实践案例Databricks 数据洞察在美的暖通与楼宇的应用实践
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实践案例Databricks 数据洞察在美的暖通与楼宇的应用实践相关的知识,希望对你有一定的参考价值。
简介: 获取更详细的 Databricks 数据洞察相关信息,可至产品详情页查看:https://www.aliyun.com/product/bigdata/spark
作者
美的暖通与楼宇事业部 先行研究中心智能技术部
美的暖通 IoT 数据平台建设背景
美的暖通与楼宇事业部(以下简称美的暖通)是美的集团旗下五大板块之一,产品覆盖多联机组、大型冷水机组、单元机、机房空调、扶梯、直梯、货梯以及楼宇自控软件和建筑弱电集成解决方案,远销海内外200多个国家。当前事业部设备数据上云仅停留在数据存储层面,缺乏挖掘数据价值的平台,造成大量数据荒废,并且不断消耗存储资源,增加存储费用和维护成本。另一方面,现有数据驱动应用缺乏部署平台,难以产生实际价值。因此,急需统一通用的 IoT 数据平台,以支持设备运行数据的快速分析和建模。
我们的 IoT 数据平台建设基于阿里云 Databricks 数据洞察全托管 Spark 产品,以下是整体业务架构图。在本文后面的章节,我们将就IoT数据平台建设技术选型上的一些思考,以及 Spark 技术栈尤其是 Delta Lake 场景的应用实践做一下分享。
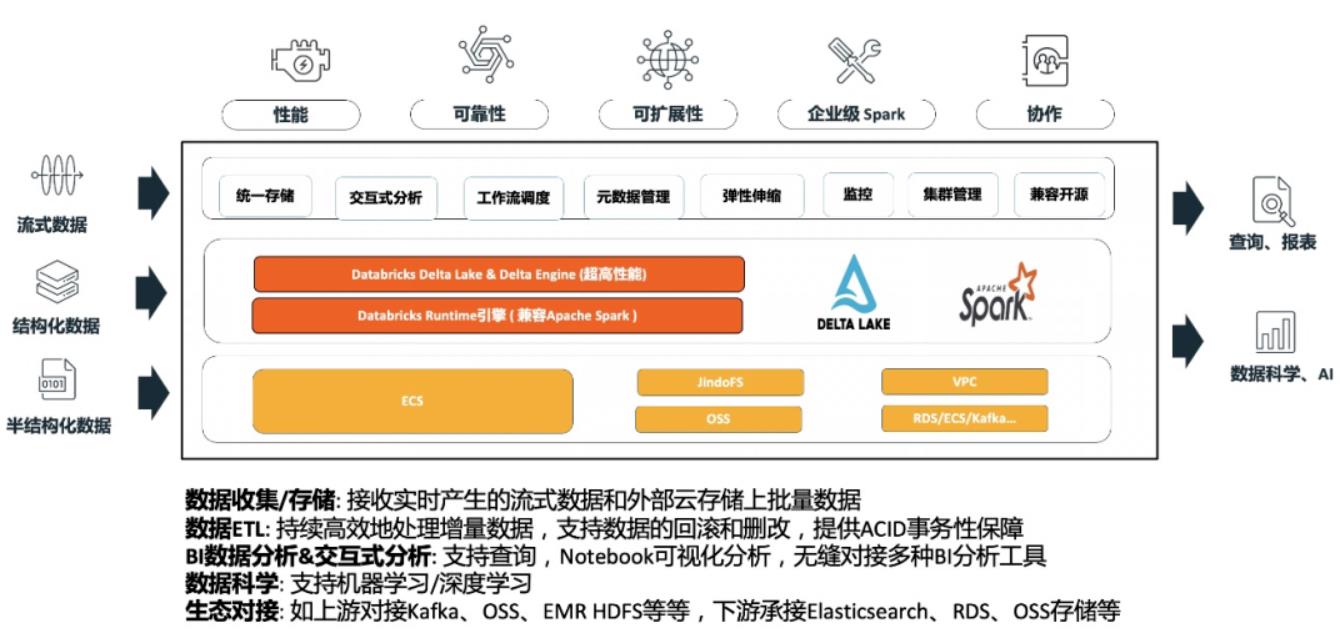
选择 Spark & Delta Lake
在数据平台计算引擎层技术选型上,由于我们数据团队刚刚成立,前期的架构选型我们做了很多的调研,综合各个方面考虑,希望选择一个成熟且统一的平台:既能够支持数据处理、数据分析场景,也能够很好地支撑数据科学场景。加上团队成员对 Python 及 Spark 的经验丰富,所以,从一开始就将目标锁定到了 Spark 技术栈。
选择 Databricks 数据洞察 Delta Lake
通过与阿里云计算平台团队进行多方面的技术交流以及实际的概念验证,我们最终选择了阿里云 Databricks 数据洞察产品。作为 Spark 引擎的母公司,其商业版 Spark 引擎,全托管 Spark 技术栈,统一的数据工程和数据科学等,都是我们决定选择 Databricks 数据洞察的重要原因。
具体来看,Databricks 数据洞察提供的核心优势如下:
- Saas 全托管 Spark:免运维,无需关注底层资源情况,降低运维成本,聚焦分析业务
- 完整 Spark 技术栈集成:一站式集成 Spark 引擎和 Delta Lake 数据湖,100%兼容开源 Spark 社区版;Databricks 做商业支持,最快体验 Spark 最新版本特性
- 总成本降低:商业版本 Spark 及 Delta Lake 性能优势显著;同时基于计算存储分离架构,存储依托阿里云 OSS 对象存储,借助阿里云 JindoFS 缓存层加速;能够有效降低集群总体使用成本
- 高品质支持以及SLA保障:阿里云和 Databricks 提供覆盖 Spark 全栈的技术支持;提供商业化 SLA 保障与7*24小时 Databricks 专家支持服务
IoT 数据平台整体架构
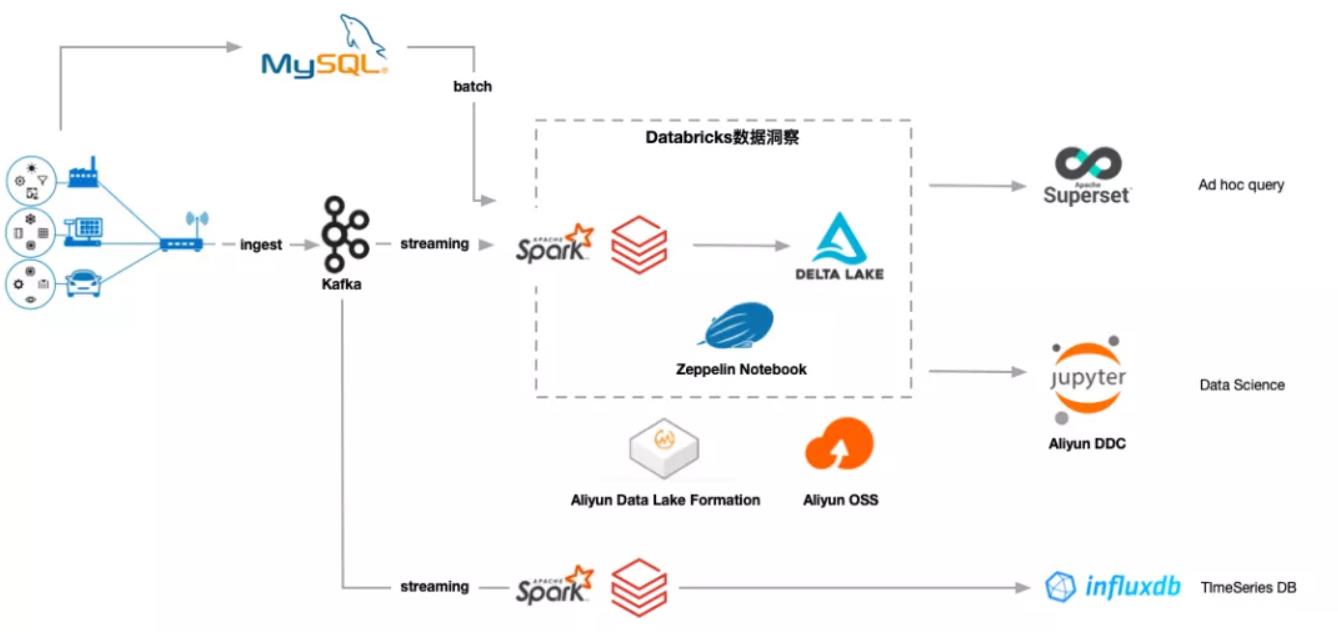
