超详攻略!Databricks 数据洞察 - 企业级全托管 Spark 大数据分析平台及案例分析
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了超详攻略!Databricks 数据洞察 - 企业级全托管 Spark 大数据分析平台及案例分析相关的知识,希望对你有一定的参考价值。
简介: 5分钟读懂 Databricks 数据洞察 ~ 更多详细信息可登录 Databricks 数据洞察 产品链接:https://www.aliyun.com/product/bigdata/spark(当前产品提供¥599首购试用活动,欢迎试用!)
开源大数据社区 & 阿里云 EMR 系列直播 第四期
主题:Databricks 数据洞察 - 企业级全托管 Spark 大数据分析平台及案例分析
讲师:棕泽,阿里云技术专家,计算平台事业部开放平台-生态企业团队负责人
内容框架:
- Databricks 数据洞察产品介绍
- 功能介绍
- 典型场景
- 客户案例
- 产品Demo
直播回放:扫描文章底部二维码加入钉群观看回放
一、Databricks 数据洞察产品介绍
1、 Databricks 公司简介
2、 什么是阿里云 Databricks 数据洞察产品
01\\ Databricks 公司简介

① ApacheSpark 创始公司,也是 Spark 的最大代码贡献者,Spark 技术生态背后的商业公司。
在2013年,由加州大学伯克利分校 AMPLab 的创始团队 ApacheSpark 的创建者所成立。
② 核心产品和技术,主导和推进 Spark 开源生态
ApacheSpark、DeltaLake、Koalas 、MLFlow、OneLakehousePlatform
③ 公司定位
- Databricksis the Data + AI company,为客户提供数据分析、数据工程、数据科学和人工智能方面的服务,一体化的 Lakehouse 架构
- 开源版本 VS 商业版本:公司绝大部分技术研发资源投入在商业化产品
- 多云策略,与顶级云服务商合作,提供数据开发、数据分析、机器学习等产品,Data+AI 一体化分析平台
④ 市场地位
- 科技独角兽,行业标杆,领导Spark整体技术生态的走向及风向标
- 2021年最受期待的科技上市公司
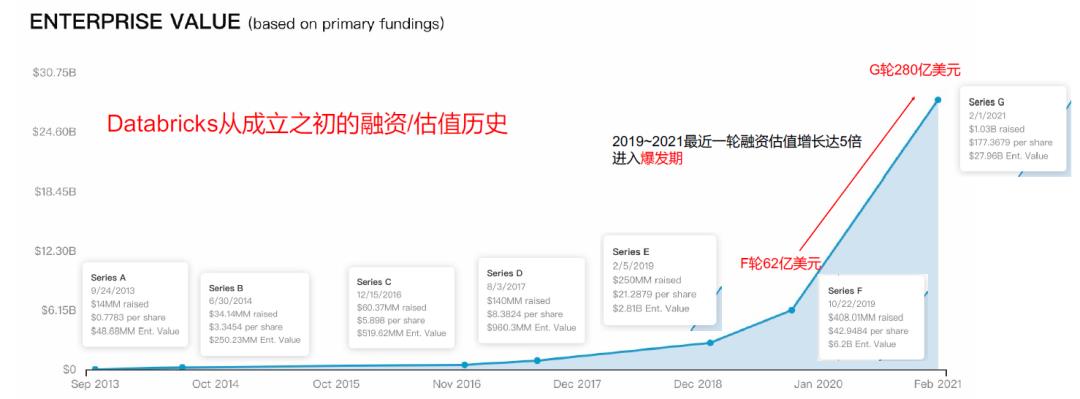
02\\ Databricks 公司估值及融资历史
(来源 Databricks 官网)
① 2019年10月G轮,估值 $ 6.2 Billion
② 2021年2月初F轮,估值 $ 28 Billion
