6.3 图解BERT模型:从零开始构建BERT
Posted 炫云云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了6.3 图解BERT模型:从零开始构建BERT相关的知识,希望对你有一定的参考价值。
文章目录
论文地址
- https://arxiv.org/pdf/1810.04805
本文首先介绍BERT模型要做什么,即:模型的输入、输出分别是什么,以及模型的预训练任务是什么;然后,分析模型的内部结构,图解如何将模型的输入一步步地转化为模型输出;最后,我们在多个中/英文、不同规模的数据集上比较了BERT模型与现有方法的文本分类效果。
BERT 模型提出已经有接近两年的时间了,学术界和工业界也都在不断迭代。想要深入掌握的话,不仅要知道原理,更要懂得源码细节,以及亲手实战 BERT 精调,了解这两年来一系列模型的发展脉络。
BERT受到完型填空任务的启发,通过使用一个“masked language model”(MLM)预训练目标来减轻上面提到的单向约束问题。 MLM随机masks掉input中的一些tokens,目标是从这些tokens的上下文中预测出它们在原始词汇表中的id。不想left-to-right 的预训练语言模型,MLM目标使得表征融合了left和right的上下文信息,这允许作者预训练一个深度双向的Transformer模型。除了MLM,作者还使用了一个“next sentence prediction”任务,连带的预训练text-pair表征。论文的贡献如下:
- 展示了双向预训练语言表征的重要性。BERT使用MLM使得模型可以预训练深度双向表征;GPT在预训练上使用单向语言模型;ELMo使用分别训练好的left-to-right 和right-to-left表征,然后仅仅是简单的串联在一起。
- 显示了预训练表征可以减少对许多工程繁重的特定任务架构的需求。BERT是首个在巨大量级的句子和词级别的任务上达到最佳表现的基于fine-tuning的表征模型。
- BERT 打破了11项NLP任务的最佳记录。代码和预训练模型可以从这里获取 。
1. 模型的输入/输出