整体的架构如上图所示。
我们接入的 IoT 数据分为两部分,历史存量数据和实时数据。目前,历史存量数据是通过 Spark SQL 以天为单位从不同客户关系数据库批量导入 Delta Lake 表中;实时数据通过 IoT 平台采集到云 Kafka ,经由 Spark Structured Streaming 消费后实时写入到 Delta Lake 表中。在这个过程中,我们将实时数据和历史数据都 sink 到同一张 Delta 表里,这种批流一体操作可大大简化我们的 ETL 流程(参考后面的案例部分)。数据管道下游,我们对接数据分析及数据科学工作流。
IoT 数据采集:从 Little Data 到 Big Data
作为 IoT 场景的典型应用,美的暖通最核心的数据均来自 IoT 终端设备。在整个 IoT 环境下,分布着无数个终端传感器。从小的维度看,传感器产生的数据本身属于 Small Data(或者称为 Little Data)。当把所有传感器连接成一个大的 IoT 网络,产生自不同传感器的数据经由 Gateway 与云端相连接,并最终在云端形成 Big Data 。
在我们的场景下,IoT 平台本身会对不同协议的数据进行初步解析,通过定制的硬件网络设备将解析后的半结构化 JSON 数据经由网络发送到云 Kafka。云 Kafka 扮演了整个数据管道的入口。
数据入湖:Delta Lake
IoT 场景下的数据有如下几个特点:
- 时序数据:传感器产生的数据记录中包含时间相关的信息,数据本身具有时间属性,因此不同的数据之间可能存在一定的相关性。利用 as-of-join 将不同时间序列数据 join 到一起是下游数据预测分析的基础
- 数据的实时性:传感器实时生成数据并以最低延迟的方式传输到数据管道,触发规则引擎,生成告警和事件,通知相关工作人员。
- 数据体量巨大:IoT 网络环境下遍布各地的成千上万台设备及其传感器再通过接入服务将海量的数据归集到平台
- 数据协议多样:通常在 IoT 平台接入的不同种类设备中,上传数据协议种类多样,数据编码格式不统一
IoT 数据上述特点给数据处理、数据分析及数据科学等带来了诸多挑战,庆幸的是,这些挑战借助 Spark 和 Delta Lake 都可以很好地应对。Delta Lake 提供了 ACID 事务保证,支持增量更新数据表以及流批同时写数据。借助 Spark Structed Streaming 可以实现 IoT 时序数据实时入湖。
以下是 Delta Lake 经典的三级数据表架构。具体到美的暖通 IoT 数据场景,我们针对每一层级的数据表分别做了如下定义:
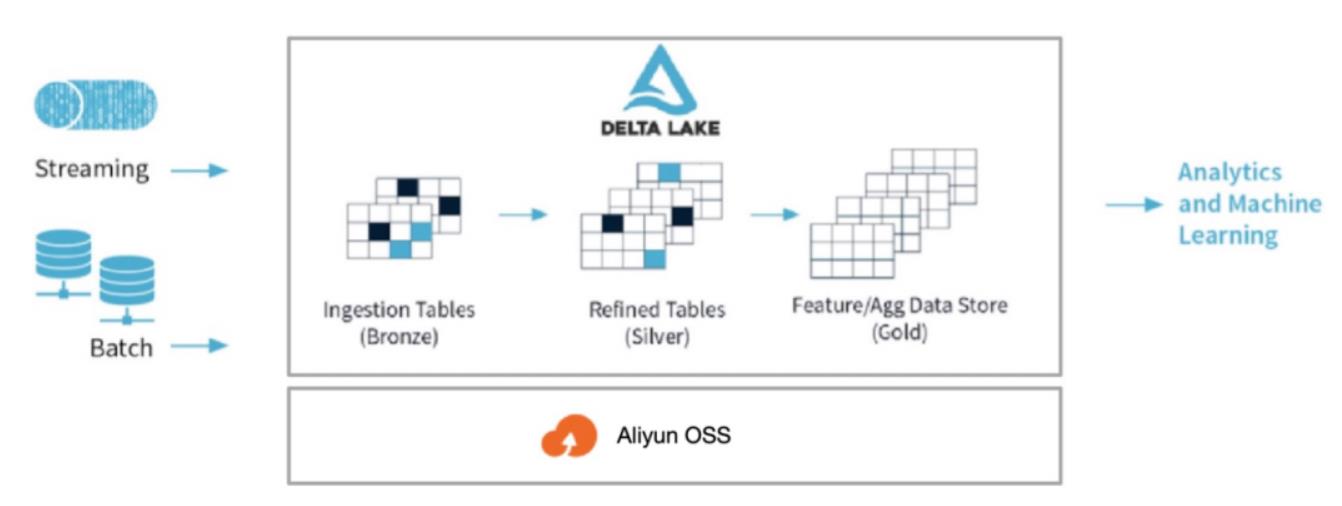
- Bronze 表:存储原生数据(Raw Data),数据经由 Spark Structed Streaming 从 Kafka 消费下来后 upsert 进 Delta Lake 表,该表作为唯一的真实数据表 (Single Source of Truth)
- Silver表:该表是在对 Bronze 表的数据进行加工处理的基础上生成的中间表,在美的暖通的场景下,数据加工处理的步骤涉及到一些复杂的时序数据计算逻辑,这些逻辑都包装在了 Pandas UDF 里提供给 Spark 计算使用
