320万开发者在用的飞桨,全新发布推理部署导航图:打通AI应用最后一公里
Posted 百度大脑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了320万开发者在用的飞桨,全新发布推理部署导航图:打通AI应用最后一公里相关的知识,希望对你有一定的参考价值。
在飞桨框架的版本号升级到 2.1 之后,一切都已不一样了。
深度学习框架的行列中,百度飞桨的实力一直让人无法忽视。因此,飞桨也已吸引了大量使用者,构建了无数工业级应用。
「飞桨平台已吸引了超过 320 万开发者,相比一年前增加近 70%,同时其服务的机构达到了 12 万家。飞桨的发展壮大,见证了 AI 工业大生产的如火如荼。」百度首席技术官、深度学习技术及应用国家工程实验室主任王海峰博士,在昨天的 Wave Summit 深度学习开发者峰会上向我们展示了一连串数字。
5 月 20 日下午,Wave Summit 2021 在北京正式举行。在活动中,百度发布了飞桨九大最新发布和全平台升级,这些新技术和工具来自百度源于产业实践的技术、与开发者共生的开源生态,它们正推动着产业智能化加速到来。

王海峰在 Wave Summit2021 上做开场致辞。
飞桨带来的九大新发布其中包含 6 项技术产品,以及 3 个生态成果和计划。除了为飞桨加入一系列新功能之外,百度还展示了自己在 AI 领域的最新研究成果。
这其中包括:
- 飞桨开源框架 2.1 版
- 云原生机器学习核心 PaddleFlow
- 全新推理部署导航图
- 全新大规模图检索引擎
- 开源文心 ERNIE 四大预训练模型
- 硬件生态大范围覆盖
- 飞桨「大航海」计划
- ……
作为「人工智能时代的操作系统」,飞桨连接了智能芯片的算力与大量基础应用,让最先进 AI 算法的大规模应用成为可能。
飞桨框架 2.1:开发体验太妙了
借助飞桨,数百万开发者已不再需要从头开始编写 AI 算法的代码,即可高效进行技术创新并应用于业务。机器学习门槛的大幅降低,加快了人工智能应用的多样化和规模化。在这背后,百度的 AI 技术经历了长时间的发展。
百度早在 2013 年就成立了深度学习研究院,2016 年 8 月,它率先开源了深度学习框架 PaddlePaddle(飞桨),打造了中国首个自主研发、功能完备、开源开放的产业级深度学习平台。随着这一体系的不断改进,飞桨吸引了数百万开发者。
今年 3 月,飞桨迎来了发展历程中的一个里程碑:2.0 正式版的发布。对于飞桨平台来说,这是一次向智能化「基础设施」进化的全面换代。除了成熟的动态图模式,其在 API 系统、大规模模型训练、软硬件一体化等方面均有大量革新。
5 月 20 日的 Wave Summit 上,飞桨开源框架正式升级到 2.1 版本。百度深度学习技术平台部高级总监马艳军带来了关于飞桨开源的最新进展和发布。

