Keras深度学习实战(32)——基于LSTM预测股价
Posted 盼小辉丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Keras深度学习实战(32)——基于LSTM预测股价相关的知识,希望对你有一定的参考价值。
Keras深度学习实战(32)——基于LSTM预测股价
0. 前言
股价预测是时间序列预测中最具挑战性的问题之一,研究股价预测问题具有重要的理论意义和应用价值。大多数有关股价预测的技术分析都依赖于历史模式,鉴于循环神经网络 (Recurrent neural networks, RNN) 模型就是通过考虑历史数据来做出决策,因此,RNN 模型非常适合做金融时间序列的预测。同时,长短时记忆网络模型长短时记忆网络 (Long Short Term Memory, LSTM) 模型预测股价的误差值比 RNN 要小,因此选择 LSTM 模型预测金融时间序列更合适。
1. 模型与数据集分析
1.1 数据集分析
本文使用的股价数据集来自 GitHib,也可以使用格式与之类似的股价数据集。下载数据集后,查看其内容,可以看到数据集中包含时间、开盘时股价等一系列相关信息,本文需要预测的是股价当天的最终价格,即 Close 列的数据:

1.2 模型分析
为了预测股票的价格,我们考虑以下两种策略:
- 仅根据最近
5天的股价预测股价 - 根据最近
5天的股价和目标公司的最新消息预测股价
对于第一种策略,准备数据集的方法与为其他 LSTM 模型构建数据集的方法类似;而第二种策略则涉及同时对数字和文本数据进行处理。上述两种处理数据的方法如下:
- 仅使用最近五天的股票价格:
- 根据时间顺序,对数据集样本进行排序
- 前
5个股价作为输入,第6个股价数据作为输出 - 滑动此窗口,以第
2个到第6个数据样本作为输入,第7个数据点作为输出,依此类推,直到滑动到最后一个数据样本:- 每
5个数据样本作为LSTM中5个时间戳的输入 - 第
6个数据样本作为模型输出
- 每
- 由于我们预测的股价是连续值,因此损失函数为均方误差
- 使用最近
5天的股价和相关公司的新闻标题数据:在这种情况下,有两种类型的数据需要进行处理。对于过去5天股价的数据预处理与仅使用最近5天的股价策略相同,但需要额外处理新闻标题的文本数据,然后将其都整合到模型中:- 对于这
2种不同类型的数据,我们使用2个不同的模型:- 第
1个模型使用历史上最近5天股价数据的模型 - 第
2个模型利用新闻标题数据集修改第1个模型得到的预测输出
- 第
- 为了简单起见,假设仅在预测股价之日之前的最新标题会对预测当天的股价的结果产生影响
- 由于我们有两个不同的模型,因此需要使用函数式
API将这两个模型结合起来
- 对于这
2. 基于长短时记忆网络LSTM预测股价
在本节中,我们主要解决以下问题:
- 根据最近
5天的股价预测股价 - 将最近
5天的股价与最近的新闻标题文字数据结合起来
2.1 根据最近五天的股价预测股价
在本小节中,我们仅基于最近的 5 个数据样本来预测下一时间戳的股价。
(1) 导入相关库和数据集:
import numpy as np
import pandas as pd
data2 = pd.read_csv('stock_data.csv')
(2) 构造输入、输出数据,其中输入是最近 5 天的股价,输出是第 6 天的股票价格值:
x= []
y = []
for i in range(data2.shape[0]-5):
x.append(data2.loc[i:(i+4)]['Close'].values)
y.append(data2.loc[i+5]['Close'])
x = np.array(x)
y = np.array(y)
(3) 整形输入数据的形状,使其形状为 (batch_size, time_steps, features_per_time_step):
x = x.reshape(x.shape[0],x.shape[1],1)
(4) 将数据集划分为训练和测试数据集:
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.30)
(5) 构建 LSTM 模型用于根据最近的 5 个数据样本预测下一时间戳的股价:
from keras.models import Sequential
from keras.layers import Dense, LSTM
model = Sequential()
model.add(Dense(100, input_shape = (5,1), activation = 'relu'))
model.add((LSTM(100)))
model.add(Dense(1000,activation='relu'))
model.add(Dense(1,activation='linear'))
model.summary()
该模型的简要架构信息输入如下:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 5, 100) 200
