GCN与文本分类Graph Convolutional Networks for Text Classification
Posted Facico
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GCN与文本分类Graph Convolutional Networks for Text Classification相关的知识,希望对你有一定的参考价值。
TextGCN
Graph Convolutional Networks for Text Classification
https://github.com/yao8839836/text_gcn?utm_source=catalyzex.com
属于把GCN用在NLP上的开山之作,构造比较简单,效果也不错,不过使用的是最简单的“频域卷积网络”,所以速度比价慢


- 不知道作者有没有试过简易的多项式的GCN核或切比雪夫网络
构造图
边权
A i , j = { P M I ( i , j ) i,j都是单词,PMI(i,j)>0 T F − I D F i , j i是文档,j是单词 1 i = j 0 o t h e r w i s e A_{i,j}=\\left\\{ \\begin{aligned} PMI(i,j)&& \\text{i,j都是单词,PMI(i,j)>0}\\\\ TF-IDF_{i,j} &&\\text{i是文档,j是单词}\\\\ 1&& i=j\\\\ 0&& otherwise \\end{aligned}\\right. Ai,j=⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧PMI(i,j)TF−IDFi,j10i,j都是单词,PMI(i,j)>0i是文档,j是单词i=jotherwise
对于一个单词对(i,j)的PMI值为
P
M
I
(
i
,
j
)
=
log
p
(
i
,
j
)
p
(
i
)
p
(
j
)
p
(
i
,
j
)
=
l
e
n
(
W
(
i
,
j
)
)
l
e
n
(
W
)
p
(
i
)
=
l
e
n
(
W
(
i
)
)
l
e
n
(
W
)
PMI(i,j)=\\log \\frac{p(i,j)}{p(i)p(j)}\\\\ p(i,j)=\\frac{len(W(i,j))}{len(W)}\\\\ p(i)=\\frac{len(W(i))}{len(W)}\\\\
PMI(i,j)=logp(i)p(j)p(i,j)p(i,j)=len(W)len(W(i,j))p(i)=len(W)len(W(i))
- PMI表示两个词的语义相似度
对TF-IDF
- TF:词频
t f i , j = n i , j ∑ k n k , j n i , j 表 示 词 i 在 文 档 j 中 出 现 次 数 ∑ k n k , j 是 文 档 j 中 所 有 词 出 现 次 数 之 和 t f 表 示 某 个 文 档 中 某 次 的 词 频 tf_{i,j}=\\frac{n_{i,j}}{\\sum_{k}n_{k,j}}\\\\ n_{i,j}表示词i在文档j中出现次数\\\\ \\sum_{k}n_{k,j}是文档j中所有词出现次数之和 \\\\tf 表示某个文档中某次的词频\\\\ tfi,j=∑knk,jni,jni,j表示词i在文档j中出现次数k∑nk,j是文档j中所有词出现次数之和tf表示某个文档中某次的词频 - IDF:反文档频率,包含word的文档数量的反比。若包含word的文档越少,IDF越大,说明词条有更好的类别区分能力
i d f i = log ∣ D ∣ { j : t i ∈ d j } ∣ D ∣ 文 档 总 数 { j : t i ∈ d j } : 包 含 t i 的 文 档 数 目 , 反 正 分 母 为 0 通 常 + 1 idf_{i}=\\log \\frac{|D|}{\\{j:t_i\\in d_j\\}}\\\\ |D|文档总数\\\\ \\{j:t_i\\in d_j\\}:包含t_i的文档数目,反正分母为0通常+1 idfi=log{j:ti∈dj}∣D∣∣D∣文档总数{j:ti∈dj}:包含ti的文档数目,反正分母为0通常+1
T F − I D F = T F ∗ I D F TF-IDF=TF*IDF TF−IDF=TF∗IDF,值越大表示对文档越重要
GCN卷积核
A ~ = D − 1 2 A D − 1 2 \\tilde A = D^{-\\frac{1}{2}}AD^{-\\frac{1}{2}} A~=D−21AD−21
网络结构
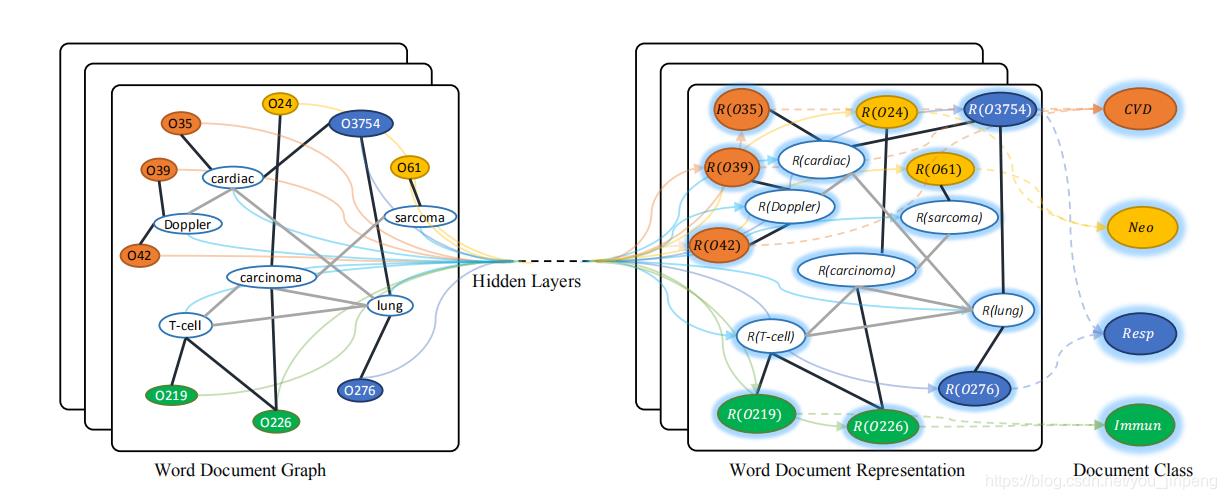
-
作者构建了两层的GCN
L ( 1 ) = ρ ( A ~ X W 0 ) 这 里 作 者 用 的 激 活 函 数 是 R e L U L ( j + 1 ) = ρ ( A ~ L ( j ) W j ) L^{(1)}=\\rho(\\tilde A X W_0)\\\\ 这里作者用的激活函数是ReLU\\\\ L^{(j+1)}=\\rho(\\tilde A L^{(j)} W_j) L(1)=ρ(A~XW0)这里作者用的激活函数是ReLUL(j+1)=ρ(A~L(j)Wj) -
分类器
Z = s o f t m a x ( A ~ R e L U ( A ~ X W 0 ) W 1 ) Z=softmax(\\tilde A ReLU(\\tilde A XW_0)W_1) Z=softmax(A~ReLU(A~XW0)W1) -
损失函数
L =以上是关于GCN与文本分类Graph Convolutional Networks for Text Classification的主要内容,如果未能解决你的问题,请参考以下文章
GCN与文本分类Graph Convolutional Networks for Text Classification
GCN与文本分类Graph Convolutional Networks for Text Classification
GCN笔记:Graph Convolution Neural Network,ChebNet