飞桨技术升级
飞桨新版本首先提升的是训练速度。飞桨开源框架 V2.1 着重优化了自动混合精度训练,最大化地使用 FP16 计算,减少与 FP32 的转换开销,并使用了多种策略自动保证模型正常收敛。此外,飞桨开源框架 V2.1 还优化了大量 FP16 算子的性能,在多个领域的主流模型上都有明显的性能提升。
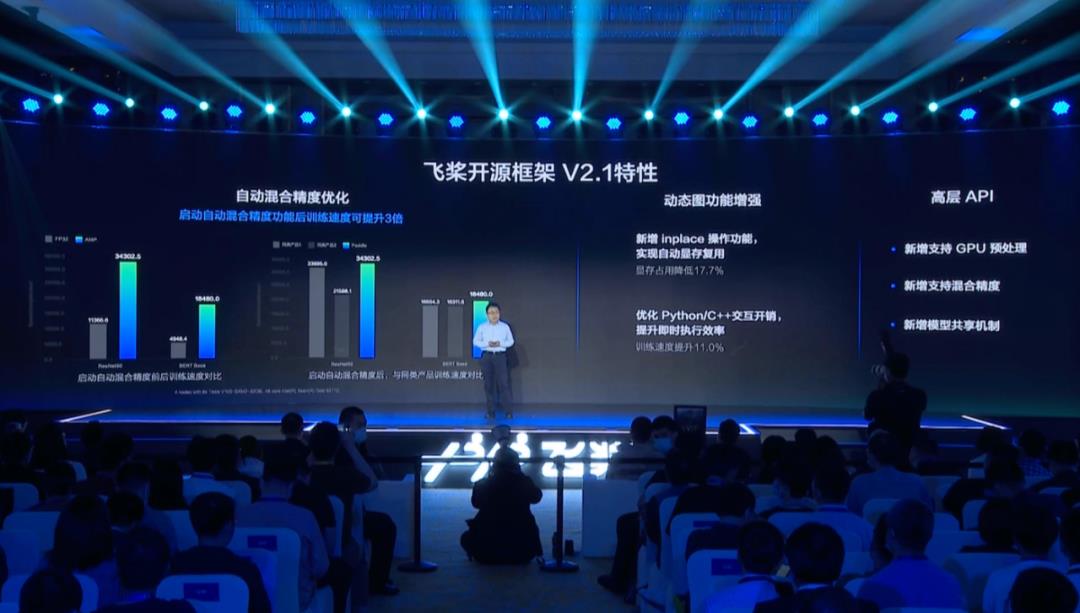
以 ResNet50 和 BERT 为例,启动自动混合精度功能后,模型的训练速度可以提升 3 倍,与同类系统相比处于领先水平(超过了 PyTorch 和 TensorFlow)。
其次,飞桨框架 2.1 版本的动态图功能进一步增强,新增了 inplace 操作功能,实现了自动显存复用,可将显存占用降低 17.7%。此外还优化了 Python/C++ 交互的开销,提升即时执行效率,使得训练速度提升 11%。
在飞桨框架 2.0 版本正式推出的高层 API,这一次也进行了升级,增强了数据预处理类 API,扩展了基于 GPU 设备的计算能力,此外在全流程训练上增加了混合精度策略支持。2.1 版本还新增了模型共享机制,高层 API 可以直接调用飞桨官方算法库中的经典的、复用性高的模型。

同时,飞桨开源框架 V2.1 对自定义算子功能的易用性进行了大量优化,降低开发者自定义算子(op)的学习与开发成本。现在的算子封装更加简洁,隐藏了不必要的框架底层概念,同时彻底打通了训练和推理。通过封装 Python 端扩展 API,实现了一键完成自定义算子编译、安装与接口自动生成,有效降低了开发者编写和使用自定义算子的成本,让开发者更加专注于算子计算的本质。
「在新版本中,就可以像调用飞桨 API 一样调用自己写的自定义算子了。」马艳军说道。
模型部署,全面增强
在大会中,百度还分享了飞桨推理部署工具链的最新升级。至今,模型部署仍是 AI 产业实践中的难题,推理部署工具链条是否通畅,一定程度上决定了 AI 应用最后一公里路走得好不好。
飞桨模型压缩工具 PaddleSlim 有两项重要升级。首先是优化了剪枝压缩技术,新增了非结构化稀疏工具。早期剪枝使用结构化稀疏的方式,剪枝时以某个结构为单元,这样虽然可以直接减小 Tensor 的尺寸和计算量,但一些有价值的网络结构会被「误伤」。而非结构化稀疏则是以每一个数值为单元进行剪枝,更加精确、灵活,通用性、易用性也都非常好。
此外,PaddleSlim 率先支持了 OFA(Once For All)压缩模式,结合多种压缩策略的优势来保障压缩后模型的精度;接口简洁对用户代码低侵入,让用户无需修改现有的模型训练代码。这种方法的可移植性较好,训练一个超网络就可以得到多个适配不同部署环境的子模型,只需对模型微调即可。

