企业版Spark Databricks + 企业版Kafka Confluent 联合高效挖掘数据价值
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了企业版Spark Databricks + 企业版Kafka Confluent 联合高效挖掘数据价值相关的知识,希望对你有一定的参考价值。
简介:本文介绍了如何使用阿里云的Confluent Cloud和Databricks构建数据流和LakeHouse,并介绍了如何使用Databricks提供的能力来挖掘数据价值,使用Spark MLlib构建您的机器学习模型。
前提条件
- 已注册阿里云账号,详情请参见阿里云账号注册流程
- 已开通 Databricks 数据洞察服务
- 已开通 OSS 对象存储服务
- 已开通 Confluent 流数据服务
创建Databricks集群 & Confluent集群
- 登录Confluent管理控制台,创建Confluent集群,并开启公网服务
- 登录Databricks管理控制台,创建Databricks集群
Databricks Worker节点公网访问
Databricks的worker节点暂时不支持公网访问,为了能访问Confluent的公网地址,请联系Databricks的开发人员添加NAT网关。
案例:出租车数据入湖及分析
出租车和网约车在每天的运行中持续产生行驶轨迹和交易数据,这些数据对于车辆调度,流量预测,安全监控等场景有着极大的价值。
本案例中我们使用纽约市的出租车数据来模拟网约车数据从产生,发布到流数据服务Confluent,通过Databricks Structured Streaming进行实时数据处理,并存储到LakeHouse的整个流程。数据存储到LakeHouse后,我们使用spark和spark sql对数据进行分析,并使用Spark的MLlib进行机器学习训练。
前置准备:
- 创建topic:
登录Confluent的control center,在左侧选中Topics,点击Add a topic按钮,创建一个名为nyc_taxi_data的topic,将partition设置为3,其他配置保持默认。
- 创建OSS bucket:
在和Databricks同一Region的OSS中,创建bucket,bucket命名为:databricks-confluent-integration
进入到Bucket列表页,点击创建bucket按钮
创建好bucket之后,在该bucket创建目录:checkpoint_dir和data/nyc_taxi_data两个目录 - 收集url,用户名,密码,路径等以便后续使用a。
- confluent集群ID:在csp的管控界面,集群详情页获取
-

- Confluent Control Center的用户名和密码
- 路径:
- Databricks Structured Streaming的checkpoint存储目录
- 采集的数据的存储目录
下面是我们后续会使用到的一些变量:
# 集群管控界面获取 confluent_cluster_id = "your_confluent_cluster_id" # 使用confluent集群ID拼接得到 confluent_server = "rb-confluent_cluster_id.csp.aliyuncs.com:9092" control_center_username = "your_confluent_control_center_username" control_center_password = "your_confluent_control_center_password" topic = "nyc_taxi_data" checkpoint_location = "oss://databricks-confluent-integration/checkpoint_dir" taxi_data_delta_lake = "oss://databricks-confluent-integration/data/nyc_taxi_data"
数据的产生
在本案例中,我们使用Kaggle上的NYC出租车数据集来模拟数据产生。
- 我们先安装confluent的python客户端,其他语言的客户端参考confluent官网
pip install confluent_kafka
- 构造用于创建Kafka Producer的基础信息,如:bootstrap-server,control center的username,password等
