小白视角的大数据基础实践Hadoop环境搭建与测试
Posted 小生凡一
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小白视角的大数据基础实践Hadoop环境搭建与测试相关的知识,希望对你有一定的参考价值。
1.简介
实验环境
- Vmware (Ubuntu18.04)
- Java 1.8
- Hadoop 3.1.3

1.1基础知识
- Hadoop是一个由Apache基金会所开发的开源分布式计算平台,为了让用户可以在不了解分布式底层细节的情况下开发分布式程序。
- Hadoop是一个基础架构系统,是Google的云计算基础架构的开源实现,主要由HDFS、MapReduce组成,其中HDFS是Google的GFS的开源实现,MapReduce是Google的MapReduce的开源实现。HDFS为海量的数据提供了存储,MapReduce为海量的数据提供了计算。
- Hadoop是基于Java语言开发的,具有很好的跨平台特性,并且可以部署在廉价的计算机集群中。
- 简单来说,Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台,充分利用集群的威力进行高速运算和存储。
1.2 特点
Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,它具有以下几个方面的特性
- 高可靠性
- 高效性
- 高可扩展性
- 高容错性
- 成本低
- 运行在Linux平台上
- 支持多种编程语言
1.3 生态系统
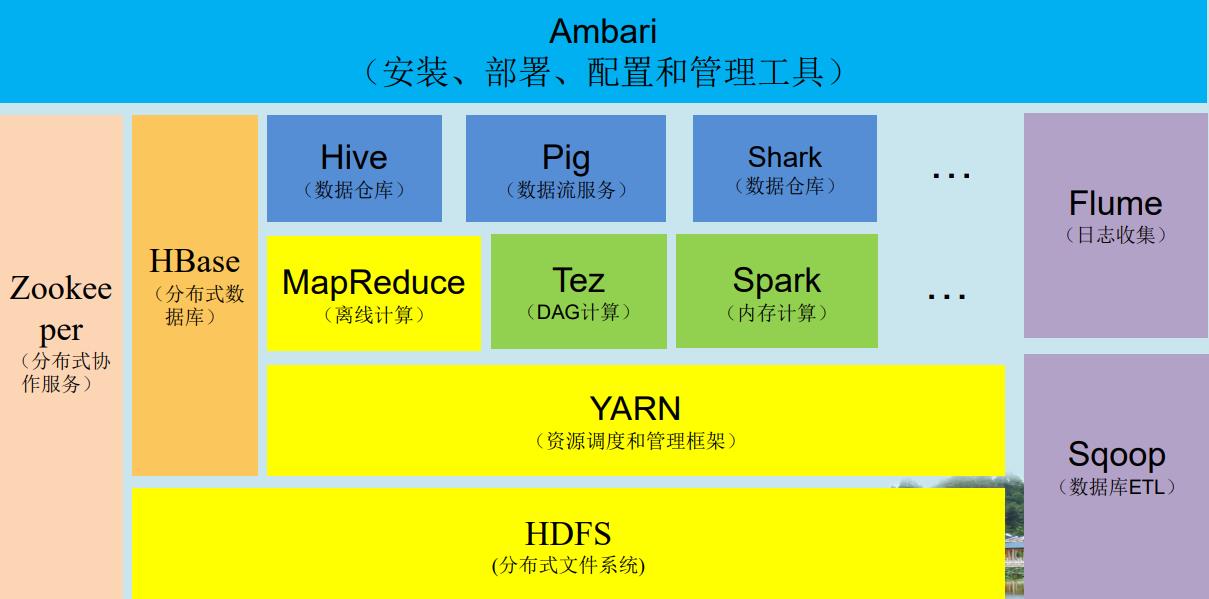
1.3.1 HDFS
一款分布式文件系统,来源于2003年10月Google发表的GFS论文,是Hadoop体系中数据存储管理的基础,两大核心之一。HDFS具有高容错性,在设计上HDFS把硬件故障当成常态来考虑,所以它能检测到出现故障的硬件,并加以解决,不仅体现它的可靠性。HDFS通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
1.3.2 YARN
YARN是为在现有的和新的Hadoop集群上工作而设计的资源调度器。从Apache Hadoop2.0版本开始,YARN不但为已有的MapReduce应用提供了全面的兼容,也致力于支持几乎所有的分布式应用,实现了在Hadoop框架上运行其他非MapReduce作业
1.3.3 MapReduce
一种计算模型,来源于2004年12月Google发表的一篇关于MapReduce的论文,可用于海量数据的计算。其中,Map函数对数据集上的独立元素进行指定的操作,生成Key-Value对形式的中间结果。Reduce函数则对Map函数得到的所有Key-Value对中相同Key的所有Value进行规约来得到最后的结果,简单地说,就是“分而治之”。MapReduce适用于大量计算机组成的分布式并行环境。
1.3.4 Zookeeper
一种分布式的、可用性高的协调服务,来源于2006年11月Google发表的Chubby论文。Zookeeper提供分布式锁之类的基本服务用于构建分布式应用。
1.3.5 HBase
一种分布式的、按列存储的数据库,来源于2006年11月Google发表的Bigtable论文。HBase采用了BigTable的数据模型:增强的稀疏排序映射表(key/value),其中键由行关键字、列关键字和时间戳构成。HBase使用HDFS作为底层存储,同时支持MapReduce的批量试计算和点查询(随机读取),它将数据存储和并行计算完美地结合在一起。