借助 OFA 策略,BERT 模型体积减小了 26%,CPU、GPU 实现明显加速。综合使用 PaddleSlim 的压缩策略,CycleGAN 体积减小 97%,CPU、GPU 均有大幅加速。
飞桨的轻量化推理引擎 Paddle Lite 也进行了全面升级。近日,百度发布了面向移动开发者的开箱即用工具集 LiteKit,针对移动端开发的特点对 Paddle Lite 进行了封装,显著降低了端侧 AI 开发者的开发成本。此外,Paddle Lite 在 ARM CPU 和 OpenCL 的推理性能也进一步提升,尤其在广泛应用的 INT8 性能持续保持领先。硬件支持方面,Paddle Lite 与包括瑞芯微、Intel FPGA 开发套件在内的硬件的进一步融合适配,满足了更多应用场景的需要。

针对服务化部署的实际需求,Paddle Serving 新增了全异步设计的 Pipeline 模式,以更好支持现实业务中模型组合使用的问题。多模型应用设计复杂,为了降低开发和维护难度,同时保证服务的可用性,人们通常会采用串行或简单的并行方式,但这种情况下吞吐量仅能达到一般可用状态,且 GPU 利用率普遍偏低。Paddle Serving 的升级很好地解决了这个问题。

右图是在 PaddleOCR 上的测试数据。可以看到,随着用户访问数量的增加,非 Pipeline 模式无论是吞吐量或 GPU 利用率都很快达到了瓶颈,而 Pipeline 模式依然稳步提升,可有效支持企业的大规模部署需求。
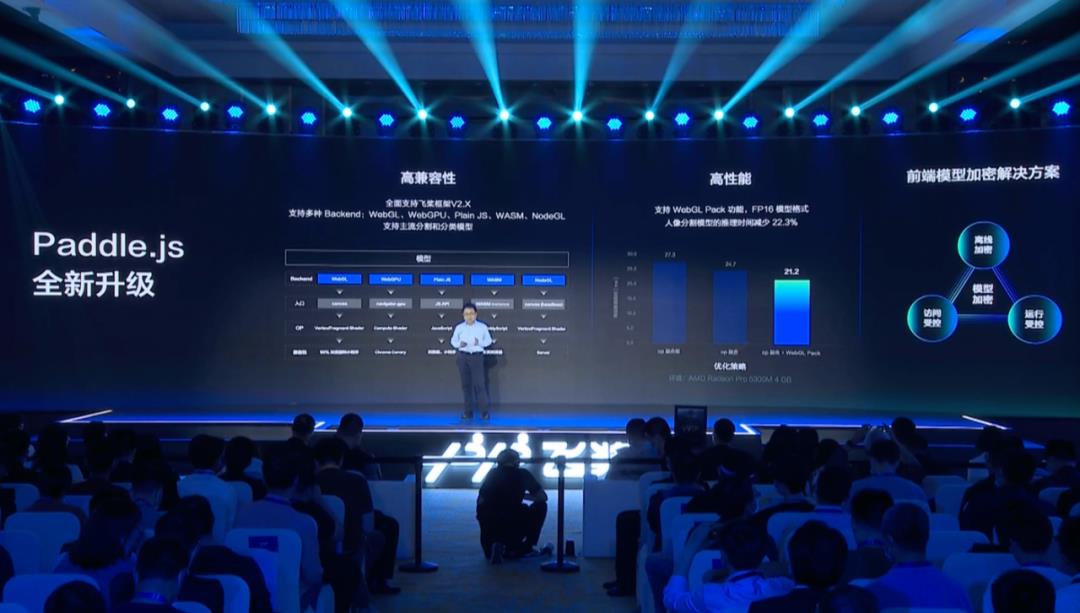
飞桨前端推理引擎 Paddle.js 也获得了进一步增强。升级后的 Paddle.js 保持高兼容性,完整支持了飞桨框架 2.0 及之后版本的模型格式,新增了对多种 Backend 和主流图像分割及分类模型的支持,在高兼容性的同时同时也兼顾了高性能。新增的 WebGL Pack 功能则可以实现数据四通道排布并行计算,减少资源占用。
另外,Paddle.JS 还推出了前端模型加密解决方案,在模型文件离线加密、访问受控、运行推理受控三个重要环节加强保障,有效提高业务的安全性。
飞桨推理部署工具链上的技术升级完成之后,为了让开发者能够快速将想法投入实践,了解「哪条路走得通,哪条路还未走通」,百度将自身 AI 技术实践的经验做成了一张推理部署导航图供人参考:
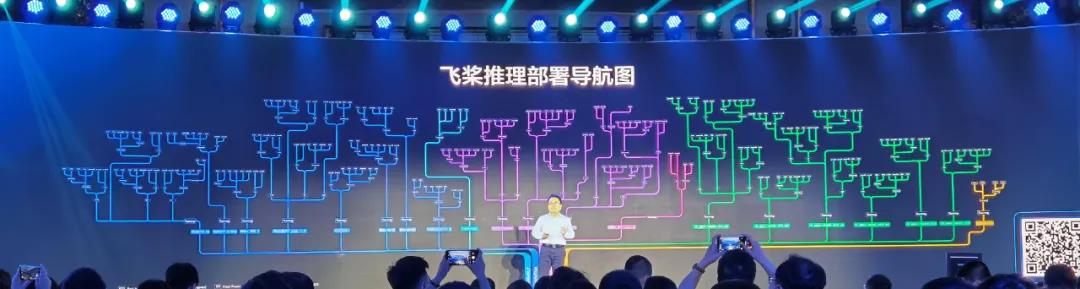
据介绍,这其中已经涵盖了 300 多条经过充分验证的部署通路,未来还会增加更多路径。
云原生机器学习核心 PaddleFlow
除了性能增强和改进,百度本次还宣布机器学习核心 PaddleFlow 开放邀测。PaddleFlow 是首个为专为 AI 平台开发者提供的云原生机器学习核心系统,人们可以基于它开发出更多细分场景和深度定制的 AI 平台。
根据百度 AI 产品研发部总监忻舟介绍,PaddleFlow 具有三层结构,为开发者提供了资源调度、作业执行与服务部署等AI开发平台核心能力,以及友好的开发接口。

