Centos8 安装hadoop 2.7.7(3节点)
Posted saynaihe
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Centos8 安装hadoop 2.7.7(3节点)相关的知识,希望对你有一定的参考价值。
背景:
本地测试环境想跑点东西,就整个三节点的hadoop2.7.7吧。也跑过3.3.0的版本。本地正好跟着友凡老师的教程做些东西,他的课程都是2.6.0的版本。也不想先升级太快不匹配各种找问题了。就找了个2.7.7的包本地跑一跑了
基础环境
| 主机名 | ip | 系统 |
|---|---|---|
| hadoop1 | 192.168.0.192 | centos8.2 |
| hadoop2 | 192.168.0.192 | centos8.2 |
| hadoop3 | 192.168.0.128 | centos8.2 |
注: 关于主机名的修改hostnamectl set-hostname XXX
嗯 ,别忘了修改三台主机的hosts文件:

开始安装:
1. java环境的配置
我的java环境是提前搭建好的(hadoop1-3节点):
[root@hadoop1 hadoop]# java -version
java version "1.8.0_291"
Java(TM) SE Runtime Environment (build 1.8.0_291-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.291-b10, mixed mode
具体安装java环境如下:
https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html下载jdk包。我是下载了jdk-8u291-linux-x64.tar.gz
tar zxvf jdk-8u291-linux-x64.tar.gz
mv jdk1.8.0_291 /usr/java/jdk1.8.0_291
vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_291
export CLASSPATH=$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib
export PATH=/usr/local/mysql/bin:$JAVA_HOME/bin:$PATH

source /etc/profile
###验证版本:
java -verison

2. hadoop环境的安装
1. 下载hadoop安装包
hadoop1节点执行
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
tar zxvf hadoop-2.7.7.tar.gz
mv hadoop-2.7.7 /usr/local/hadoop
2. 用户配置
不想用root用户默认启动了,跟着大佬们的步骤创建一个hadoop用户吧!
useradd hadoop && echo 'hadoop' | passwd --stdin hadoop && for i in 1 2 3; do ssh root@hadoop${i} "useradd hadoop && echo 'hadoop' | passwd --stdin hadoop && id hadoop"; done
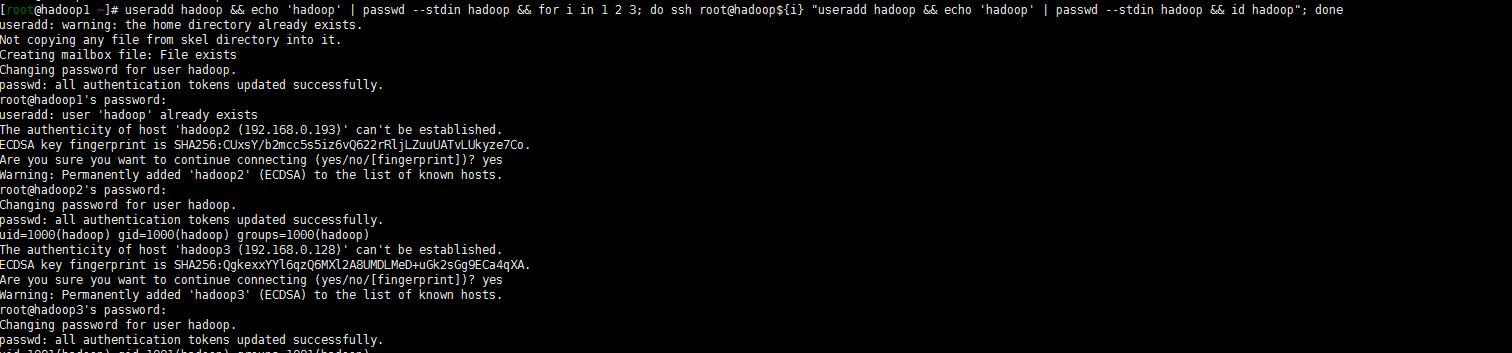
3. 设置hadoop用户秘钥登录集群每个节点
注: hadoop1节点执行
## 切换hadoop用户
su - hadoop
## 生成ssh-keygen
ssh-keygen -t rsa -P ''
## 复制ssh-key秘钥到其他节点
for i in 1 2 3; do ssh-copy-id -i .ssh/id_rsa.pub hadoop@hadoop${i}; done
## 创建所需要目录并修改目录权限
for i in 1 2 3; do ssh root@hadoop${i} "mkdir -pv /data/hadoop/hdfs/{nn,snn,dn}"; done
for i in 1 2 3; do ssh root@hadoop${i} "chown -R hadoop:hadoop /data/hadoop/hdfs/"; done
4. hadoop 配置文件调整
注: 仍然在hadoop1节点修改
vi /usr/local/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_291
vi /usr/local/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:8020</value>
</property>
</configuration>
vi /usr/local/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop1:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
</configuration>
vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hadoop/hdfs/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/hadoop/hdfs/dn</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>file:///data/hadoop/hdfs/snn</value>
</property>
<property>
<name>fs.checkpoint.edits.dir</name>
<value>file:///data/hadoop/hdfs/snn</value>
</property>
</configuration>
vim /usr/local/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vi /usr/local/hadoop/etc/hadoop/slaves
hadoop2
hadoop3
5. 将hadoop文件同步到其他节点(hadoop2 hadoop3)
for i in 2 3; do scp -r /usr/local/hadoop hadoop${i}:/usr/local/hadoop/; done
注意:记录检查一下目录文件的权限 /usr/local/hadoop目录下文件权限都chown -R hadoop:hadoop *下。 还有/data/hadoop目录下权限!