- 本轮融资,三大云服务商 AWS、GCP、MSAzure 以及 Salesforce 都进行了跟投——足以看到云厂商对 Databricks 的发展的重视
- 上市预期:计划 IPO 在2021年——多方预测 Databricks 上市之时其估值可能达到350亿美元,甚至是高达500亿美元
03\\ Databricks 和阿里云联手打造的高品质 Spark 大数据分析平台

- Apache Spark 背后的商业公司,Spark 创始团队,美国科技独角兽
- 在全球拥有5,000多个客户和450多个合作伙伴,品牌认知强
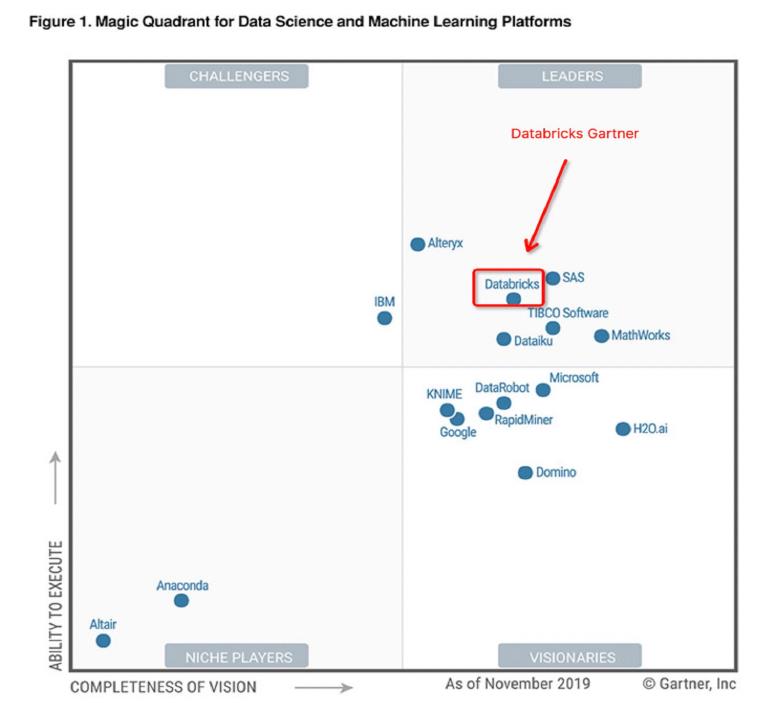
- 2020年,在 Gartner 发布的数据科学和机器学习(DSML)平台魔力象限报告中,位于领导者象限

04\\ Databricks + 阿里云 = Databricks 数据洞察

产品核心:
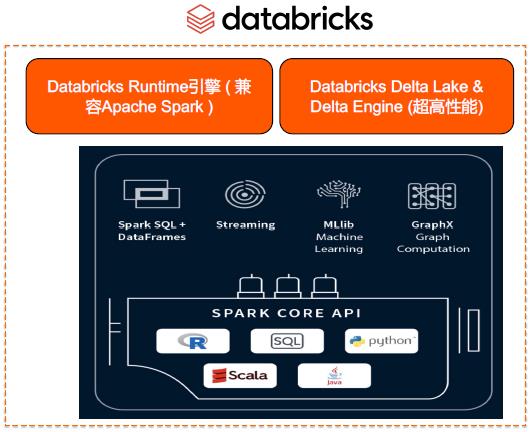
- 基于商业版 Spark 的全托管大数据分析& AI 平台
- 内置商业版 Spark 引擎 Databricks Runtime ,在计算层面提供高效、稳定的保障
- 与阿里云产品集成互通,提供数据安全、动态扩容、监控告警等企业级特性
产品引擎与服务:
