安全实验室 | HTTP走私攻击原理分析
Posted 第59号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了安全实验室 | HTTP走私攻击原理分析相关的知识,希望对你有一定的参考价值。
当今网络环境下攻击手段层出不穷,企业在疲于应对APT等攻击时,策略及资源将会慢慢倾斜,导致很多企业忽视了一些爆出较久、利用危害不大的漏洞。这种想法本身是错误的,千万不要轻视任何一个看起来没什么危险的漏洞,但这些漏洞打出“组合拳”时,其威力也相当可怕。
本期美创安全实验室将给大家分析一种黑客常用的攻击漏洞也就是HTTP走私漏洞的原理。
漏洞简介
HTTP走私漏洞最早是在2005年由Watchfire记录的。看漏洞名字就知道,这是一个与HTTP协议相关的漏洞。在目前的网络环境下,很多网站都是采用前后端分离的方式进行开发的,但不同的服务器可能会有不同的方式实现RFC协议标准,这时候攻击者就可能利用前后端服务器对数据包的边界了解不一致的情况,向一个请求数据包中插入下一个请求数据包的一部分,这样可能在前端看来这是一个完整的数据包,但在后端看来这是两个数据包,从而绕过一些安全控制,未经授权的访问敏感数据甚至突破边界。
简单来说,这个漏洞就是攻击者在经过不断地探索之后,大概摸清了前后端对数据包的处理方式,然后以某种形式,例如将两个数据包合并成一个,发送给后端,后端可能会成功解析两个数据包,从而绕过前面的安全机制。
漏洞形成原理
那么究竟是为什么会产生这种情况呢?这里我们要先介绍2个概念:HTTP Pipelining和Transfer-Encoding。在HTTP1.1之后,新增了一个特殊的请求头Connection:Keep-Alive,这个字段的意思是表示这是一个长连接。说到长连接,就不得不提一下TCP握手了,众所周知,HTTP是运行在TCP上一层的协议,而TCP本身就有启动慢的特点,所以为了尽可能提高HTTP的性能,长连接诞生了。
使用异步技术可以将多个http请求批量提交,而不用等收到响应再开始下一个请求。
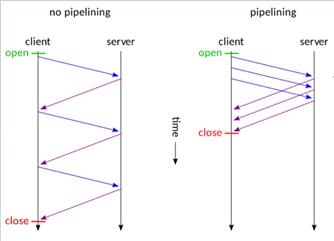
然后我们再说Transfer-Encoding这一概念,在以前我们有一个指标Content-Length能够帮助我们识别一个数据包的边界,浏览器可以通过Content-Length的长度信息,判断出响应实体已结束,但随着现在服务端为了用户的体验,想要缓存所有内容以降低TTFB的值,所以现在我们急需一个新的机制能够不依赖头部的长度信息,就能知道实体的边界。
对没错,Transfer-Encoding出来救场了,Transfer-Encoding虽然也是一个头信息,但是他其实表示的是分块编码,当我们使用了这个报文头后,就代表报文采用了分块编码,这时报文中的实体需要改为用一系列分块来传输。每个分块包含十六进制的长度值和数据,长度值独占一行,长度不包括它结尾的 CRLF(\r\n),也不包括分块数据结尾的 CRLF。最后一个分块长度值必须为 0,对应的分块数据没有内容,表示实体结束。
Ok。相关的概念我们都清楚了,从HTTP1.1开始,就已经支持了通过TCP发送多个HTTP请求,服务器解析标头以计算出每个结束的位置以及下一个开始的位置,虽然这听起来是很合理的设计,但仔细想想,这意味着后端服务器与前端服务器就每个消息的结束位置必须要统一,否则,如果攻击者发送一个模糊不清的请求,该请求被后端解释为一个完整的请求加上残缺的下一个请求,这样就会产生HTTP走私漏洞。
HTTP走私漏洞分类
1. Content-Length + Content-Length情况:
假设前后端后允许接收一个数据包中含有两个Content-Length,且前端优先考虑第一个内容长度,而后端优先考虑第二个内容长度,因此攻击者可以构造如下数据包:
POST /HTTP/1.1
Host: example.com
Content-Length: 5
Content-Length: 4
1234A
这样前端读取到第一个内容长度为5,就将整个数据包发送给后端,而后端通过读取第二个内容长度后,将对数据包中红色内容发起响应,而遗留下来的蓝色内容A,将被存储在缓冲区内,并于下一个数据包进行拼接后执行,这样就会导致服务器出错,引起意外响应。虽然这种情况发生的难度太高,而且RFC7230已经规定了服务器当收到请求中包含两个Content-Length且两者的值不同时,需要返回400错误,但难免会有服务器不严格遵守规范的情况发生。
2. Content-Length + Transfer-Encoding情况:
顾名思义,一个数据包可能既存在Content-Length报文头也可能存在Transfer-Encoding报文头,假设前端按照Content-Length来定义数据包边界,而后端则以Transfer-Encoding报文头为准。那么攻击者可能构造如下数据包:
POST /HTTP/1.1
Host:example.com
Content-Length:6
Transfer-Encoding:chunked
0
A
这样前端读取到CL字段为6,所以会将整个数据包发送给后端,而后端通过读取TE的标头,明确了报文实体采用了分块编码的方式,分块编码是有特定的格式,前一行为分块编码大小,后一行为具体的数值,最终以0为结尾,所以后端只对数据包中的红色部分进行响应,遗留下的A会被留在缓冲区中,等待后续请求的到来,最终造成异常。
3. Transfer-Encoding + Content-Length情况:
同第二种方法类似,这次是前端根据Transfer-Encoding来定义数据包边界,后端根据Content-Length来定义边界。那么攻击者可能构造如下数据包:
POST /HTTP/1.1
Host:example.com
Content-Length:3
Transfer-Encoding:chunked
1
A
0\r\n
前端在接收到TE的报文头后,明确报文实体采用了分块编码方式,并且以0为结束,发送给后端。后端在接收到了报文中的CL后,明确报文实体长度为3,也就是到红色内容处进行响应,遗留下来的A\r\n\r\n0\r\n将被留在缓冲区中,与下一个请求拼接,从而造成异常。
4. Transfer-Encoding + Transfer-Encoding情况:
当一个数据包中存在两个Transfer-Encoding报文头时并不会引起任何错误,因为RFC中规定了可以允许这种情况的发生,但这样就没有什么意义了,所以一般情况攻击者会利用第二个TE头混淆分块编码的主体,让隐藏在是实体之中的CL执行,假设前端接收第一个TE值、后端接受第二个TE值,攻击者可能构造如下代码:
POST/ HTTP/1.1
Host:example.com
Transfer-Encoding:chunked
Transfer-Encoding:xxx
5c
GPOST / HTTP/1.1
Content-Type:application/x-www-form-urlencoded
Content-Length:15
A=1
0
前端在接收到第一个TE时,明确实体采用分块编码,并识别到最末端数据0表示实体结束,将整个数据包传送给后端,后端解析第二个TE,发现格式错误,这时候默认执行CL报文头,所以这个数据包就被拆分成了两个数据包被后端执行并响应了。
漏洞检测方法
1. 根据延时查找CL+TE或TE+CL漏洞:
可以发送如下请求:
POST / HTTP/1.1
Host:example.com
Transfer-Encoding:chunked
Content-Length:4
1
A
X
类似的这种请求,通常都会导致时间延迟,因为遗留在缓存区的内容需要下一个数据包到达才能结束响应,因此会有明显的延迟效应。同理针对TE+CL漏洞,只要稍微修改一下测试数据包即可。
2. 据差异响应确认HTTP请求走私漏洞:
可以发送如下数据包:
POST/search HTTP/1.1
Host: vulnerable-website.com
Content-Length:50
Transfer-Encoding:chunked
e
q=smuggling&x=
0
GET /404HTTP/1.1
Foo: x
前端服务器根据CL的解析,将全部内容都发送给后端,而后端根据TE的存在,将其分成了两个数据包:
POST/search HTTP/1.1
Host:vulnerable-website.com
Content-Length:50
Transfer-Encoding:chunked
e
q=smuggling&x=
0
和
GET /404HTTP/1.1
Foo: x
可见最后两行被保留在缓冲区中,一旦他们与下一个数据包的信息拼接在了一起,将会导致数据包格式错误,返回404页面,证明确实存在CL+TE漏洞。
防御修复方案
在前端服务器通过同一网络连接将多个请求转发到后端服务器的情况下,会出现HTTP请求走私漏洞,并且后端连接所使用的协议有可能会造成边界不统一的风险。防止HTTP请求走私漏洞的一些通用方法如下:
❖ 使用HTTP / 2进行后端连接,因为此协议可防止对请求之间的边界产生歧义。
❖ 前端服务器和后端服务器使用完全相同的Web服务器软件,以便它们就请求之间的界限达成一致。
以上是关于安全实验室 | HTTP走私攻击原理分析的主要内容,如果未能解决你的问题,请参考以下文章