[Chapter 4] Reinforcement Learning Model-Free Method
Posted 超级超级小天才
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Chapter 4] Reinforcement Learning Model-Free Method相关的知识,希望对你有一定的参考价值。
Model-Free RL Method
In model-based method, we need firstly model the environment by learning/estimating the transition and reward functions. However, in model-free method, we consider learning the value/utility functions V ( s ) V(s) V(s) or U ( s ) U(s) U(s) or action-value functions Q ( s , a ) Q(s,a) Q(s,a) directly without learning P ( s ′ │ s , a ) P(s^′│s,a) P(s′│s,a) and R ( s , a , s ′ ) R(s,a,s^′) R(s,a,s′). There are also two main kinds of approaches, one is called Monte Carlo (MC) Learning and another one is called Temporal Difference (TD) Learning. The main difference between them is how often to update the policy.
Monte Carlo Learning
Firstly, we consider the prediction problem, how to compute/estimate the U ( s ) U(s) U(s) or Q ( s , a ) Q(s,a) Q(s,a)?
In Monte Carlo learning, the agent executes a set of trails based on the GLIE scheme (trading the exploration and exploitation off). In our example environment, a trail starts from location ( 1 , 1 ) (1,1) (1,1) and ends in either terminal states ( 4 , 2 ) (4,2) (4,2) or ( 4 , 3 ) (4,3) (4,3), e.g., shown below with the rewards in subscripts:
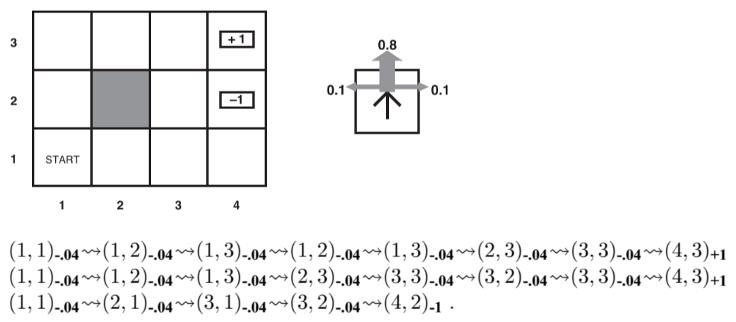
The trails collected by the agent are samples or data, on which we can learn based. You must remember the Bellman equation for the utility function, and we have another version of it for the Q-function:
U ( s ) = R ( s ) + γ m a x a ∈ A ( s ) ∑ s ′ P ( s ′ │ s , a V ( s ′ ) U(s)=R(s)+{\\gamma} max_{a \\in A(s)} \\sum_{s^′}{P(s^′│s,aV(s^′)} U(s)=R(s)+γmaxa∈A(s)s′∑P(s′│s,aV(s′)
Q ( s , a ) = R ( s ) + γ ∑ s ′ P ( s ′ │ s , a ) m a x a ′ Q ( s ′ , a ′ ) Q(s,a)=R(s)+{\\gamma} \\sum_{s^′}{P(s^′│s,a) max_{a^′}{Q(s^′,a^′)}} Q(s,a)=R(s)+γs′∑P(s′│s,a)maxa′Q(s′,a′)
where γ {\\gamma} γ is the discounted factor.
Using these two equations, we can compute the utility or Q-value for each state, for example, in the trail 3, the return or reward-to-go of state ( 1 , 1 ) (1,1) (1,1) can be computed as (suppose γ = 0.9 {\\gamma}=0.9 γ=0.9 here):
U ( [ 1 , 1 ] ) = − 0.04 + 0.9 × ( − 0.04 + 0.9 × ( − 0.04 + 0.9 × ( − 0.04 + 0.9 × ( − 1 ) ) ) ) = − 0.794 U([1,1])=−0.04+0.9 \\times (−0.04+0.9 \\times (−0.04+0.9 \\times (−0.04+0.9 \\times (−1))))=−0.794 U([1,1])=−0.04+0.9×(−0.04+0.9×(−0.04+0.9×(−0.04+0.9×(−1))))=−0.794
It can be an estimation of the return of state ( 1 , 1 ) (1,1) (1,1), while we have many many trials/samples, take an average value of all estimations, then we can get an approximate value for each state. And in infinitely many trails, sample average will converge to the expected value.
