lstm预测基于lstm实现时间序列数据预测matlab
Posted MatlabQQ1575304183
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了lstm预测基于lstm实现时间序列数据预测matlab相关的知识,希望对你有一定的参考价值。
1. 循环神经网络(RNNs)
人们思考问题往往不是从零开始的。就好像你现在阅读这篇文章一样,你对每个词的理解都会依赖于你前面看到的一些词,而不是把你前面看的内容全部抛弃了,忘记了,再去理解这个单词。也就是说,人们的思维总是会有延续性的。
传统的神经网络是做不到这样的延续性(它们没办法保留对前文的理解),这似乎成了它们一个巨大的缺陷。举个例子,在观看影片中,你想办法去对每一帧画面上正在发生的事情做一个分类理解。目前还没有明确的办法利用传统的网络把对影片中前面发生的事件添加进来帮助理解后面的画面。
但是,循环神经网络可以做到。在RNNs的网络中,有一个循环的操作,使得它们能够保留之前学习到的内容。
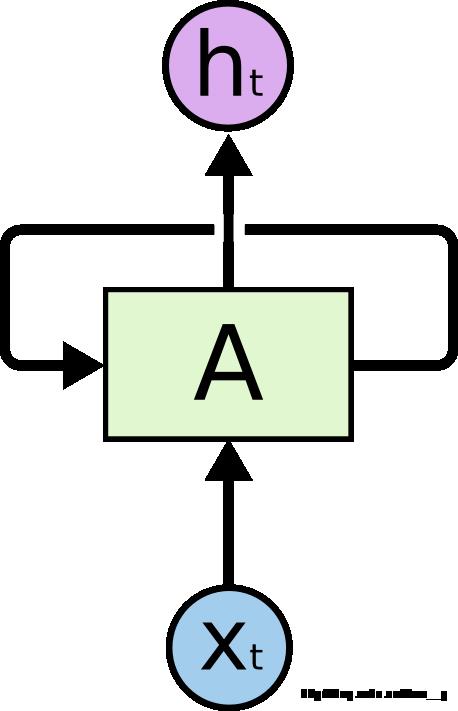 Fig1. RNNs 网络结构
Fig1. RNNs 网络结构
在上图网络结构中,对于矩形块 A 的那部分,通过输入$ x_t (t时刻的特征向量),它会输出一个结果(t时刻的特征向量),它会输出一个结果(t时刻的特征向量),它会输出一个结果 h_t $(t时刻的状态或者输出)。网络中的循环结构使得某个时刻的状态能够传到下一个时刻。(译者注:因为当前时刻的状态会作为下一时刻输入的一部分)
这些循环的结构让 RNNs 看起来有些难以理解。但是,你稍微想一下就会发现,这似乎和普通的神经网络有不少相似之处呀。我们可以把 RNNs 看成是一个普通的网络做了多次复制后叠加在一起组成的。每一网络会把它的输出传递到下一个网络中。我们可以把 RNNs 在时间步上进行展开,就得到下图这样:
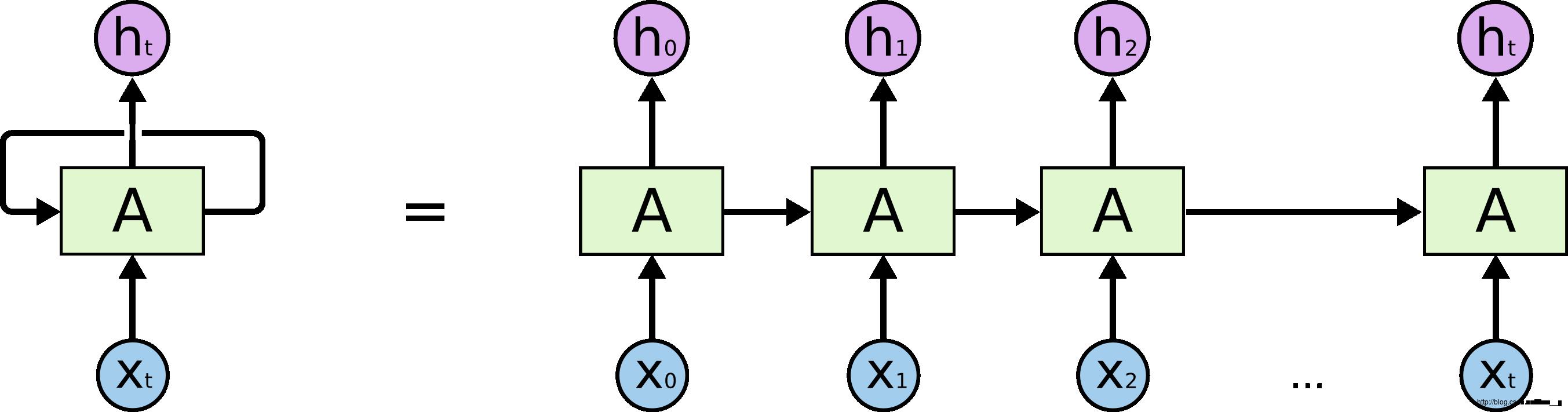 fig2. RNNs 展开网络结构
fig2. RNNs 展开网络结构
从 RNNs 链状的结构很容易理解到它是和序列信息相关的。这种结构似乎生来就是为了解决序列相关问题的。
而且,它们的的确确非常管用!在最近的几年中,人们利用 RNNs 不可思议地解决了各种各样的问题:语音识别,语言模型,翻译,图像(添加)字幕,等等。关于RNNs在这些方面取得的惊人成功,我们可以看 Andrej Karpathy 的博客: The Unreasonable Effectiveness of Recurrent Neural Networks.
RNNs 能够取得这样的成功,主要还是 LSTMs 的使用。这是一种比较特殊的 RNNs,而且对于很多任务,它比普通的 RNNs 效果要好很多很多!基本上现在所使用的循环神经网络用的都是 LSTMs,这也正是本文后面所要解释的网络。
2. 长时期依赖存在的问题
RNNs 的出现,主要是因为它们能够把以前的信息联系到现在,从而解决现在的问题。比如,利用前面的画面,能够帮助我们理解当前画面的内容。如果 RNNs 真的可以做到这个,那么它肯定是对我们的任务有帮助的。但是它真的可以 做到吗,恐怕还得看实际情况呀!