在资源调度层,PaddleFlow 带有 AI 平台运行所需的存储,及计算资源的统一接入/调度。支持高性能的 AI 异构计算资源管理,并提供灵活丰富的资源调度策略,包括拓扑感知、超发抢占、GPU 虚拟化等。它支持常见的各种存储系统的统一对接,还提供了高性能存储中间件来加速 AI 计算时数据访问的效率。
在作业执行和服务部署层,提供了AI平台核心关键能力,从作业调度、工作流调度,到模型的管理以及预测服务的管理,并支持包括飞桨在内的深度学习框架以及算法库,以及常见的Spark、MPI等计算类型。
在用户接入层,PaddleFlow 提供易被集成的 REST API、命令行客户端等多种形式,还提供了多租户和基本的认证授权机制,另外对平台管理员支持简单的管理操作,包括任务查看、资源管控等。
百度表示,这一工具性能优异,支持数万算力卡调度、数千并发作业数的大规模并行训练的能力。同时,PaddleFlow 也非常轻量和易于应用,可以实现一键部署安装。针对市场上大多数实际应用条件是单机的情况,PaddleFlow 还对单机部署做了大量优化。
在 AI 领域最热方向,提出更强技术
飞桨框架 2.1 版中还有几个值得关注的重要新技术。
万亿规模图检索引擎

图神经网络是最近 AI 领域的热门方向,随着大规模图学习在知识图谱和搜索推荐领域的广泛应用,大规模图模型训练愈加受到重视。飞桨提供了从分布式数据处理、图检索、前向反向图模型计算、多 server 参数更新的全流程通用分布式能力,形成了大规模图模型训练架构。

对于图检索环节,5 月 20 日,百度正式发布了大规模图检索引擎,将图的邻接表通过双层哈希切分方式存放到不同 graphserver 上,worker 端请求 graphserver 通过图检索引擎获得子图进行训练。经过 Intel CPU 环境上实测,该引擎不仅支持万亿边图模型训练,也能够很好地支持线性扩展。
据介绍,这项技术已在网易云音乐的主播推荐场景上进行了应用:大规模图检索引擎和飞桨分布式训练技术,成功支撑了语音主播业务的十亿级边的图模型训练。通过知识迁移,现在推荐系统可以有效解决冷启动问题,提高推荐场景中的有效播放率。
文心 ERNIE 开源四大预训练模型
百度也在不断推动着 NLP 模型技术研究层面的创新。这一次,文心 ERNIE 语义理解开发套件全新开源发布了 4 大预训练模型:分别是多粒度语言知识增强模型 ERNIE-Gram、超长文本理解模型 ERNIE-Doc、融合场景图知识的跨模态理解模型 ERNIE-ViL和语言与视觉一体的模型 ERNIE-UNIMO。
知识与深度学习相结合实现的语义理解,不仅仅能理解语言,还可以理解图像,实现统一的跨模态语义理解。