1.3.6 Hive
Hive由Facebook开源,最初用于解决海量结构化的日志数据统计问题,一种分布式的、按列存储的数据仓库。Hive管理HDFS中存储的数据,并提供基于SQL的查询语句HQL,将SQL转化为MapReduce任务在Hadoop上执行,用以查询数据。
1.3.7 Pig
数据流语言和运行环境,由Yahoo开源,用以探究非常庞大的数据集。Pig运行在MapReduce和HDFS集群上。
1.3.8 Mahout
Mahout最初是Apache Lucent的子项目,随着它的快速发展,如今已经是Apache的顶级项目。Mahout包含了分类、聚类、推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。除此之外,Mahout还包含数据的输入/输出工具和与其他存储系统集成等数据挖掘支持架构。
1.3.9 Sqoop
Sqoop是SQL-to-Hadoop的缩写,该工具用于在结构化数据存储(如关系型数据库)和HDFS之间高效批量传输数据。数据的导入和导出本质上是MapReduce程序,充分利用了MR的并行化和容错性。
1.3.10 Flume
Flume是Cloudera开源的日志收集系统,具有分布式、高可靠、高容错、易于定制和扩展的特点。它将数据从产生到传输再到处理以及最后写入目标路径的过程抽象为数据流,在具体的数据流中,数据源支持在Flume中定制数据发送方,从而支持收集各种不同协议数据。同时,Flume数据流提供对日志数据进行简单处理的能力。除此之外,Flume还具有能够将日志写入各种数据目标(可定制)的能力。总的来说,Flume是一个可扩展、适合复杂环境的海量日志收集系统。
2. Hadoop 安装于环境配置
2.1 解压Hadoop压缩包
cd 进入 Hadoop 安装包存放位置,执行 tar 命令将 hadoop-3.1.3.tar.gz 解压到/usr/local 目录下,ls 查看是否生成了 hadoop3.1.3 文件夹。
2.2 Hadoop环境变量配置
编辑用户环境配置文件
cd /usr/local
sudo vim ~/.bashrc
配置HADOOP_HOME、PATH环境变量,保存并退出文件

执行命令使环境生效
. ~/.bashrc
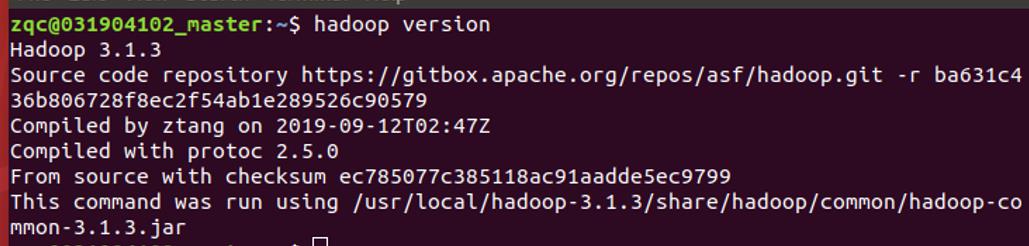
测试环境是否成功
3. 单机模式
3.1 特点
- 无需运行任何守护进程,所有程序都在同一个JVM上执行,在独立模式上测试和调试MapReduce程序非常方便,因此该模式比较适合开发阶段。
- Hadoop 的默认模式为单机模式(本地模式\\非分布式),不需要进行其它配置即可运行。Hadoop 附带了丰富的例子,包括 workcount、grep、join 等,下面运行 grep 例子来感受 Hadoop运行。
3.2 配置
用户主目录中新建 input 文件夹存放输入数据文件:

拷贝 Hadoop 安装目录下/etc/hadoop 中所有的 XML 文件到 input 文件夹中:

3.3 执行例子
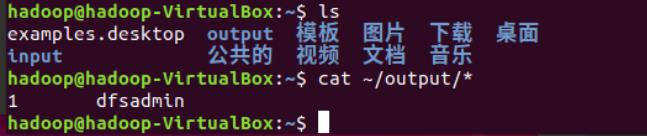
**注意:**Hadoop 默认不会覆盖结果文件,因此再次运行上面实例会提示出错,需要先将output 删除。查看当前目录下的文件,多出了 output 文件夹,cat 命令查看结果打印到屏幕上。
4. 伪分布模式