有时候,我们在处理当前任务的时候,只需要看一下比较近的一些信息。比如在一个语言模型中,我们要通过上文来预测一下个词可能会是什么,那么当我们看到“ the clouds are in the ?”时,不需要更多的信息,我们就能够自然而然的想到下一个词应该是“sky”。在这样的情况下,我们所要预测的内容和相关信息之间的间隔很小,这种情况下 RNNs 就能够利用过去的信息, 很容易的实现。
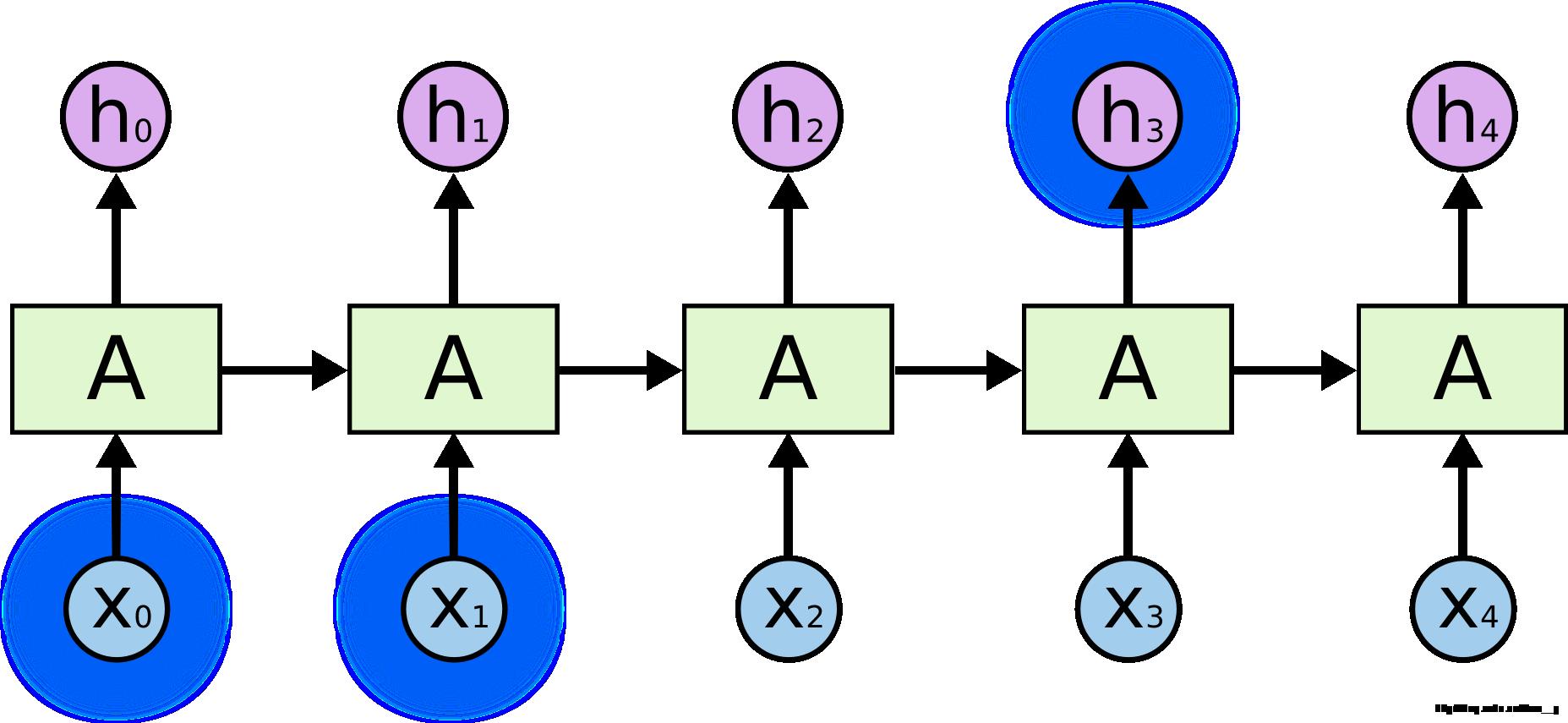 fig2. 短期依赖
fig2. 短期依赖
但是,有些情况是需要更多的上下文信息。比如我们要预测“I grew up in France … (此处省略1万字)… I speak ?”这个预测的词应该是 Franch,但是我们是要通过很长很长之前提到的信息,才能做出这个正确的预测的呀,普通的 RNNs 很难做到这个。
随着预测信息和相关信息间的间隔增大, RNNs 很难去把它们关联起来了。
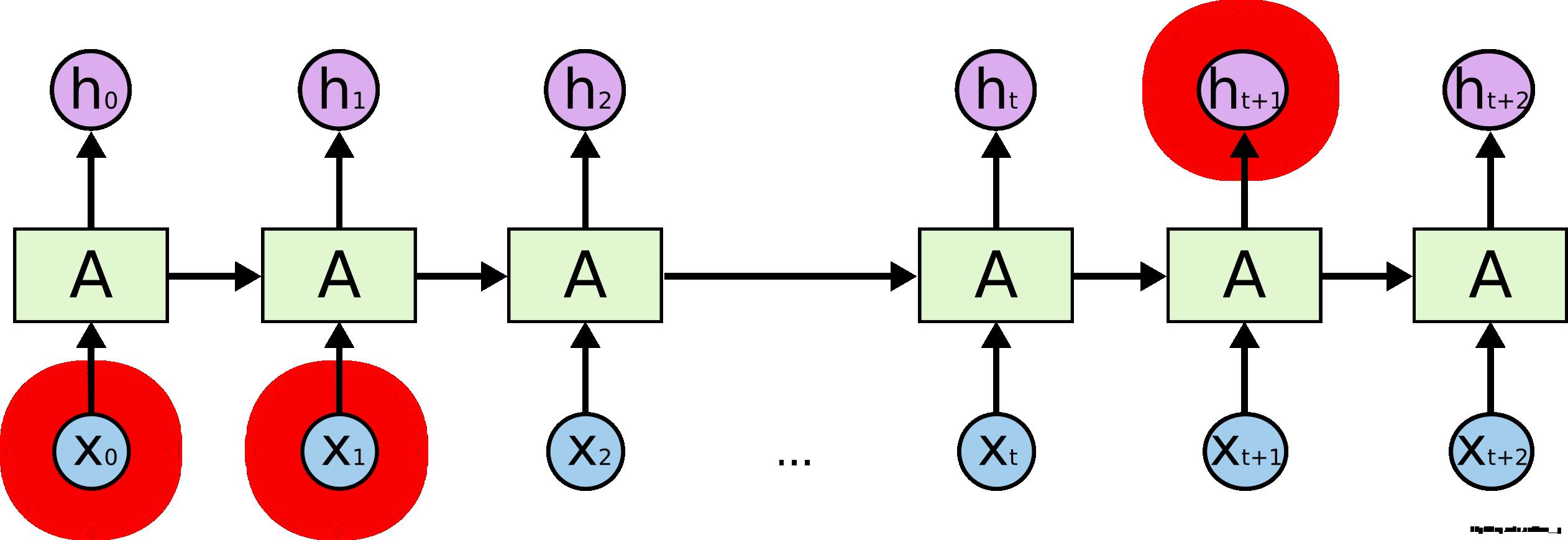 fig3. 长期依赖
fig3. 长期依赖
从理论上来讲,通过选择合适的参数,RNNs 确实是可以把这种长时期的依赖关系(“long-term dependencies”) 联系起来,并解决这类问题的。但遗憾的是在实际中, RNNs 无法解决这个问题。 Hochreiter (1991) [German] 和 Bengio, et al. (1994) 曾经对这个问题进行过深入的研究,发现 RNNs 的确很难解决这个问题。
但是非常幸运,LSTMs 能够帮我们解决这个问题。
3. LSTM 网络
长短期记忆网络(Long Short Term Memory networks) - 通常叫做 “LSTMs” —— 是 RNN 中一个特殊的类型。由Hochreiter & Schmidhuber (1997)提出,广受欢迎,之后也得到了很多人们的改进调整。LSTMs 被广泛地用于解决各类问题,并都取得了非常棒的效果。
明确来说,设计 LSTMs 主要是为了避免前面提到的 长时期依赖 (long-term dependency )的问题。它们的本质就是能够记住很长时期内的信息,而且非常轻松就能做到。
所有循环神经网络结构都是由完全相同结构的(神经网络)模块进行复制而成的。在普通的RNNs 中,这个模块结构非常简单,比如仅是一个单一的 tanh 层。
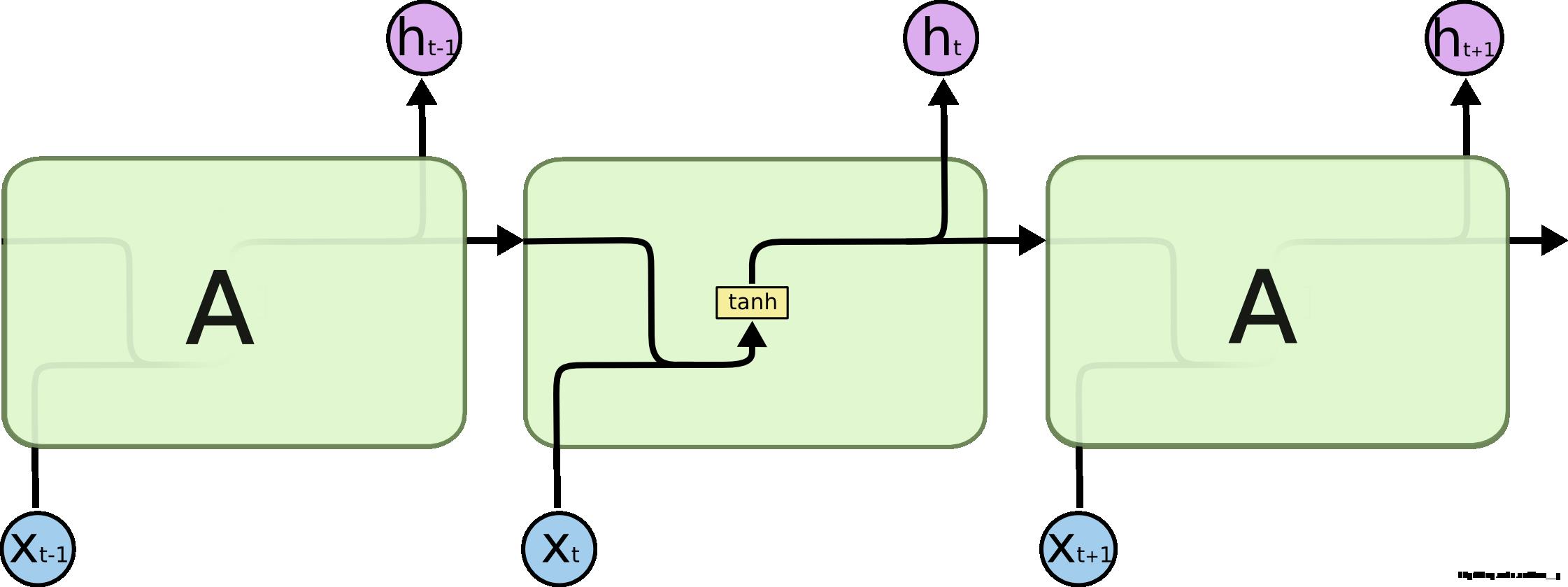 fig4. 普通 RNNs 内部结构
fig4. 普通 RNNs 内部结构
LSTMs 也有类似的结构(译者注:唯一的区别就是中间部分)。但是它们不再只是用一个单一的 tanh 层,而是用了四个相互作用的层。
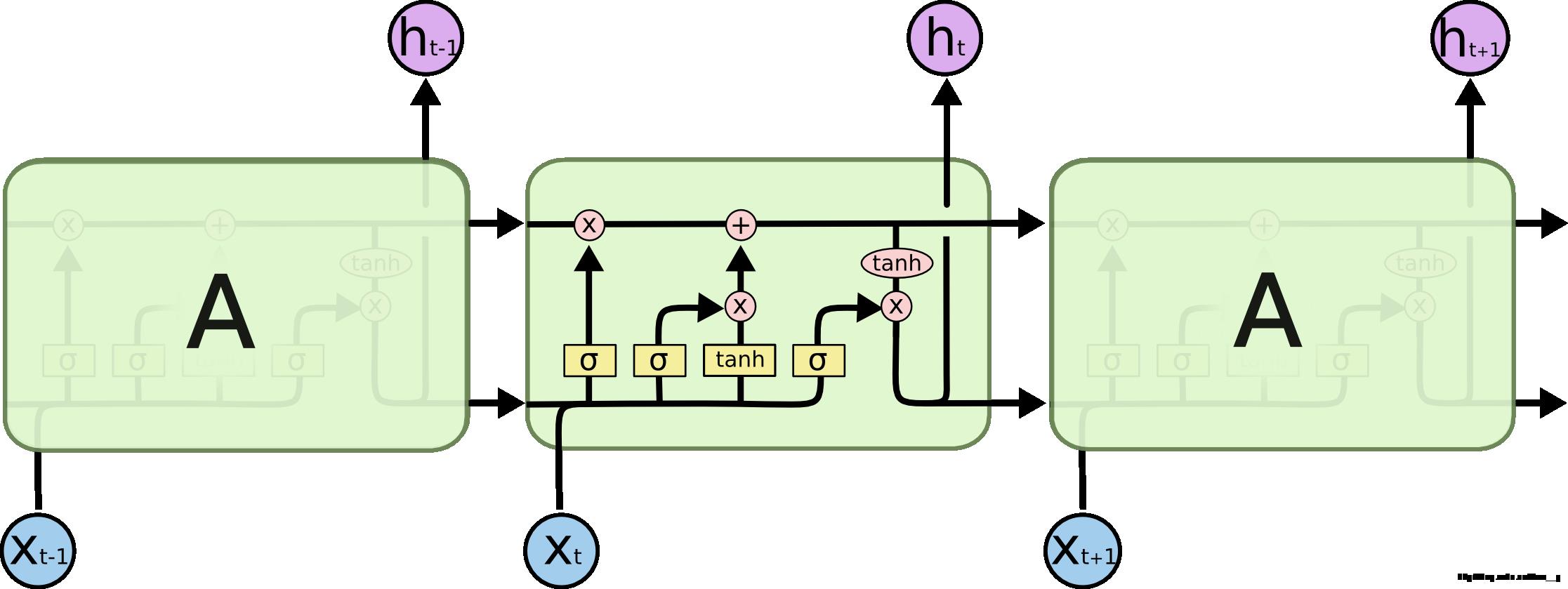 fig5. LSTM 内部结构
fig5. LSTM 内部结构
别担心,别让这个结构给吓着了,下面根据这个结构,我们把它解剖开,一步一步地来理解它(耐心看下去,你一定可以理解的)。现在,我们先来定义一下用到的符号:
 fig6. 符号说明
fig6. 符号说明