其中,ERNIE-Gram 提出了显式的 n-gram 掩码语言模型,通过引入多粒度语言知识增强预训练模型效果,在 5 项典型中文文本任务效果显著超越业界开源的预训练模型。
ERNIE-Doc 针对篇章长文本建模不充分问题,提出回顾式建模技术和增强记忆模型机制,在 13 项长文本理解任务上取得了领先效果。
ERNIE-ViL 针对跨模态理解难题,基于知识增强思想,实现了融合场景知识的跨模态预训练,在 5 项跨模态理解任务上取得效果领先。
ERNIE-UNIMO 进一步增强不同模态间的知识融合,通过跨模态对比学习,同时提升跨模态语义理解与生成、文本理解与生成的效果,在 13 项跨模态和文本任务上实现了测试成绩的领先。
打造最强 AI 算力
强大的 AI 平台不仅需要软件和算法,也需要 AI 芯片的算力,百度飞桨正在与各家芯片厂商进行适配,同时也在研究下一代计算机架构。
硬件生态成果:飞桨硬件生态路线图
去年,百度在 Wave Summit 峰会上正式发布了飞桨硬件生态伙伴圈,如今已有超过 20 家芯片、服务器、ISV 领导厂商相继加入,已适配的芯片或 IP 达到了 31 款,全面地覆盖了国内外知名硬件厂商。

螺旋桨和量桨的升级
在 2020 年 12 月的 Wave Summit + 峰会上,百度正式发布了生物计算平台「PaddleHelix 螺旋桨」。飞桨也开启了与生物计算的「跨界」之旅。

目前,螺旋桨 PaddleHelix 已经升级到了 1.0 正式版本,新增了化合物预训练模型 ChemRL。而且 ChemRL 模型已经应用到了 ADMET、虚拟筛选等下游任务:今年 3 月,在国际权威的图神经网络基准 OGB 的 HIV 和 PCBA 两个药物相关的数据集上,ChemRL 获得双冠军。百度也正式开源了 PaddleHelix(https://github.com/PaddlePaddle/PaddleHelix),供更多开发者探索使用。
经历了一年的发展,在 2020 年 5 月发布的国内首个量子机器学习开发工具「量桨」获得了又一次升级。量桨与飞桨框架 2.0 及其之后的版本同步更新,整体运行速度得到了大幅提升,在核心应用场景平均提升达到 21.9%,最高提升达到 40.5%。

其整体功能也得到了进一步加强,适配了近期量子设备,新增量子核方法等特征提取方式。对于难度很大的纠缠提纯任务,量桨新增了最优化量子纠缠处理框架,给出了目前业界最优且可实施的提纯方案。
EasyDL 和 BML 双平台:全面升级
面对各个行业面临的众多场景需求,飞桨企业版采用 AI 开发双平台的形式——EasyDL 零门槛 AI 开发平台和 BML 全功能 AI 开发平台,让不够精通人工智能算法的企业开发者能够像使用家电一样简单的用起 AI,更多的专注于业务场景和创新。另一方面,AI 技术专家也可以更高效地开发出全新技术,并快速进行部署。

这一次,EasyDL 和 BML 同时迎来了多项升级。
EasyDL 在数据处理、训练与评估、模型部署及性能优化方面做了 200 多项自动化机制,并基于近期开发者需求的分析,对场景适配优化和模型评估与诊断做了重点优化。EasyDL 的宗旨成为一个提供自动化建模的平台,通过对各个核心环节的技术创新,实现端到端全流程的自动化,让开发者在极简的用户体验下获得高精度的模型效果。