4.1 特点
- Hadoop守护进程运行在本地机器上,模拟一个小规模的集群,该模式下的Hadoop集群实现的并不是真正的集群状态。
- Hadoop 伪分布式配置是在没有多台计算机节点的情况下,对 Hadoop 的分布式存储和计算进行模拟安装和配置。
4.2 SSH 免密登陆
这个在第一篇已经写了如何进行ssh免密登陆,这里就不多说了。
链接在这 搭建Hadoop集群
4.3 修改Hadoop配置文件
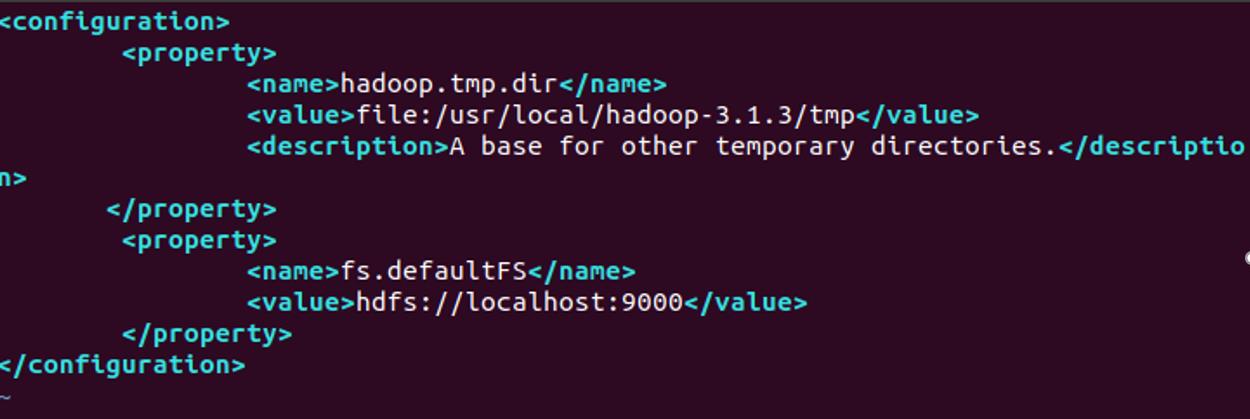
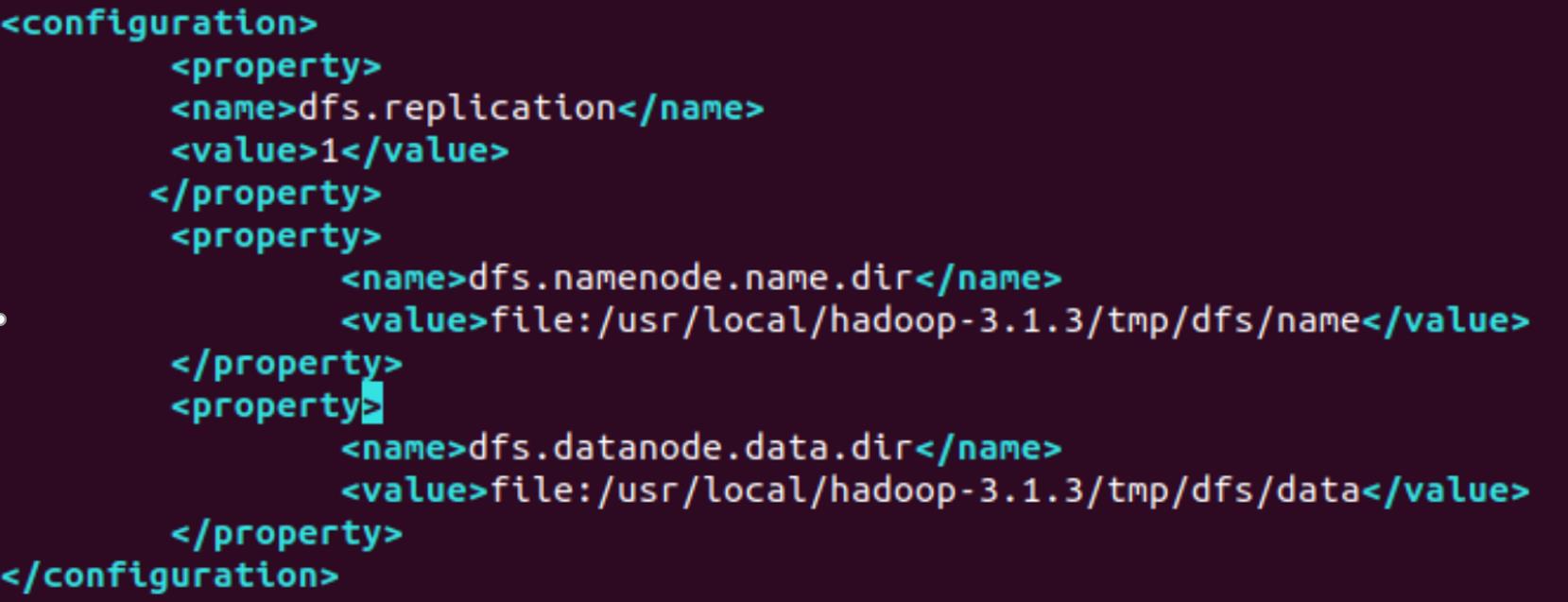
Hadoop 的配置文件位于安装目录的/etc/hadoop/下,伪分布式模式配置需要修改配置文件 core-site.xml 和 hdfs-site.xml。
core-site.xml 配置文件
hdfs-site.xml配置文件
4.4 初始化
hdfs namenode -format
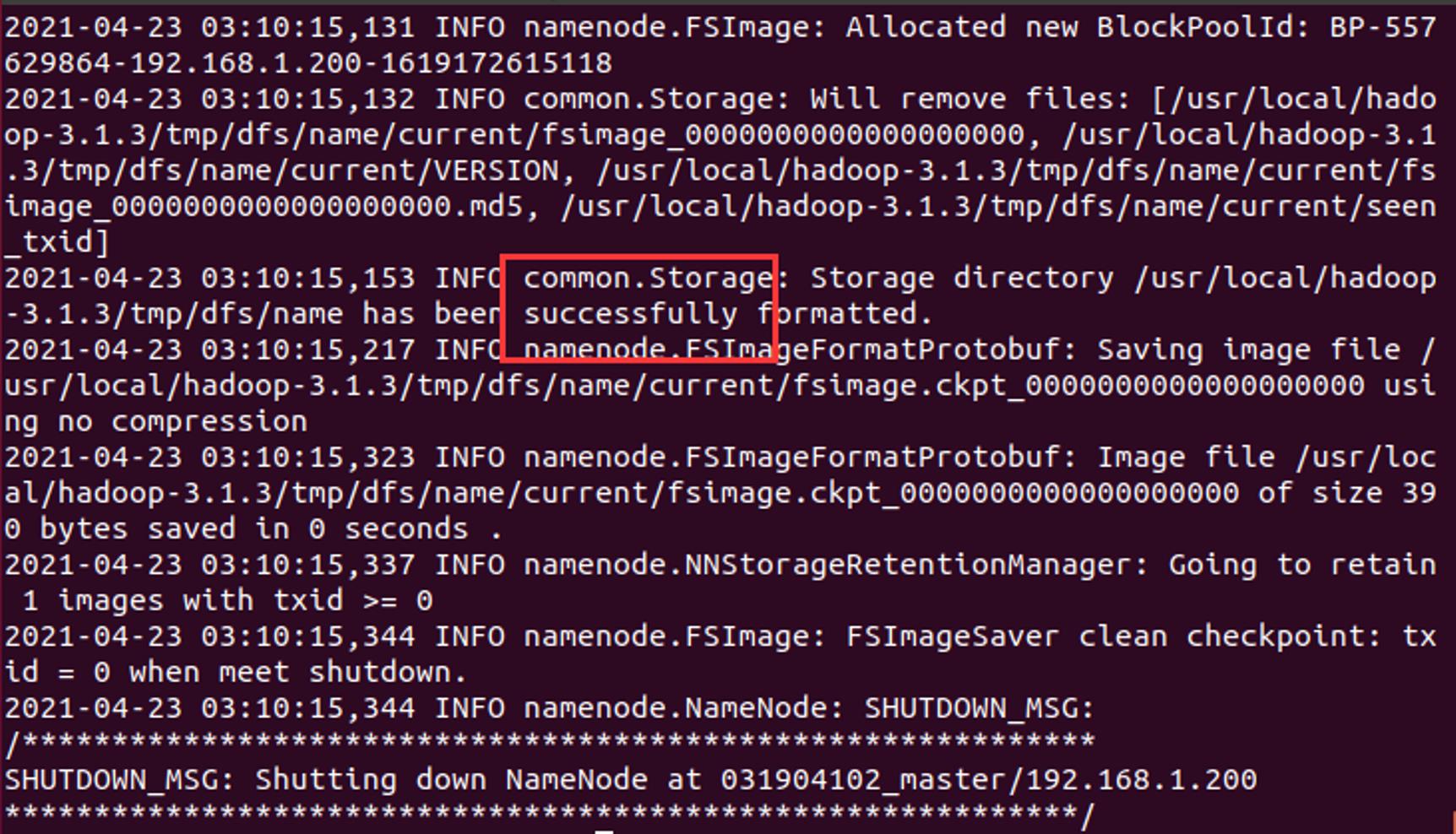
找到Successfully就可以了
先对配置文件进行配置,一开始以为localhost改成031904102_master导致失败,一直start不起来,后来才改成了localhost,localhost是对应127.0.0.1,是本机的localhost,而031904102_master对应的是192.168.1.200,对不上,所有后面连不上。
start-dfs.sh
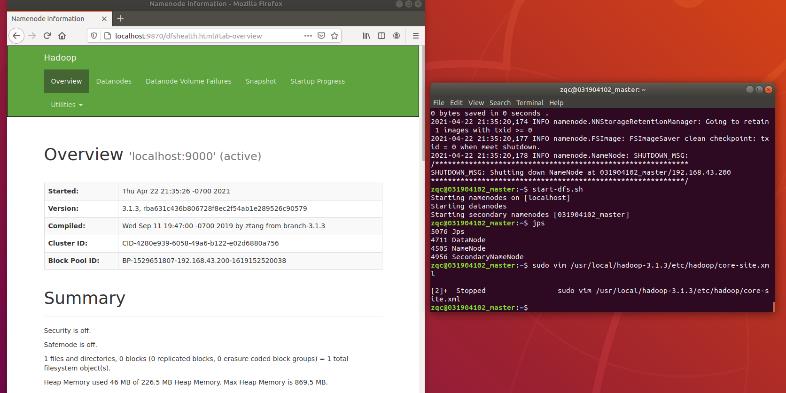
执行命令 jps 验证是否成功启动,成功启动应包含如下进程。如果没有启动成功,可以通过启动日志排查原因,日志位于安装目录的 logs 文件夹下后缀为.log。(根据错误信息具体问题要具体分析。确认配置文件没有错误,一般可以尝试关闭 stop-dfs.sh 后再启动 start-dfs.sh;或者可以尝试删除安装目录下整个 tmp 文件,重新执行 namenode –format。)
4.3 执行
- 在hadoop上创建文件
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/hadoop
hdfs dfs -mkdir /user/hadoop/input
查看hadoop是否创建成功文件
hdfs dfs -ls /user/hadoop
- 将/etc/hadoop 目录下所有的 XML 文件上传至 input 文件夹:
hdfs dfs -put 原路径 目的路径
hdfs dfs -put /usr/local/hadoop-3.1.3/etc/hadoop*.xml input
查看是否存在input中
hdfs dfs -ls /user/hadoop/input
- 执行 MapReduce 的 grep例子,将结果存放到 output 文件夹中,然后在分布式文件系统上查看结果:
hadoop jar /usr/local/hadoop-3.1.3/etc/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep input output 'dfs[a-z.]+'
在分布式文件系统上查看结果
hdfs dfs -cat output/*
5. 全分布模式
注意 :更改主机名称之后,要重新配置ssh密钥!!!!
注意主机名不要有 _ 要用-代替!!!!!
