2021年大数据Hadoop(十六):MapReduce计算模型介绍
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021年大数据Hadoop(十六):MapReduce计算模型介绍相关的知识,希望对你有一定的参考价值。
全网最详细的Hadoop文章系列,强烈建议收藏加关注!
后面更新文章都会列出历史文章目录,帮助大家回顾知识重点。
目录
本系列历史文章
2021年大数据Hadoop(十五):Hadoop的联邦机制 Federation
2021年大数据Hadoop(十三):HDFS意想不到的其他功能
2021年大数据Hadoop(十一):HDFS的元数据辅助管理
2021年大数据Hadoop(八):HDFS的Shell命令行使用
2021年大数据Hadoop(七):HDFS分布式文件系统简介
2021年大数据Hadoop(六):全网最详细的Hadoop集群搭建
2021年大数据Hadoop(二):Hadoop发展简史和特性优点
2021年大数据Hadoop(一):Hadoop介绍
前言
2021年全网最详细的大数据笔记,轻松带你从入门到精通,该栏目每天更新,汇总知识分享

MapReduce计算模型介绍
理解MapReduce思想
MapReduce思想在生活中处处可见。或多或少都曾接触过这种思想。MapReduce的思想核心是“分而治之”,适用于大量复杂的任务处理场景(大规模数据处理场景)。即使是发布过论文实现分布式计算的谷歌也只是实现了这种思想,而不是自己原创。
Map负责“分”,即把复杂的任务分解为若干个“简单的任务”来并行处理。可以进行拆分的前提是这些小任务可以并行计算,彼此间几乎没有依赖关系。
Reduce负责“合”,即对map阶段的结果进行全局汇总。
这两个阶段合起来正是MapReduce思想的体现。
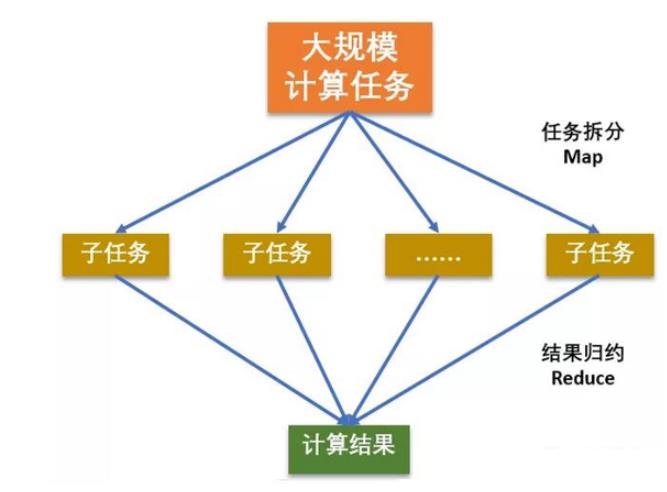
图:MapReduce思想模型
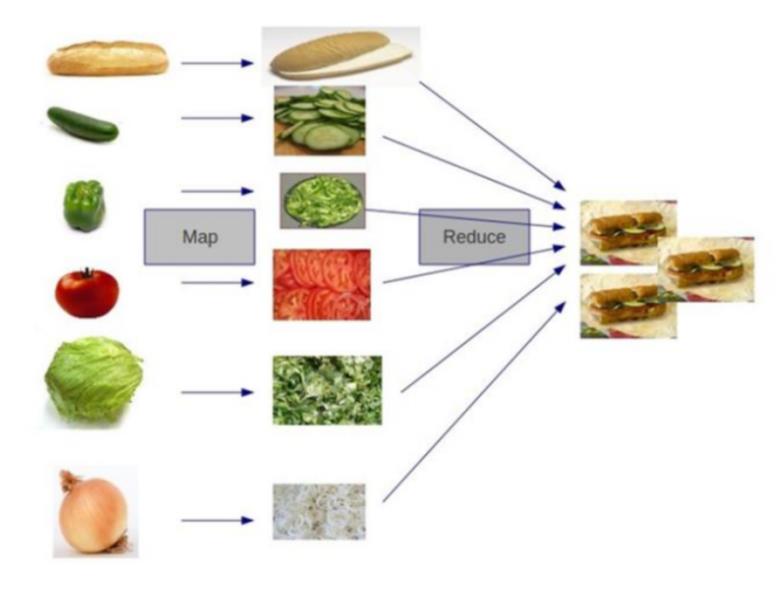
还有一个比较形象的语言解释MapReduce:
我们要数图书馆中的所有书。你数1号书架,我数2号书架。这就是“Map”。我们人越多,数书就更快。
现在我们到一起,把所有人的统计数加在一起。这就是“Reduce”。
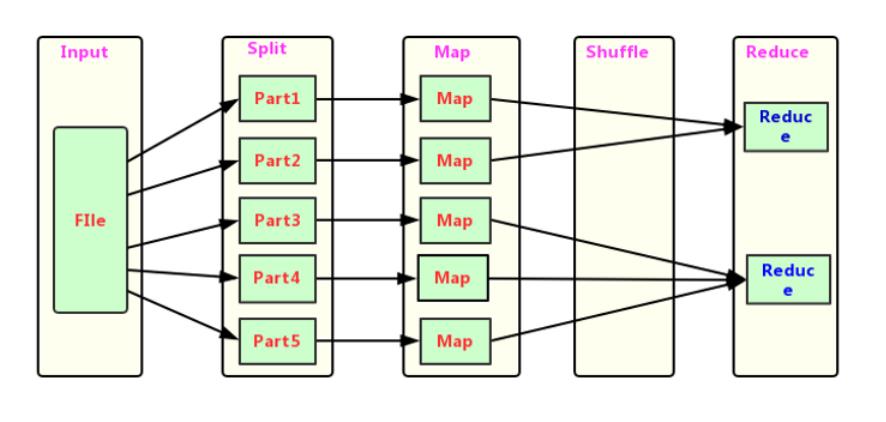
MapReduce的运行需要由Yarn集群来提供资源调度。
Hadoop MapReduce设计构思
MapReduce是一个分布式运算程序的编程框架,核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在Hadoop的yarn集群上。