BERT模型的全称是:BidirectionalEncoder Representations from Transformer。
从名字中可以看出,BERT模型的目标是利用大规模无标注语料训练、获得文本的包含丰富语义信息的Representation,即:文本的语义表示,然后将文本的语义表示在特定NLP任务中作微调,最终应用于该NLP任务。
煮个栗子,BERT模型训练文本语义表示的过程就好比我们在高中阶段学习语数英、物化生等各门基础学科,夯实基础知识;而模型在特定NLP任务中的参数微调就相当于我们在大学期间基于已有基础知识、针对所选专业作进一步强化,从而获得能够应用于实际场景的专业技能。
在基于深度神经网络的NLP方法中,文本中的字/词通常都用一维向量来表示(一般称之为“词向量”);在此基础上,神经网络会将文本中各个字或词的一维词向量作为输入,经过一系列复杂的转换后,输出一个一维词向量作为文本的语义表示。
特别地,我们通常希望语义相近的字/词在特征向量空间上的距离也比较接近,如此一来,由字/词向量转换而来的文本向量也能够包含更为准确的语义信息。
因此,BERT模型的主要输入是文本中各个字/词的原始词向量,该向量既可以随机初始化,也可以利用Word2Vector等算法进行预训练以作为初始值;输出是文本中各个字/词融合了全文语义信息后的向量表示,如下图所示(为方便描述且与BERT模型的当前中文版本保持一致,本文统一以字向量作为输入):
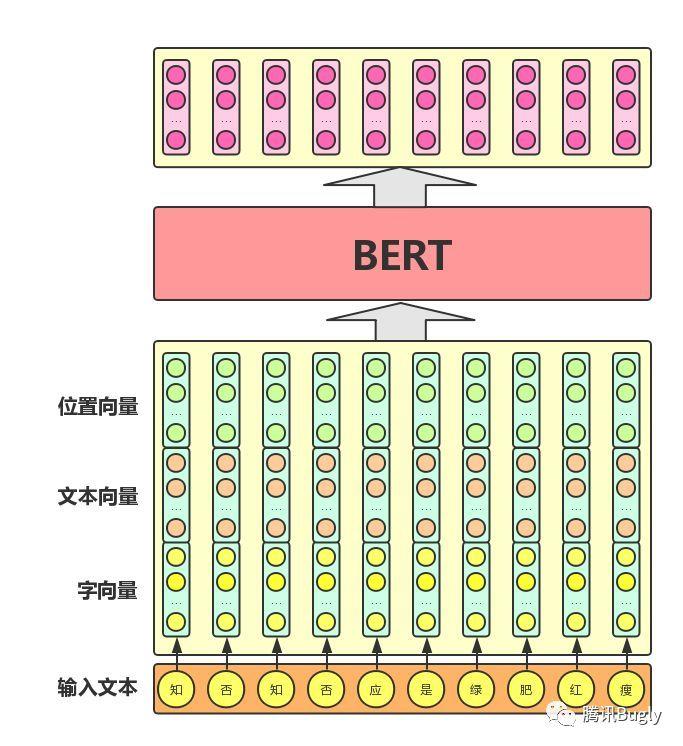
从上图中可以看出,BERT模型通过查询字向量表将文本中的每个字转换为一维向量,作为模型输入;模型输出则是输入各字对应的融合全文语义信息后的向量表示。
此外,模型输入除了字向量,还包含另外两个部分:
-
文本向量:该向量的取值在模型训练过程中自动学习,用于刻画文本的全局语义信息,并与单字/词的语义信息相融合。
-
位置向量:由于出现在文本不同位置的字/词所携带的语义信息存在差异(比如:“我爱你”和“你爱我”),因此,BERT模型对不同位置的字/词分别附加一个不同的向量以作区分。