不要111111_xxxx 要11111-xxx 不然报错!我就是这样!下面这些例子时我修改前的,没成功,但是步骤是一样的,后来改回来之后重新做了一遍,忘记截图了。
5.1 特点
与伪分布模式的区别在于其守护进程运行在一个集群上,通常采用全分布模式来整合集群环境下的所有资源。
5.2 集群准备
- 准备两台虚拟机(直接克隆复制已有的虚拟机):一台作为主节点 Master,一台
作为从节点 Slave; - Mater 节点要求:安装 SSH server、配置 Java 环境、安装 Hadoop;
- Slave 节点要求:安装 SSH server、配置 Java 环境。
以上内容在第一篇的时候已经说好了!Slave,就是克隆
注意:如果节点是直接克隆配置好伪分布式模式的虚拟机,需要删除 hadoop目录下的 tmp 文件夹和 logs 文件夹,或者删除原有 Hadoop 安装路径下的所有文件夹,重新进行解压和环境配置。
5.3 网络配置
两个节点 IP 配置如下,请依据计算机实际情况进行 IP 地址和主机名分配。
主机名 IP 地址
Master 192.168.1.10
Slave 192.168.1.11
- 虚拟机设置桥接网络,Ubuntu 系统内设置静态 IP,使节点之间网络互通。具体设置查看“关于 VirtualBox 的虚拟机复制及 Ubuntu 系统的静态 IP 配置”文档、“关于 VMware workstations 中 Ubuntu 系统的静态 ip 配置”文档。