- 100% 兼容开源 Spark,经阿里云与 Databricks 联合研发性能优化
- 提供商业化 SLA 保障与7*24小时 Databricks 专家支持服务
DDI 产品能力核心构件
产品关键信息与优势
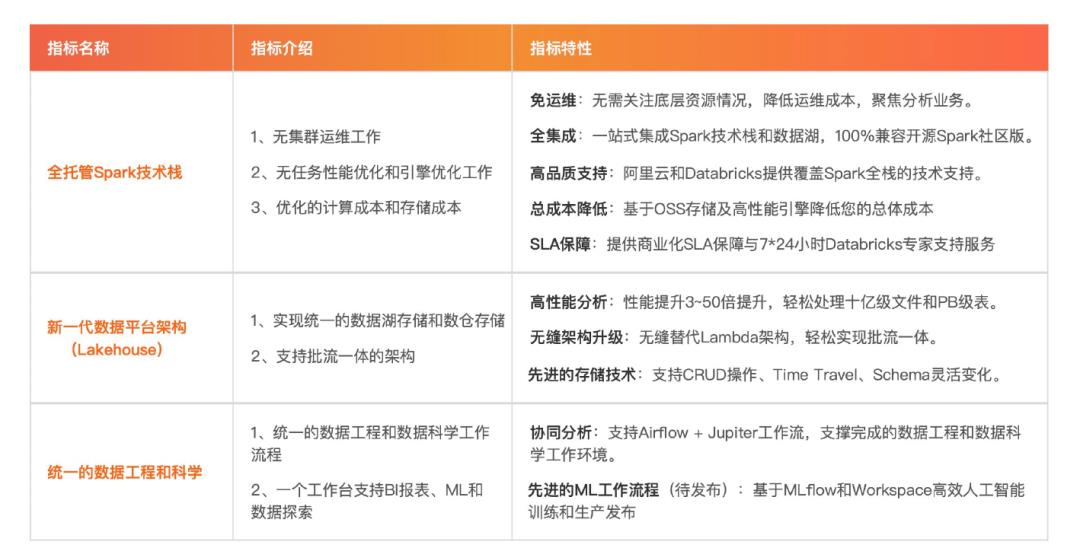
二、DDI 产品功能介绍
1、整体架构
2、引擎能力
3、性能
4、功能
5、成本
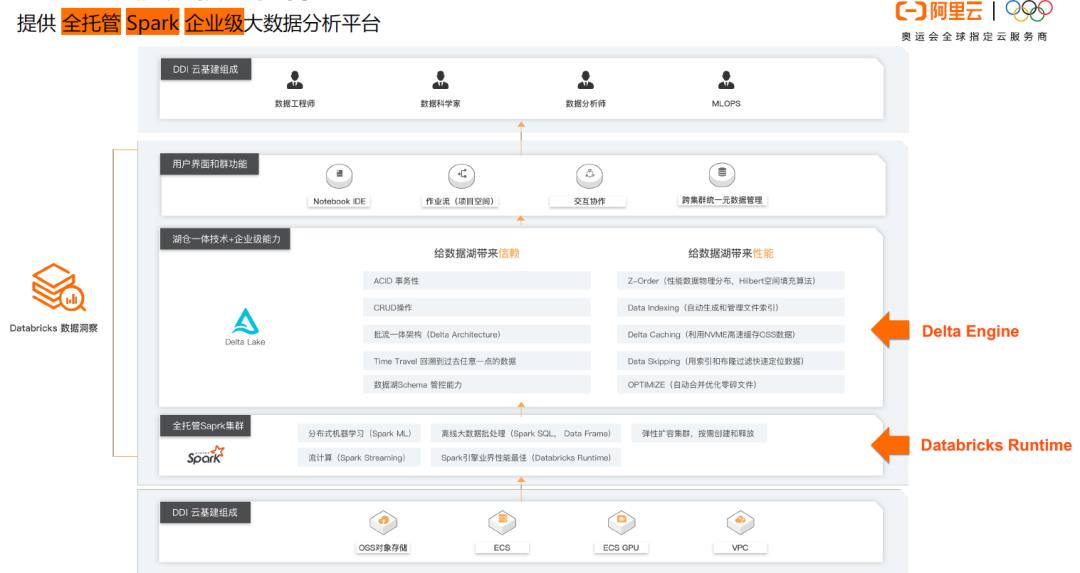
01\\ 阿里云 Databricks 数据洞察 (DDI) 架构
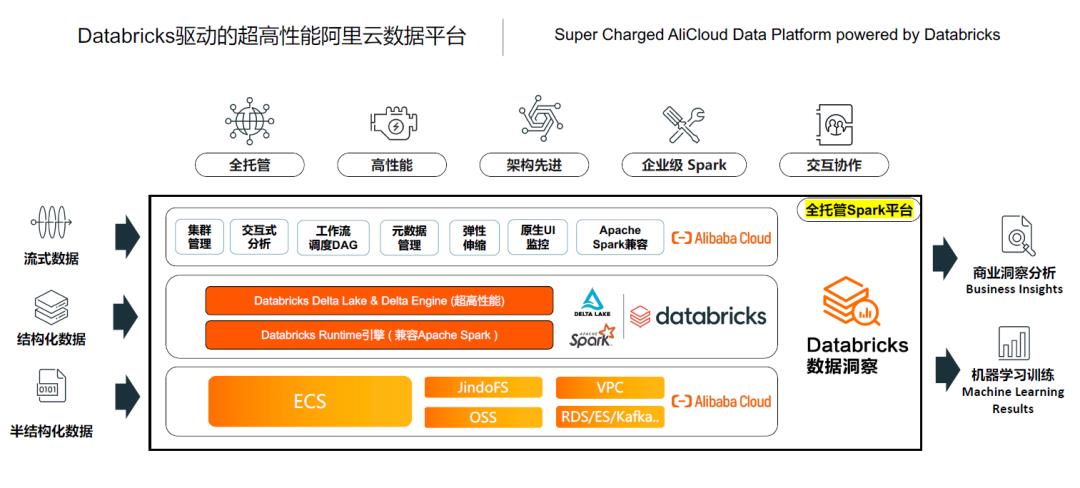
02\\ 引擎:企业级性能优化,提升计算引擎效率和数据读写效率
企业级高性能、稳定性、可靠性
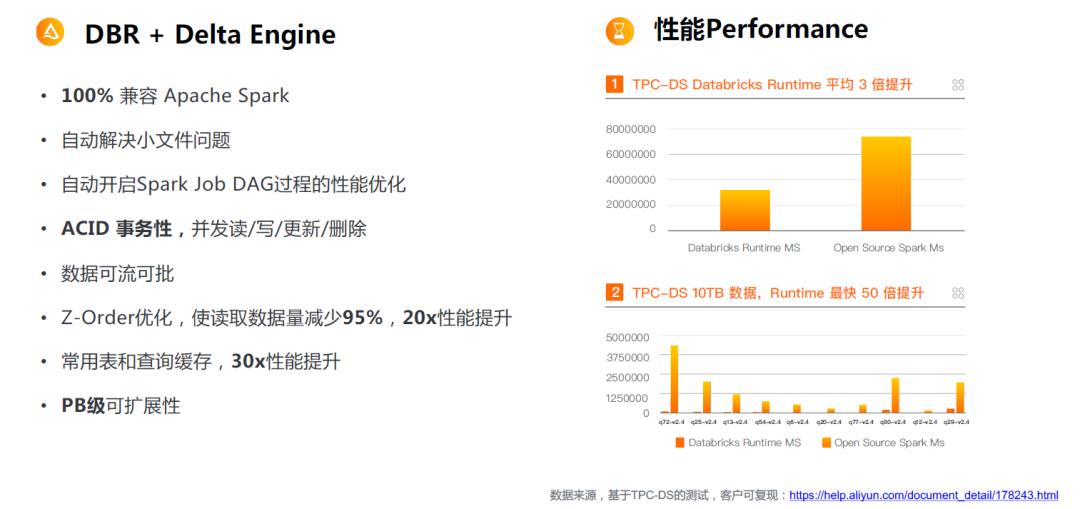
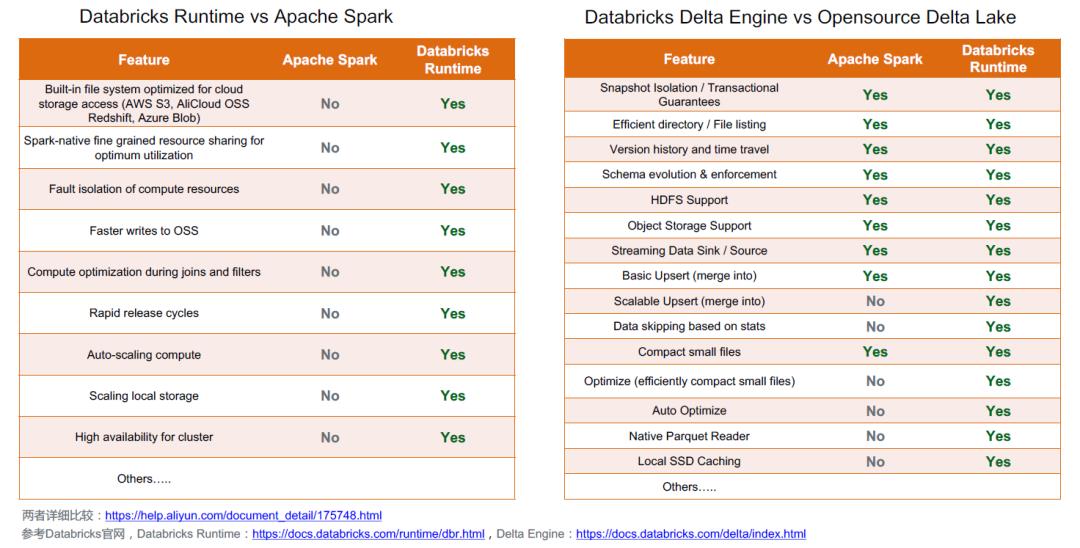
03\\ 企业级 Databricks Runtime vs 社区版 Open Source Spark
04\\ 基于计算存储分离的架构,HDFS vs OSS 成本的对比

05\\ 基于 JindoFS 进行 OSS 访问优化加速,优化数据访问性能
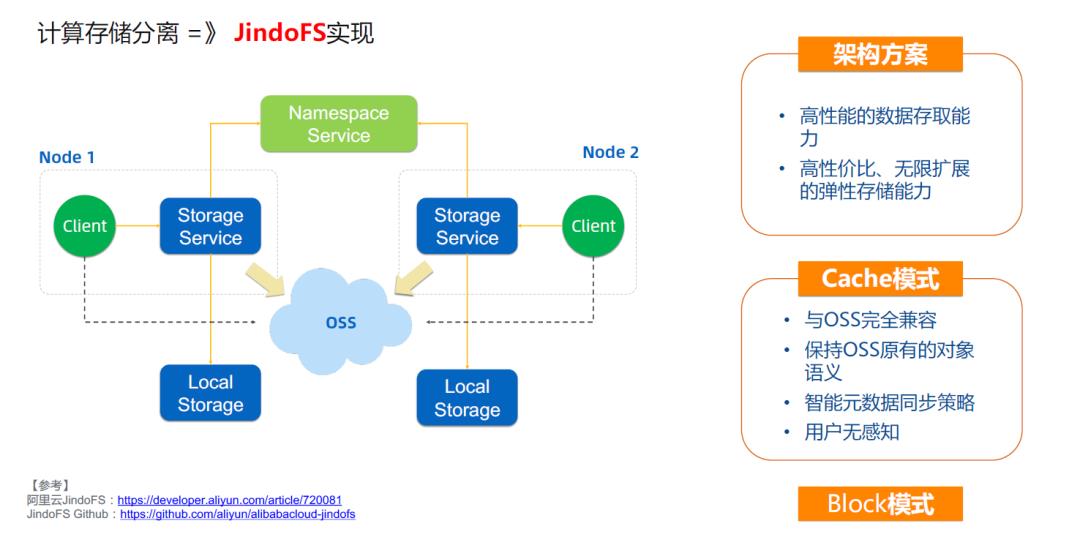