最后,BERT模型将字向量、文本向量和位置向量的加和作为模型输入。特别地,在目前的BERT模型中,文章作者还将英文词汇作进一步切割,划分为更细粒度的语义单位(WordPiece),例如:将playing分割为play和##ing;此外,对于中文,目前作者尚未对输入文本进行分词,而是直接将单字作为构成文本的基本单位。
对于不同的NLP任务,模型输入会有微调,对模型输出的利用也有差异,例如:
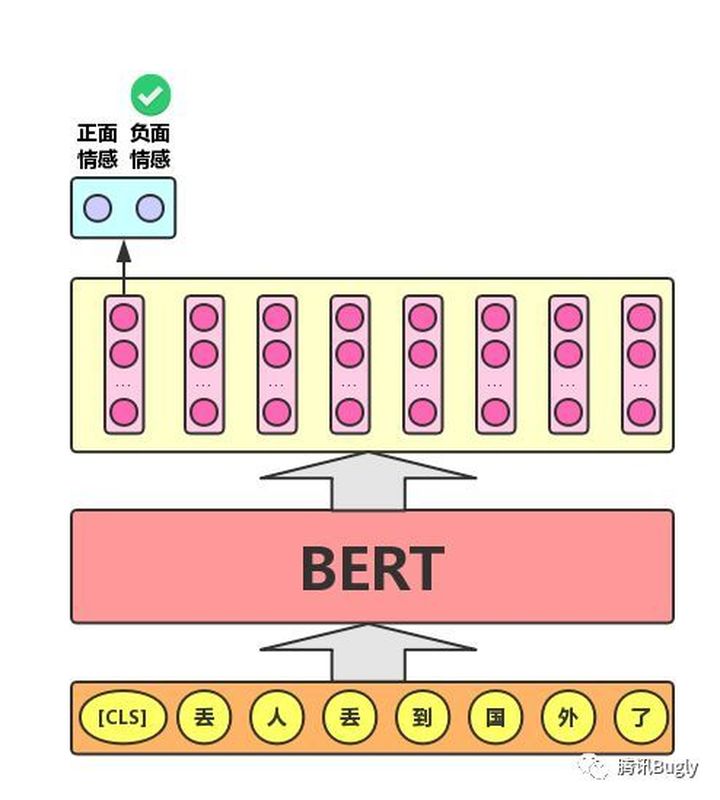
单文本分类任务:对于文本分类任务,BERT模型在文本前插入一个[CLS]符号,并将该符号对应的输出向量作为整篇文本的语义表示,用于文本分类,如下图所示。可以理解为:与文本中已有的其它字/词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个字/词的语义信息。
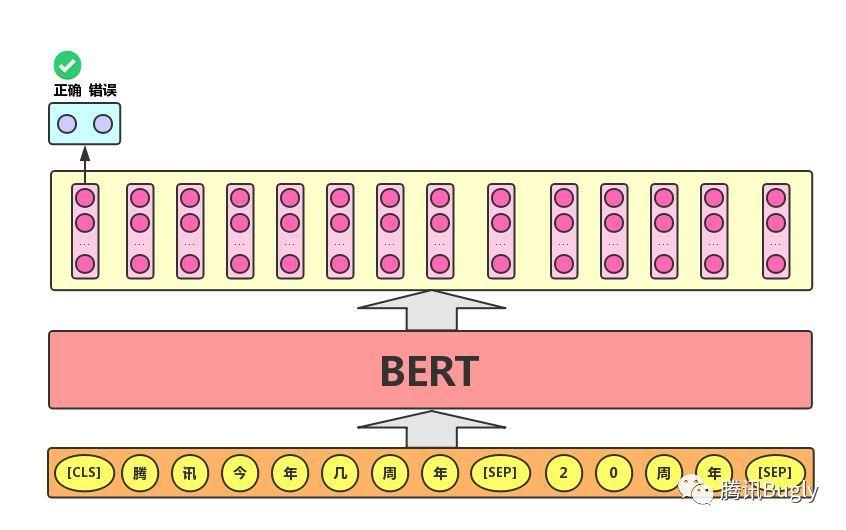
语句对分类任务:该任务的实际应用场景包括:问答(判断一个问题与一个答案是否匹配)、语句匹配(两句话是否表达同一个意思)等。对于该任务,BERT模型除了添加[CLS]符号并将对应的输出作为文本的语义表示,还对输入的两句话用一个**[SEP]符号**作分割,并分别对两句话附加两个不同的文本向量以作区分,如下图所示。
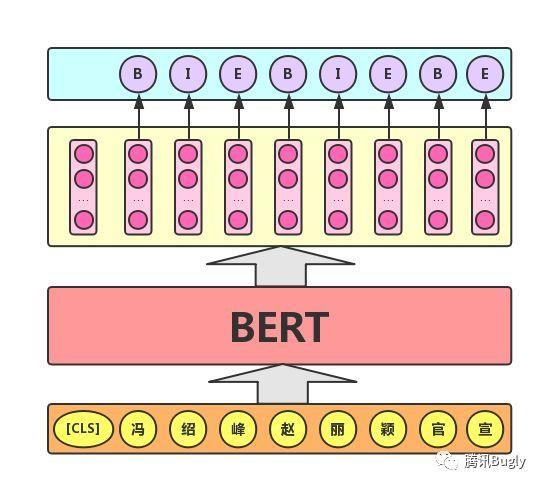
**序列标注任务:**该任务的实际应用场景包括:中文分词&新词发现(标注每个字是词的首字、中间字或末字)、答案抽取(答案的起止位置)等。对于该任务,BERT模型利用文本中每个字对应的输出向量对该字进行标注(分类),如下图所示(B、I、E分别表示一个词的第一个字、中间字和最后一个字)。
- ……
根据具体任务的不同,在实际应用中我们可以脑洞大开,通过调整模型的输入、输出将模型适配到真实业务场景中。
2. 模型的预训练任务
BERT实际上是一个语言模型。语言模型通常采用大规模、与特定NLP任务无关的文本语料进行训练,其目标是学习语言本身应该是什么样的,这就好比我们学习语文、英语等语言课程时,都需要学习如何选择并组合我们已经掌握的词汇来生成一篇通顺的文本。
