基于LSTM的序列预测: 飞机月流量预测
Posted pan_jinquan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于LSTM的序列预测: 飞机月流量预测相关的知识,希望对你有一定的参考价值。
基于LSTM的序列预测: 飞机月流量预测
循环神经网络,如RNN,LSTM等模型,比较适合用于序列预测,下面以一个比较经典的飞机月流量数据集,介绍LSTM的使用方法和训练过程。
完整的项目代码下载:https://download.csdn.net/download/guyuealian/33998269
【尊重原作,转载请注明出处】:https://panjinquan.blog.csdn.net/article/details/120918732
目录
1.数据处理
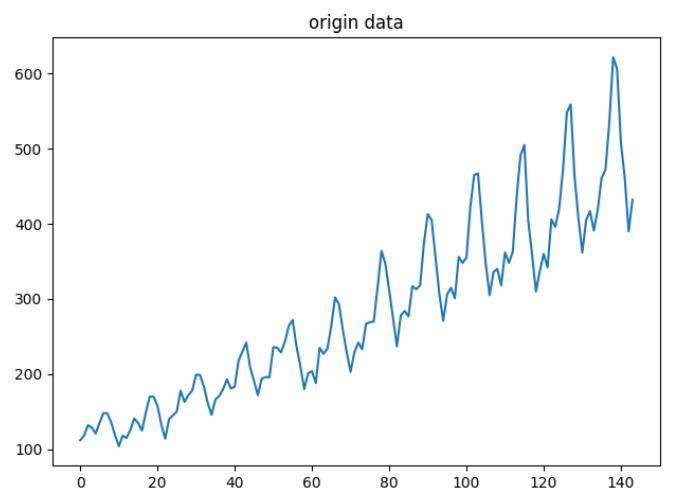
下表图是某国家12年共144个月的飞机月流量数据表,由于月流量数据是不规范的标量,需要将数据标准化到同一尺度,即0~1之间,以便用于模型训练。
| 原始数据 | 归一化后的数据 |
 |  |
def load_dataset(file="data/data.csv", plot=False):
"""加载数据并进归一化"""
orig_data = pd.read_csv(file, usecols=[1])
# 首先我们进行预处理,将数据中 `na` 的数据去掉,然后将数据标准化到 0 ~ 1 之间。
data = orig_data.dropna()
dataset = np.asarray(data.values, dtype=np.float32)
dataset = data_normalization(dataset)
if plot:
plt.plot(orig_data)
plt.title("origin data") #
plt.show()
plt.plot(dataset)
plt.title("norm data") # 标准化数据
plt.show()
return dataset
def data_normalization(x):
"""
数据归一化(0,1)
:param x:
:return:
"""
mx, mi = np.max(x), np.min(x)
y = (x - mi) / (mx - mi)
return y接着我们进行数据集的创建,我们想通过前面几个月的流量来预测当月的流量,比如我们希望通过前两个月的流量来预测当月的流量,我们可以将前两个月的流量当做输入,当月的流量当做输出。同时我们需要将我们的数据集分为训练集和测试集,通过测试集的效果来测试模型的性能,这里我们简单的将前面几年的数据作为训练集(70%),后面两年的数据作为测试集(30%),其中look_back=2表示使用前2个月的流量数据预测当前月的流量,当然也可以设置为look_back=3或4。
def create_dataset(dataset, look_back=2):
"""
:param dataset: (144,1)
:param look_back:
:return: data_inputs (142,2)
data_target (142,1)
"""
dataset = np.asarray(dataset)
data_inputs, data_target = [], []
for i in range(len(dataset) - look_back):
a = dataset[i:(i + look_back)]
data_inputs.append(a)
data_target.append(dataset[i + look_back])
data_inputs = np.array(data_inputs).reshape((-1, look_back))
data_target = np.array(data_target).reshape((-1, 1))
return data_inputs, data_target
def split_train_test_data(data_inputs, data_target, rate=0.7):
"""
:param data_inputs:
:param data_target:
:param rate:训练集占比
:return:
"""
# 划分训练集和测试集,70% 作为训练集
train_size = math.ceil(len(data_inputs) * rate)
train_inputs = data_inputs[:train_size]
train_target = data_target[:train_size]
test_inputs = data_inputs[train_size:]
test_target = data_target[train_size:]
return train_inputs, train_target, test_inputs, test_targetRNN模型输入数据的维度是(seq,batch,input),其中batch是1,由于只有一个序列,input就是预测依据的月份数2,seq的大小就是训练集的序列长度
2.构建LSTM模型
Pytorch已经实现了LSMT模块,在此基础上可构建循环神经网络LSTM模型。模型共包含两个模块:第一模块是LSTM,以两个月的数据作为输入,并得到一个输出特征。第二个模块是全连接层FC,将 RNN 的输出回归到目标值;模块之间数据维度变化,需要使用 `view` 来重新排列
因为 `nn.Linear` 不接受三维的输入,所以我们先将前两维合并在一起,然后经过线性层之后再将其分开,最后输出结果。
另外,模型输入维度是根据前面的数据处理来确定的,由于我们新建的训练数据是依赖前两个月的飞机月流量数据来预测第三个月的流量,所以数据数据的维度是2。
# -*-coding: utf-8 -*-
"""
@Author : panjq
@E-mail : pan_jinquan@163.com
@Date : 2021-10-17 14:21:43
"""
import torch
from torch import nn
class LSTMModel(nn.Module):
"""定义LSTM模型: LSTM+FC的回归模型"""
def __init__(self, input_size, hidden_size=5, num_layers=7, output_dim=1):
"""
Ref:
https://www.zhihu.com/question/41949741/answer/318771336
https://zhuanlan.zhihu.com/p/41261640
输入数据格式:
input(seq_len, batch, input_size)
h0(num_layers * num_directions, batch, hidden_size)
c0(num_layers * num_directions, batch, hidden_size)
输出数据格式:
output(seq_len, batch, hidden_size * num_directions)
hn(num_layers * num_directions, batch, hidden_size)
cn(num_layers * num_directions, batch, hidden_size)
:param input_size: RNN输入的特征维度,如单词向量中embedding_dim,序列向量的特征维度,注意不是序列长度
:param hidden_size: RNN隐藏层或输出层的特征维度
:param num_layers: RNN的网络层数,即模型集成的LSTM的个数,相当于LSTM摞起个数,默认1个
Number of recurrent layers. E.g., setting ``num_layers=2``
would mean stacking two LSTMs together to form a `stacked LSTM`,
with the second LSTM taking in outputs of the first LSTM and
computing the final results. Default: 1
:param output_dim:
"""
super(LSTMModel, self).__init__()
self.rnn = nn.LSTM(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers) # rnn
self.reg = nn.Linear(hidden_size, output_dim) # 回归
def forward(self, inptut):
"""
inptut=(seq, batch, input_size)
output=(seq, batch, hidden_size)
:param inptut:
:return:
"""
# output, (hn, cn) = rnn(input, (h0, c0))
o, _ = self.rnn(inptut) # output=(seq, batch, hidden_size)
s, b, h = o.shape
o = o.view(s * b, h) # 转换成线性层的输入格式
o = self.reg(o)
o = o.view(s, b, -1)
return o
torch.nn.LSTM()参数说明:
input_size 输入数据的特征维数,通常就是embedding_dim(词向量的维度)
hidden_size LSTM中隐层的维度
num_layers 循环神经网络的层数
bias 用不用偏置,default=True
batch_first 这个要注意,通常我们输入的数据shape=(batch_size,seq_length,embedding_dim),而batch_first默认是False,所以我们的输入数据最好送进LSTM之前将batch_size与seq_length这两个维度调换
dropout 默认是0,代表不用dropout
bidirectional默认是false,代表不用双向LSTM
3.损失函数和优化器
序列预测本质还是一个回归模型,回归任务最常用的损失函数主要有MSE、RMSE、MAE,表达式如下:
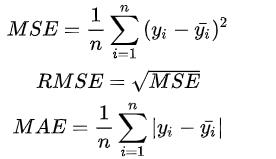
本题目比较简单,可以直接使用均方误差(MSE) 作为优化目标函数,Pytorch中 已经定义MSELoss函数
nn.MSELoss()优化器,可使用SGD或者Adam
4.训练Pipeline
# -*-coding: utf-8 -*-
"""
@Author : panjq
@E-mail : pan_jinquan@163.com
@Date : 2021-10-17 14:21:43
"""
import argparse
import torch
from torch import nn
import matplotlib.pyplot as plt
from seq.data_utils import load_dataset, create_dataset, split_train_test_data
from seq.lstm import LSTMModel
class Trainer(object):
def __init__(self, args):
self.num_epoch = args.num_epoch
# 通过前几个月(look_back)的流量来预测当月的流量,默认2
self.look_back = 2
self.batch_size = 1
self.dataset = load_dataset(args.data_file, plot=True)
self.data_inputs, self.data_target = create_dataset(self.dataset, look_back=self.look_back)
self.train_inputs, self.train_target, self.test_inputs, self.test_target = \\
split_train_test_data(self.data_inputs, self.data_target)
# 需要将数据改变一下形状,因为RNN读入的数据维度是(seq, batch, feature)
# 所以要重新改变一下数据的维度,这里只有一个序列,所以batch是 1
# 而输入的 feature就是我们希望依据的几个月份
# 这里我们定的是两个月份,所以feature就是2
self.train_inputs = self.train_inputs.reshape(-1, self.batch_size, self.look_back)
self.train_target = self.train_target.reshape(-1, self.batch_size, 1)