既然是做计算的框架,那么表现形式就是有个输入(input),MapReduce操作这个输入(input),通过本身定义好的计算模型,得到一个输出(output)。
对许多开发者来说,自己完完全全实现一个并行计算程序难度太大,而MapReduce就是一种简化并行计算的编程模型,降低了开发并行应用的入门门槛。
Hadoop MapReduce构思体现在如下的三个方面:
如何对付大数据处理:分而治之
对相互间不具有计算依赖关系的大数据,实现并行最自然的办法就是采取分而治之的策略。并行计算的第一个重要问题是如何划分计算任务或者计算数据以便对划分的子任务或数据块同时进行计算。不可分拆的计算任务或相互间有依赖关系的数据无法进行并行计算!
构建抽象模型:Map和Reduce
MapReduce借鉴了函数式语言中的思想,用Map和Reduce两个函数提供了高层的并行编程抽象模型。
Map: 对一组数据元素进行某种重复式的处理;
Reduce: 对Map的中间结果进行某种进一步的结果整理。
MapReduce中定义了如下的Mapper和Reducer两个抽象的编程接口,由用户去编程实现:
map: (k1; v1) → [(k2; v2)]
reduce: (k2; [v2]) → [(k3; v3)]
Map和Reduce为程序员提供了一个清晰的操作接口抽象描述。通过以上两个编程接口,大家可以看出MapReduce处理的数据类型是<key,value>键值对。
统一构架,隐藏系统层细节
如何提供统一的计算框架,如果没有统一封装底层细节,那么程序员则需要考虑诸如数据存储、划分、分发、结果收集、错误恢复等诸多细节;为此,MapReduce设计并提供了统一的计算框架,为程序员隐藏了绝大多数系统层面的处理细节。
MapReduce最大的亮点在于通过抽象模型和计算框架把需要做什么(what need to do)与具体怎么做(how to do)分开了,为程序员提供一个抽象和高层的编程接口和框架。程序员仅需要关心其应用层的具体计算问题,仅需编写少量的处理应用本身计算问题的程序代码。如何具体完成这个并行计算任务所相关的诸多系统层细节被隐藏起来,交给计算框架去处理:从分布代码的执行,到大到数千小到单个节点集群的自动调度使用。
以上是关于2021年大数据Hadoop(十六):MapReduce计算模型介绍的主要内容,如果未能解决你的问题,请参考以下文章
2021年大数据Hadoop(二十一):MapReuce的Combineer
2021年大数据Hadoop(十五):Hadoop的联邦机制 Federation