Here, actually you can see that in trail 1, location ( 1 , 2 ) (1,2) (1,2) appears two times, in this case, if we only use the first one, it becomes a first visit method, or if we use both of the samples, it becomes a every visit method, we will focus on the first visit method in this section.
Assume state s s s is encountered k k k times giving k k k returns. We can rewrite the average, U k ( s ) U_k(s) Uk(s) of k k k returns G 1 ( s ) , . . . , G k ( s ) G_1(s), ..., G_k(s) G1(s),...,Gk(s) as:
U k ( s ) = U k − 1 ( s ) + 1 k ( G k ( s ) − U k − 1 ( s ) ) U_k(s)=U_{k−1}(s)+ \\frac{1}{k} (G_k(s)−U_{k−1}(s)) Uk(s)=Uk−1(s)+k1(Gk(s)−Uk−1(s))
where U k − 1 ( s ) U_{k−1}(s) Uk−1(s) is the estimate after receiving k − 1 k−1 k−1 returns, so G k ( s ) − U k − 1 ( s ) G_k(s)−U_{k−1}(s) Gk(s)−Uk−1(s) can be considered the prediction error for the k k k-th return.
In a similar way, we can also choose to learn the Q-functions instead of learning the value functions. After that, for the control problem, we only need to greedy choose the policy by:
π ( s ) = a r g m a x a ′ Q ( s , a ′ ) {\\pi}(s)=arg max_{a′}{Q(s,a^′)} π(s)=argmaxa′Q(s,a′)
There is another problem you may want to know, how to sample trails in MC learning? As we have stated above, it’s better to using a GLIE scheme, for example, ϵ {\\epsilon} ϵ-greedy, which means that for a probability of ϵ {\\epsilon} ϵ, using the current policy (computed by the control problem part) to select a current-best action, and for a probability of 1 − ϵ 1−{\\epsilon} 1−ϵ, choosing actions randomly.
MC learning is an instance of supervised learning: each example has state as input and observed return as output, so it’s simple and unbiased. However, the biggest disadvantage for MC learning is that we need to wait till the end of episode to get one trail and then learn can be done. So let’s introduce another method, which can learn after each step – temporal difference learning.
Temporal Difference Learning
Temporal difference (TD) learning exploits more of the Bellman equation constraints than Monte Carlo learning. For a transition from state s s s to s ′ s′ s′, TD learning does:
U π ( s ) ← U π ( s ) + α ( R ( s ) + γ U π ( s ′ ) − U π ( s ) ) U^{\\pi}(s) \\leftarrow U^{\\pi}(s)+ \\alpha (R(s)+{\\gamma}U^{\\pi}(s^′)−U^{\\pi}(s)) Uπ(s)←Uπ(s)+α(R(s)+γUπ(s′)−Uπ(s))
where α {\\alpha} α is the learning rate and γ {\\gamma} γ is the discounted factor.
In the formula, we can see that it will increase U π ( s ) U^{\\pi}(s) Uπ(s) if R ( s ) + γ U π ( s ′ ) R(s)+{\\gamma}U^{\\pi}(s^′) R(s)+γUπ(s′) is larger than U π ( s ) U^{\\pi}(s) U以上是关于[Chapter 4] Reinforcement Learning Model-Free Method的主要内容,如果未能解决你的问题,请参考以下文章
[Chapter 4] Reinforcement Learning Model-Free Method
[Chapter 5] Reinforcement LearningFunction Approximation
[Chapter 5] Reinforcement LearningFunction Approximation
[Chapter 5] Reinforcement LearningFunction Approximation