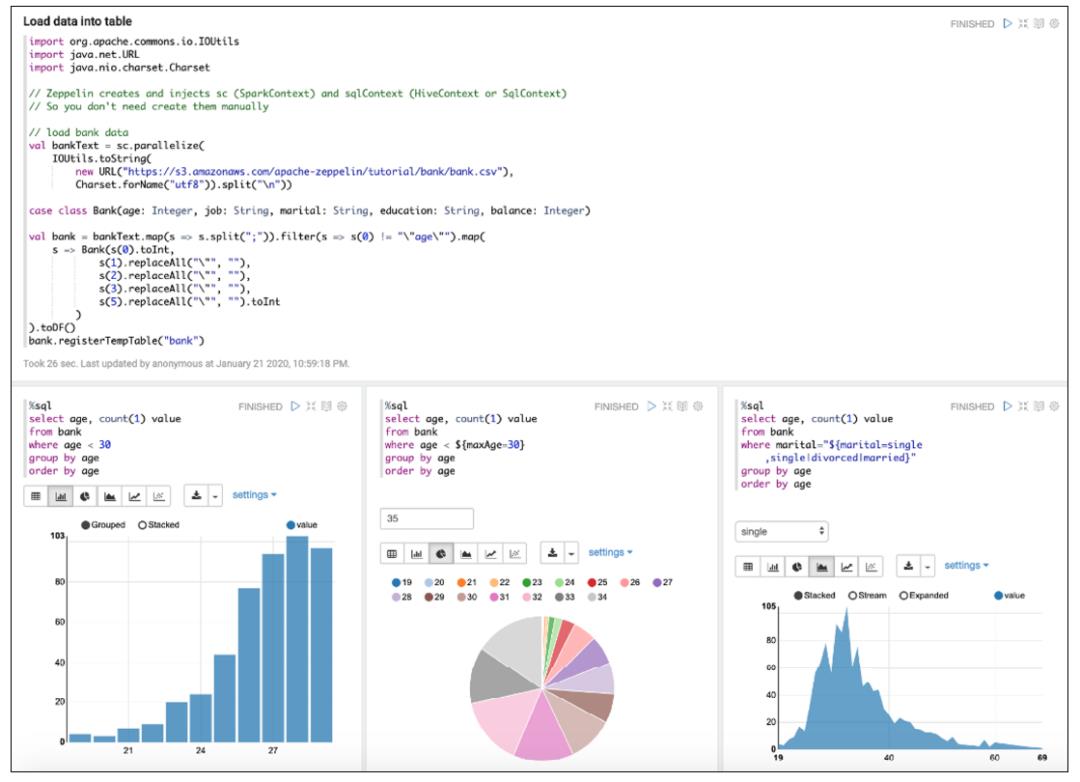
06\\ 交互式分析 Notebook ,聚集数据
优化的 Apache Zeppelin
- 多语言支持
- Scala、Python、Spark SQL、R
- 交互式分析
- 数据可视化
- 集成调度能力
- 一站式开发平台
- 多用户协作开发
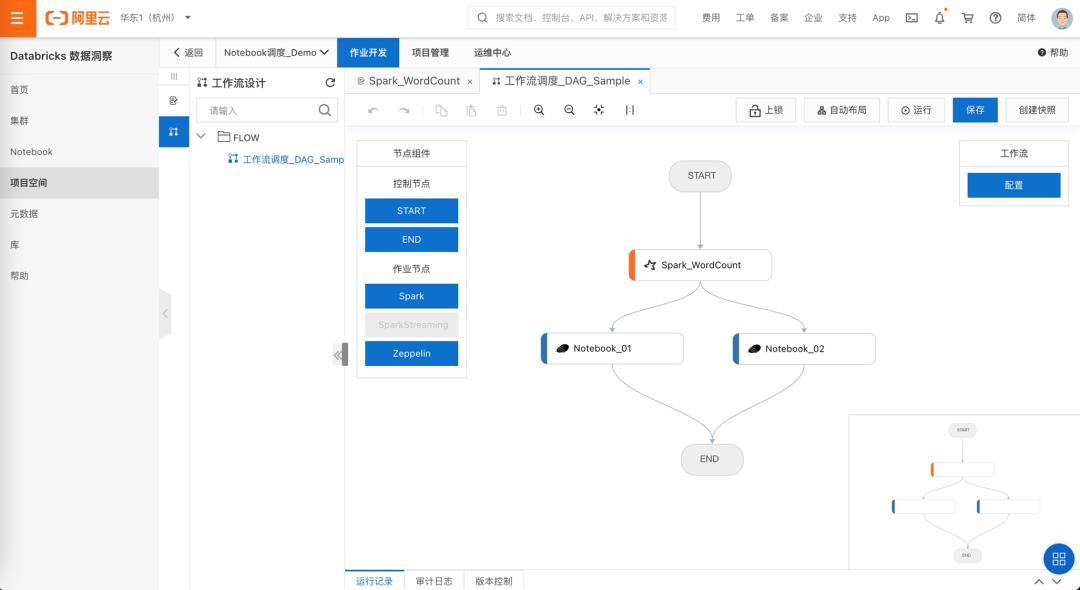
07\\ 数据开发作业提交 & 工作流调度
- 支持 jar 包提交作业及作业调度能力
- 支持 Spark/Spark Streaming/Notebook
- 不同作业类型工作流混合调度
- 支持调度运维、审计日志、版本控制等
08\\ 丰富的数据源支持

09\\ 元数据管理
三种元数据选择的方式

三、典型场景
1、客户存在的痛点问题及 DDI 如何解决
2、Lambda 架构到批流一体架构
3、Lakehouse 架构的演进
4、DDI 在阿里云中产品的组合
01\\ 开源大数据平台客户普遍存在的痛点问题

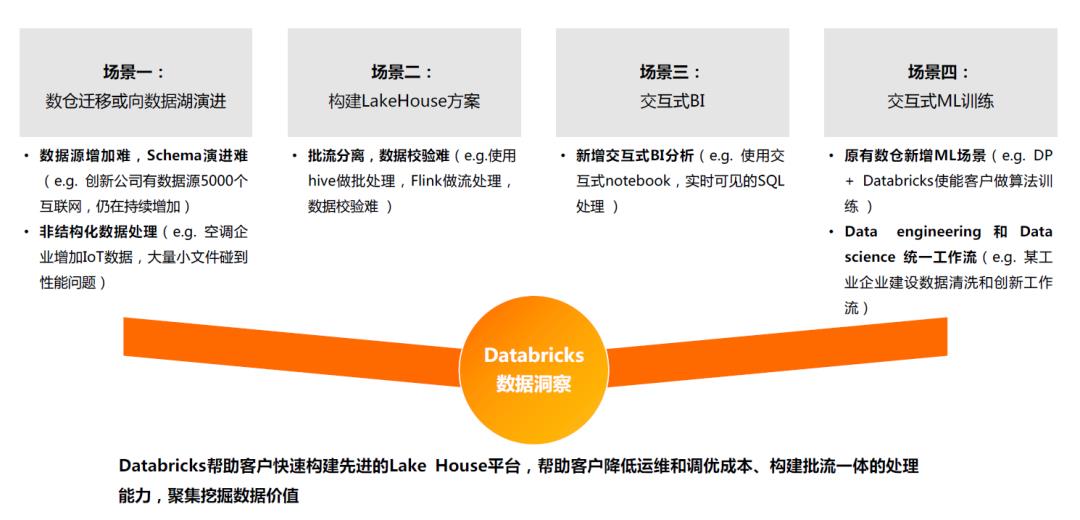
02\\ Databricks 数据洞察在四大场景帮助客户提升生产效率
03\\ Delta Lake 的项目背景以及要解决的问题