回到BERT模型上,其预训练过程就是逐渐调整模型参数,使得模型输出的文本语义表示能够刻画语言的本质,便于后续针对具体NLP任务作微调。为了达到这个目的,BERT文章作者提出了两个预训练任务:Masked LM和Next Sentence Prediction。
2.1 Masked LM
Masked LM的任务描述为:给定一句话,随机抹去这句话中的一个或几个词,要求根据剩余词汇预测被抹去的几个词分别是什么,如下图所示。
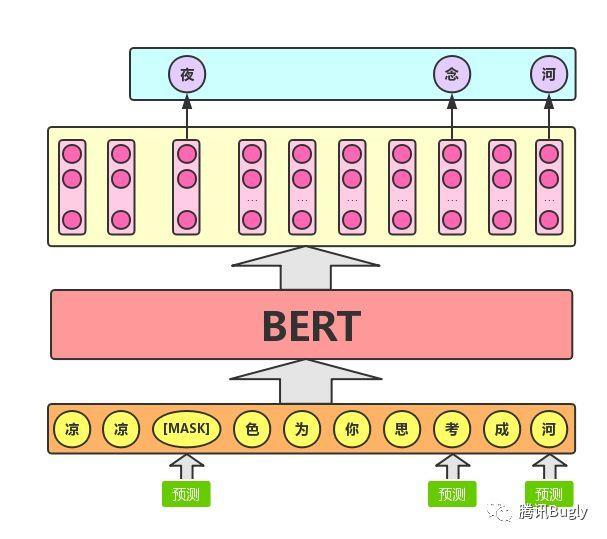
这不就是我们高中英语常做的完形填空么!所以说,BERT模型的预训练过程其实就是在模仿我们学语言的过程。具体来说,文章作者在一句话中随机选择15%的词汇用于预测。
对于在原句中被抹去的词汇,80%情况下采用一个特殊符号[MASK]替换,10%情况下采用一个任意词替换,剩余10%情况下保持原词汇不变。
这么做的主要原因是:在后续微调任务中语句中并不会出现[MASK]标记,而且这么做的另一个好处是:预测一个词汇时,模型并不知道输入对应位置的词汇是否为正确的词汇(10%概率),这就迫使模型更多地依赖于上下文信息去预测词汇,并且赋予了模型一定的纠错能力。
2.2 NextSentence Prediction
Next Sentence Prediction的任务描述为:给定一篇文章中的两句话,判断第二句话在文本中是否紧跟在第一句话之后,如下图所示。
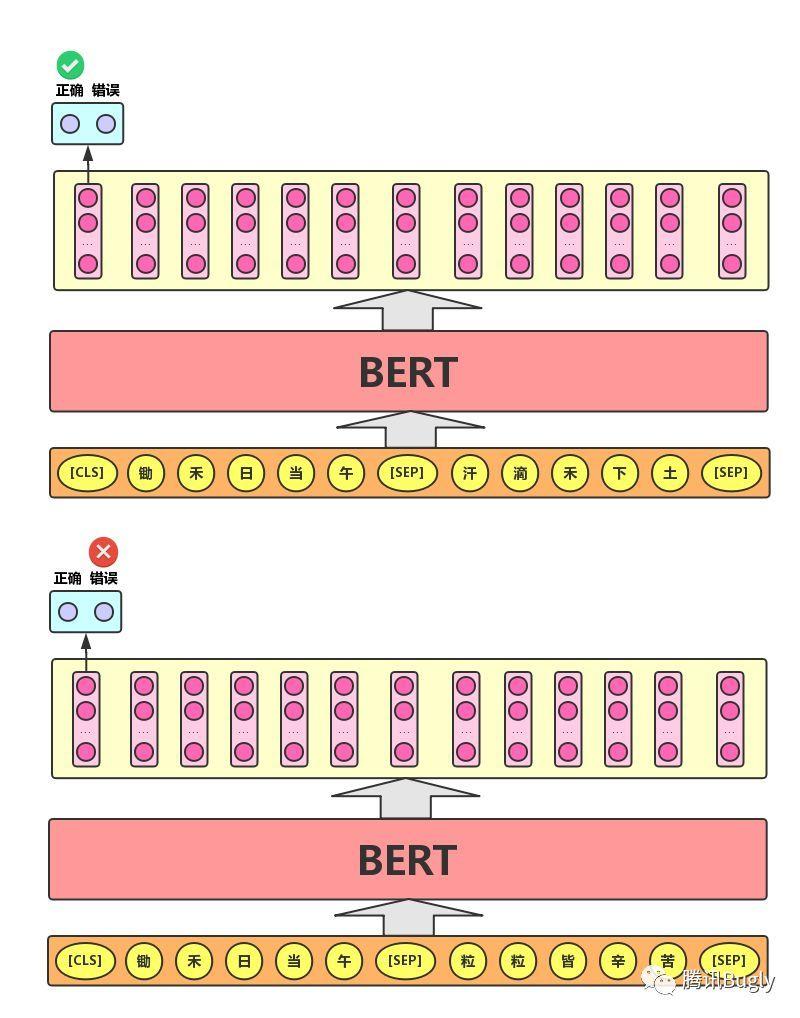
当年大学考英语四六级的时候,大家应该都做过段落重排序,即:将一篇文章的各段打乱,让我们通过重新排序把原文还原出来,这其实需要我们对全文大意有充分、准确的理解。Next Sentence Prediction任务实际上就是段落重排序的简化版:只考虑两句话,判断是否是一篇文章中的前后句。在实际预训练过程中,文章作者从文本语料库中随机选择50%正确语句对和50%错误语句对进行训练,与Masked LM任务相结合,让模型能够更准确地刻画语句乃至篇章层面的语义信息。