- 修改/etc/hostsname 文件,更改节点主机名为“031904102-Master”和“031904102-Slave”
没截图,按照老师的样子截了个图
sudo vim /etc/hostsname
3. 改/etc/hosts 文件,更改 IP 映射关系,所有节点都要修改。hosts 文件原有映射保留一条 localhost 其余删除,再插入两个节点的 IP 地址映射,注意主机名和 IP 地址不要对应错了,主机名区分大小写。
sudo vim /etc/hosts
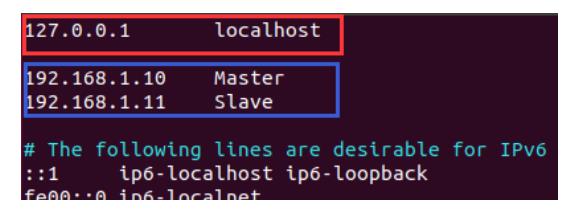
重启之后生效即可
reboot
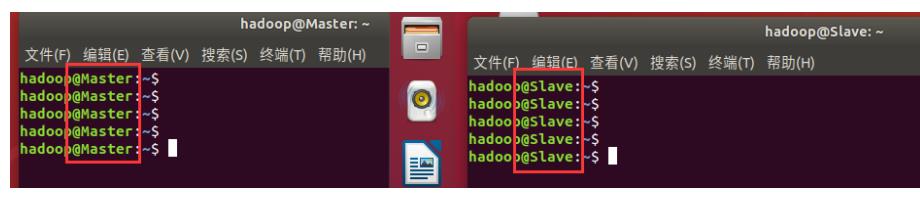
上面这个还是老师的图,老师是master
下面这个是我的,我的是031904102-Master 注意不要像下面那样下划线 “ _ ” !!
检查master和slave能否ping通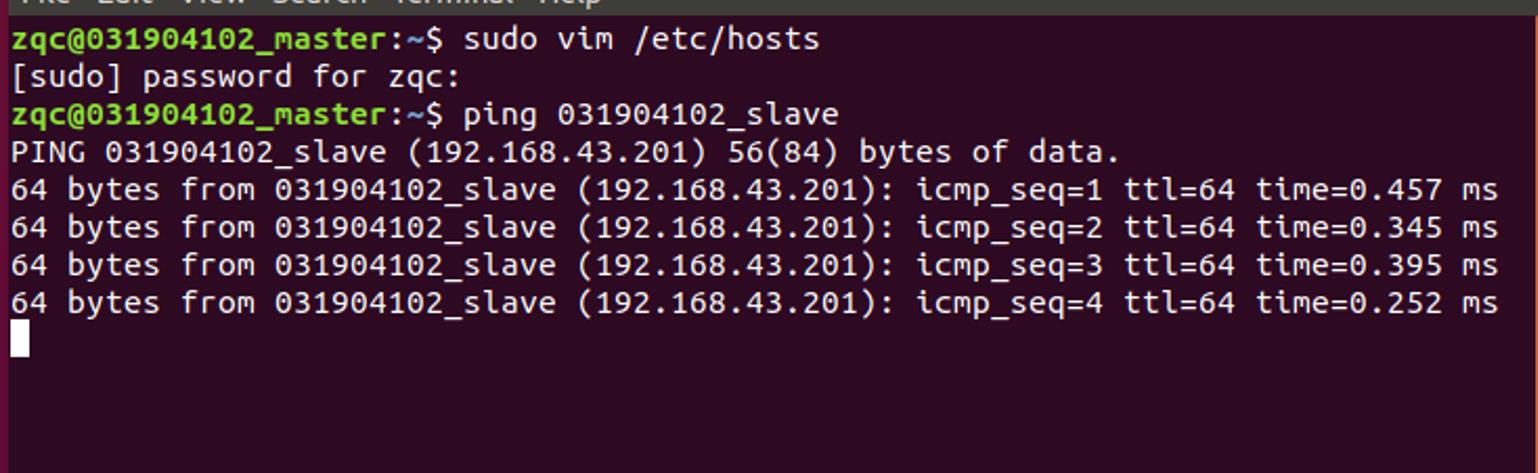
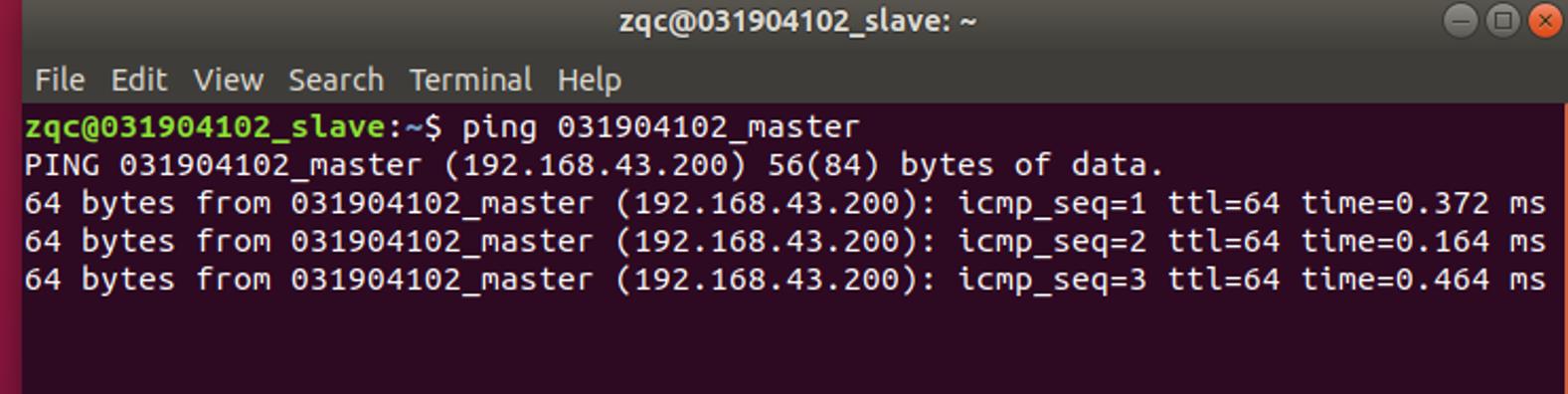
发现都可以即可
5.4ssh免密登陆
这一段第一篇已经讲过,再讲一次吧。