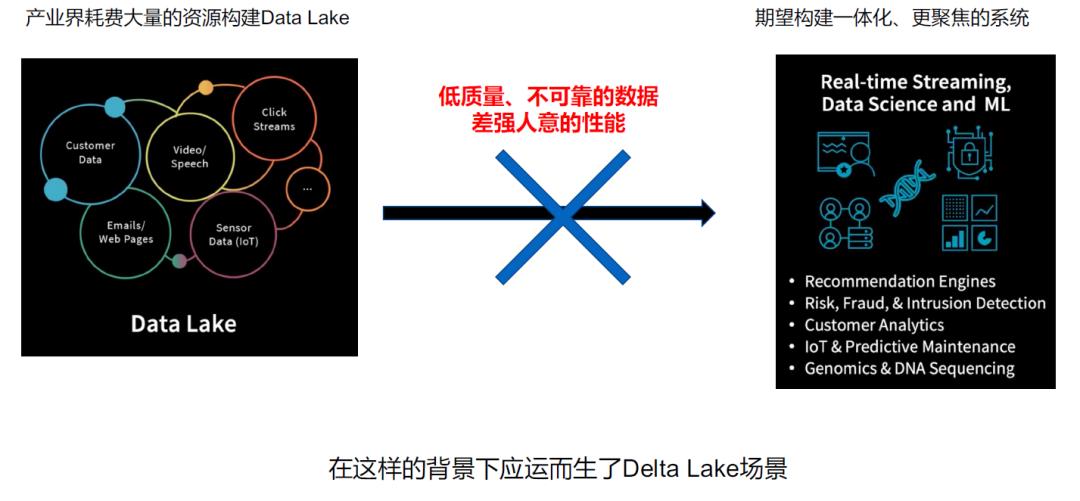
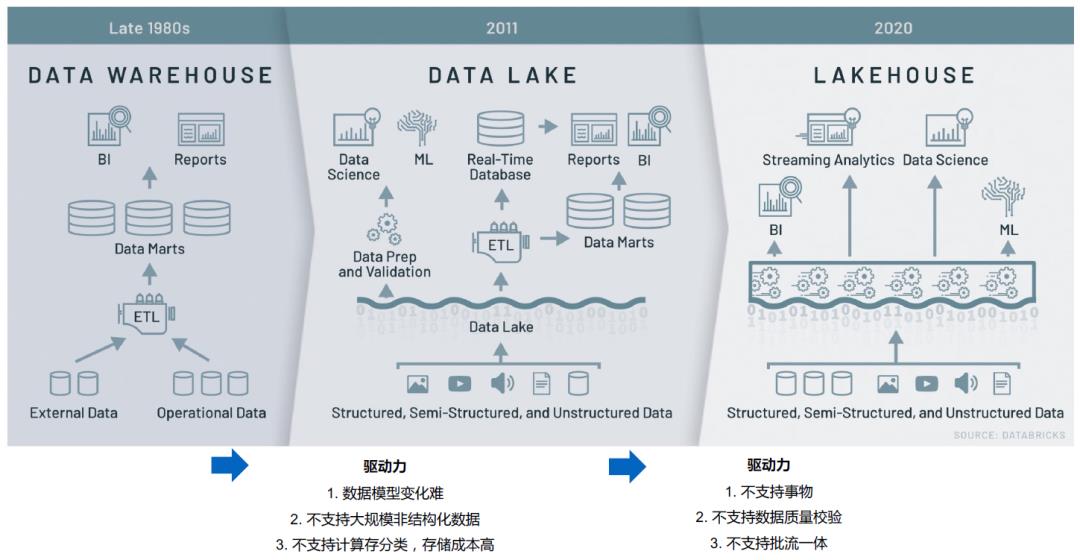
04\\ 大数据发展进入 Lake House 时代
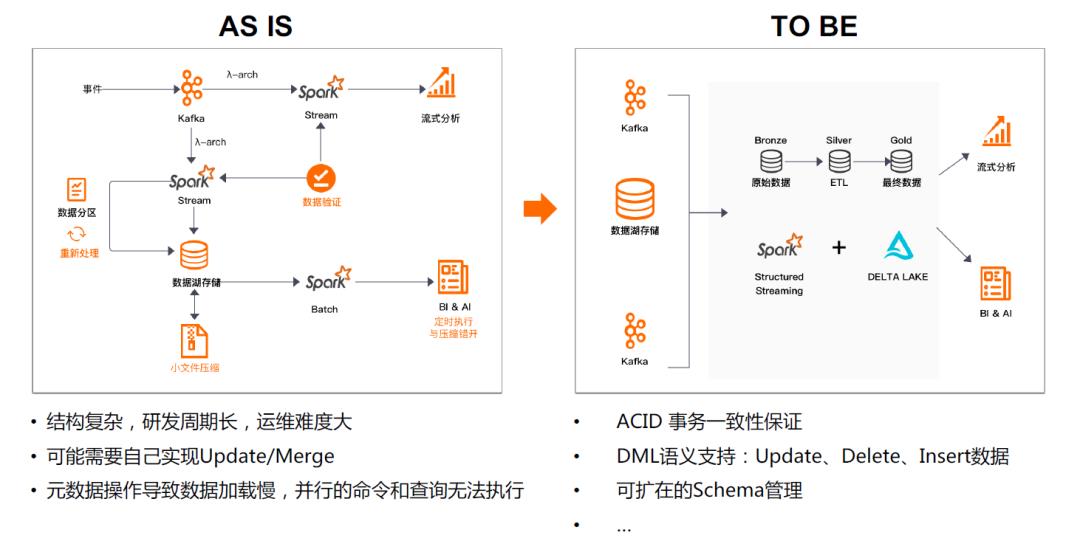
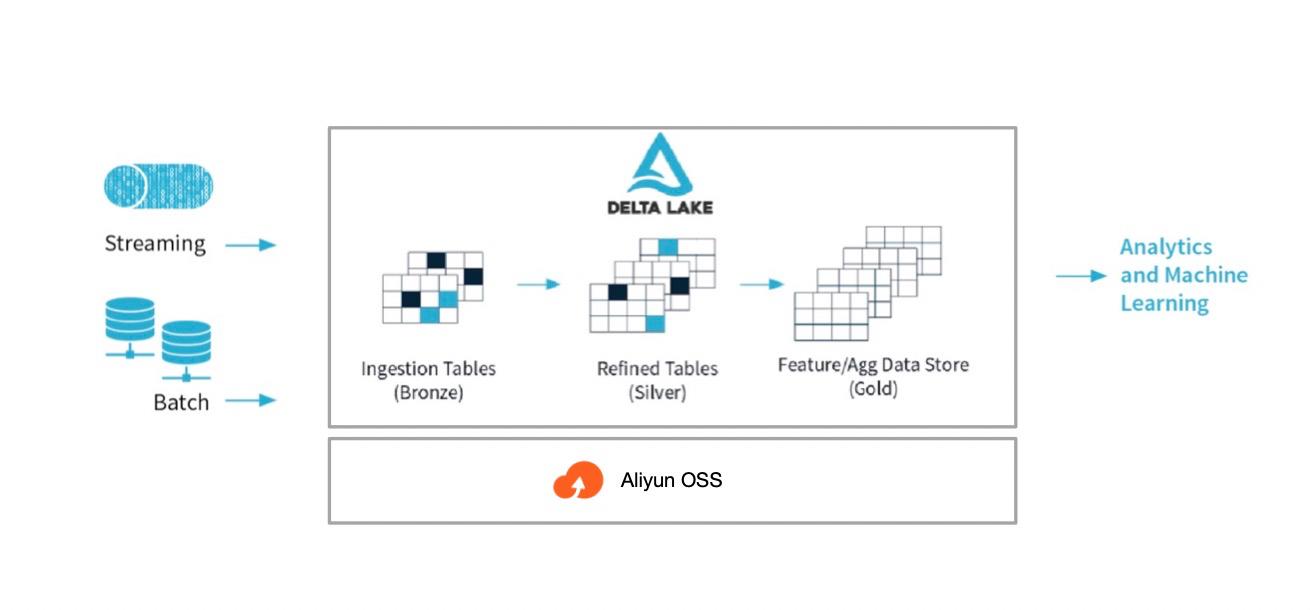
05\\ 使用 DDI 构建批流一体数仓,简化复杂架构
06\\ DDI 在阿里云产品中的组合
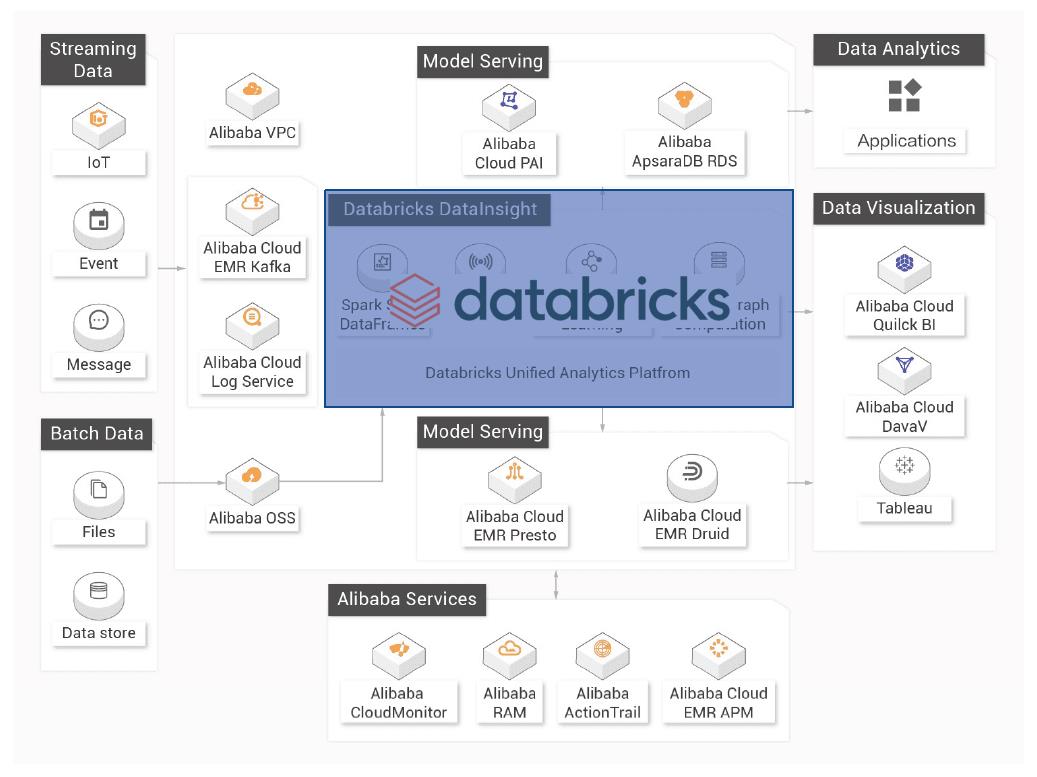
07\\ Databricks 数据洞察典型架构
DDI 与阿里云产品深度集成(典型场景)
数据获取
- 接收实时产生的流式数据和外部云存储上批量数据。
数据 ETL
- 持续高效地处理增量数据,支持数据的回滚和删改,提供 ACID 事务性保障。
BI报表数据分析 & 交互式分析
- 支持 Ad hoc 查询,Notebook 可视化分析,无缝对接多种BI分析工具。
AI数据探索
- 支持机器学习,Mllib 等 Spark 生态 AI 场景。
上下游网络打通
- 如上游对接 Kafka、OSS、EMR HDFS 等等,下游承接 Elasticsearch、RDS、OSS 存储等。
四、典型场景客户案例介绍
