论文泛读194用于中文评论文本的中文情感分析的 Transformer-Encoder-GRU (TE-GRU)
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读194用于中文评论文本的中文情感分析的 Transformer-Encoder-GRU (TE-GRU)相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《Transformer-Encoder-GRU (T-E-GRU) for Chinese Sentiment Analysis on Chinese Comment Text》
一、摘要
由于其复杂性和不确定性,中文情感分析(CSA)一直是自然语言处理中的挑战之一。Transformer 已经成功地捕捉到语义特征,但是它使用位置编码来捕捉序列特征,与循环模型相比有很大的缺点。在本文中,我们提出了用于中文情感分析的 TE-GRU,它结合了Transformer、Encoder和 GRU。我们对三个中文评论数据集进行了实验。针对中文评论文本中标点符号的混淆,我们选择性地保留了一些具有分句能力的标点符号。实验结果表明,TE-GRU 优于经典循环模型和注意力循环模型。
二、结论
在三个未经严格清洗的真实中文评论数据集上,我们保留了具有子句能力的标点符号作为预处理。然后我们将我们提出的T-E-GRU模型与各种递归模型和注意递归模型进行了比较。在测试集上,与其他模型中的最佳表现相比,T-E-GRU在准确性和F1上有1%的提升。
三、模型
T-E-GRU模型:
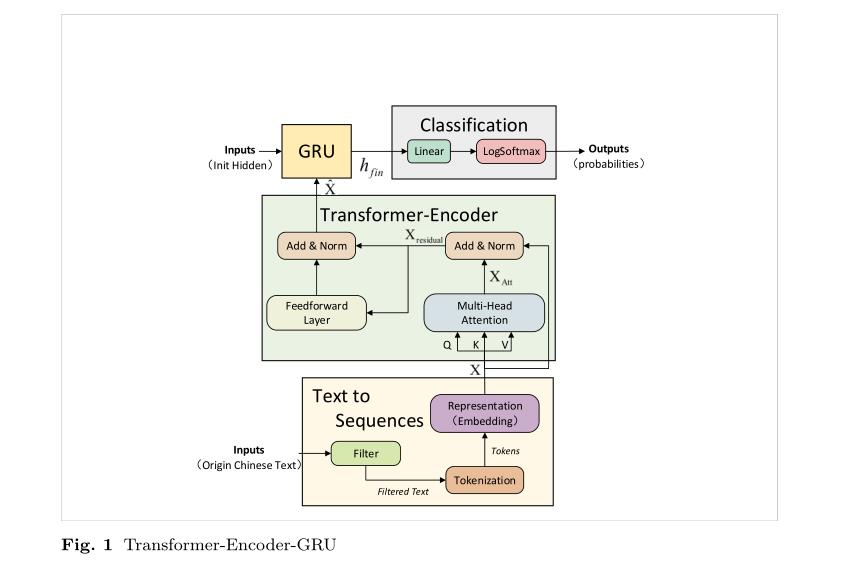
transformer具有强大的全局特征提取能力,非常适合CSA。递归模型是一种自然的序列结构,非常适合捕捉序列特征。特别是,由于其与LSTM相似的性能和更便宜的计算,GRU已经成为最好的循环模型之一。
T-E-GRU结合了变压器-编码器和GRU,与递归模型相比,T-E-GRU变压器-编码器中的多头自关注机制和残差连接可以更好地配合长序列信息的丢失。与transformer不同的是,T-E-GRU使用GRU提取序列特征,而不是位置编码,可以更好地处理文本情感依赖词序的问题。此外,与关注的递归模型相比,T-E-GRU结合了在自然语言处理中取得良好效果的变压器结构。
以上是关于论文泛读194用于中文评论文本的中文情感分析的 Transformer-Encoder-GRU (TE-GRU)的主要内容,如果未能解决你的问题,请参考以下文章