浅析大数据之MapReduce
Posted 皇瑪亚洲之星
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅析大数据之MapReduce相关的知识,希望对你有一定的参考价值。
说起MapReduce,可以从思想、模型和运算及应用过程等几个方面来进行理解。首先,来简单说说它的思想。MapReduce可以说是凝结了人类对数据处理工作的基本思想,即分类与汇总。我们都知道,MapReduce其实分为两个阶段,即map阶段和reduce阶段。map阶段即映射阶段,该阶段主要负责对数据进行切分处理,reduce阶段即归约阶段,也就是在map阶段的处理结果上进行汇总。我们可以把它定位成一种用于大规模数据集并行运算的编程(算法)模型。
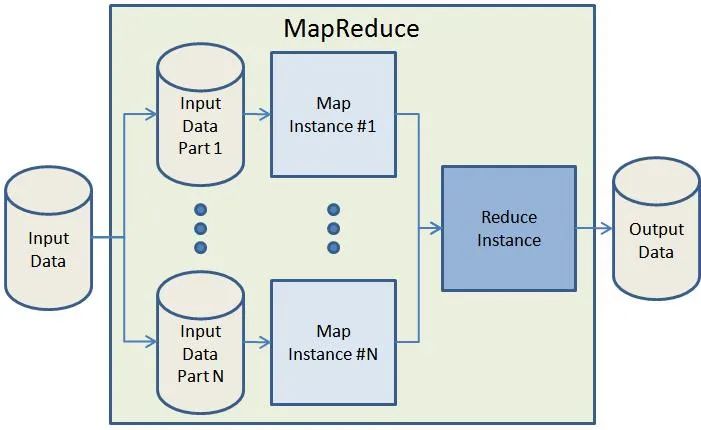
在实际应用中,MapReduce是Hadoop框架集群的核心之一,在HDFS的基础上对海量数据进行运算。
MMapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算,用于解决海量数据的计算问题。
1)映射(Mapping)对集合里的每个目标应用同一个操作。即,如果你想把表单里每个单元格乘以二,那么把这个函数单独地应用在每个单元格上的操作就属于mapping。
2)化简(Reducing)遍历集合中的元素来返回一个综合的结果。即,输出表单里一列数字的和这个任务属于reducing。
你向MapReduce框架提交一个计算作业时,它会首先把计算作业拆分成若干个Map任务,然后分配到不同的节点上去执行,
每一个Map任务处理输入数据中的一部分,当Map任务完成后,它会生成一些中间文件,这些中间文件将会作为Reduce任务的输入数据。
Reduce任务的主要目标就是把前面若干个Map的输出汇总到一起并输出。
MapReduce的伟大之处就在于编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
我们只要遵循 MapReduce 编程模型编写业务处理逻辑代码(编写Map和Reduce里面的函数),就可以运行在 Hadoop 分布式集群上,无需关心分布式计算是如何完成的。也就是说,我们只需要关心业务逻辑,不用关心系统调用与运行环境,这和我们目前的主流开发方式是一致的。
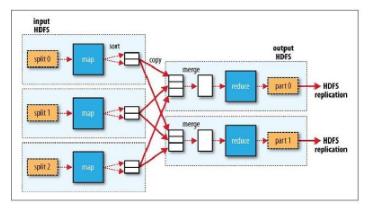
其实,MapReduce中的map在做select/scan,shuffle就是在做groupby,reduce在做aggregation。另外,reduce也用于实现join。
MapReduce 既是一个编程模型,又是一个计算框架。也就是说,开发人员必须基于 MapReduce 编程模型进行编程开发,然后将程序通过 MapReduce 计算框架分发到 Hadoop 集群中运行。我们先看一下作为编程模型的 MapReduce。
MapReduce 的编程模型,类似于函数式编程,按照这个模型写出的代码运行在hadoop集群,可以实现分布式计算的效果

点分享

点收藏
以上是关于浅析大数据之MapReduce的主要内容,如果未能解决你的问题,请参考以下文章
大数据框架之Hadoop:MapReduceMapReduce框架原理——Join多种应用
浅析大数据之MapReduce
Google大数据处理系统介绍之MapReduce浅析
组合数据浅析之“幻方”
大数据技术栈
大数据离线