BERT模型通过对Masked LM任务和Next Sentence Prediction任务进行联合训练,使模型输出的每个字/词的向量表示都能尽可能全面、准确地刻画输入文本(单句或语句对)的整体信息,为后续的微调任务提供更好的模型参数初始值。
3. 模型结构
了解了BERT模型的输入/输出和预训练过程之后,我们来看一下BERT模型的内部结构。前面提到过,BERT模型的全称是:BidirectionalEncoder Representations from Transformer,也就是说,Transformer是组成BERT的核心模块,而Attention机制又是Transformer中最关键的部分,因此,下面我们从Attention机制开始,介绍如何利用Attention机制构建Transformer模块,在此基础上,用多层Transformer组装BERT模型。
3.1 Attention机制
Attention: Attention机制的中文名叫“注意力机制”,顾名思义,它的主要作用是让神经网络把“注意力”放在一部分输入上,即:区分输入的不同部分对输出的影响。这里,我们从增强字/词的语义表示这一角度来理解一下Attention机制。
我们知道,一个字/词在一篇文本中表达的意思通常与它的上下文有关。比如:光看“鹄”字,我们可能会觉得很陌生(甚至连读音是什么都不记得吧),而看到它的上下文“鸿鹄之志”后,就对它立马熟悉了起来。因此,字/词的上下文信息有助于增强其语义表示。同时,上下文中的不同字/词对增强语义表示所起的作用往往不同。比如在上面这个例子中,“鸿”字对理解“鹄”字的作用最大,而“之”字的作用则相对较小。为了有区分地利用上下文字信息增强目标字的语义表示,就可以用到Attention机制。
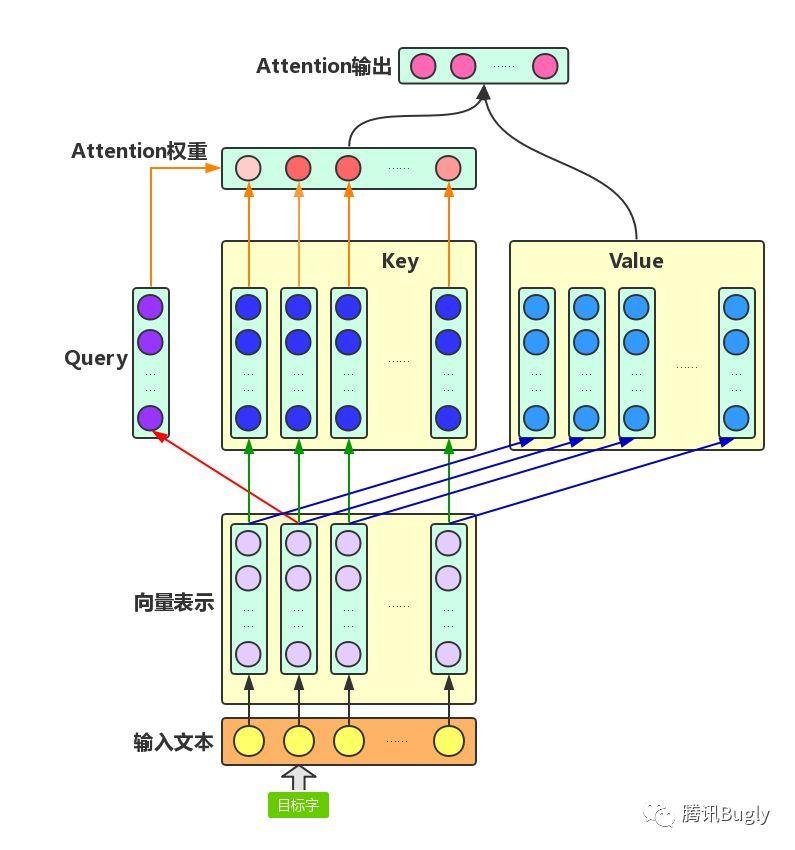
Attention机制主要涉及到三个概念:Query、Key和Value。
在上面增强字的语义表示这个应用场景中,目标字及其上下文的字都有各自的原始Value,Attention机制将目标字作为Query、其上下文的各个字作为Key,并将Query与各个Key的相似性作为权重,把上下文各个字的Value融入目标字的原始Value中。