self.test_inputs = self.test_inputs.reshape(-1, self.batch_size, self.look_back)
self.data_inputs = self.data_inputs.reshape(-1, self.batch_size, self.look_back)
self.model = self.build_model()
self.criterion = nn.MSELoss()
self.optimizer = torch.optim.Adam(self.model.parameters(), lr=1e-2)
def build_model(self):
# 定义好网络结构,输入的维度input_dim=2(因为我们使用两个月的流量作为输入)
# 隐藏层的维度hidden_dim=4
model = LSTMModel(input_dim=self.look_back, hidden_dim=4)
return model
def train(self):
inputs = torch.from_numpy(self.train_inputs)
target = torch.from_numpy(self.train_target)
self.model.train() # 转换成测试模式
# 开始训练
for epoch in range(self.num_epoch):
# 前向传播
output = self.model(inputs)
loss = self.criterion(output, target)
# 反向传播
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
if epoch % 100 == 0: # 每 100 次输出结果
print('Epoch: {}, Loss: {:.5f}'.format(epoch, loss.item()))
self.test()
def test(self):
"""
这里蓝色的是真实的数据集,红色的是预测的结果,我们能够看到,使用lstm能够得到比较相近的结果,
预测的趋势也与真实的数据集是相同的,因为其能够记忆之前的信息,
而单纯的使用线性回归并不能得到较好的结果,从这个例子也说明了 RNN 对于序列有着非常好的性能。
:return:
"""
self.model.eval() # 转换成测试模式
# inputs = torch.from_numpy(self.test_inputs)
inputs = torch.from_numpy(self.data_inputs)
output = self.model(inputs) # 测试集的预测结果
# 改变输出的格式
output = output.view(-1).data.numpy()
# 画出实际结果和预测的结果
plt.plot(output, 'r', label='prediction')
plt.plot(self.dataset, 'b', label='real')
plt.legend(loc='best')
plt.show()
def get_parser():
data_file = "data/data.csv"
parser = argparse.ArgumentParser(description=__doc__)
# parser.add_argument('--batch_size', type=int, default=32, help='训练的批量大小')
parser.add_argument('--num_epoch', type=int, default=1000, help='训练的轮数')
parser.add_argument('--data_file', type=str, default=data_file, help='数据文件')
return parser
if __name__ == '__main__':
parser = get_parser()
args = parser.parse_args()
t = Trainer(args)
t.train()
训练迭代1000次后,模型已经收敛,Loss已经很小了
Epoch: 0, Loss: 0.08340
Epoch: 100, Loss: 0.00399
Epoch: 200, Loss: 0.00360
Epoch: 300, Loss: 0.00321
Epoch: 400, Loss: 0.00285
Epoch: 500, Loss: 0.00326
Epoch: 600, Loss: 0.00156
Epoch: 700, Loss: 0.00128
Epoch: 800, Loss: 0.00127
Epoch: 900, Loss: 0.00121
5.预测效果
下面是测试效果,其中蓝色是真实的飞机月流量数据,红色的预测的数据,可以看到使用LSTM能够预测近似的结果。

6.更多AI项目
更多AI技术博客推荐:
人脸检测+人体检测C++ android项目_pan_jinquan的博客-CSDN博客人脸检测+人体检测C++ Android实现本博客将实现C++版本的人脸检测,人脸关键点检测,人体检测,人脸+人体检测,推理框架采用TNN,在普通Android手机,CPU和GPU都可以达到实时检测的效果人脸检测+人脸关键点检测+人体检测Android Demo APP(非源码,仅供学习交流)链接: https://pan.baidu.com/s/1By43I1DbMa0gBPLObtPZMQ 提取码: msnr尊重原创,转载请注明出处:https://panjinquan.blog.. https://panjinquan.blog.csdn.net/article/details/120688804
https://panjinquan.blog.csdn.net/article/details/120688804
如果你觉得该帖子帮到你,还望贵人多多支持,鄙人会再接再厉,继续努力的~

以上是关于基于LSTM的序列预测: 飞机月流量预测的主要内容,如果未能解决你的问题,请参考以下文章
深度学习多变量时间序列预测:LSTM算法构建时间序列多变量模型预测交通流量+代码实战
深度学习多变量时间序列预测:Encoder-Decoder LSTM算法构建时间序列多变量模型预测交通流量+代码实战
深度学习多变量时间序列预测:GRU算法构建时间序列多变量模型预测交通流量+代码实战