在网络结构图中,每条线都传递着一个向量,从一个节点中输出,然后输入到另一个节点中。粉红色的圆圈表示逐点操作,比如向量相加;黄色的矩形框表示的是一个神经网络层(就是很多个神经节点);合并的线表示把两条线上所携带的向量进行合并(比如一个带 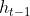 ,另一个带
,另一个带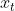 , 那么合并后的输出就是
, 那么合并后的输出就是); 分开的线表示将线上传递的向量复制一份,传给两个地方。
3.1 LSTMs 的核心思想
LSTMs 最关键的地方在于 cell(整个绿色的框就是一个 cell) 的状态 state:结构图上面的那条横穿的水平线。
cell 状态的传输就像一条传送带,向量从整个 cell 中穿过,只是做了少量的线性操作。这种结构能够很轻松地实现信息从整个 cell 中穿过而不做改变。(译者注:这样我们就可以实现了长时期的记忆保留了)
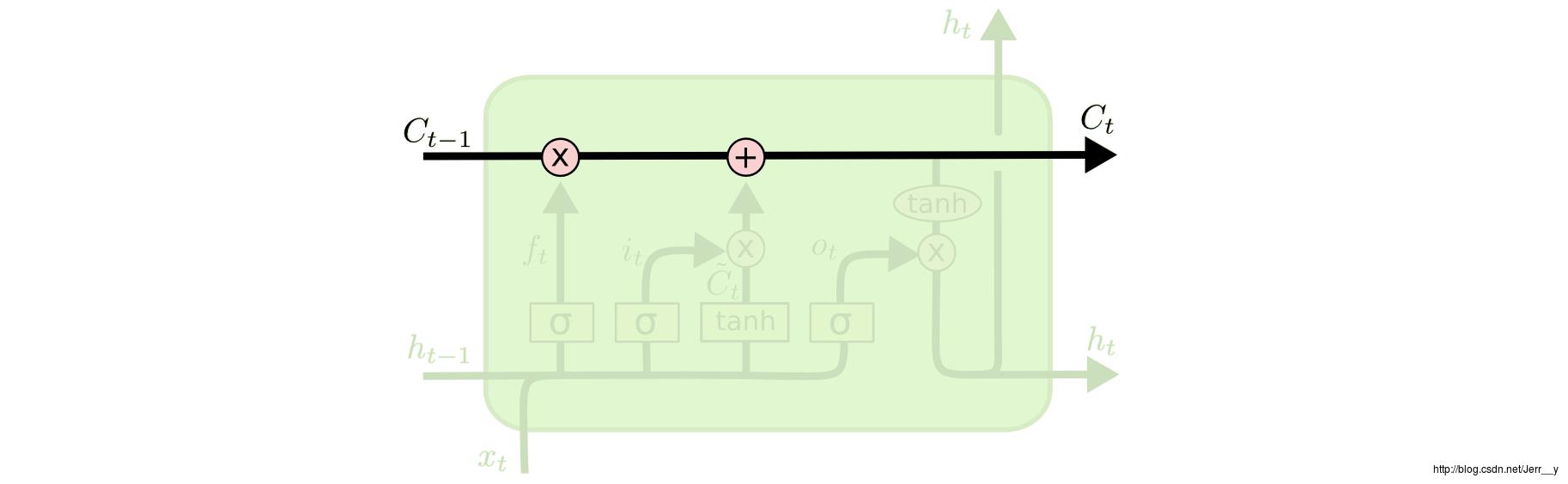 fig7. 传送带结构
fig7. 传送带结构
若只有上面的那条水平线是没办法实现添加或者删除信息的。而是通过一种叫做 门(gates) 的结构来实现的。
门 可以实现选择性地让信息通过,主要是通过一个 sigmoid 的神经层 和一个逐点相乘的操作来实现的。
sigmoid 层输出(是一个向量)的每个元素都是一个在 0 和 1 之间的实数,表示让对应信息通过的权重(或者占比)。比如, 0 表示“不让任何信息通过”, 1 表示“让所有信息通过”。
每个 LSTM 有三个这样的门结构,来实现保护和控制信息。(译者注:分别是 “forget gate layer”, 遗忘门; “input gate layer”,传入门; “output gate layer”, 输出门)
3.2 逐步理解 LSTM
3.2.1 遗忘门
首先是 LSTM 要决定让那些信息继续通过这个 cell,这是通过一个叫做“forget gate layer ”的sigmoid 神经层来实现的。它的输入是 表示的隐藏状态和新的输入信息
,输出是一个数值都在
![[0,1]](https://image.cha138.com/20210624/8d645e3655ec4202b3201a2813bf55e3.jpg) 之间的向量(向量长度和 cell 的状态
之间的向量(向量长度和 cell 的状态 一样),表示让
的各部分信息通过的比重。 0 表示“不让任何信息通过”, 1 表示“让所有信息通过”。
回到我们上面提到的语言模型中,我们要根据所有的上文信息来预测下一个词。这种情况下,每个 cell 的状态中都应该包含了当前主语的性别信息(保留信息),这样接下来我们才能够正确地使用代词。但是当我们又开始描述一个新的主语时,就应该把上文中的主语性别给忘了才对(忘记信息)。
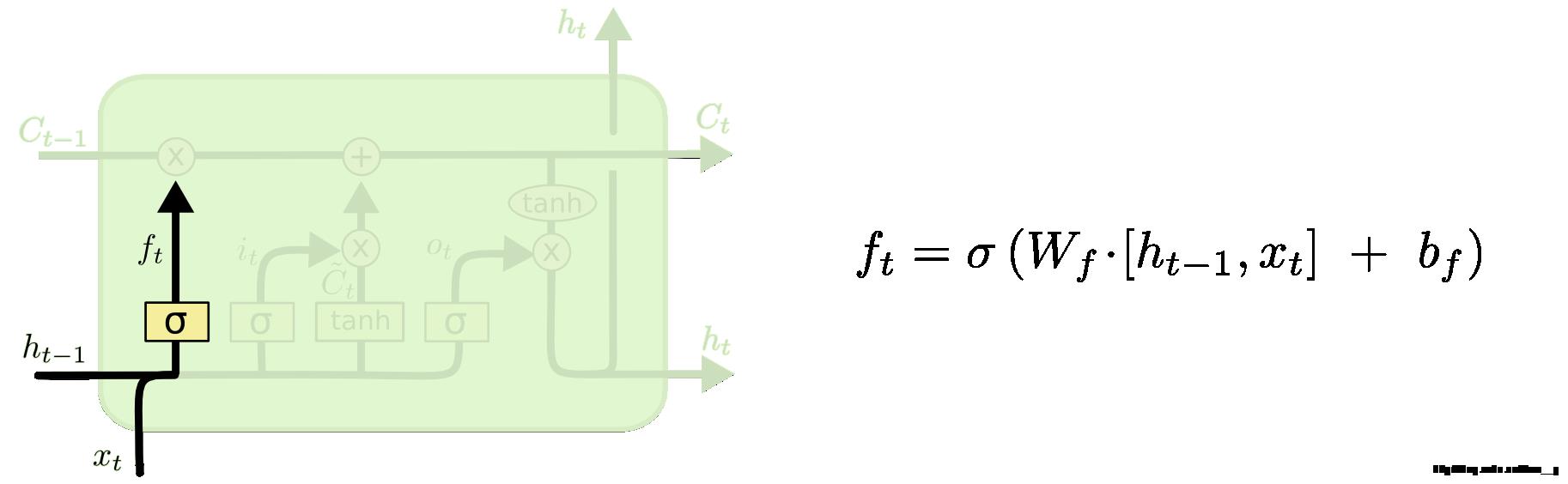 fig9. 遗忘门 (forget gates)
fig9. 遗忘门 (forget gates)
3.2.2 传入门
下一步是决定让多少新的信息加入到 cell 状态 中来。实现这个需要包括两个 步骤:首先,一个叫做“input gate layer ”的 sigmoid 层决定哪些信息需要更新;一个 tanh 层生成一个向量,也就是用来更新的内容,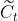 。在下一步,我们把这两部分联合起来,对 cell 的状态进行一个更新。