conf =
'bootstrap.servers': confluent_server,
'key.serializer': StringSerializer('utf_8'),
'value.serializer': StringSerializer('utf_8'),
'client.id': socket.gethostname(),
'security.protocol': 'SASL_SSL',
'sasl.mechanism': 'PLAIN',
'sasl.username': control_center_username,
'sasl.password': control_center_password
- 创建Producer:
producer = Producer(conf)
- 向Kafka中发送消息(模拟数据的产生):
with open("/Path/To/train.csv", "rt") as f:
float_field = ['fare_amount', 'pickup_longitude', 'pickup_latitude',
'dropoff_longitude', 'dropoff_latitude']
for row in reader:
i += 1
try:
for field in float_field:
row[field] = float(row[field])
row['passenger_count'] = int(row['passenger_count'])
producer.produce(topic=topic, value=json.dumps(row))
if i % 1000 == 0:
producer.flush()
if i == 200000:
break
except ValueError: # discard null/NAN data
continue
Kafka中的partition和offset
在使用spark读取Kafka中的数据之前,我们回顾一下Kafka中的概念:partition和offset
- partition:kafka为了能并行进行数据的写入,将每个topic的数据分为多个partition,每个partition由一个Broker负责,向partition写入数据时,负责该partition的Broker将消息复制给它的follower
- offset:Kafka会为每条写入partition里的消息进行编号,消息的编号即为offset

我们在读取Kafka中的数据时,需要指定我们想要读取的数据,该指定需要从两个维度:partition的维度 + offset的维度。
- Earliest:从每个partition的offset 0开始读取和加载
- Latest:从每个partition最新的数据开始读取
- 自定义:指定每个partition的开始offset和结束offset
- 读取topic1 partition 0 offset 23和partition 0 offset -2之后的数据:
""""topic1":"0":23,"1":-2"""
除了指定start offset,我们还可以通过endingOffsets参数指定读取到什么位置为止。
将数据存储到LakeHouse:Spark集成Confluent
理解上述概念后,Databricks和Confluent的集成非常简单,只需要对spark session的readStream参数进行简单的设置就可以将Kafka中的实时流数据转换为Spark中的Dataframe:
lines = (spark.readStream
# 指定数据源: kafka
.format("kafka")
# 指定kafka bootstrap server的URL
.option("kafka.bootstrap.servers", confluent_server)
# 指定订阅的topic
.option("subscribe", topic)
# 指定想要读取的数据的offset,earliest表示从每个partition的起始点开始读取
.option("startingOffsets", "earliest")
# 指定认证协议
.option("kafka.security.protocol", "SASL_SSL")
.option("kafka.sasl.mechanism", "PLAIN")