- Gold 表:Silver 表的数据施加 Schema 约束并做进一步清洗后的数据汇入 Gold 表,该表提供给下游的 Ad Hoc 查询分析及数据科学使用
数据分析:Ad-Hoc 查询
我们内部在开源 Superset 基础上定制了内部版本的 SQL 查询与数据可视化平台,通过 PyHive 连接到 Databricks 数据洞察 Spark Thrift Server 服务,可以将 SQL 提交到集群上。商业版本的 thrift server 在可用性及性能方面都做了增强,Databricks 数据洞察针对 JDBC 连接安全认证提供了基于 LDAP 的用户认证实现。借助 Superset ,数据分析师及数据科学家可以快速高效的对 Delta Lake 表进行数据探索。
数据科学:Workspace
楼宇能耗预测与设备故障诊断预测是美的暖通 IoT 大数据平台建设的两个主要业务目标。在 IoT 数据管道下游,需要对接机器学习平台。现阶段为了更快速方便地支撑起数据科学场景,我们将 Databricks 数据洞察集群与阿里云数据开发平台 DDC 打通。DDC 集成了在数据科学场景下更友好的 Jupyter Notebook ,通过在 Jupyter 上使用 PySpark ,可以将作业跑到 Databricks 数据洞察集群上;同时,也可以借助 Apache Airflow 对作业进行调度。同时,考虑到机器学习模型构建、迭代训练、指标检测、部署等基本环节,我们也在探索 MLOps ,目前这部分工作还在筹备中。
典型应用场景介绍
Delta Lake 数据入湖(批流一体)
使用 UDF 函数定义流数据写入 Delta Lake 的 Merge 规则
%spark
import org.apache.spark.sql._
import io.delta.tables._
// Function to upsert `microBatchOutputDF` into Delta table using MERGE
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO delta_{table_name} t
USING updates s
ON s.uuid = t.uuid
WHEN MATCHED THEN UPDATE SET
t.device_id = s.device_id,
t.indoor_temperature =
s.indoor_temperature,
t.ouoor_temperature = s.ouoor_temperature,
t.chiller_temperature =
s.chiller_temperature,
t.electricity = s.electricity,
t.protocal_version = s.protocal_version,
t.dt=s.dt,
t.update_time=current_timestamp()
WHEN NOT MATCHED THEN INSERT
(t.uuid,t.device_id,t.indoor_temperature,t.ouoor_temperature ,t.chiller_temperature
,t.electricity,t.protocal_version,t.dt,t.create_time,t.update_time)
values