。在下一步,我们把这两部分联合起来,对 cell 的状态进行一个更新。
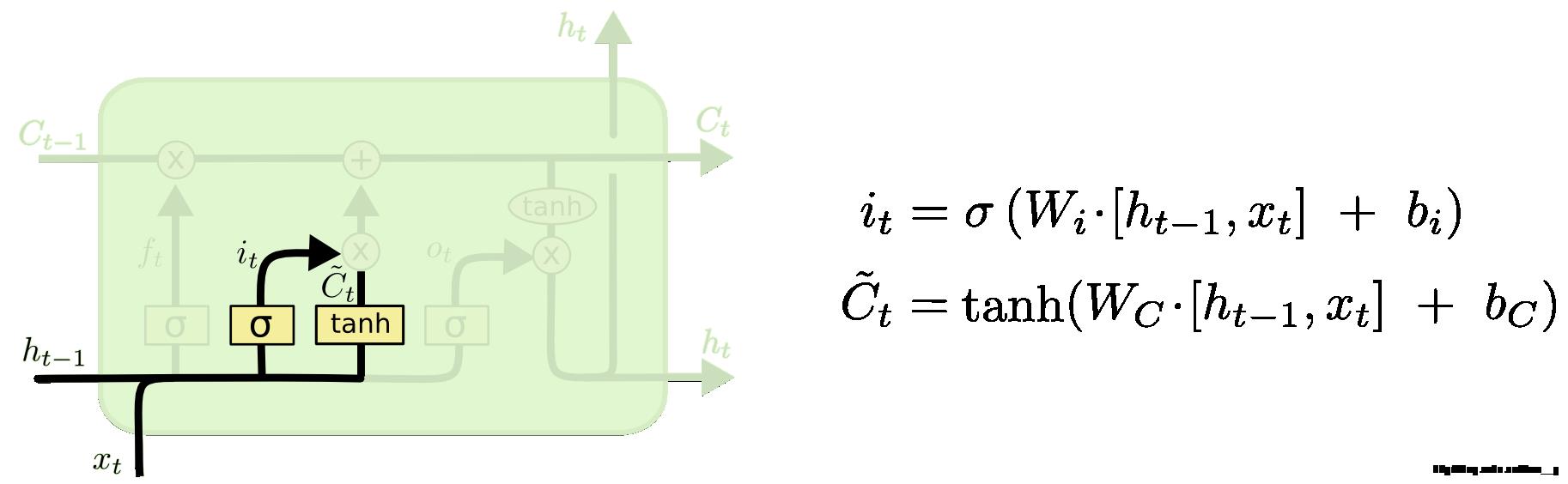 fig10. 传入门 (input gates)
fig10. 传入门 (input gates)
在我们的语言模型的例子中,我们想把新的主语性别信息添加到 cell 状态中,来替换掉老的状态信息。
有了上述的结构,我们就能够更新 cell 状态了, 即把更新为
。 从结构图中应该能一目了然, 首先我们把旧的状态
和
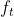 相乘,把一些不想保留的信息忘掉。然后加上相乘, 把一些不想保留的信息忘掉。然后加上相乘,把一些不想保留的信息忘掉。然后加上
相乘,把一些不想保留的信息忘掉。然后加上相乘, 把一些不想保留的信息忘掉。然后加上相乘,把一些不想保留的信息忘掉。然后加上。这部分信息就是我们要添加的新内容。
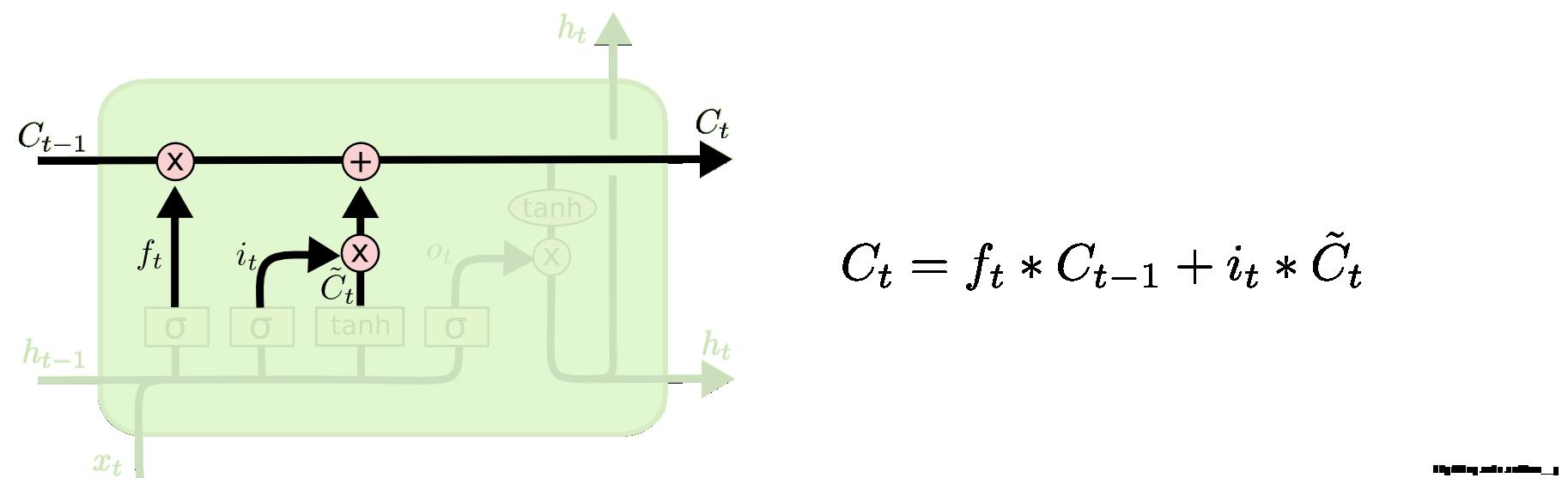 fig11. 更新 cell 状态
fig11. 更新 cell 状态
3.2.3 输出门
最后,我们需要来决定输出什么值了。这个输出主要是依赖于 cell 的状态,但是又不仅仅依赖于
,而是需要经过一个过滤的处理。首先,我们还是使用一个sigmoid层来(计算出)决定,而是需要经过一个过滤的处理。首先,我们还是使用一个 sigmoid 层来(计算出)决定,而是需要经过一个过滤的处理。首先,我们还是使用一个sigmoid层来(计算出)决定
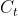 中的哪部分信息会被输出。接着,我们把中的哪部分信息会被输出。接着,我们把中的哪部分信息会被输出。接着,我们把
中的哪部分信息会被输出。接着,我们把中的哪部分信息会被输出。接着,我们把中的哪部分信息会被输出。接着,我们把  通过一个 tanh 层(把数值都归到 -1 和 1 之间),然后把 tanh 层的输出和 sigmoid 层计算出来的权重相乘,这样就得到了最后输出的结果。
通过一个 tanh 层(把数值都归到 -1 和 1 之间),然后把 tanh 层的输出和 sigmoid 层计算出来的权重相乘,这样就得到了最后输出的结果。
在语言模型例子中,假设我们的模型刚刚接触了一个代词,接下来可能要输出一个动词,这个输出可能就和代词的信息相关了。比如说,这个动词应该采用单数形式还是复数的形式,那么我们就得把刚学到的和代词相关的信息都加入到 cell 状态中来,才能够进行正确的预测。
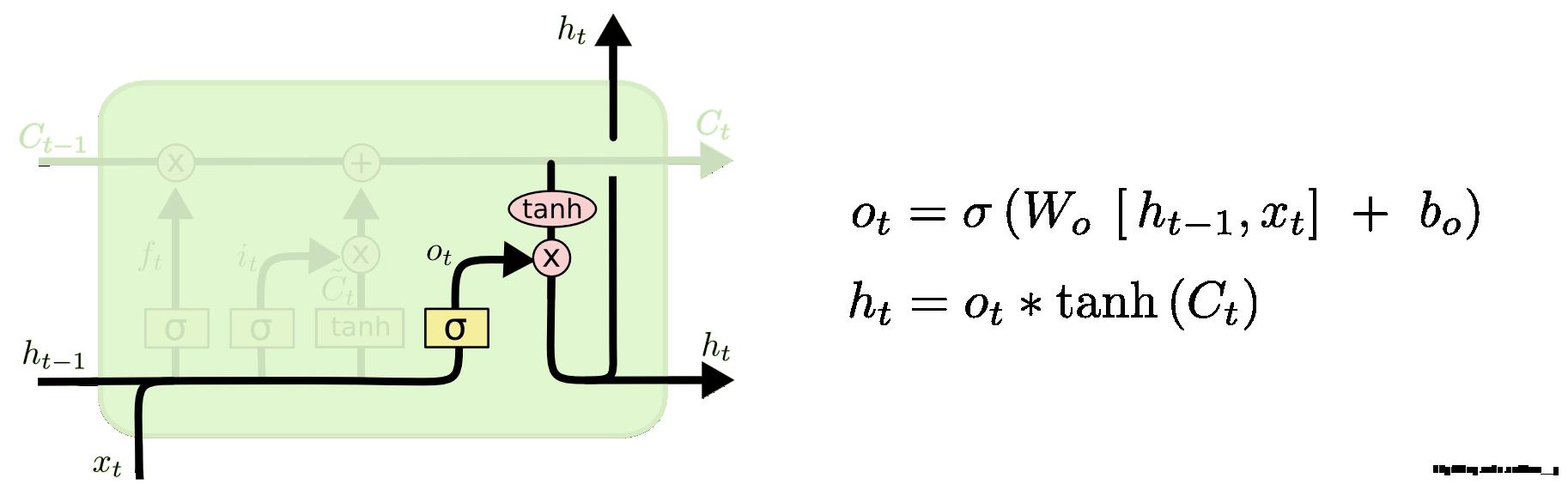 fig12. cell 输出
fig12. cell 输出
4. LSTM 的变种 GRU
原文这部分介绍了 LSTM 的几个变种,还有这些变形的作用。在这里我就不再写了。有兴趣的可以直接阅读原文。