6. 将hadoop系统变量添加到profile
vi /etc/profile
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_PREFIX=/usr/local/hadoop
export PATH=$PATH:${HADOOP_PREFIX}/bin:${HADOOP_PREFIX}/sbin
export HADOOP_YARN_HOME=${HADOOP_PREFIX}
export HADOOP_MAPPERD_HOME=${HADOOP_PREFIX}
export HADOOP_COMMON_HOME=${HADOOP_PREFIX}
export HADOOP_HDFS_HOME=${HADOOP_PREFIX}
source /etc/profile
7. hadoop初始化-格式化hdfs
su - hadoop
hdfs namenode -format
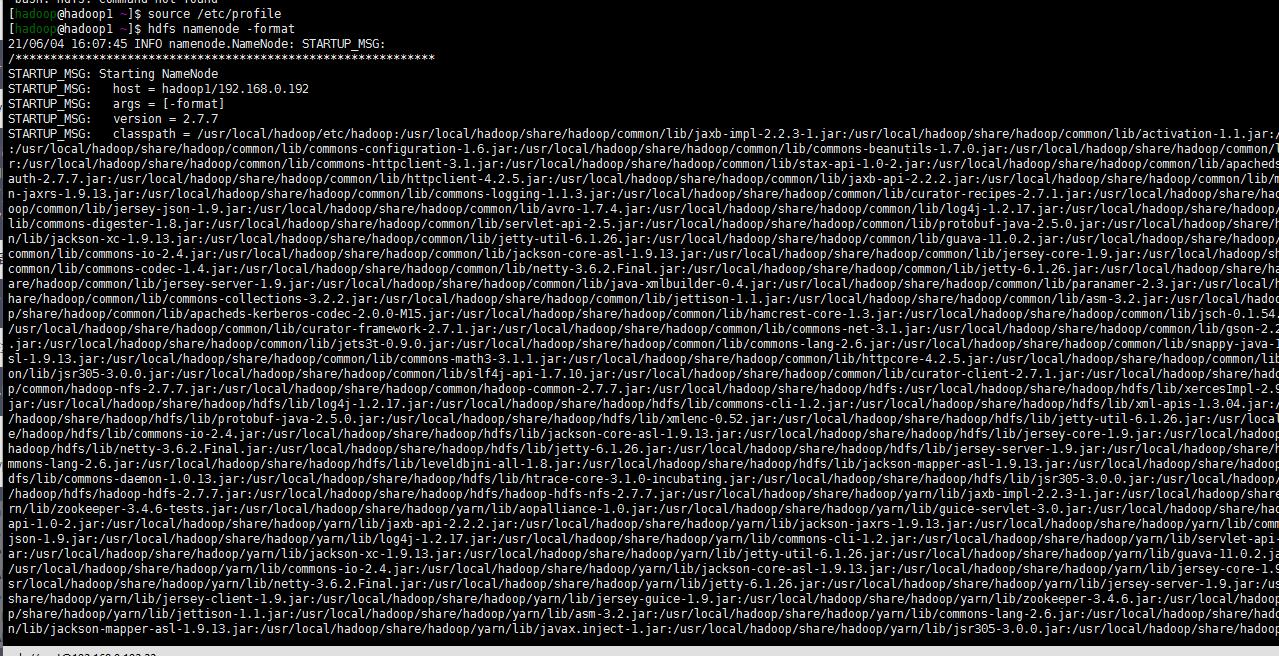
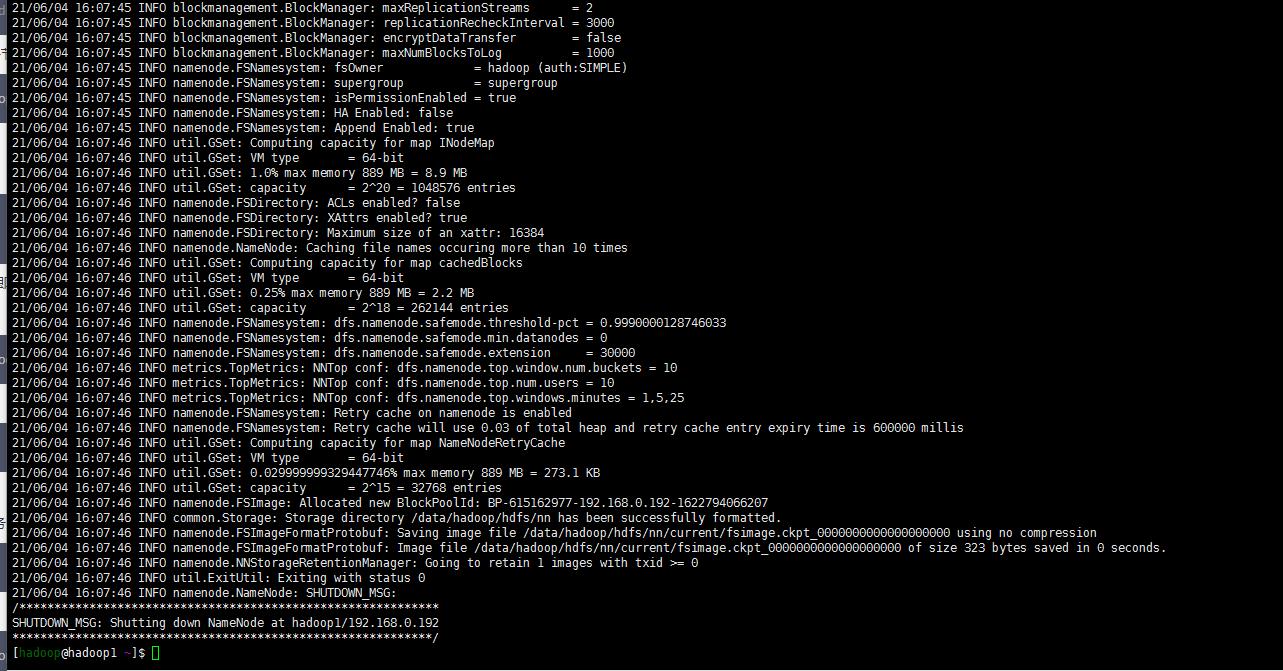
8. 启动dfs yarn 服务
start-dfs.sh
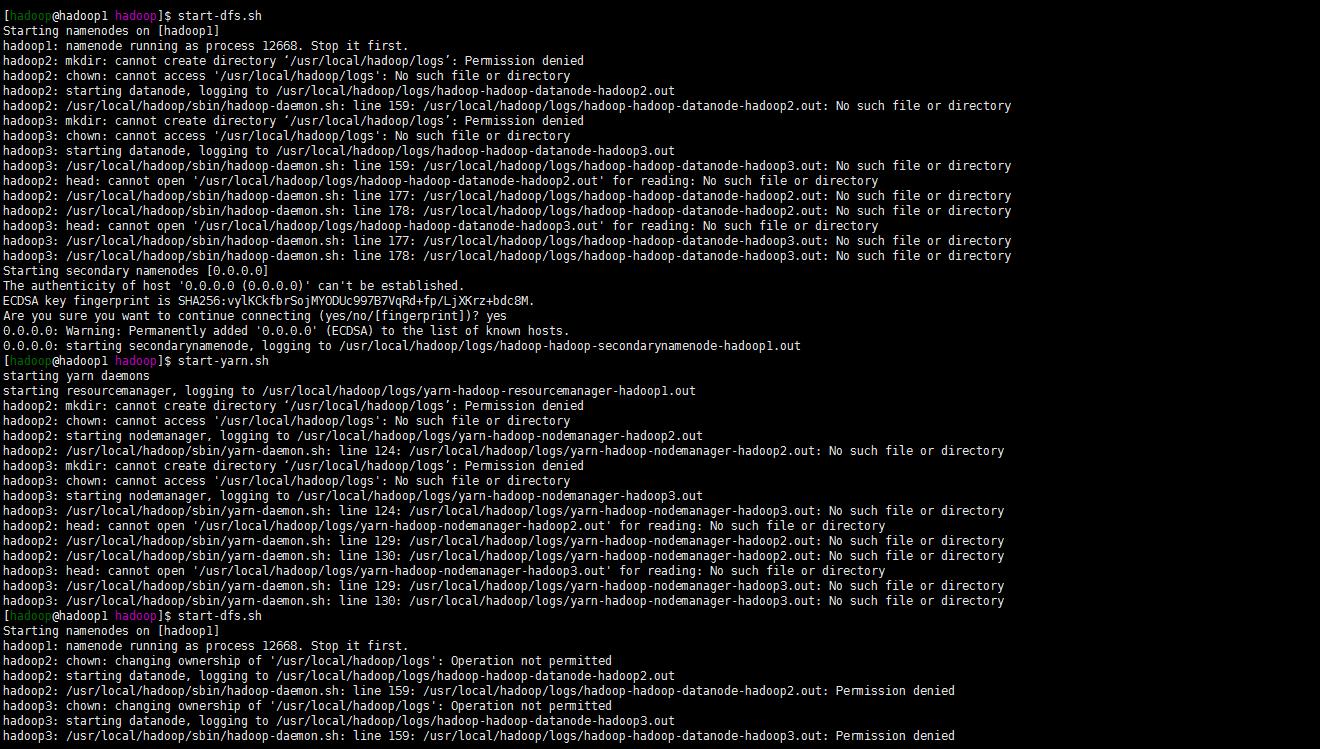
嗯报错了目录权限的问题。
cd /usr/local/hadoop
chown hadoop.hadoop -R logs