(s.uuid,s.device_id,s.indoor_temperature,s.ouoor_temperature,s.chiller_temperature,s.electricity,s.protocal_version
,s.dt,current_timestamp(),current_timestamp())
""")
}
使用 Spark Structured Streaming 实时流写入 Delta Lake
%spark
import org.apache.spark.sql.functions._
import org.apache.spark.sql.streaming.Trigger
def getquery(checkpoint_dir:String,tableName:String,servers:String,topic:String ) {
var streamingInputDF =
spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", servers)
.option("subscribe", topic)
.option("startingOffsets", "latest")
.option("minPartitions", "10")
.option("failOnDataLoss", "true")
.load()
val resDF=streamingInputDF
.select(col("value").cast("string"))
.withColumn("newMessage",split(col("value"), " "))
.filter(col("newMessage").getItem(7).isNotNull)
.select(
col("newMessage").getItem(0).as("uuid"),
col("newMessage").getItem(1).as("device_id"),
col("newMessage").getItem(2).as("indoor_temperature"),
col("newMessage").getItem(3).as("ouoor_temperature"),
col("newMessage").getItem(4).as("chiller_temperature"),
col("newMessage").getItem(5).as("electricity"),
col("newMessage").getItem(6).as("protocal_version")
)
.withColumn("dt",date_format(current_date(),"yyyyMMdd"))
val query = resDF
.writeStream
.format("delta")
.option("checkpointLocation", checkpoint_dir)
.trigger(Trigger.ProcessingTime("60 seconds")) // 执行流处理时间间隔
.foreachBatch(upsertToDelta _) //引用upsertToDelta函数
.outputMode("update")
query.start()
}
数据灾备:Deep Clone