下面主要讲一下其中比较著名的变种 GRU(Gated Recurrent Unit ),这是由 Cho, et al. (2014) 提出。在 GRU 中,如 fig.13 所示,只有两个门:重置门(reset gate)和更新门(update gate)。这个结构中,把遗忘门和传入门合并为一个更新们,把cell状态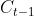 和隐藏状态
和隐藏状态进行了合并。最后模型比标准的 LSTM 结构要简单,而且这个结构后来也非常流行。
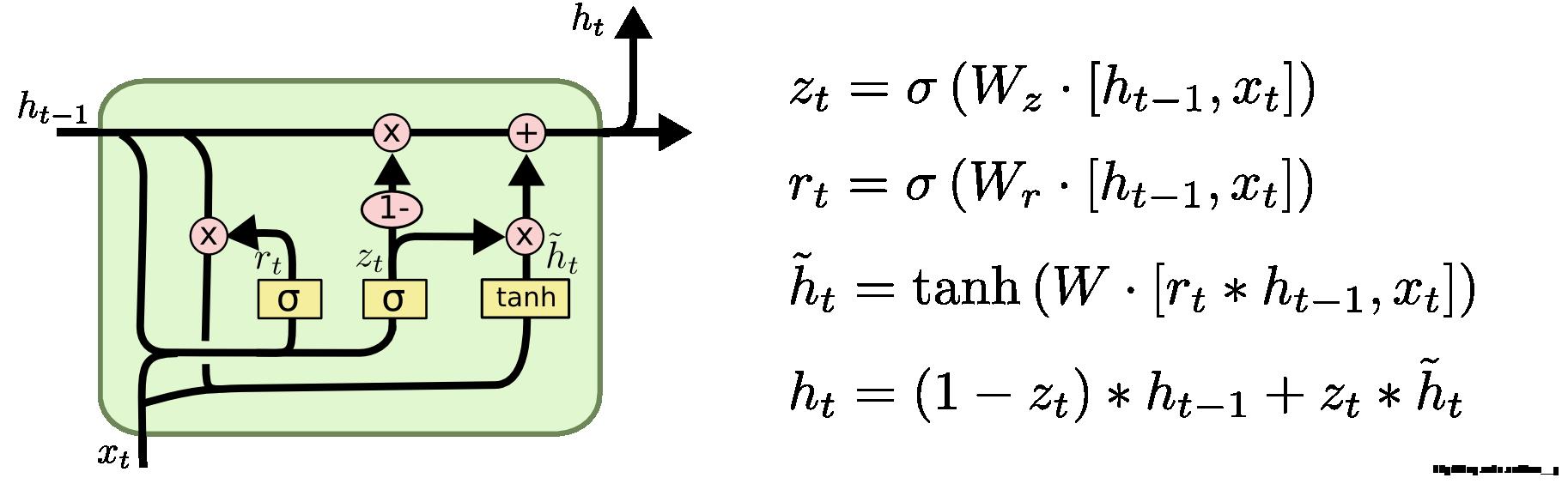 fig13. GRU结构
fig13. GRU结构
其中, 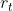 表示重置门,
表示重置门,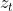 表示更新门。**重置门决定是否将之前的状态忘记。当 趋于 0 的时候,前一个时刻的隐藏状态信息 会被忘掉,当前输入的信息被设置为隐藏状态
表示更新门。**重置门决定是否将之前的状态忘记。当 趋于 0 的时候,前一个时刻的隐藏状态信息 会被忘掉,当前输入的信息被设置为隐藏状态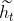 。更新门决定是否要将隐藏状态更新为新的状态。
。更新门决定是否要将隐藏状态更新为新的状态。
和 LSTM 比较一下:
- (1) GRU 少一个门,同时少了cell状态
。
- (2) 在 LSTM 中,通过遗忘门和传入门控制信息state的保留和传入;GRU 则通过重置门来控制是否要保留原来隐藏状态的信息,但是不再限制当前信息的传入。
- (3) 在 LSTM 中,虽然得到了新的细胞状态 , 但是还不能直接输出,而是通过更新门来控制最后的输出。
clc; clear; close all;
%% ---------------------------- init Variabels ----------------------------
opt.Delays = 1:30;
opt.dataPreprocessMode = 'Data Standardization'; % 'None' 'Data Standardization' 'Data Normalization'
opt.learningMethod = 'LSTM';
opt.trPercentage = 0.80; % divide data into Test and Train dataset
% ---- General Deep Learning Parameters(LSTM and CNN General Parameters)
opt.maxEpochs = 400; % maximum number of training Epoch in deeplearning algorithms.
opt.miniBatchSize = 32; % minimum batch size in deeplearning algorithms .
opt.executionEnvironment = 'cpu'; % 'cpu' 'gpu' 'auto'
opt.LR = 'adam'; % 'sgdm' 'rmsprop' 'adam'
opt.trainingProgress = 'none'; % 'training-progress' 'none'
