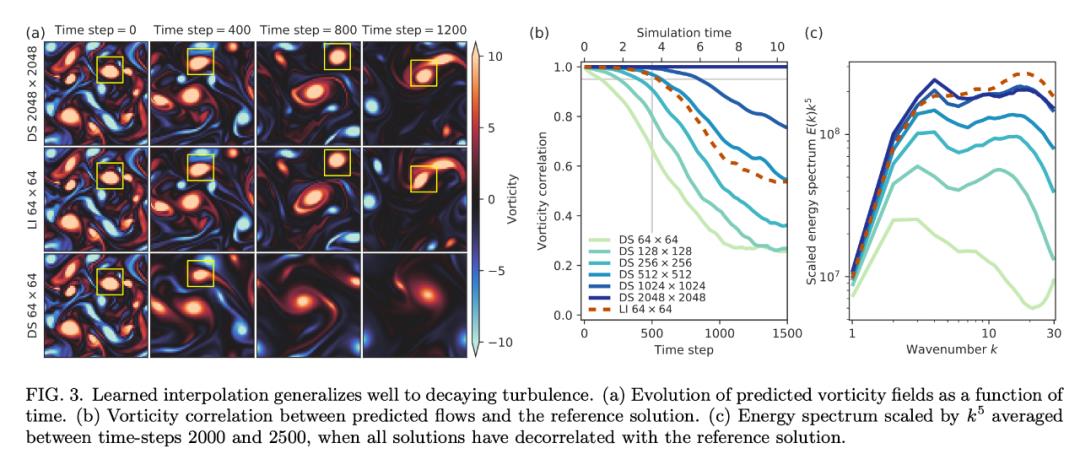
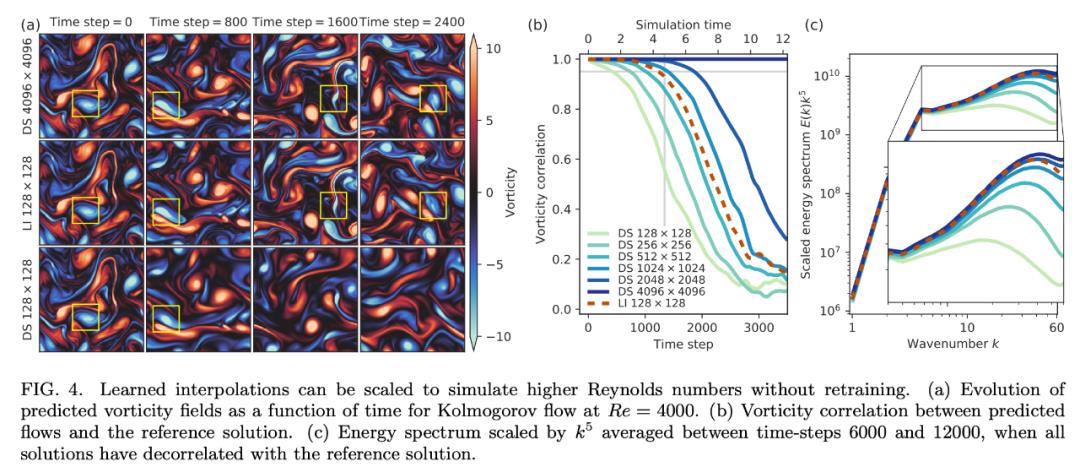
最后,该模型可以泛化至更高的雷诺数吗?也就是更复杂的流。下图 4a 表明,该模型的准确率可以匹配以 7 倍分辨率运行的 DNS。鉴于该测试是在复杂度显著增加的流上进行的,因此这种泛化效果很不错。图 4b 对速度进行了可视化,表明该模型可以处理更高的复杂度,图 4c 的能谱进一步验证了这一点。
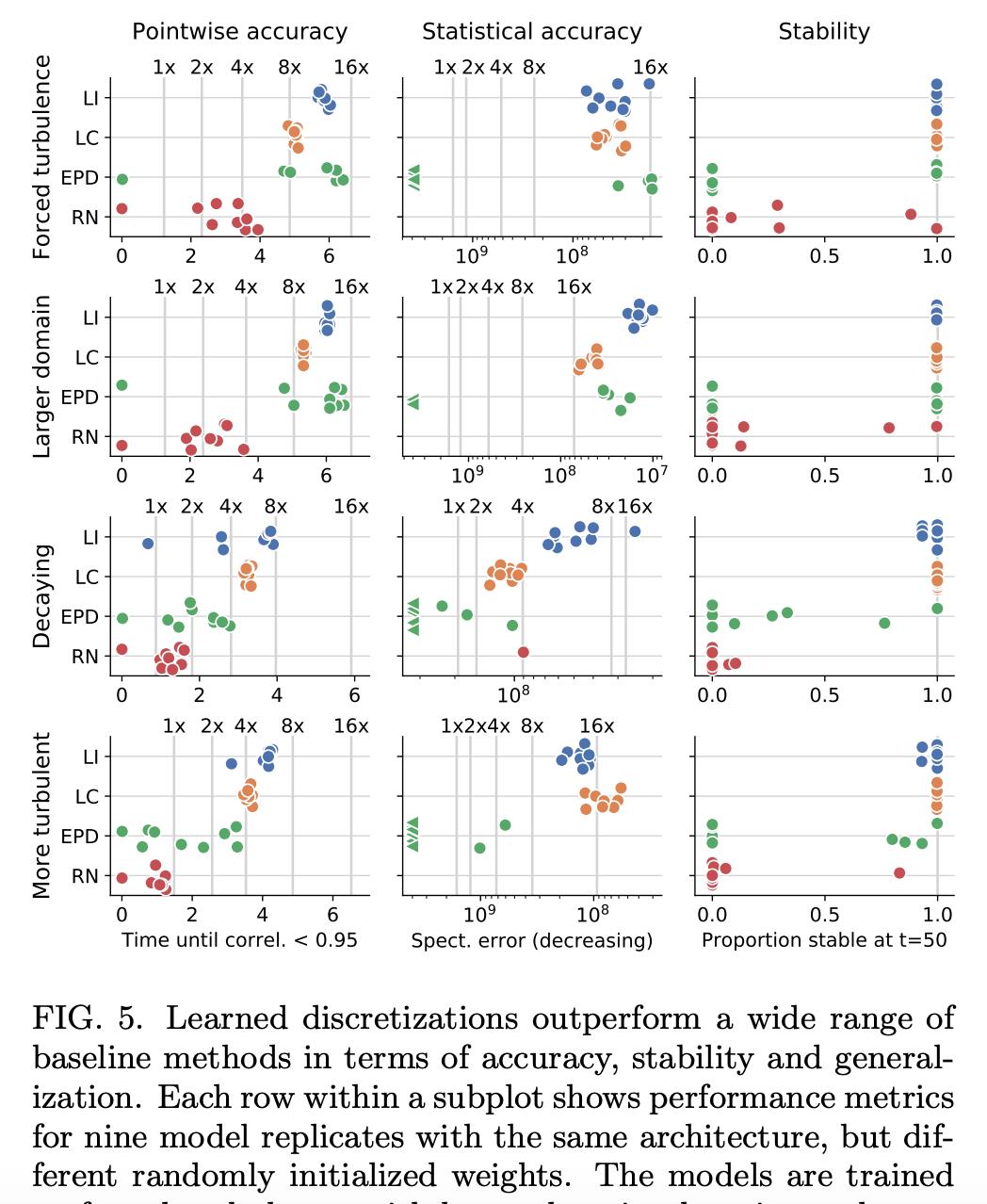
研究者将 learned interpolation 与其他 ML 方法的性能进行了对比,包括 ResNet (RN) [50]、Encoder Processor-Decoder (EPD) [51, 52] 架构和之前介绍的 learned correction (LC) 模型。下图 5 展示了这些方法在所有考虑配置中的结果。总体而言,learned interpolation (LI) 性能最佳,learned correction (LC) 紧随其后。
研究者已经描述了该方法在 DNS 纳维 - 斯托克斯方程中的应用,但其实该方法是较为通用的,可用于任意非线性偏微分方程。为了证明这一点,研究者将该方法应用于 LES 加速。当 DNS 不可用时,LES 是执行大规模模拟的行业标准方法。
下图 6 表明,将 learned interpolation 应用于 LES 也能达到 8 倍的 upscaling,相当于实现大约 40 倍的加速。
2021年 2 月的第一周,机器之心将携手二十余位 AI 人耳熟能详的重磅嘉宾进行在线直播,通过圆桌探讨、趋势Talk,报告解读及案例分享等形式,为关注人工智能产业发展趋势的AI人解读技术演进趋势,共同探究产业发展脉络。连续七天,精彩不停。
添加机器之心Pro小助手(syncedai 或 syncedproii),备注「2021」,进群一起看直播。
以上是关于机器学习与流体动力学:谷歌AI利用「ML+TPU」实现流体模拟数量级加速的主要内容,如果未能解决你的问题,请参考以下文章
AI - 一些概念
利用AI和机器学习为数据中心提供动力
谷歌机器学习速成课程---2深入了解机器学习(Descending into ML)
国产开源项目也能用SQL解决机器学习问题!与谷歌BigQuery ML有何不同?
AI - MLCC - 02 - 深入了解机器学习 (Descending into ML)
深度揭秘谷歌TPU2机器学习集群:新一代的「谷歌云TensorFlow处理单元」