投递简历总是石沉大海?HR表现的机会都不给你?Python爬虫实战:简历模板采集
Posted 五包辣条!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了投递简历总是石沉大海?HR表现的机会都不给你?Python爬虫实战:简历模板采集相关的知识,希望对你有一定的参考价值。
工具准备
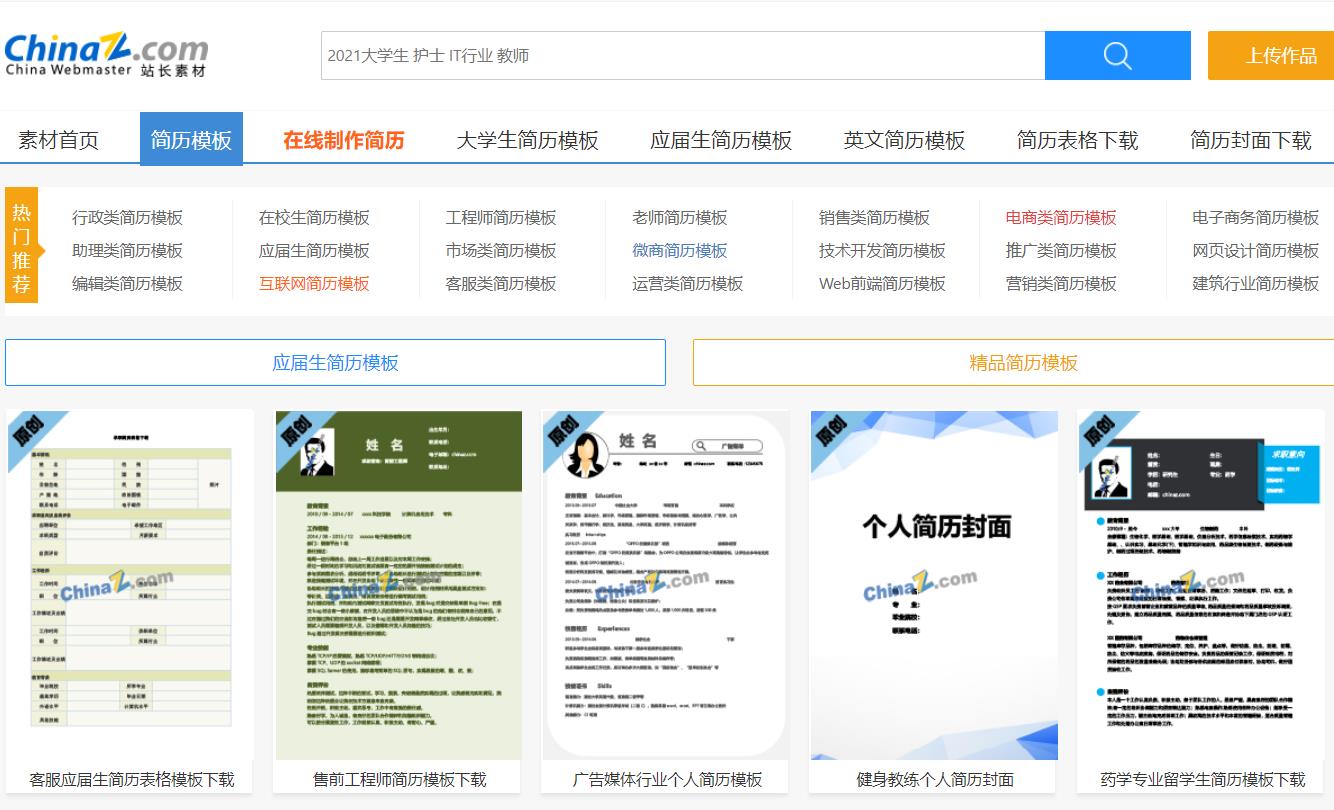
数据来源: 站长素材
开发环境:win10、python3.7
开发工具:pycharm、Chrome
项目思路解析
找到进入详情页面的超链接地址,以及对应简历的名字
提取出参数信息
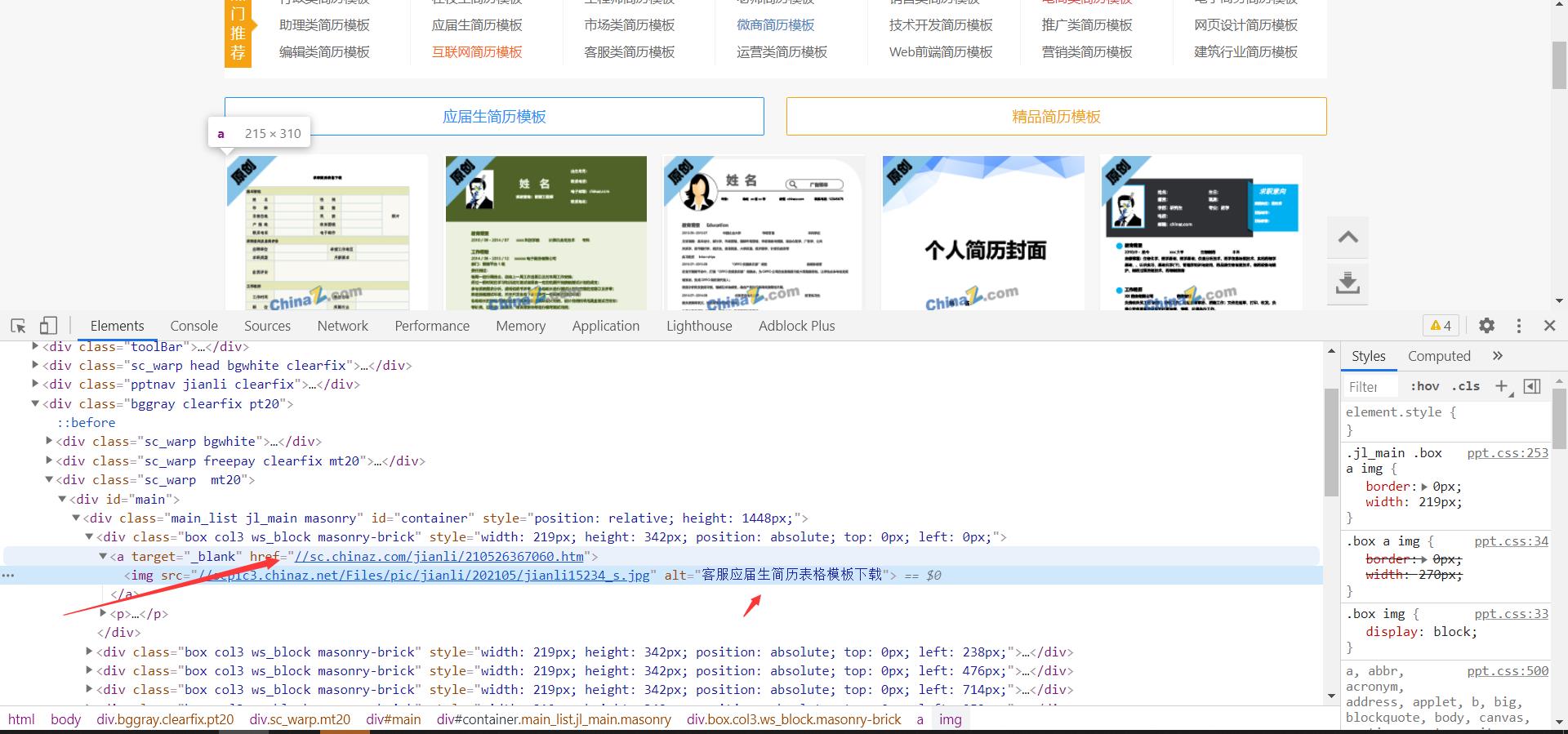
使用xpath语法的时候需要注意网页源代码跟浏览器页面渲染的页面会有出入,提取数据需要根据网页源代码来提取
html_data = etree.HTML(page)
a_list = html_data.xpath("//div[@class='box col3 ws_block']/a")
for a in a_list:
resume_href = 'https:' + a.xpath('./@href')[0]
resume_name = a.xpath('./img/@alt')[0]
