2021华中杯 B 题
Posted zhuo木鸟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021华中杯 B 题相关的知识,希望对你有一定的参考价值。
2021华中杯 B 题:题目+数据+代码
本人专挑数据挖掘、机器学习和 NLP 类型的题目做,有兴趣也可以逛逛我的数据挖掘竞赛专栏。
本人不会回访,不互关,不互吹,以及谢绝诸如此类事
思路
其实这个比赛可以总结为一个问题,第二个问题只是在第一个问题的基础上的应用而已。而解决第1个问题的关键就在于构建一个机器学习模型,从而能够根据两个非结构化的文本来输出,两者之间是否重复。说到底就是一个监督学习的问题。
要解决这个监督学习问题,首先就要将非结构化的文本转换为结构化的,类似于表格或者向量的数据。为了解决这个问题,本文将英语文本进行拆分,停用词过滤,提取词根,在采用词袋模型配合TF-IDF方法,最终将非结构化的英语文本转换为一个向量。
之后将附件2,与处理过后的附件一进行合并,从而获得用以机器学习的数据集。考虑到直接合并产生的数据及占用的空间非常大,所以本文在进行合并操作的时候进行了适当的筛选。
然后由于重复的数据比起非重复的数据,数量上差距太大,如果直接用于监督学习,会由于类别不均衡问题,导致模型的效果太差。所以在训练模型之前,本文采用过采样和欠采样的方法,来解决数据的类别不均衡问题。
再考虑到数据的特征非常多,容易造成维度灾难,因此本文将采用卡方检验来排除那些不相关的特征。
最后本文将采用逻辑回归模型,根据上述处理过后的数据,即按 7:3 的比例拆分成训练集和测试集,在训练集中训练模型,在测试集中评价模型评价指标为 F1 值。
第二题有些迷,建议大家挑着做吧,对这次比赛,我个人意见是比较大的(哪有类别不均衡成这种程度的嘛~)。
到机器学习模型之后,要解决第2问就比较容易了。只需要将目标问题与其他问题的两两配对,输入到逻辑回归模型之中,就可以得出相应的概率,然后依据概率最大,提取出前10个问题即可。
逻辑回归模型当然不仅可以输出概率,也可以输出类别。我们只要应用逻辑回归模型对目标问题和这前10个问题进行预测,得到标签,结合原数据标签,就可以得出可以K值。
不过,按照我的那个模型,算出的 K 值比较低… 原因可能是因为在训练模型的时候,数据没有全部投入的缘故,又或者是解决类别不均衡时,引入了太多的误差。因此,这里就仅仅实现了一部分了
若要解决这个问题,可以:
- 加大训练数据,最好将所有的数据都投进去。
- 给相似数据赋予一个较大的权重,使得少数类数据能够被加强学习…
又或者,换一个做法…
非结构化文本→结构化表格(英文)
这里主要将英文的文本数据,转换成结构化的 TF-IDF 词袋模型数据:
网页标识处理
这里将所有的网络 tag 都删除,仅保留文本:
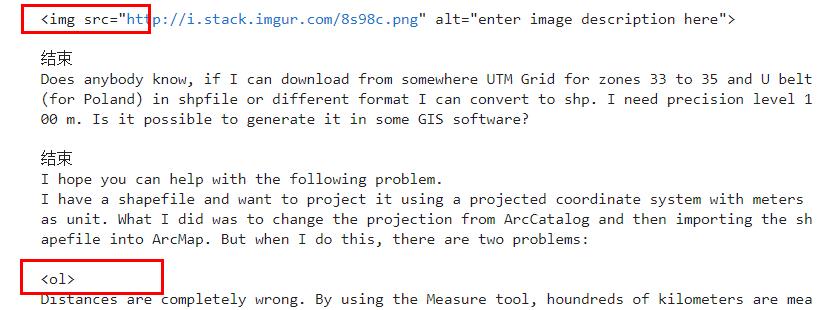
空格、标点符号过滤,并转换为小写
以第一条为例:
I have an ArcGis Desktop Standard license and I would like to perform an operation to find out the difference between 2 features classes geometries (Something like symmetrical difference in Arcgis advanced version). Unfortunately symmetrical difference is not available for Arcgis desktop standard. The operation should be performed using Arcpy. Has anyone a tip for me, how to perform such an operation on Arcgis Standard?