% ------------- BILSTM parameters
opt.isUseBiLSTMLayer = true; % if it is true the layer turn to the Bidirectional-LSTM and if it is false it will turn the units to the simple LSTM
opt.isUseDropoutLayer = true; % dropout layer avoid of bieng overfit
opt.DropoutValue = 0.5;
% ------------ Optimization Parameters
opt.optimVars = [
optimizableVariable('NumOfLayer',[1 4],'Type','integer')
optimizableVariable('NumOfUnits',[50 200],'Type','integer')
optimizableVariable('isUseBiLSTMLayer',[1 2],'Type','integer')
optimizableVariable('InitialLearnRate',[1e-2 1],'Transform','log')
optimizableVariable('L2Regularization',[1e-10 1e-2],'Transform','log')];
opt.isUseOptimizer = true;
opt.MaxOptimizationTime = 14*60*60;
opt.MaxItrationNumber = 60;
opt.isDispOptimizationLog = true;
opt.isSaveOptimizedValue = false; % save all of Optimization output on mat files
opt.isSaveBestOptimizedValue = true; % save Best Optimization output o丿 a mat file
%% --------------- load Data
data = loadData(opt);
if ~data.isDataRead
return;
end
%% --------------- Prepair Data
[opt,data] = PrepareData(opt,data);
%% --------------- Find Best LSTM Parameters with Bayesian Optimization
[opt,data] = OptimizeLSTM(opt,data);
%% --------------- Evaluate Data
[opt,data] = EvaluationData(opt,data);
%% ---------------------------- Local Functions ---------------------------
function data = loadData(opt)
[chosenfile,chosendirectory] = uigetfile({'*.xlsx';'*.csv'},...