如下图所示,Attention机制将目标字和上下文各个字的语义向量表示作为输入:
- 首先通过线性变换获得目标字的Query向量表示、上下文各个字的Key向量表示以及目标字与上下文各个字的原始Value表示,(query,要去查询的;key,等着被查的;value,实质的特征信息)
- 然后计算Query向量与各个Key向量的相似度作为权重,
- 加权融合目标字的Value向量和各个上下文字的Value向量,作为Attention的输出,即:目标字的增强语义向量表示。
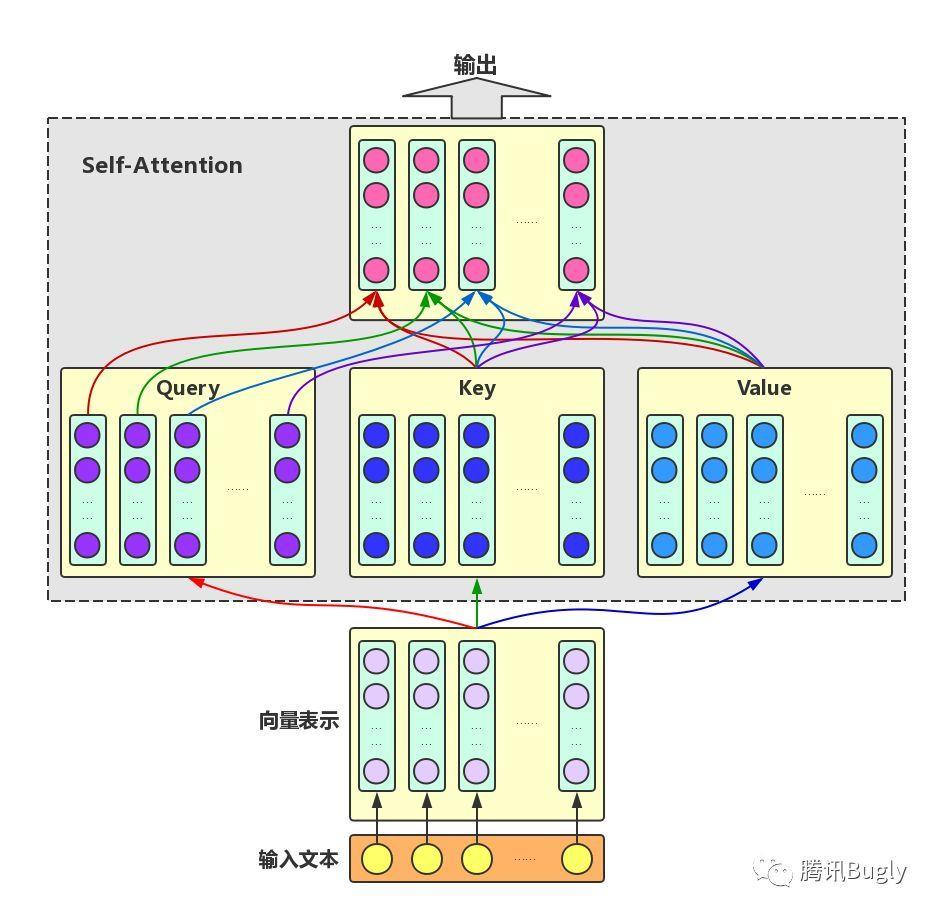
Self-Attention
对于输入文本,我们需要对其中的每个字分别增强语义向量表示,因此,我们分别将每个字作为Query,加权融合文本中所有字的语义信息,得到各个字的增强语义向量,如下图所示。在这种情况下,Query、Key和Value的向量表示均来自于同一输入文本,因此,该Attention机制也叫Self-Attention。
Multi-head Self-Attention
为了增强Attention的多样性,文章作者进一步利用不同的Self-Attention模块获得文本中每个字在不同语义空间下的增强语义向量,并将每个字的多个增强语义向量进行线性组合,从而获得一个最终的与原始字向量长度相同的增强语义向量,如下图所示。
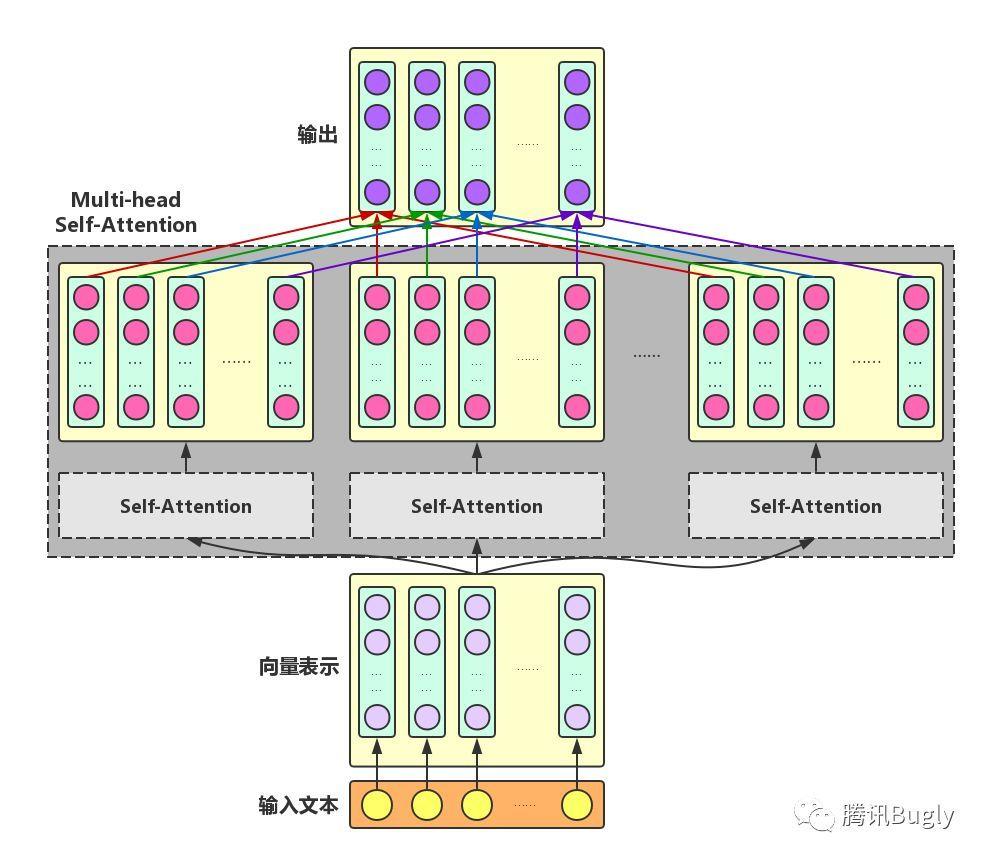
这里,我们再给出一个例子来帮助理解Multi-head Self-Attention(注:这个例子仅用于帮助理解,并非严格正确)。看下面这句话:“南京市长江大桥”,在不同语义场景下对这句话可以有不同的理解:“南京市/长江大桥”,或“南京市长/江大桥”。对于这句话中的“长”字,在前一种语义场景下需要和“江”字组合才能形成一个正确的语义单元;而在后一种语义场景下,它则需要和“市”字组合才能形成一个正确的语义单元。我们前面提到,Self-Attention旨在用文本中的其它字来增强目标字的语义表示。在不同的语义场景下,Attention所重点关注的字应有所不同。