进入详情页面
找到对应的详情页面的地址
提取对应rar的下载地址
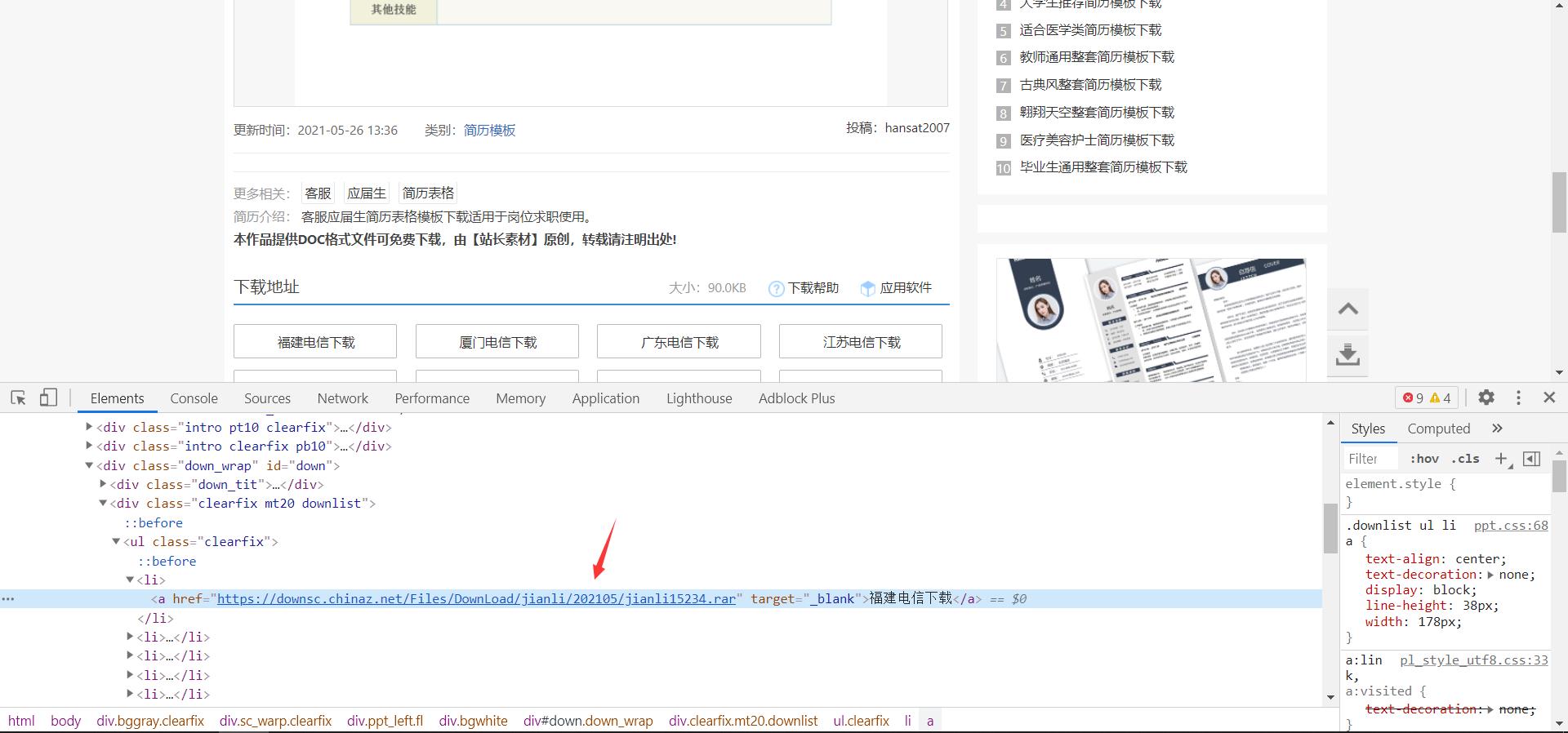
resume_tree = etree.HTML(resume_page)
resume_link = resume_tree.xpath('//ul[@class="clearfix"]/a/@href')[0]
简易源码分享
import requests
from lxml import etree
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:86.0) Gecko/20100101 Firefox/86.0',
}
for i in range(2, 10):
url = f'https://sc.chinaz.com/jianli/free_{str(i)}.html' # 设置相应的路由i
response = requests.get(url=url, headers=headers)
html_data = etree.HTML(response.text)
a_list = html_data.xpath("//div[@class='box col3 ws_block']/a")
for a in a_list:
new_url = 'https:' + a.xpath('./@href')[0]
name = a.xpath('./img/@alt')[0]
res = requests.get(url=new_url) # 进入简历模板详情页面
resume_tree = etree.HTML(res.text)
resume_url = resume_tree.xpath('//ul[@class="clearfix"]/a/@href')[0]
result = requests.get(url=resume_url, headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:86.0) Gecko/20100101 Firefox/86.0'}).content # 获取二进制数据
path = './moban/' + name + '.rar'
with open(path, 'wb') as fp:
fp.write(result) # 保存文件
以上是关于投递简历总是石沉大海?HR表现的机会都不给你?Python爬虫实战:简历模板采集的主要内容,如果未能解决你的问题,请参考以下文章
求求你,不这样写简历,我要是HR连面试机会都不给你,别说我没告诉你!
渣硕试水字节跳动,本以为简历都过不了,123+HR面直接拿到意向书