'Select Excel time series Data sets','data.xlsx');
filePath = [chosendirectory chosenfile];
if filePath ~= 0
data.DataFileName = chosenfile;
data.CompleteData = readtable(filePath);
if size(data.CompleteData,2)>1
warning('Input data should be an excel file with only one column!');
disp('Operation Failed... '); pause(.9);
disp('Reloading data. '); pause(.9);
data.x = [];
data.isDataRead = false;
return;
end
data.seriesdataHeder = data.CompleteData.Properties.VariableNames(1,:);
data.seriesdata = table2array(data.CompleteData(:,:));
disp('Input data successfully read.');
data.isDataRead = true;
data.seriesdata = PreInput(data.seriesdata);
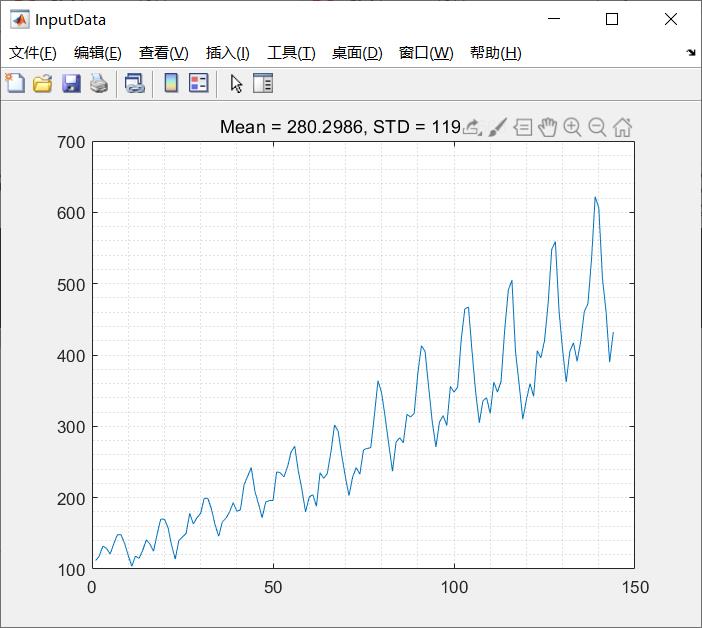
figure('Name','InputData','NumberTitle','off');
plot(data.seriesdata); grid minor;
title({['Mean = ' num2str(mean(data.seriesdata)) ', STD = ' num2str(std(data.seriesdata)) ];});
if strcmpi(opt.dataPreprocessMode,'None')
data.x = data.seriesdata;
elseif strcmpi(opt.dataPreprocessMode,'Data Normalization')
data.x = DataNormalization(data.seriesdata);
figure('Name','NormilizedInputData','NumberTitle','off');
plot(data.x); grid minor;
title({['Mean = ' num2str(mean(data.x)) ', STD = ' num2str(std(data.x)) ];});
elseif strcmpi(opt.dataPreprocessMode,'Data Standardization')
data.x = DataStandardization(data.seriesdata);
figure('Name','NormilizedInputData','NumberTitle','off');
plot(data.x); grid minor;
title({['Mean = ' num2str(mean(data.x)) ', STD = ' num2str(std(data.x)) ];});
end
else
warning(['In order to train network, please load data.' ...
'Input data should be an excel file with only one column!']);
disp('Operation Cancel.');
data.isDataRead = false;
end
end
function data = PreInput(data)
if iscell(data)
for i=1:size(data,1)
for j=1:size(data,2)
if strcmpi(data{i,j},'#NULL!')
tempVars(i,j) = NaN; %#ok
else
tempVars(i,j) = str2num(data{i,j}); %#ok
end
end
end
data = tempVars;
end
end
function vars = DataStandardization(data)
for i=1:size(data,2)
x.mu(1,i) = mean(data(:,i),'omitnan');
x.sig(1,i) = std (data(:,i),'omitnan');
vars(:,i) = (data(:,i) - x.mu(1,i))./ x.sig(1,i);
end
end
function vars = DataNormalization(data)
for i=1:size(data,2)
vars(:,i) = (data(:,i) -min(data(:,i)))./ (max(data(:,i))-min(data(:,i)));
end
end
% --------------- data preparation for LSTM ---
function [opt,data] = PrepareData(opt,data)
% prepare delays for time serie network
data = CreateTimeSeriesData(opt,data);
% divide data into test and train data
data = dataPartitioning(opt,data);
% LSTM data form
data = LSTMInput(data);
end
% ----Run Bayesian Optimization Hyperparameters for LSTM Network Parameters
function [opt,data] = OptimizeLSTM(opt,data)
if opt.isDispOptimizationLog
isLog = 2;
else
isLog = 0;
end
if opt.isUseOptimizer
opt.ObjFcn = ObjFcn(opt,data);
BayesObject = bayesopt(opt.ObjFcn,opt.optimVars, ...
'MaxTime',opt.MaxOptimizationTime, ...
'IsObjectiveDeterministic',false, ...
'MaxObjectiveEvaluations',opt.MaxItrationNumber,...
'Verbose',isLog,...
'UseParallel',false);
end
end
% ---------------- objective function
function ObjFcn = ObjFcn(opt,data)
ObjFcn = @CostFunction;
function [valError,cons,fileName] = CostFunction(optVars)
inputSize = size(data.X,1);
outputMode = 'last';
numResponses = 1;
dropoutVal = .5;
if optVars.isUseBiLSTMLayer == 2
optVars.isUseBiLSTMLayer = 0;
end
if opt.isUseDropoutLayer % if dropout layer is true
if optVars.NumOfLayer ==1
if optVars.isUseBiLSTMLayer
opt.layers = [ ...
sequenceInputLayer(inputSize)
bilstmLayer(optVars.NumOfUnits,'OutputMode',outputMode)
dropoutLayer(dropoutVal)
fullyConnectedLayer(numResponses)
regressionLayer];
else
opt.layers = [ ...
sequenceInputLayer(inputSize)
lstmLayer(optVars.NumOfUnits,'OutputMode',outputMode)
dropoutLayer(dropoutVal)
fullyConnectedLayer(numResponses)
regressionLayer];
end
elseif optVars.NumOfLayer==2
if optVars.isUseBiLSTMLayer
opt.layers = [ ...
sequenceInputLayer(inputSize)
bilstmLayer(optVars.NumOfUnits,'OutputMode','sequence')
dropoutLayer(dropoutVal)
bilstmLayer(optVars.NumOfUnits,'OutputMode',outputMode)
dropoutLayer(dropoutVal)
fullyConnectedLayer(numResponses)
regressionLayer];
else
opt.layers = [ ...
