数据分析——python,pandas:DataFrame对象(pivot_table函数的使用)数据透视表
Posted 小乖乖的臭坏坏
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据分析——python,pandas:DataFrame对象(pivot_table函数的使用)数据透视表相关的知识,希望对你有一定的参考价值。
如果刚刚看过这篇博文:
数据分析——python,pandas:DataFrame对象(groupby函数的使用)排序
https://blog.csdn.net/weixin_42887138/article/details/117676527
那我就直接上代码了:
import pandas as pd
import numpy as np
a = [[1,2,3,4,5],[1,3,6,8,0],[2,2,6,0,2],[2,2,5,7,6]]
col = ['a','b','c','d','e']
df_data = pd.DataFrame(a,columns=col)
print('df_data:\\n', df_data, '\\n')
df = df_data.groupby(['a','b','c']).sum()
会有这样一张表:
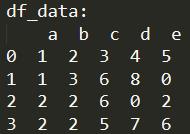
那么,这篇博文要讲的是数据透视表,主要由函数pivot_table实现。这个函数中无论是构建成新表的索引指标index,列columns,表中的值values,都是由原来的表格的列来确定。
举个例子:以b和d列作为新表的行,c列作为新表的咧,e列中的值作为新表中的值。
df = df.pivot_table(index=['b','d'], columns='c', values='e', fill_value=0)
接下来,给完整代码以欣赏:
import pandas as pd
import numpy as np
a = [[1,2,3,4,5],[1,3,6,8,0],[2,2,6,0,2],[2,2,5,7,6]]
col = ['a','b','c','d','e']
df_data = pd.DataFrame(a,columns=col)
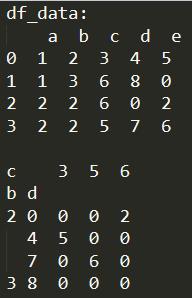
print('df_data:\\n', df_data, '\\n')
df = df_data.groupby(['a','b','c']).sum()
#数据透视表的作用是将原来的数据表中的列名,分别设置到行、列和值,然后建立一张具有全新意义的新表。
df = df.pivot_table(index=['b','d'], columns='c', values='e', fill_value=0)
df.reset_index(inplace=True)
print(df)
运行结果:
作于:
2021-6-7
23:13
以上是关于数据分析——python,pandas:DataFrame对象(pivot_table函数的使用)数据透视表的主要内容,如果未能解决你的问题,请参考以下文章
python pandas.DataFrame选取修改数据最好用.loc,.iloc,.ix