更改主机名称之后,要重新配置ssh密钥。在本次实验中借助xftp进行密钥的传递。
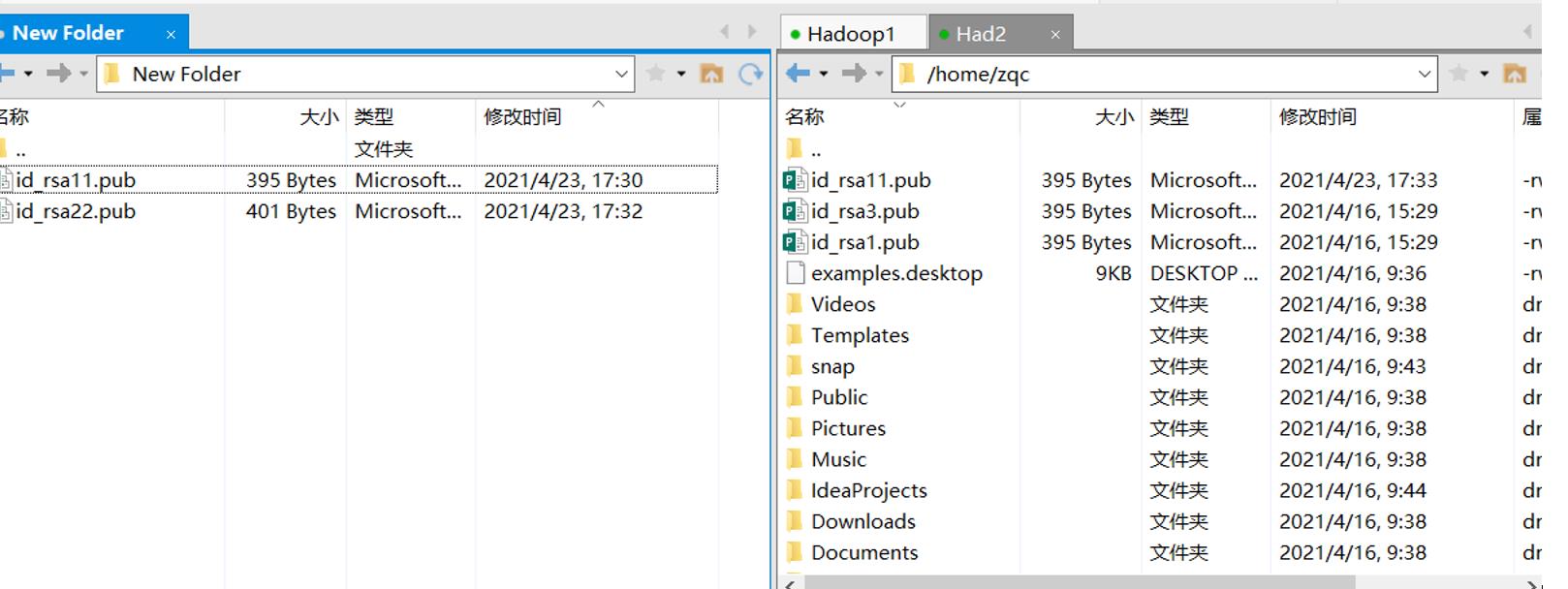
左边是Master 右边是Slave,将对方的id_rsa.pub发给对方
在xftp上进行密钥的复制之后,将其中的密钥cat到authorized_keys中,这和之前的一样的操作
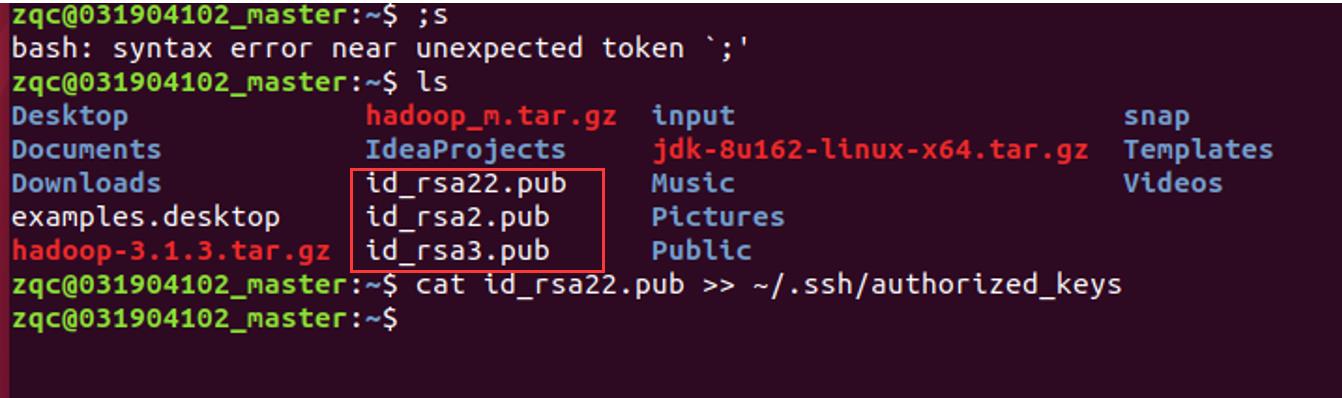
这样就可以实现两台机子的免密登陆了
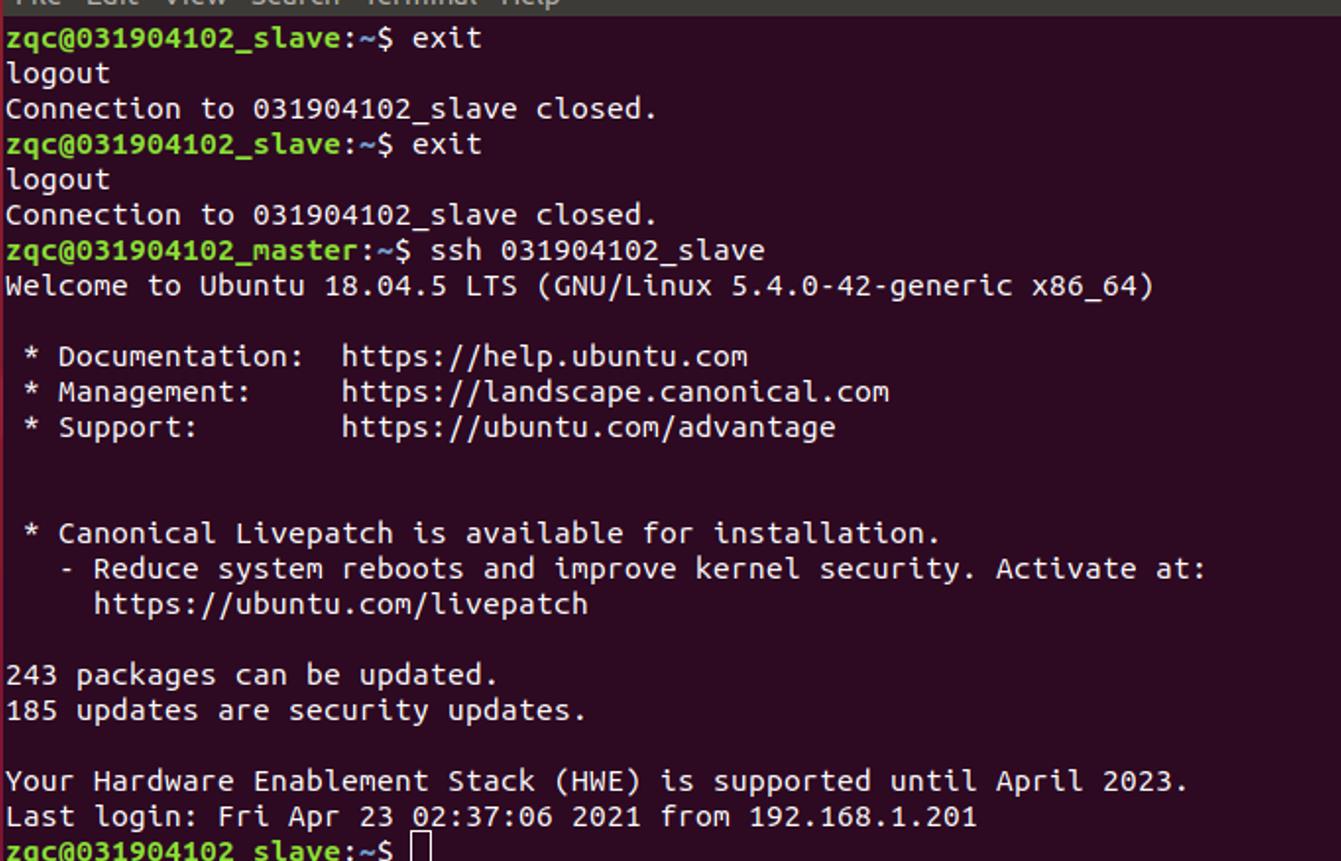
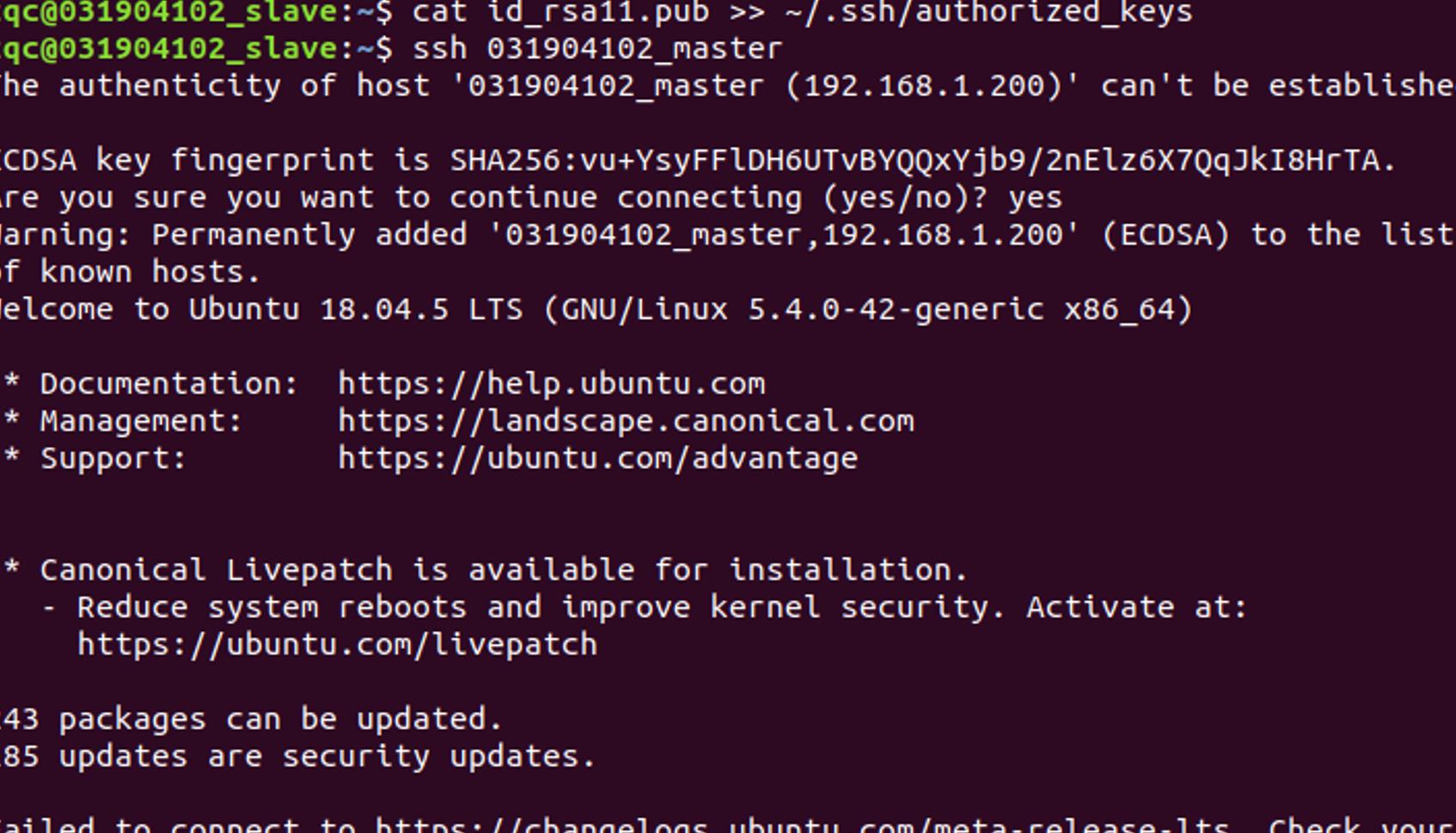
5.5 Hadoop 环境配置
然后再依次配置master中hadoop的文件配置
-
workers
这里是你副节点的主机名称,我截是截老师的,我自己的是031904102-Slave就多了个学号,按照你自己的来。

-
core-site.xml
这也是老师的图,我这里是031904102-Master
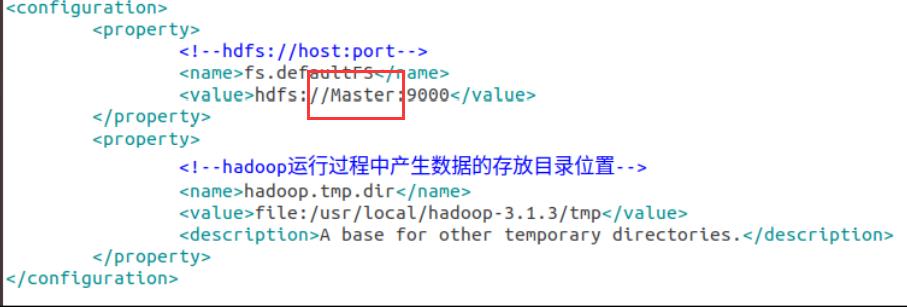
-
hdfs-site.xml

-
mapred-site.xml
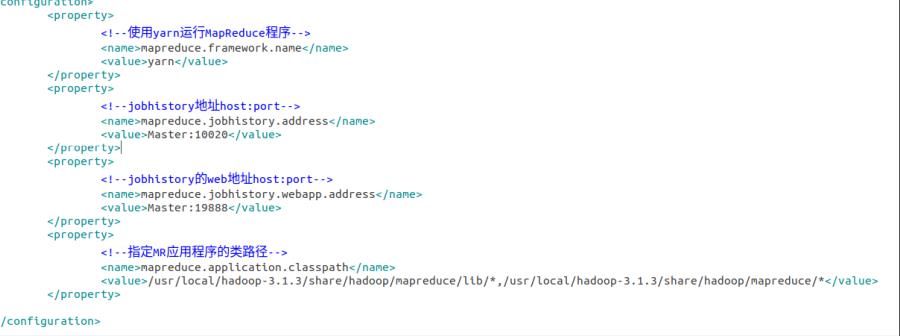
-
yarn-site.xml