1、基智科技(STEPONE)自建上云案例
2、工业制造头部公司数据分析案例
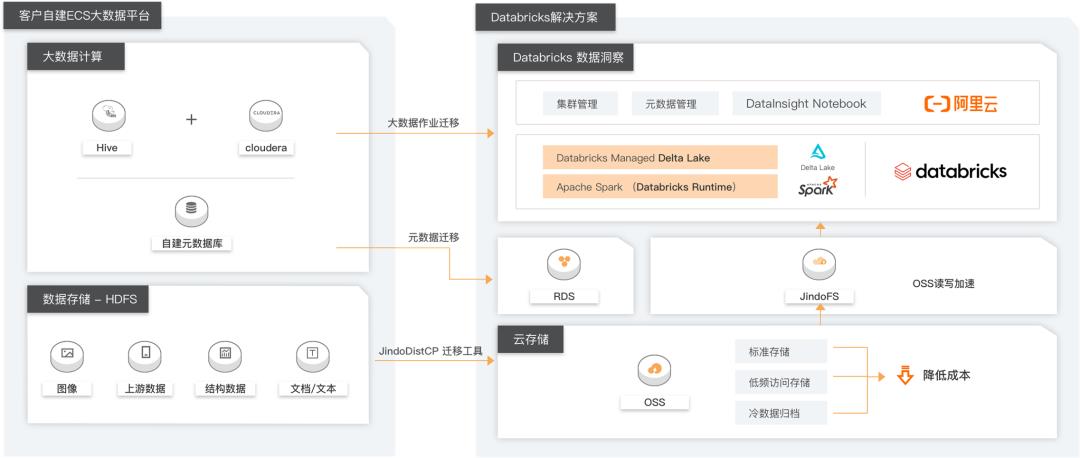
客户案例 01:基智科技(STEPONE)Databricks 上云迁移
本架构描述利用 Databricks 数据洞察 解决客户大数据计算问题:
- 数据存储:自建 Hive数仓-》OSS (降低存储成本,同时做计算存储分离)
- 大数据分析:自建 CDH -》Databricks 数据洞察(全托管 Spark ,高性能 Runtime 引擎,Notebook 交互式分析,工作流 DAG 调度, Python 库的安装方便等)
- 元数据:自建 CDH -》RDS mysql 自建元数据库或使用 DDI 统一元数据库
- 数据迁移:使用 DistCp 或 JindoDistCp 将数据迁移到 OSS,数据结果同步继续使用Sqoop 定时任务
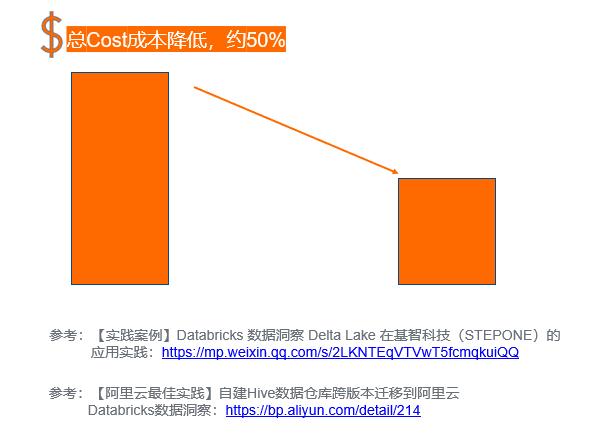
客户成本收益分析
- 全托管 Spark 集群免运维,节省人力成本(省1运维+ 1大数据,此外免去性能调优)
- 相比自建机器资源多了3倍,此外算上 Databricks Runtime 相比开源 spark 来说(预估3倍),整体性能提升9倍