重新启动yarn与dfs。当然了也有可能还没有创建logs目录。手动创建一下啊可以。关键注意的还是目录的权限

9. web访问hadoop对应服务
嗯可以绑定host 的方式访问hadoop1:50070
也可以直接http://192.168.0.192:50070/

访问yarn
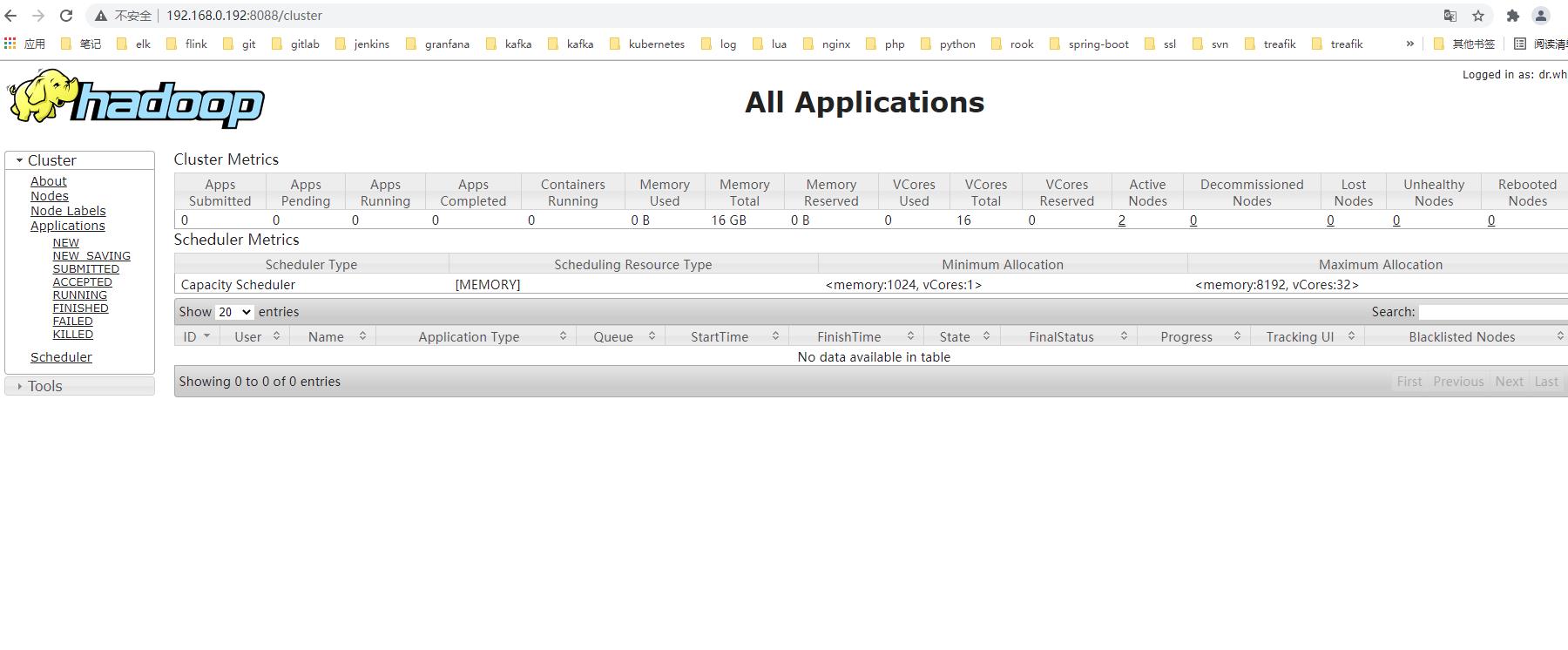
关于日志的查看就直接去/user/local/hadoop/logs目录下查看就可以了!
总结:
1. 文件目录的权限
2. 环境变量的正确配置
3. scp chown等命令的高效使用
以上是关于Centos8 安装hadoop 2.7.7(3节点)的主要内容,如果未能解决你的问题,请参考以下文章