hdfs name node -format
初始化一下就可以了。 -
配置其余节点,使所有节点 Hadoop 配置保持一致。删除之前运行伪分布式生成的
log 文件和 tmp 文件夹,打包 Hadoop 远程发送给其它节点并解压。如果其它节点已安装有
Hadoop 也可以直接同步修改配置文件。
Master节点的操作
删除
sudo rm -r /usr/local/hadoop-3.1.3/tmp
sudo rm -r /usr/local/hadoop-3.1.3/logs/*
打包
cd /usr/local
tar -zcf ~/hadoop_m.tar.gz ./hadoop-3.1.3
scp ~/hadoop_m.tar.gz Slave:/home/hadoop

于是上网就有说上传到tmp目录中。就可以了
这里Slave是你上面配置的Slave 我自己的是031904102-Slave
Slave的操作
sudo rm -r /usr/local/hadoop-3.1.3
sudo tar -zxf ~/hadoop_m.tar.gz -C /usr/local
5.6测试实例
- 启动
start-dfs.sh
start-yarn.sh
mapred --daemon start historyserver
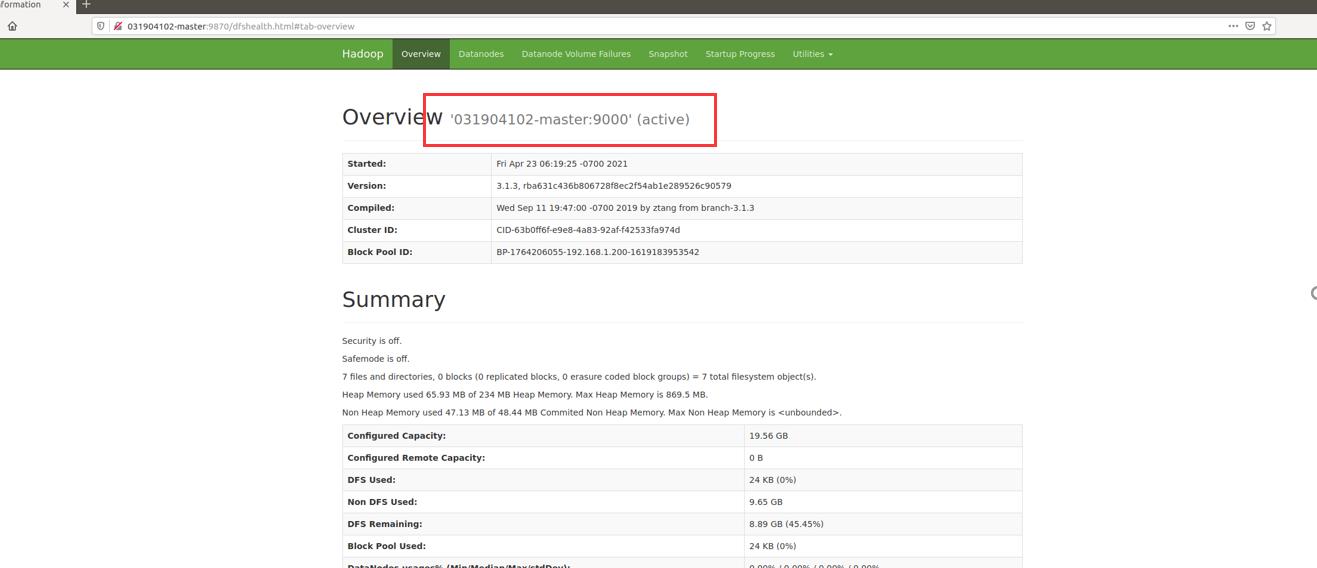