因此,Multi-head Self-Attention可以理解为考虑多种语义场景下目标字与文本中其它字的语义向量的不同融合方式。可以看到,Multi-head Self-Attention的输入和输出在形式上完全相同,输入为文本中各个字的原始向量表示,输出为各个字融合了全文语义信息后的增强向量表示。因此,Multi-head Self-Attention可以看作是对文本中每个字分别增强其语义向量表示的黑盒。
3.2 Transformer Encoder
在Multi-headSelf-Attention的基础上再添加一些“佐料”,就构成了大名鼎鼎的Transformer Encoder。实际上,Transformer模型还包含一个Decoder模块用于生成文本,但由于BERT模型中并未使用到Decoder模块,因此这里对其不作详述。
下图展示了Transformer Encoder的内部结构,可以看到,Transformer Encoder在Multi-head Self-Attention之上又添加了三种关键操作:
- 残差连接(ResidualConnection):将模块的输入与输出直接相加,作为最后的输出。这种操作背后的一个基本考虑是:修改输入比重构整个输出更容易(“锦上添花”比“雪中送炭”容易多了!)。这样一来,可以使网络更容易训练。
- Layer Normalization:对某一层神经网络节点作0均值1方差的标准化。
- 线性转换:对每个字的增强语义向量再做两次线性变换,以增强整个模型的表达能力。这里,变换后的向量与原向量保持长度相同。
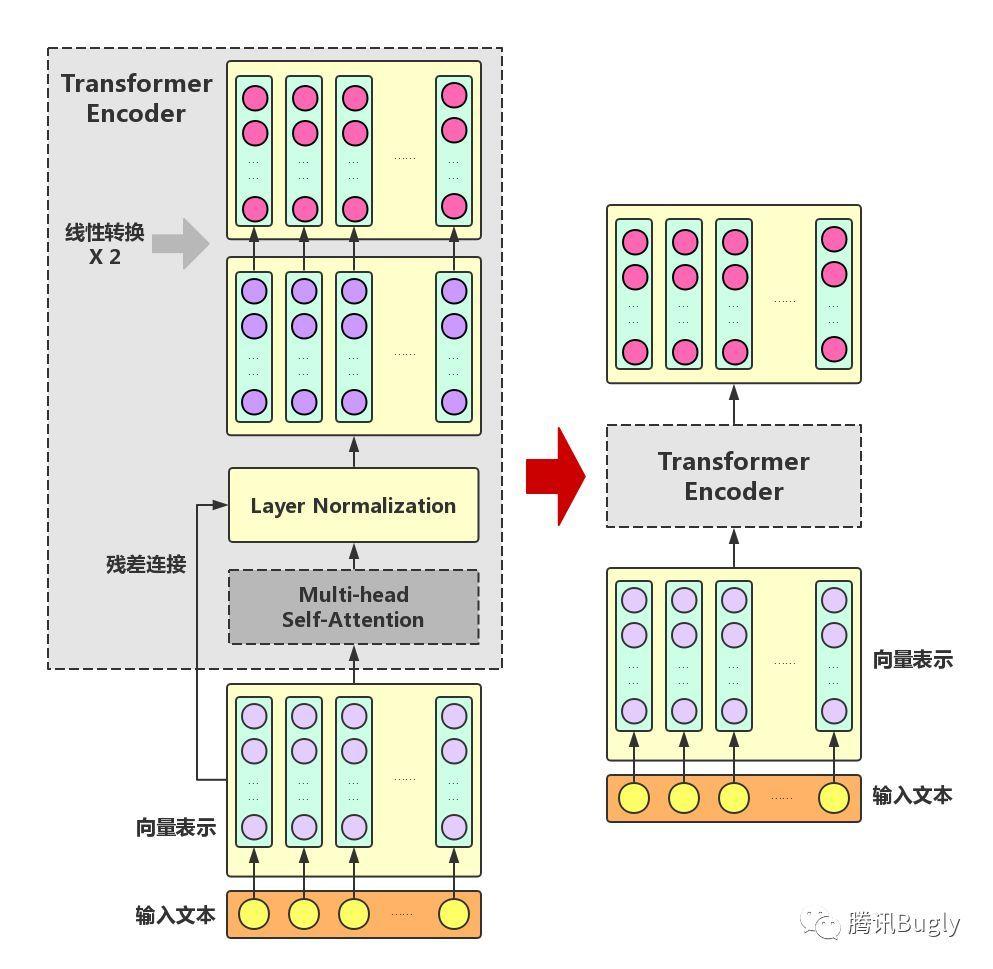
可以看到,Transformer Encoder的输入和输出在形式上还是完全相同,因此,Transformer Encoder同样可以表示为将输入文本中各个字的语义向量转换为相同长度的增强语义向量的一个黑盒。
3.3 BERT model
组装好TransformerEncoder之后,再把多个Transformer Encoder一层一层地堆叠起来,BERT模型就大功告成了!