由于 Delta Lake 的数据仅接入实时数据,对于存量历史数据我们是通过 SparkSQL 一次性 Sink Delta Lake 的表中,这样我们流和批处理时只维护一张 Delta 表,所以我们只在最初对这两部分数据做一次 Merge 操作。同时为了保证数据的高安全,我们使用 Databricks Deep Clone 来做数据灾备,每天会定时更新来维护一张从表以备用。对于每日新增的数据,使用 Deep Clone 同样只会对新数据 Insert 对需要更新的数据 Update 操作,这样可以大大提高执行效率。
CREATE OR REPLACE TABLE delta.delta_{table_name}_clone
DEEP CLONE delta.delta_{table_name};
性能优化:OPTIMIZE & Z-Ordering
在流处理场景下会产生大量的小文件,大量小文件的存在会严重影响数据系统的读性能。Delta Lake 提供了 OPTIMIZE 命令,可以将小文件进行合并压缩,另外,针对 Ad-Hoc 查询场景,由于涉及对单表多个维度数据的查询,我们借助 Delta Lake 提供的 Z-Ordering 机制,可以有效提升查询的性能。从而极大提升读取表的性能。DeltaLake 本身提供了 Auto Optimize 选项,但是会牺牲少量写性能,增加数据写入 delta 表的延迟。相反,执行 OPTIMIZE 命令并不会影响写的性能,因为 Delta Lake 本身支持 MVCC,支持 OPTIMIZE 的同时并发执行写操作。因此,我们采用定期触发执行 OPTIMIZE 的方案,每小时通过 OPTIMIZE 做一次合并小文件操作,同时执行 VACCUM 来清理过期数据文件:
OPTIMIZE delta.delta_{table_name} ZORDER by device_id, indoor_temperature;
set spark.databricks.delta.retentionDurationCheck.enabled = false;
VACUUM delta.delta_{table_name} RETAIN 1 HOURS;
另外,针对 Ad-Hoc 查询场景,由于涉及对单表多个维度数据的查询,我们借助 Delta Lake 提供的 Z-Ordering 机制,可以有效提升查询的性能。
总结与展望
我们基于阿里云 Databricks 数据洞察产品提供的商业版 Spark 及 Delta Lake 技术栈快速构建了 IoT 数据处理平台,Databricks 数据洞察全托管免运维、商业版本引擎性能上的优势以及计算/存储分离的架构,为我们节省了总体成本。同时,Databricks 数据洞察产品自身提供的丰富特性,也极大提升了我们数据团队的生产力,为数据分析业务的快速开展交付奠定了基础。未来,美的暖通希望与阿里云 Databricks 数据洞察团队针对 IoT 场景输出更多行业先进解决方案。
原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是关于实践案例Databricks 数据洞察在美的暖通与楼宇的应用实践的主要内容,如果未能解决你的问题,请参考以下文章
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察