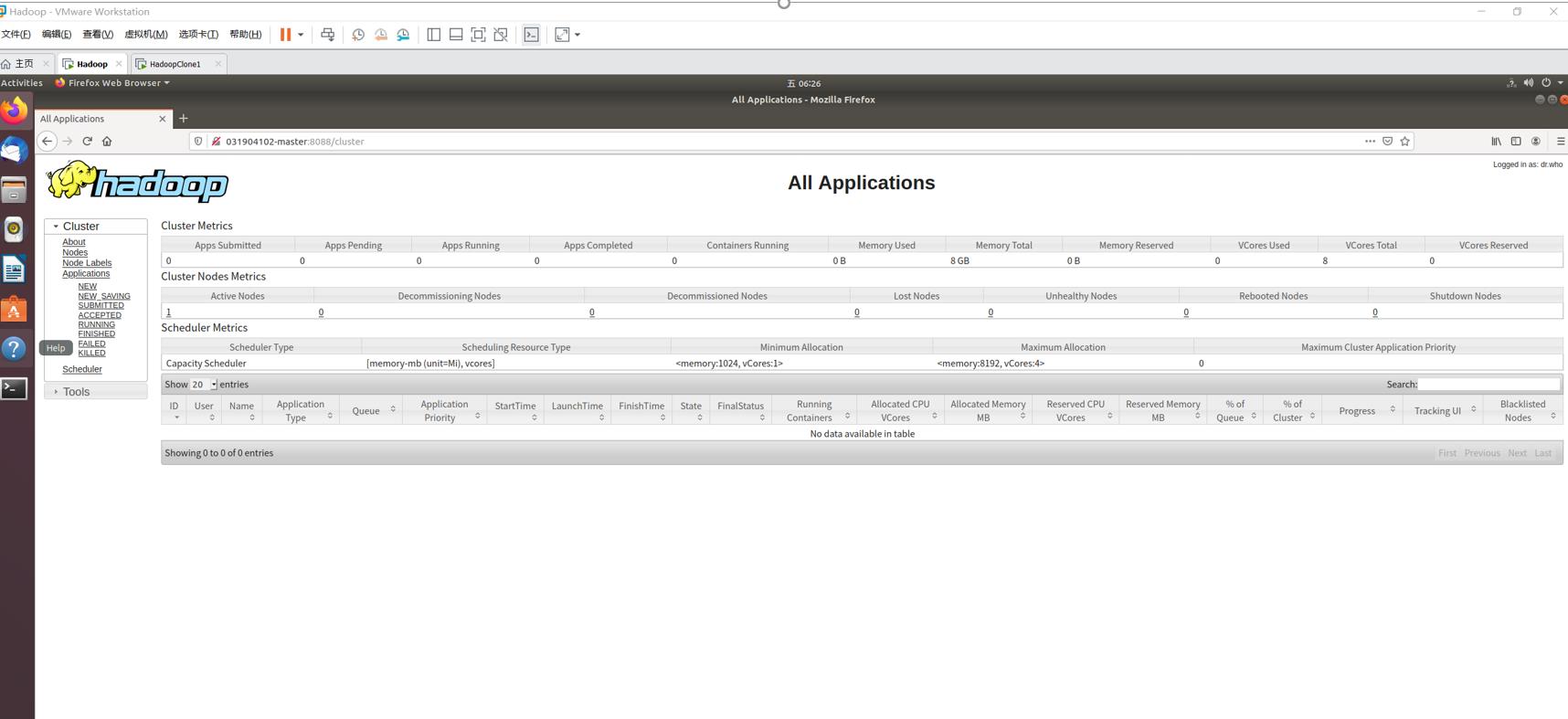
- 查看是否成功启动
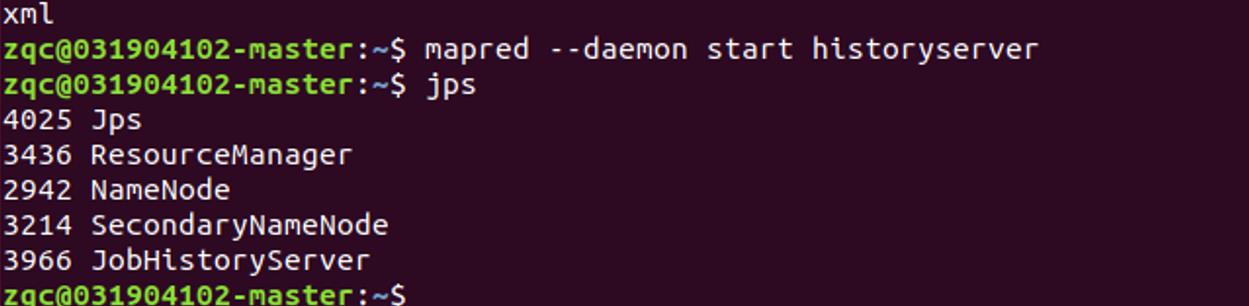
一定要是- !不能是下划线_
在hadoop上创建文件
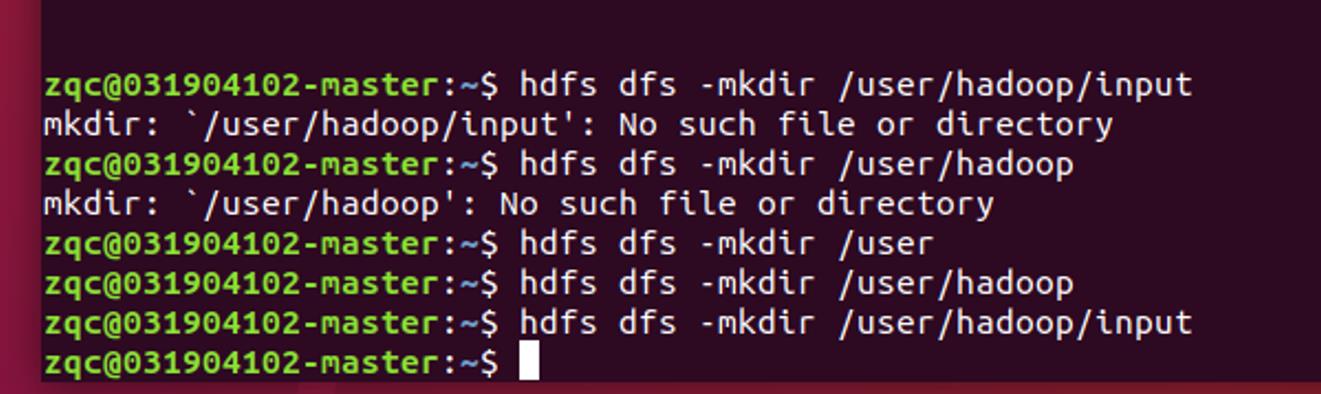
和上面伪分布一样
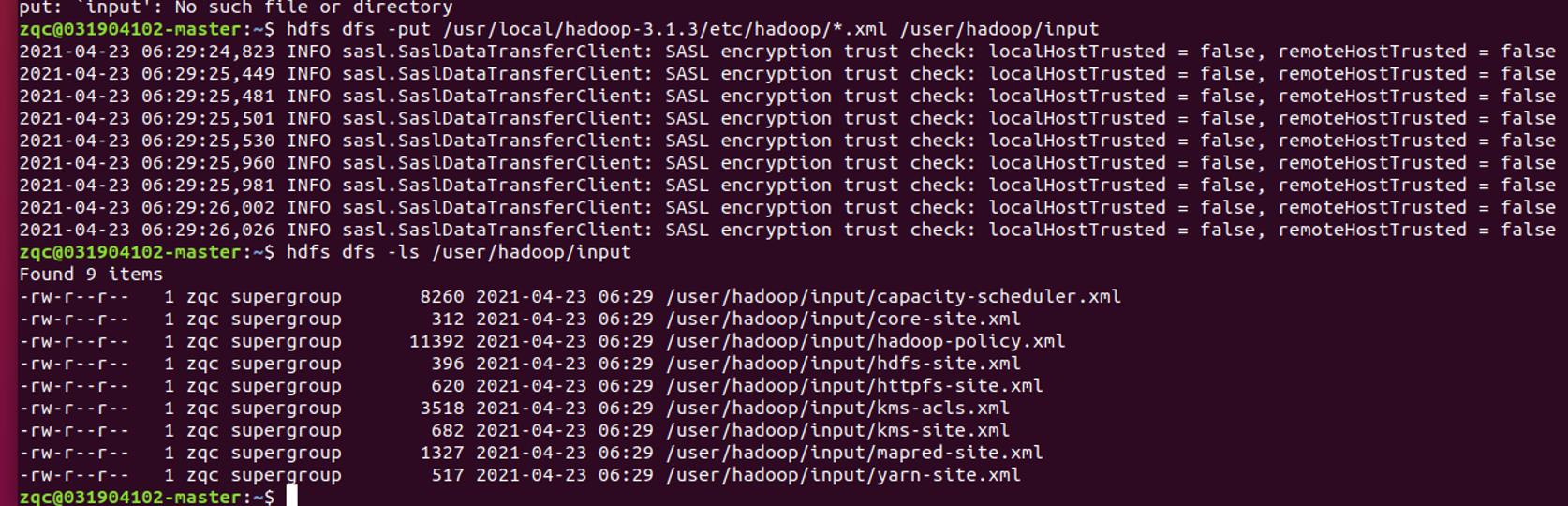
有文件之后
执行grep操作
hadoop jar /usr/local/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep input output `dfs[a-z]+`

cat一下结果
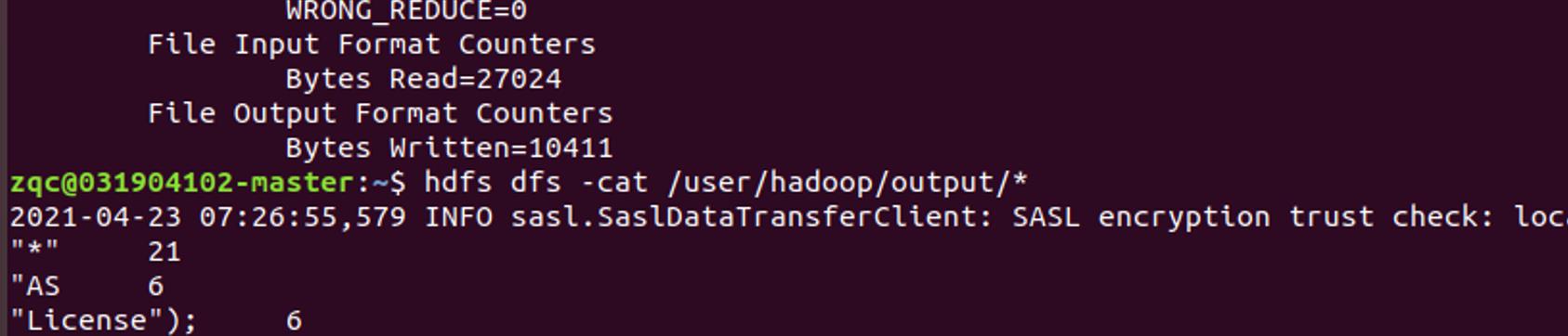
再次测试时,记得把输出结果删除
hdfs dfs -rm -r output
总结
hadoop的三种模式已经介绍一一配置了!
有什么问题评论区留言或是私信我吧!
我是大数据专业的,喜欢大数据的可以关注我!
以上是关于小白视角的大数据基础实践Hadoop环境搭建与测试的主要内容,如果未能解决你的问题,请参考以下文章
打怪升级之小白的大数据之旅(四十二)<Hadoop运行环境搭建>
打怪升级之小白的大数据之旅(四十三)<Hadoop运行模式(集群搭建)>