Thanks
经过如下处理:
- 将文本的左右两边的空格,空行都删除。
- 将文本转换为小写
- 将文本中所有的标点符号转换为 空格。
可得:
i have an arcgis desktop standard license and i would like to perform an operation to find out the difference between 2 features classes geometries something like symmetrical difference in arcgis advanced version unfortunately symmetrical difference is not available for arcgis desktop standard the operation should be performed using arcpy has anyone a tip for me how to perform such an operation on arcgis standard thanks
停用词过滤、保留词根
- 将字符串中包含的停用词1过滤
- 将字符串中的每个字符,用其词根替换。
转换后变为:
arcgi desktop standard licens would like perform oper find differ 2 featur class geometri someth like symmetr differ arcgi advanc version unfortun symmetr differ avail arcgi desktop standard oper perform use arcpi anyon tip perform oper arcgi standard thank
TF-IDF 建模
- 用 TF-IDF 词袋模型,对上述处理后的数据进行建模。至此,就可以将非结构化的文本数据,转换为结构化文本。

生成用于机器学习的数据集
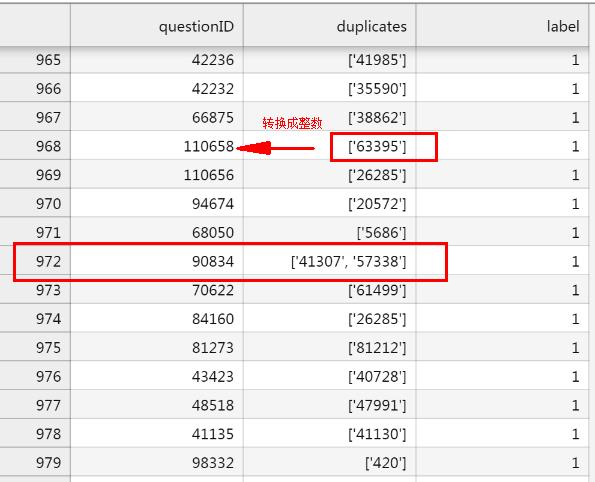
附件 2 有 questionID、duplicates、labels。其中 Duplicates 是一个字符串,字符串包含了所有与该行 questionID 重复的所有 questions 的 IDs,如下所示:
返回目录
将 duplicates 转换成 duplicate
比如 questionID = 90834,将其转换为:
| questionID | duplicate |
|---|---|
| 90834 | 41307 |
| 90834 | 57338 |
当然,在此之前,需要将 [‘41307’, ‘57338’] 转换为单纯的整数。
附件一与附件二合并
粗放地合并
对于那些标签 0 的数据,我们发现他们的 duplicates 列 NAN:

以 73399 为例,可以理解为,73399 和其他 questionID 的标签都为 0,也就是问题不重复。
因此,可以我们可以考虑将附件一种的 question 两两组合起来,并根据附件二,给这些数据打上标签,以表明这两个问题是否重复。
但这就会导致一个大问题,首先附件 1 的问题(数据)共有 7294 条。若两两组合,则会有 ! 7294 = 53202436 !7294=53202436 !7294=53202436,共有 5 千多万条。而附件 1 经过处理后,共有 23268 列,加上两两拼接,共有 23268 × 2 = 46536 23268\\times2=46536 23268×2=46536,最终数据的大小是 ( 53202436 , 46536 ) (53202436 ,46536 ) (53202436,46536)。可以看到,数据量非常的大!
另一个问题是,附件二中,那些两两重复的问题共有 1004 个。两相对比下, 53202436 : 1004 ≈ 5299 53202436:1004 \\approx 5299 53202436:1004≈5299,可以说数据是非常不均衡的。如果采用过采样、欠采样的方法解决,则必须要用欠采样生成新样本,从而将数据量化为: ( 1 亿 , 46536 ) (1 亿,46536) (1亿,46536)
所以不能将用这种合并。
选择地合并
由于我们的题目是要求出一个,给出两个问题,返回两个问题相似的概率。所以,就要训练一个机器学习模型。
那么,训练该机器学习的数据集,是否有必要将所有问题的两两组合都投入训练呢?需要但不必要。
因为,我们已经知道,首先:
- 输入只是局限于附件 1 中。
- 重复与否,也局限于附件 2 中。
那么,既然如此,我们只要把那些,两两重复的所有 id 提取出来(共 1792 条,没记错的话),然后,再与剩下的问题两两构成配对即可。这时,数据集的大小大概为:13105521。
虽然如此,但是不得不说数据量还是太大了,并且还是会有类别不均衡的问题。因此,这里考虑,使用分层不重复抽样的方法,从 label==0 的数据抽取 0.005,再与 label==1 的数据构成一个新的数据集。最终得到 66527 个数据。
不过:

这就是大数据的魅力啊!
