论文泛读105Transformer中微调与组合的相互作用
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读105Transformer中微调与组合的相互作用相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《On the Interplay Between Fine-tuning and Composition in Transformers》
一、摘要
预训练的 Transformer 语言模型在各种 NLP 任务上表现出卓越的性能。然而,最近的研究表明,这些模型中的短语级表示反映了词汇内容的重大影响,但缺乏复杂的、组合短语信息的证据。在这里,我们研究了微调对上下文嵌入的能力的影响,以捕获超出词汇内容的短语含义信息。具体来说,我们对具有高词汇重叠的对抗性释义分类任务和情感分类任务的模型进行了微调。在微调之后,我们在之前的工作之后分析受控设置中的短语表示。我们发现微调在很大程度上无法使这些表示中的组合性受益,尽管对情绪的训练产生了很小的、某些型号的本地化收益。在后续分析中,我们确定了复述数据集中的混杂线索,这些线索可以解释该任务缺乏作文的好处,并讨论了情感训练局部收益的潜在因素。
二、结论
我们已经测试了微调对变压器表示中短语含义构成的影响。虽然我们选择的任务有望解决作文弱点和对单词重叠的依赖,但我们发现微调模型中的表示在受控作文测试中几乎没有改善,或者仅显示非常局部的改善。后续分析表明,PAWS-QQP数据集包含虚假的线索,破坏了复杂的意义属性的学习时,训练的任务。然而,来自SST调优的结果表明,在不同大小的标记短语上进行训练对于学习作文是有效的。未来的工作应该研究模型属性如何与微调相互作用,以在特定的模型和层中产生改进——并且应该转向具有丰富意义注释的短语级训练,我们预测这将是改进模型短语意义组成的有前途的方向。
三、模型
选择了两个不同的数据集,它们具有解决这些弱点的有希望的特征。我们对这些任务进行微调,然后对微调后的模型中的上下文化表示进行分层测试,并与预训练模型的结果进行比较。
- PAWS-QQP数据集,正反均有很高的词汇重叠度。
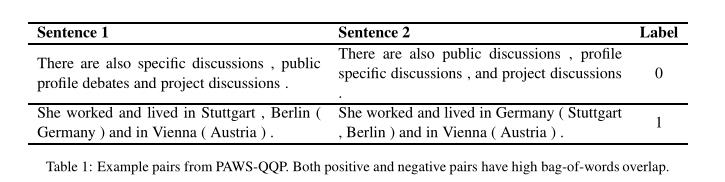
- SST
与短语合成的训练和评估相关联的数据集是斯坦福情感树库,它包含各种长度的句法短语,以及这些短语的细粒度人工注释情感标签。因为该数据集包含各种大小的组合短语的注释,所以我们可以合理地期望在该数据集上的训练可以培养对组合短语含义的增加的敏感性。
以上是关于论文泛读105Transformer中微调与组合的相互作用的主要内容,如果未能解决你的问题,请参考以下文章
论文泛读151Transformer-F:具有学习通用句子表示的有效方法的 Transformer 网络
论文泛读200通过适配器使用预训练语言模型进行稳健的迁移学习
论文泛读200通过适配器使用预训练语言模型进行稳健的迁移学习