# 指定confluent的用户名和密码
.option("kafka.sasl.jaas.config",
f"""org.apache.kafka.common.security.plain.PlainLoginModule
required username="control_center_username" password="control_center_password";""")
.load())
从kafka中读取的数据格式如下:
root |-- key: binary (nullable = true) |-- value: binary (nullable = true) |-- topic: string (nullable = true) |-- partition: integer (nullable = true) |-- offset: long (nullable = true) |-- timestamp: timestamp (nullable = true) |-- timestampType: integer (nullable = true)
由于key和value都是binary格式的,我们需要将value(json)由binary转换为string格式,并定义schema,提取出Json中的数据,并转换为对应的格式:
schema = (StructType().add('key', TimestampType())
.add('fare_amount', FloatType())
.add('pickup_datetime', TimestampType())
.add('pickup_longitude', FloatType())
.add('pickup_latitude', FloatType())
.add('dropoff_longitude', FloatType())
.add('dropoff_latitude', FloatType())
.add('passenger_count', IntegerType())
)
# 将json中的列提取出来
lines = (lines.withColumn('data',
from_json(
col('value').cast('string'), # binary 转 string
schema)) # 解析为schema
.select(col('data.*'))) # select value中的所有列
过滤掉错误,为空,NaN的数据:
lines = (lines.filter(col('pickup_longitude') != 0)
.filter(col('pickup_latitude') != 0)
.filter(col('dropoff_longitude') != 0)
.filter(col('dropoff_latitude') != 0)
.filter(col('fare_amount') != 0)
.filter(col('passenger_count') != 0))
最后,我们将解析出来的数据输出到LakeHouse中,以进行后续的分析和机器学习模型训练:
# lakehouse 的存储格式为 delta
query = (lines.writeStream.format('delta')
.option('checkpointLocation', checkpoint_location)
.option('path', taxi_data_delta_lake).start())
# 执行job,直到出现异常(如果只想执行该Job一段时间,可以指定timeout参数)
query.awaitTermination()
数据分析
我们先将LakeHouse中的数据使用Spark加载进来:
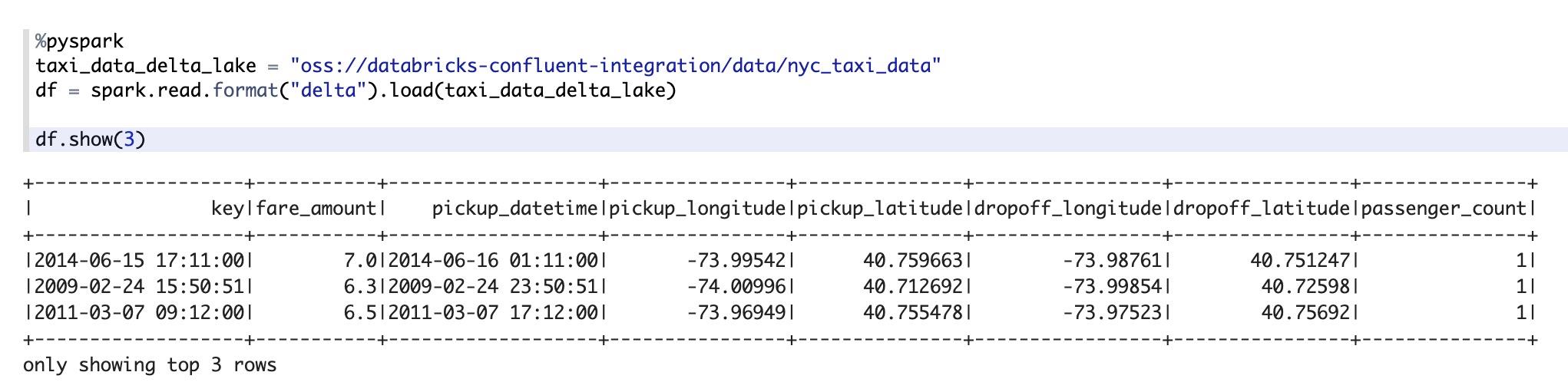
然后,我们对该Dataframe创建一个Table View,并探索fare_amount的分布:


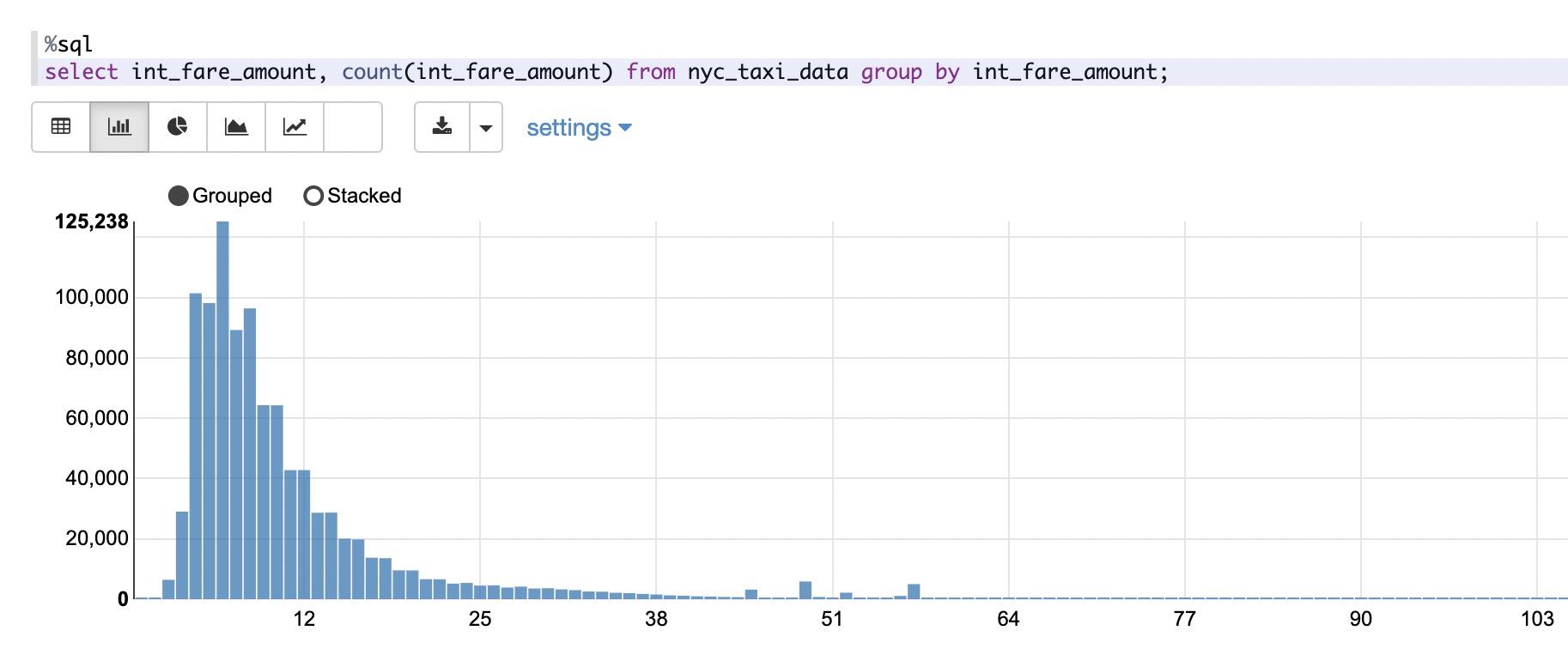
可以看到fare_amount的最小值是负数,这显然是一条错误的数据,我们将这些错误的数据过滤,并探索fare_amount的分布:

然后我们探索价格和年份,月份,星期,打车时间的关系:
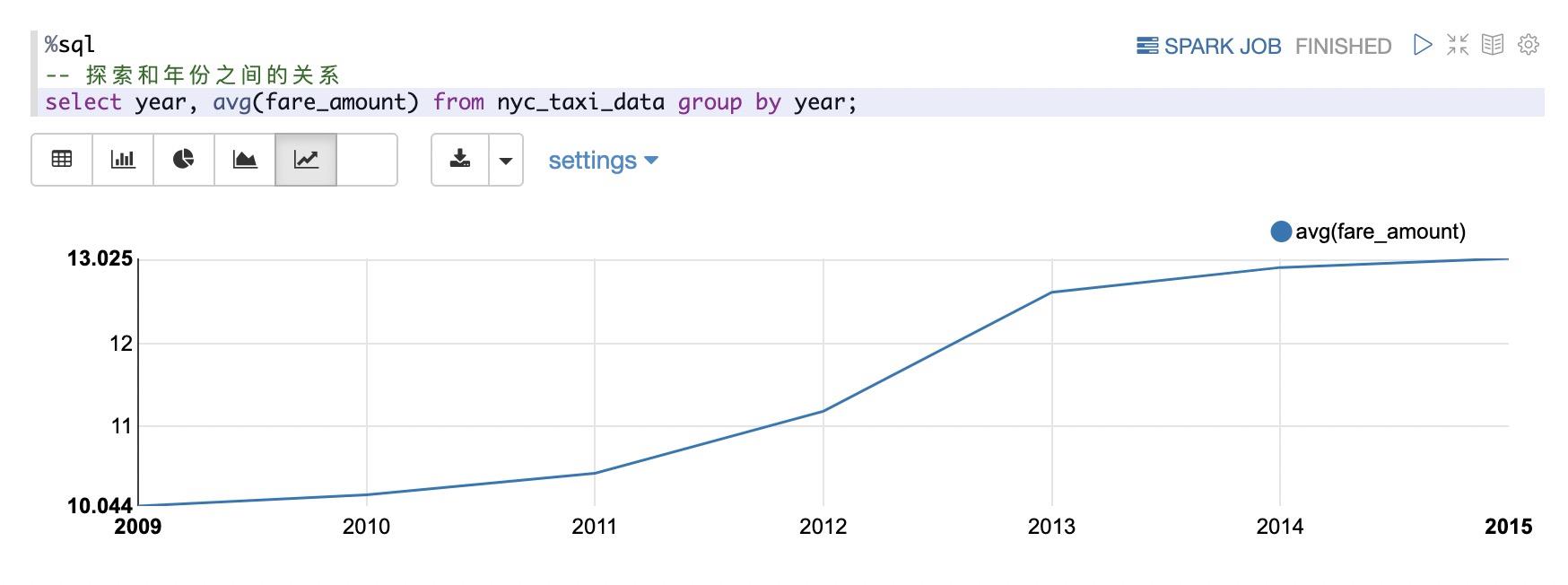
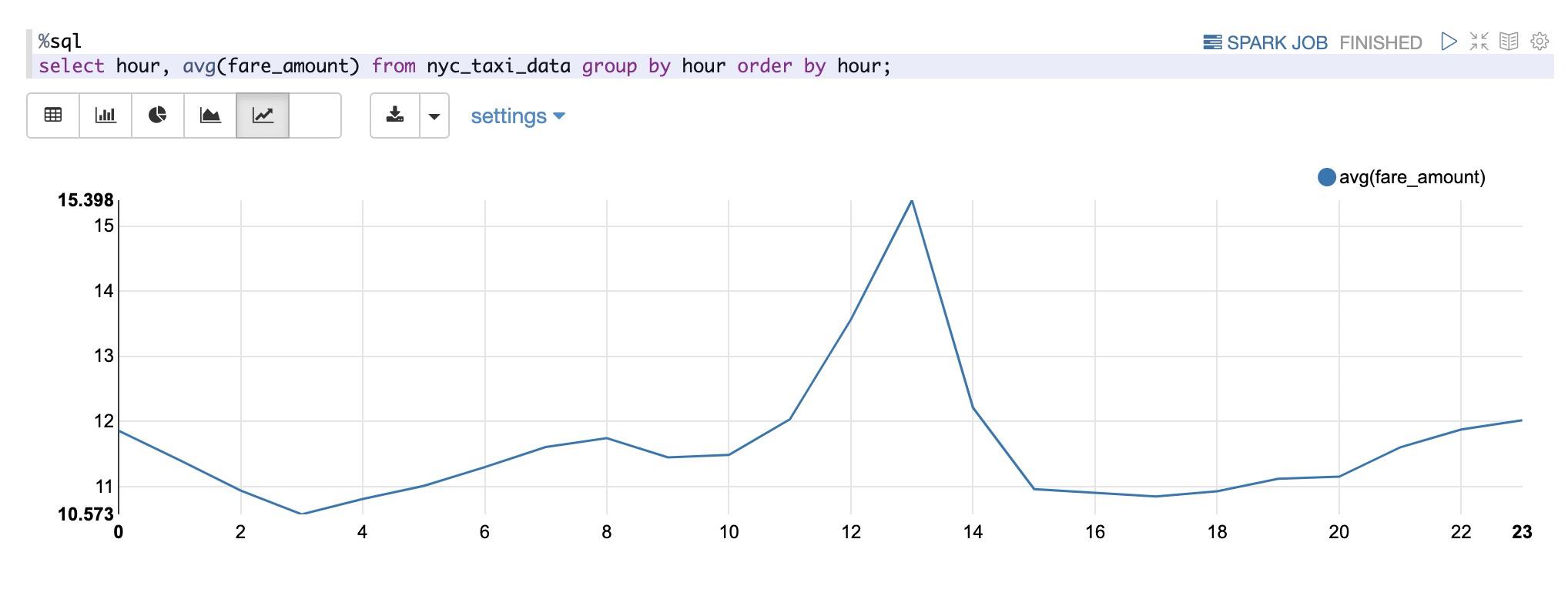
从上面可以看出两点:
- 出租车的价格和年份有很大关系,从09年到15年呈不断增长的态势