- Notebook 交互式分析+ DAG 工作流调度,提升数据开发/分析体验
- 技术方案统一,计算存储分离方案 OSS 存储节省客户存储成本,并为以后数据湖、多计算架构铺路
- Delta Lake 解决了客户增量数据更新的问题
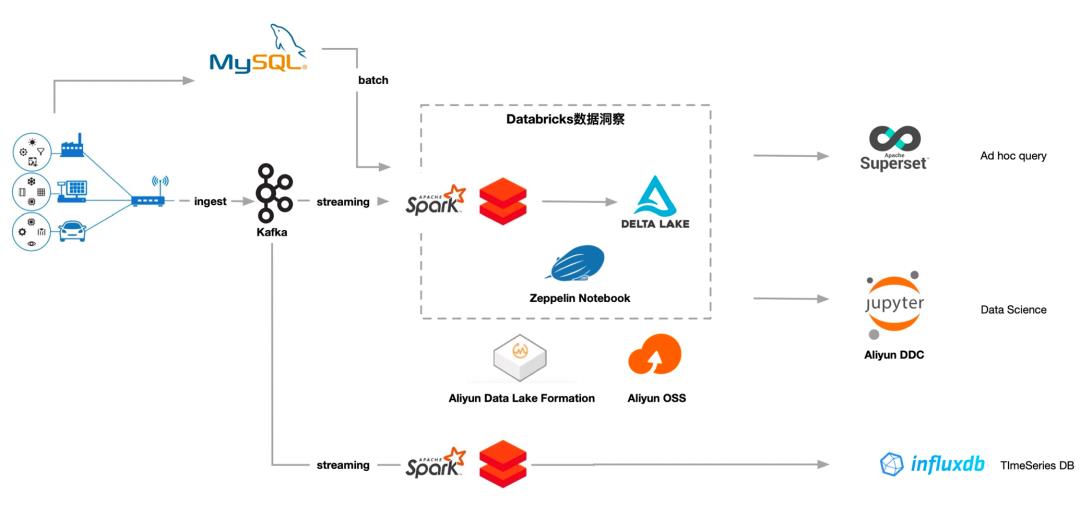
客户案例 02:工业制造头部空调公司– 大数据分析方案架构
- 数据收集/存储: 接收实时产生的流式数据和外部云存储上批量数据
- 数据 ETL:持续高效地处理增量数据,支持数据的回滚和删改,提供 ACID 事务性保障
- BI数据分析&交互式分析: 支持查询,Notebook 可视化分析,无缝对接多种BI分析工具
- 数据科学:支持机器学习/深度学习
- ⽣态对接:如上游对接 Kafka、OSS、EMR HDFS 等等,下游承接 Elasticsearch、RDS、OSS 存储等
本文为阿里云原创内容,未经允许不得转载。
以上是关于超详攻略!Databricks 数据洞察 - 企业级全托管 Spark 大数据分析平台及案例分析的主要内容,如果未能解决你的问题,请参考以下文章
实践案例Databricks 数据洞察 Delta Lake 在基智科技(STEPONE)的应用实践
企业版Spark Databricks + 企业版Kafka Confluent 联合高效挖掘数据价值