解决上述问题有两种方法:
- 用 dask 分块读取
- 特征过滤
考虑到特征过滤在接下来我们也需要使用,所以对数据先进行特征过滤。
特征过滤
为了对数据进行过滤,且在过滤的过程中,必须避免直接合并附近 1 和附件 2(11 GB 吃不消呀),所以这里将附件二(处理过的)中的 label==0 的数据随机采样,从而将 label==0 的数量弄成与 label==1 相同,也即 1004 条。
之后,再用采样后的 1004 × 3 1004\\times 3 1004×3 的“附件二”,与结构化附件一拼接,如何拼接?
首先,以 “附件二” 的第一个 questionID 和 “附件一” 的 id 为链接键,然后再用 SQL 的内连接方式拼接在一起。
之后,以以 “附件二” 的第二个 questionID 和 “附件一” 的 id 为链接键,然后再用 SQL 的内连接方式拼接在一起。
最后,再取两个表格相减的绝对值,作为最终数据。
然后,对“最终数据”,我们采用卡方检验,设置显著水平为 α = 0.5 \\alpha=0.5 α=0.5,原假设为:当前检验的特征与是否重复无关(相互独立)。之后,我们将那些否定原假设的特征提取出来,从而实现特征过滤。
合并
根据上述过滤后的表头,套用到“附件一”中,从而大大降低附件一的列数,就可以实现与“附件二”的安全合并了(占用空间小于 1GB)。
类别不均衡问题
将附件一和附件二进行合并后,由于 label==1 的数据只有 1004 条,而 label==0 的数据却有65023 条,可以看到数据是极度不均衡的。
为了解决类别不均衡问题,我们需要将数据先后进行:采用单边选择算法,和 ADASYN 算法的过采样、欠采样,进而解决类别不均衡问题。
逻辑回归模型——判断两问题是否相似
将解决类别不均衡后的数据集,按 7:3 的比例拆分为训练集、测试集,以 label 为输出,其他特征为输入。
采用逻辑回归模型,用训练集训练模型,用测试集测试模型的效果,评价模型的指标为 F1 值,结果如下:
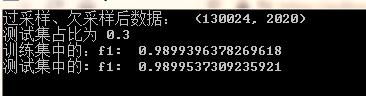
似乎测试集的 F1 比训练集还要好哈。。。
TopK 与得分 R
由于逻辑回归模型判断的标准是 sigmoid 函数,引起其不仅可以根据数据得出标签,而且也可以得出其属于某个标签的概率。因此,我们可以直接采用上述的逻辑回归模型,求出两个问题是否重复的概率,并根据概率进行排行,进而得到 TopK 列表。
由于该题的计算量比较大,对于每一个 question_id,都要和其他所有的 question 进行比较,没算个千万次还算不出来。因此,我们这边只考虑 question_id = 90834,得出与其相似的概率最大的 10 个问题如下:
[(41307, 1),
(57338, 1),
(50415, 0.9693937320515627),
(69294, 0.9441227907362385),
(59864, 0.9392773351052164),
(104161, 0.9374120712282645),
(86847, 0.911329510159202),
(57438, 0.8774133886495158),
(104165, 0.8473797269811091),
(80698, 0.8210906200777438)]
代码与提问
若需要代码,请关注、私信、说明题目和年份
如果有其他问题,请到评论区留言,私信提问,概不回答。也在此鼓励大家独立思考。
本人不会回访,不互关,不互吹,以及谢绝诸如此类事
如果本篇博文对您有所帮助,请不要吝啬您的点赞 😊
停用词指那些意义较小的词,如 an、the 等 ↩︎
以上是关于2021华中杯 B 题的主要内容,如果未能解决你的问题,请参考以下文章