sequenceInputLayer(inputSize)
lstmLayer(optVars.NumOfUnits,'OutputMode','sequence')
dropoutLayer(dropoutVal)
lstmLayer(optVars.NumOfUnits,'OutputMode',outputMode)
dropoutLayer(dropoutVal)
fullyConnectedLayer(numResponses)
regressionLayer];
end
elseif optVars.NumOfLayer ==3
if optVars.isUseBiLSTMLayer
opt.layers = [ ...
sequenceInputLayer(inputSize)
bilstmLayer(optVars.NumOfUnits,'OutputMode','sequence')
dropoutLayer(dropoutVal)
bilstmLayer(optVars.NumOfUnits,'OutputMode','sequence')
dropoutLayer(dropoutVal)
bilstmLayer(optVars.NumOfUnits,'OutputMode',outputMode)
dropoutLayer(dropoutVal)
fullyConnectedLayer(numResponses)
regressionLayer];
else
opt.layers = [ ...
sequenceInputLayer(inputSize)
bilstmLayer(optVars.NumOfUnits,'OutputMode','sequence')
dropoutLayer(dropoutVal)
bilstmLayer(optVars.NumOfUnits,'OutputMode','sequence')
dropoutLayer(dropoutVal)
bilstmLayer(optVars.NumOfUnits,'OutputMode',outputMode)
dropoutLayer(dropoutVal)
fullyConnectedLayer(numResponses)
regressionLayer];
end
elseif optVars.NumOfLayer==4
if optVars.isUseBiLSTMLayer
opt.layers = [ ...
sequenceInputLayer(inputSize)
bilstmLayer(optVars.NumOfUnits,'OutputMode','sequence')
dropoutLayer(dropoutVal)
bilstmLayer(optVars.NumOfUnits,'OutputMode','sequence')
dropoutLayer(dropoutVal)
bilstmLayer(optVars.NumOfUnits,'OutputMode','sequence')
dropoutLayer(dropoutVal)
bilstmLayer(optVars.NumOfUnits,'OutputMode',outputMode)
dropoutLayer(dropoutVal)
fullyConnectedLayer(numResponses)
regressionLayer];
else
opt.layers = [ ...
sequenceInputLayer(inputSize)
bilstmLayer(optVars.NumOfUnits,'OutputMode','sequence')
dropoutLayer(dropoutVal)
bilstmLayer(optVars.NumOfUnits,'OutputMode','sequence')
dropoutLayer(dropoutVal)
bilstmLayer(optVars.NumOfUnits,'OutputMode','sequence')
dropoutLayer(dropoutVal)
bilstmLayer(optVars.NumOfUnits,'OutputMode',outputMode)
dropoutLayer(dropoutVal)
fullyConnectedLayer(numResponses)
regressionLayer];
end
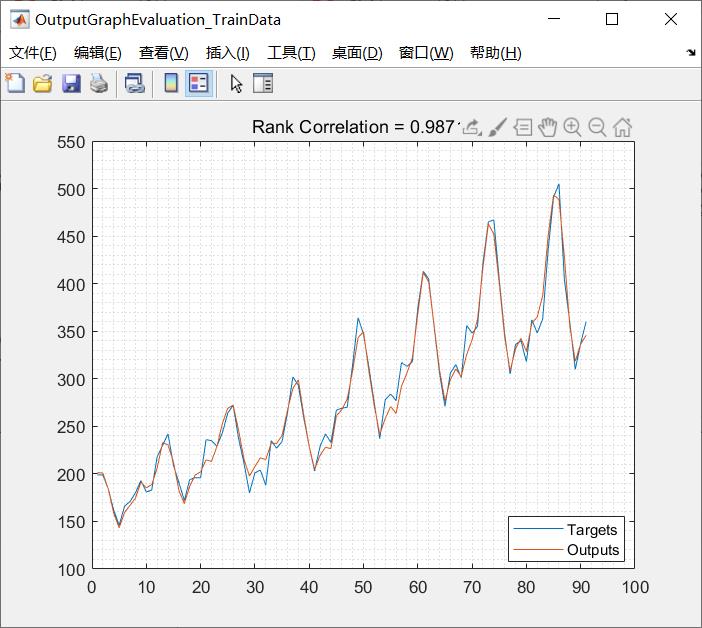
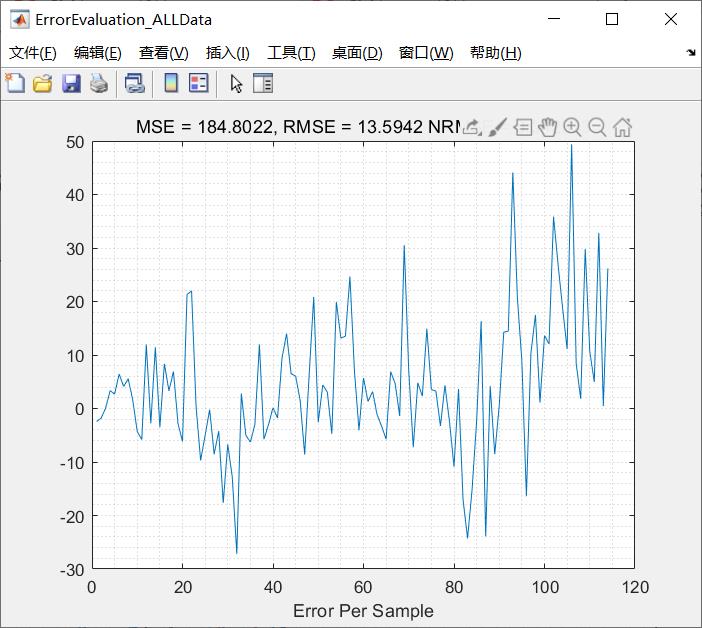
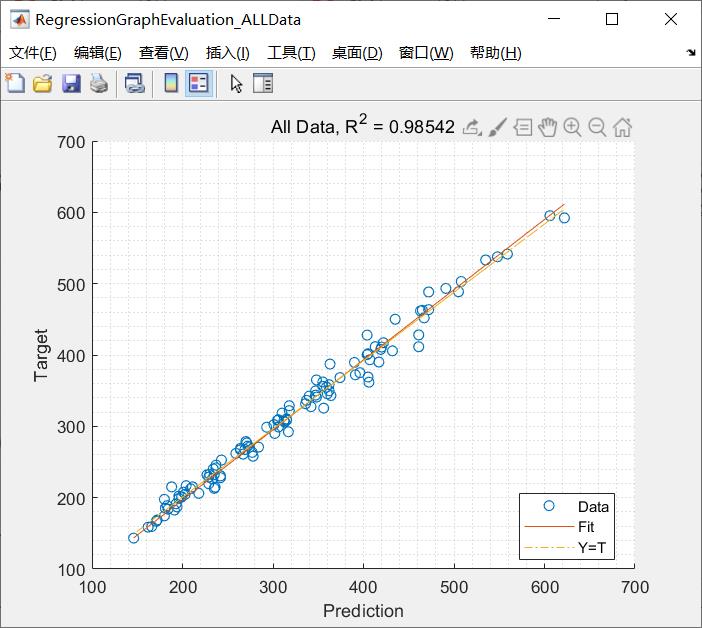
完整代码或者仿真咨询QQ1575304183
以上是关于lstm预测基于lstm实现时间序列数据预测matlab的主要内容,如果未能解决你的问题,请参考以下文章
DL之LSTM/GRU/CNN:基于tensorflow框架分别利用LSTM/GRUCNN算法对上海最高气温实现回归预测案例
Matlab基于长短期记忆网络分类LSTM实现多分类预测(Excel可直接替换数据)