_________________________________________________________________
lstm (LSTM) (None, 100) 80400
_________________________________________________________________
dense_1 (Dense) (None, 1000) 101000
_________________________________________________________________
dense_2 (Dense) (None, 1) 1001
=================================================================
Total params: 182,601
Trainable params: 182,601
Non-trainable params: 0
_________________________________________________________________
(6) 编译并拟合模型:
from keras.optimizers import Adam
adam = Adam(lr=0.0001)
model.compile(optimizer=adam, loss='mean_squared_error')
model.fit(x_train, y_train,
epochs=300,
batch_size=64,
validation_data=(x_test, y_test),
verbose=1)
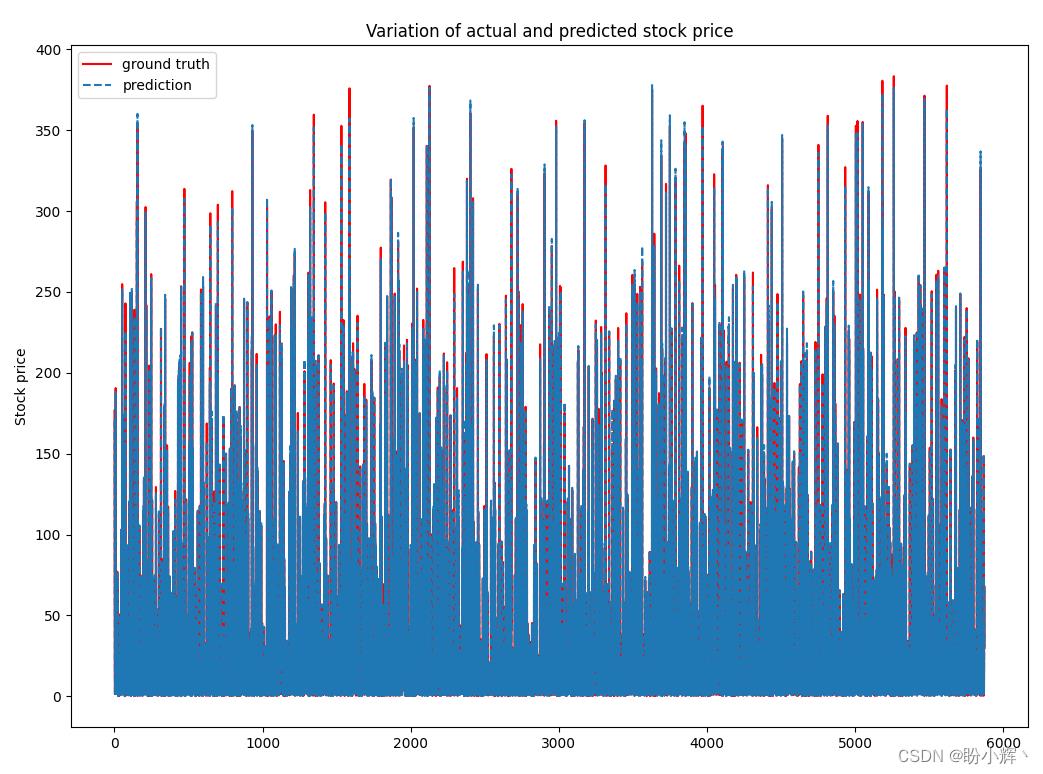
(7) 绘制预测股价与实际股价:
pred = model.predict(x_test)
import matplotlib.pyplot as plt
# plt.figure(figsize=(20,10))
plt.plot(y_test, 'r', label='ground truth')
plt.plot(pred, '--', label='prediction')
plt.title('Variation of actual and predicted stock price')
plt.ylabel('Stock price')
plt.legend()
plt.show()
预测股价与实际股价间的差异如下图所示:
2.2 考虑最近五天的股价和新闻数据
接下来,我们将合并有关公司的新闻标题的文本数据以及最近五天的股价数据,其中新闻标题文本数据从 Guardian 网站提供的新闻 API 中获取。
(1) 从 Guardian 网站导入标题数据,获取标题和相应日期,然后对日期进行预处理,以便将其转换为通用日期格式:
from bs4 import BeautifulSoup
import urllib, json
dates = []
titles = []
for i in range(100):
try:
url = 'https://content.guardianapis.com/search?from-date=2010-01-01§ion=business&page-size=200&order-by=newest&page='+str(i+1)+'&q=amazon&api-key=207b6047-a2a6-4dd2-813b-5cd006b780d7'
response = urllib.request.urlopen(url)
encoding = response.info().get_content_charset('utf8')
data = json.loads(response.read().decode(encoding))
for j in range(len(data['response']['results'])):
dates.append(data['response']['results'][j]['webPublicationDate'])
titles.append(data['response']['results'][j]['webTitle'])
except:
break
import pandas as pd
data = pd.DataFrame(dates, titles)
print(data.head())
data = data.reset_index()
data.columns = ['title','date']
print(data.head())
data['date']=data['date'].str[:10]
print(data.head())
data['date']=pd.to_datetime(data['date'], format = '%Y-%m-%d')
print(data.head())
data = data.sort_values(by='date')
print(data.head())
