大数据离线
Posted lifuwei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据离线相关的知识,希望对你有一定的参考价值。
MapReduce
MapReduce计算模型
- MapReduce的思想就是“ 分而治之”
Map 负责“分”,即把复杂的任务分解为若干个“简单的任务”来处理。“简单的任务”包含三层含义:一是数据或计算的规模相对任务要大大缩小;二是就近计算原则,即任务会分配到存放着所需数据的节点上进行计算;三是这些小任务可以并行计算,彼此间几乎没有依赖关系。
Reduce 负责对 map 阶段的结果进行汇总。 MapReduce设计构思
①如何对付大数据处理:分而治之
②构建抽象模型:Map 和 Reduce两个函数
MapReduce 处理的数据类型是<key,value>键值对
③统一构架,隐藏系统层细节MapReduce框架结构
①MRAppMaster:负责整个程序的过程调度及状态协调
②MapTask:负责 map 阶段的整个数据处理流程
③ReduceTask:负责 reduce 阶段的整个数据处理流程
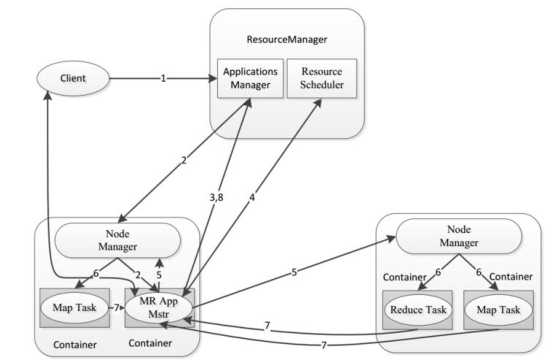
MapReduce处理流程

Mapper任务执行过程
- 第一阶段是把输入目录下文件按照一定的标准逐个进行逻辑切片,形成切片规划。默认情况下,Split size = Block size。每一个切片由一个MapTask 处理。
- 第二阶段是对切片中的数据按照一定的规则解析成<key,value>对。默认规则是把每一行文本内容解析成键值对。key 是每一行的起始位置(单位是字节),value 是本行的文本内容。(TextInputFormat)
- 第三阶段是调用 Mapper 类中的 map 方法。上阶段中每解析出来的一个<k,v>,调用一次 map 方法。每次调用 map 方法会输出零个或多个键值对。
- 第四阶段是按照一定的规则对第三阶段输出的键值对进行分区。默认是只有一个区。分区的数量就是 Reducer 任务运行的数量。默认只有一个Reducer 任务。
- 第五阶段是对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值对<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果是<1,3>、<2,1>、<2,2>。
- 第六阶段(可选,默认没有)是对数据进行局部聚合处理,也就是 combiner 处理。键相等的键值对会调用一次 reduce 方法。经过这一阶段,数据量会减少。
Reducer任务执行过程
- 第一阶段是 Reducer 任务会主动从 Mapper 任务复制其输出的键值对。Mapper 任务可能会有很多,因此 Reducer 会复制多个 Mapper 的输出。
- 第二阶段是把复制到 Reducer 本地数据,全部进行合并,即把分散的数据合并成一个大的数据。再对合并后的数据排序。
- 第三阶段是对排序后的键值对调用 reduce 方法。键相等的键值对调用一次reduce 方法,每次调用会产生零个或者多个键值对。最后把这些输出的键值对写入到 HDFS 文件中
以上是关于大数据离线的主要内容,如果未能解决你的问题,请参考以下文章