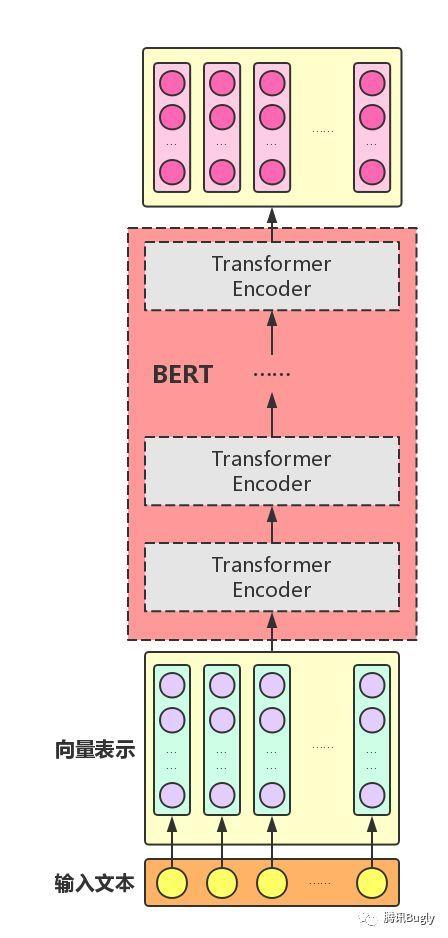
在论文中,作者分别用12层和24层Transformer Encoder组装了两套BERT模型,两套模型的参数总数分别为110M和340M。
3.4、数学公式
Bert输入一个序列并输出该序列的向量表示。序列中的每个token都有自己的隐藏向量,每个序列的第一个token总是一个特殊的分类嵌入([cls])。在BERT的每一层中,每个序列元素的隐藏状态都会被转换,但是分类/回归任务只使用[cls]的最终隐藏状态。我们现在描述序列中某个元素的向量是如何被转换的
第
i
i
i个注意机制“head”为:
Attention
i
(
h
j
)
=
∑
t
softmax
(
W
i
q
h
j
⋅
W
i
k
h
t
d
/
n
)
W
i
v
h
t
\\text { Attention }_{i}\\left(\\mathbf{h}_{j}\\right)=\\sum_{t} \\operatorname{softmax}\\left(\\frac{W_{i}^{q} \\mathbf{h}_{j} \\cdot W_{i}^{k} \\mathbf{h}_{t}}{\\sqrt{d / n}}\\right) W_{i}^{v} \\mathbf{h}_{t}
Attention i(hj)=t∑softmax(d/nWiqhj⋅Wikht)Wivht
其中
h
j
\\mathbf{h}_{j}
hj是一个特定序列元素的
d
d
d维隐藏向量,
t
t
t在每个序列元素上运行。在 BERT
W
i
q
,
W
i
k
W_{i}^{q}, W_{i}^{k}
Wiq,Wik 和
W
i
v
W_{i}^{v}
Wiv 的尺寸为
d
/
n
×
d
d / n \\times d
d/n×d,所以每个head投射到大小为
d
/
n
d / n
d/n的不同子空间,注意不同的信息。最后,
n
n
n attention head(每个size
d
/
n
d/n
d/n)的输出连接在一起(我们将其表示为
[
⋅
,
…
,
⋅
]
[\\cdot, \\ldots, \\cdot]
[⋅,…,⋅] )和线性转换:
M
H
(
h
)
=
W
o
[
Attention
1
(
h
)
,
…
,
Attention
n
(
h
)
]
\\mathrm{MH}(\\mathbf{h})=W^{o}\\left[\\text { Attention }_{1}(\\mathbf{h}), \\ldots, \\text { Attention }_{n}(\\mathbf{h})\\right]
MH(h)=Wo[ Attention 1(h),…, Attention n(h)]
W
o
W^{o}
Wo 是
d
×
d
d \\times d
d×d 矩阵 。 multi-head层有
3
n
d
2
/
n
+
d
2
=
4
d
2
3 n d^{2} / n+d^{2}=4 d^{2}
3nd2/n+d2=4d2参数。
我们进一步定义了BERT 层的另一个组成部分,self-attention层, 写成
S
A
(
⋅
)
\\mathrm{SA}(\\cdot)
SA(⋅): 以上是关于6.3 图解BERT模型:从零开始构建BERT的主要内容,如果未能解决你的问题,请参考以下文章 图解 2018 年领先的两大 NLP 模型:BERT 和 ELMo [Python人工智能] 三十四.Bert模型 keras-bert库构建Bert模型实现微博情感分析
S
A
(
h
)
=
F
F
N
(
L
N
(
h
+
M
H
(
h
)
)
)
\\mathrm{SA}(\\mathbf{h})=\\mathrm{FFN}(\\mathrm{LN}(\\mathbf{h}+\\mathrm{MH}(\\mathbf{h})))
SA(h)=FFN(LN(h+MH(h)))
L
N
(
⋅
)
\\mathrm{LN} (\\cdot)
LN(⋅)是层标准化,需要
2
d
2 d
2d 参数。FFN是一个标准的前馈网络,
FFN
(
h
)
=
W
2
f
(
W
1
h
+
b
1
)
+
b
2
,
\\operatorname{FFN}(\\mathbf{h})=W_{2} f\\left(W_{1} \\mathbf{h}+b_{1}\\right)+b_{2},
FFN(h)=W2f(W1h+b1)+b2,
f
(
⋅
)
f(\\cdot)
f(⋅)为激活函数gelu。矩阵
W
1
W_{1}
W1的大小是
d
f
f
×
d
d_{f f} \\times d
dff×d,而
W
2
W_{2}
W2的大小是
d
×
d
f
f
d \\times d_{f f}
d×dff<