- 在中午和凌晨打车比上午和下午打车更贵一些。
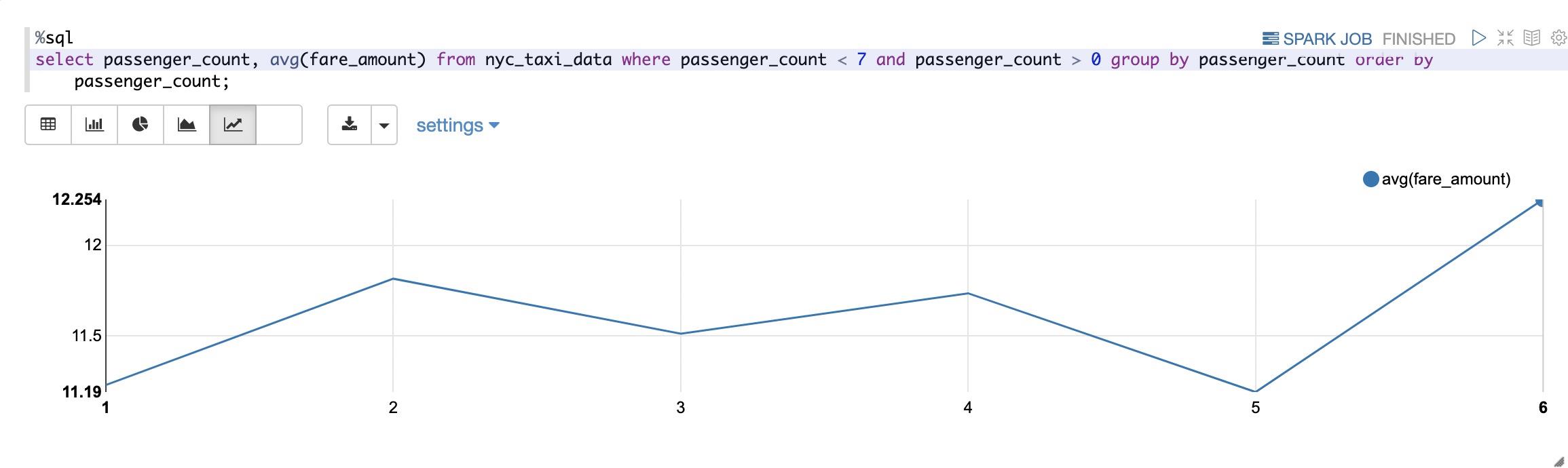
我们再进一步探索价格和乘客数量的关系:
此外,出租车价格的另一个影响因素就是距离,这里我们借助python的geopy包和Spark的UDF来计算给定两个位置的距离,然后再分析费用和距离的关系。
经纬度的范围为[-90, 90],因此,我们第一步是清除错误的数据:

然后,我们增加一列数据:出租车行驶的距离,并将距离离散化,进行后续的分析:


统计打车距离的分布:

从上图可以看出:打车距离分布在区间[0, 15]miles内,我们继续统计在该区间内,打车价格和打车距离的关系:
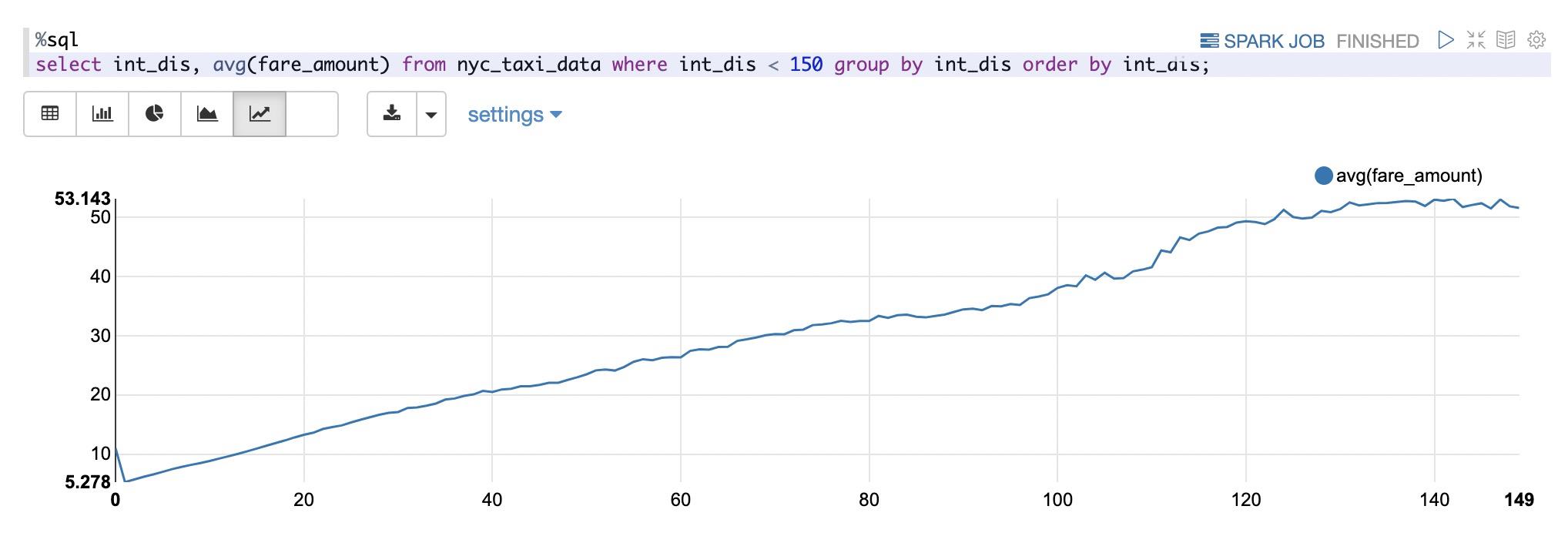
如上图所示:打车价格和打车距离呈现出线性增长的趋势。
机器学习建模
在上一小节的数据分析中,我们已经提取了和出租车相关联的一些特征,根据这些特征,我们建立一个简单的线性回归模型:
打车费用 ~ (年份,打车时间,乘客数,距离)
先将特征和目标值提取出来:

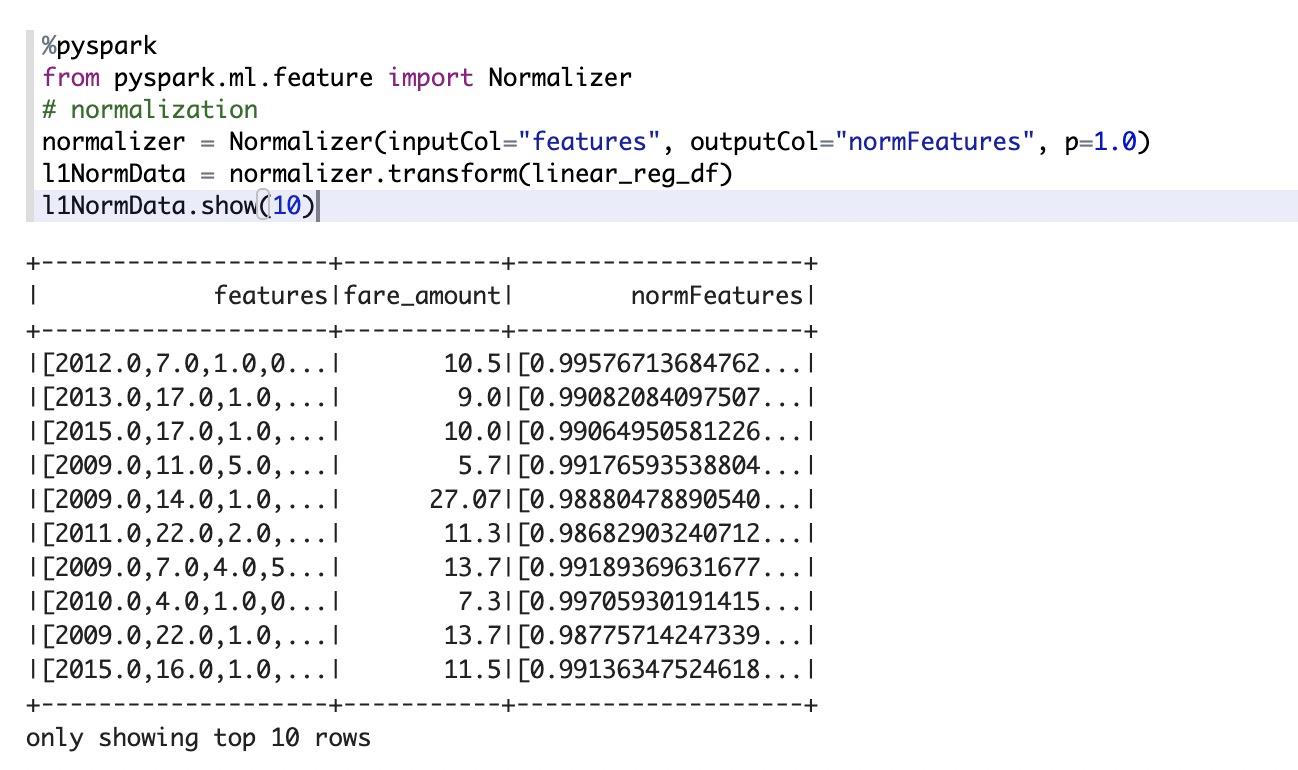
对特征做归一化:
分割训练集和测试集:

建立线性回归模型进行训练:

训练结果统计:

使用Evaluator对模型进行评价:

总结
我们在本文中介绍了如何使用阿里云的Confluent Cloud和Databricks来构建您的数据流和LakeHouse,并介绍了如何使用Databricks提供的能力来挖掘数据价值,使用Spark MLlib构建您的机器学习模型。有了Confluent Cloud和Databricks,您可以轻松实现数据入湖,及时在最新的数据上进行探索,挖掘您的数据价值。欢迎您试用阿里云Confluent和Databricks。
本文为阿里云原创内容,未经允许不得转载。
以上是关于企业版Spark Databricks + 企业版Kafka Confluent 联合高效挖掘数据价值的主要内容,如果未能解决你的问题,请参考以下文章
使用 6.4 版扩展支持(包括 Apache Spark 2.4.5、Scala 2.11)在 azure databricks 上启动集群时出现问题