data_final = data.groupby('date').first().reset_index()
(2) 按日期对股价据集和新闻标题数据集排序:
data2['Date'] = pd.to_datetime(data2['Date'],format='%Y-%m-%d')
data3 = pd.merge(data2,data_final, left_on = 'Date', right_on = 'date', how='left')
print(data3.head())
(3) 预处理文本数据以除去停用词和标点符号,然后对文本输入进行编码,过程与构建循环神经网络进行情感分类所用预处理方法相同:
word_number = data3['title'].nunique()
import nltk
import re
stop = nltk.corpus.stopwords.words('english')
def preprocess(text):
text = str(text)
text=text.lower()
text=re.sub('[^0-9a-zA-Z]+',' ',text)
words = text.split()
words2=[w for w in words if (w not in stop)]
#words3=[ps.stem(w) for w in words]
words4=' '.join(words2)
return(words4)
data3['title'] = data3['title'].apply(preprocess)
data3['title']=np.where(data3['title'].isnull(),'-','-'+data3['title'])
docs = data3['title'].values
from collections import Counter
counts = Counter()
for i,review in enumerate(docs):
counts.update(review.split())
words = sorted(counts, key=counts.get, reverse=True)
vocab_size=len(words)
word_to_int = word: i for i, word in enumerate(words, 1)
encoded_docs = []
for doc in docs:
encoded_docs.append([word_to_int[word] for word in doc.split()])
(4) 以最近 5 天的股价和股价预测日期之前最近的新闻标题为输入,并对数据进行预处理以获得输入和输出数据,然后将其划分为训练和测试数据集。其中,x1 对应于历史股价,x2 对应于股票预测日期的新闻标题:
x1 = []
x2 = []
y = []
for i in range(data3.shape[0]-5):
x1.append(data3.loc[i:(i+4)]['Close'].values)
x2.append(padded_docs[i+5])
y.append(data3.loc[i+5]['Close'])
x1 = np.array(x1)
x2 = np.array(x2)
y = np.array(y)
x1 = x1.reshape(x1.shape[0],x1.shape[1],1)
x1_train = x1[:12000,:,:]
x2_train = x2[:12000,:]
y_train = y[:12000]
x1_test = x1[12000:,:,:]
x2_test = x2[12000:,:]
y_test = y[12000:]
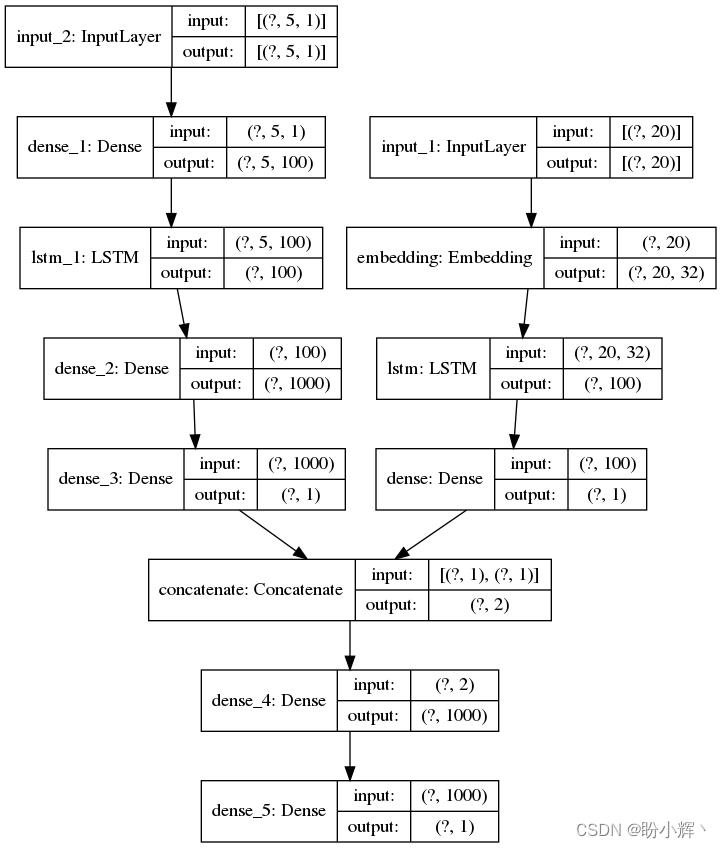
(5) 由于我们需要传递多个变量作为输入——历史股价和编码后的文本数据,因此我们使用函数式 API 构建模型:
from keras.layers import Embedding
input1 = Input(shape=(20,))
model = Embedding(input_dim=vocab_size+1, output_dim=32, input_length=20)(input1)
model = (LSTM(units=100))(model)
model = (Dense(1, activation='tanh'))(model)
input2 = Input(shape=(5,1))
model2 = Dense(100, activation='relu')(input2)
model2 = LSTM(units=100)(model2)
model2 = (Dense(1000, activation="relu"))(model2)
model2 = (Dense(1, activation="linear"))(model2)
from keras.layers import multiply
conc = multiply([model, model2])
from keras.layers import concatenate
conc = concatenate([model, model2])
conc2 = (Dense(1000, activation="relu"))(conc)
out = (Dense(1, activation="linear"))(conc2)
在以上代码中,我们将股价模型和文本数据模型的输出值相乘,因为模型需要根据文本数据和历史股价数据进行训练:
model = Model([input1, input2], out)
model.summary()
from keras.utils import plot_model
plot_model(model, show_shapes=True, show_layer_names=True, to_file='model.png')
以上模型的架构如下:
(6) 编译并拟合模型:
adam = Adam(lr=0.0001)
model.compile(adam, loss='mean_squared_error')
model.fit(x=[x2_train, x1_train], y=y_train,
epochs=300,
batch_size=32,
validation_data=([x2_test, x1_test], y_test),
verbose=1)
(7) 使用测试数据集绘制股价的实际值与模型预测值:
pred = model.predict([x2_test, x1_test])
import matplotlib.pyplot as plt
# plt.figure(figsize=(20,10))
plt.plot(y_test,'r',label='actual')
plt.plot(pred,'--', label = 'predicted')
plt.title('Variation of actual and predicted stock price')
plt.ylabel('Stock price')
plt.legend()
plt.show()
实际和预测股价的变化如下:

在预测股价时不需要考虑所有可能的影响因素,因为影响股价走势的因素多种多样。例如,在进行预测时,我们还可能包含更多的信息来源,例如相关季节性或其他经济因素。我们也可以对数据集进行缩放,以使加快网络的训练、提高模型性能。
小结
针对循环神经网络在股价预测中存在的长期依赖等缺点,本文引入了长短时记忆神经网络以提高股价预测的效果。同时,我们把有关公司的新闻标题的文本数据作为模型的输入变量时,发现预测效果更好,因此我们可以把有关公司的新闻标题的文本数据作为一个有效的输入变量。最后,通过利用 Keras 实现了以上两个股价预测模型,并进行了性能分析和对比。
系列链接
Keras深度学习实战(1)——神经网络基础与模型训练过程详解
Keras深度学习实战(2)——使用Keras构建神经网络
Keras深度学习实战(3)——神经网络性能优化技术
Keras深度学习实战(4)——深度学习中常用激活函数和损失函数详解
Keras深度学习实战(5)——批归一化详解
Keras深度学习实战(6)——深度学习过拟合问题及解决方法
Keras深度学习实战(7)——卷积神经网络详解与实现
Keras深度学习实战(8)——使用数据增强提高神经网络性能
Keras深度学习实战(9)——卷积神经网络的局限性
Keras深度学习实战(10)——迁移学习详解
Keras深度学习实战(11)——可视化神经网络中间层输出
Keras深度学习实战(12)——面部特征点检测
Keras深度学习实战(13)——目标检测基础详解
Keras深度学习实战(14)——从零开始实现R-CNN目标检测
Keras深度学习实战(15)——从零开始实现YOLO目标检测
Keras深度学习实战(16)——自编码器详解
Keras深度学习实战(17)——使用U-Net架构进行图像分割
Keras深度学习实战(18)——语义分割详解
Keras深度学习实战(19)——使用对抗攻击生成可欺骗神经网络的图像
Keras深度学习实战(20)——DeepDream模型详解
Keras深度学习实战(21)——神经风格迁移详解
Keras深度学习实战(22)——生成对抗网络详解与实现
Keras深度学习实战(23)——DCGAN详解与实现
Keras深度学习实战(24)——从零开始构建单词向量
Keras深度学习实战(25)——使用skip-gram和CBOW模型构建单词向量
Keras深度学习实战(26)——文档向量详解
Keras深度学习实战(27)——循环神经详解与实现
Keras深度学习实战(28)——利用单词向量构建情感分析模型
Keras深度学习实战(29)——长短时记忆网络详解与实现
Keras深度学习实战(30)——使用文本生成模型进行文学创作
Keras深度学习实战(31)——构建电影推荐系统
以上是关于Keras深度学习实战(32)——基于LSTM预测股价的主要内容,如果未能解决你的问题,请参考以下文章