相对 EasyDL 的零门槛自动化机制,BML 则提供了更多开发模式,让开发者针对不同的场景灵活把握更多环节。比如 Notebook 建模、可视化拖拽建模、预置模型开发和 Pipeline 建模等。
「我们将飞桨中优秀的开发套件,例如 ERNIE、PaddleOCR,以及机器学习的算法以及 AutoDl、VisualDL 等工具组件,结合产业最佳实践,优选出 67 套模型和网络的组合,预置在我们的平台里面,加速开发,大约可以节省 80% 的开发时间。」忻舟说道。

此外,来自成都国铁等企业的嘉宾也现场分享了基于飞桨实现的产业应用实践。
在交通运输领域,成都国铁已构建起可以全方位、多维度、高频次实现对高速铁路供电设备实施数字化检测 / 监测的自动化系统。它可以对动车、高铁实现实时的运营检查,又被迁移至深圳地铁的部分线路。利用嵌入式设备的轻量级算力,初步处理过的数据通过 4G/5G 网络传输到服务器端进行二次检测。边云一体的解决方案,使得地铁车辆可以在正常运行的时间进行检测,减少了地铁检修人员熬夜巡检的次数。
15 个亿,10 万家企业,超百万人才
在去年的 WAVE SUMMIT+2020 深度学习开发者峰会上,百度发布了飞桨「大航海」启航计划,围绕高校人才培养,未来三年,投入总价值 5 亿元的资金与资源,支持全国 500 所高校,重点培训 5000 位高校 AI 师资,联合培养 50 万学子。
这一路线,要贯彻到底。在昨天的活动中,百度宣布投入更多资金——「大航海」护航计划,以及「大航海」领航计划正式启动。
「大航海」护航计划指的是百度将在未来三年投入 10 亿元资金,从技术赋能、人才赋能、生态赋能全方位支持 10 万家企业智能化升级,与产业界一起培养百万 AI 人才。
「大航海」领航计划面向核心开发者,百度将与社区开发者一起共建开源生态,携手探索 AI 前沿技术领域。据了解,目前已认证 120 位 PPDE(飞桨开发者技术专家),飞桨城市 / 高校领航团达到 150 个。
去年启动的「大航海」启航计划,如今在阶段性成果之上带来了新发布:《AI 人才产教融合培养方案》,致力于构建全面实用的高校 AI 人才培养方案,包括 AI Studio 教学平台、免费算力、产业级案例和数据集、专项合作等。
此外,百度还在活动中举行了「百度奖学金」的颁奖,飞桨和清华大学、吉林大学、郑州大学三大高校创新创业实验室现场签约,宣布在课程共建、赛事合作、人才、产学结合等方面展开合作,共同推进产学研用一体化发展。

如今,我们正处于以人工智能为核心驱动力量的第四次工业革命浪潮之中,如何推动人工智能进入工业大生产阶段,成为多方思考的关键命题。如何把 AI 技术的价值带入到企业的生产活动当中,是否存在一条可以参考、可以实践的路径?
百度集团副总裁、深度学习技术及应用国家工程实验室副主任吴甜认为,这条路可以分为三个阶段,第一阶段是企业中有少数先行人员尝试引入 AI,称之为 AI 先行者探路阶段;当进行了验证后,会从个人实践转变成建设团队来学习和应用 AI,称之为 AI 工作坊应用阶段;当企业逐渐进行大量的 AI 应用,几百、几千人一起工作,多人多任务协同生产,就进入了 AI 工业大生产阶段,更长期看,还会实现社会化协同生产。
如今人工智能技术在各行业不断渗透,面对不同的应用场景,开发者们提出了更多复杂的需求,持续降低门槛是 AI 工具重要的发展方向。
在解决如何让 AI 变得更简单这个问题上,飞桨从未停止进化:从核心框架、模型库,再到开发套件和工具组件、AI开发平台,飞桨在技术上不断突破,在功能上持续丰富,在服务上愈加完善,支撑起了越来越多创新和产业智能化的发展。
百度飞桨将在 AI 的工业大生产过程中成为至关重要的一环。
以上是关于320万开发者在用的飞桨,全新发布推理部署导航图:打通AI应用最后一公里的主要内容,如果未能解决你的问题,请参考以下文章
如何在Jetson nano上同时编译TensorRT与Paddle Lite框架
百度飞桨重磅推出端侧推理引擎Paddle Lite 支持更多硬件平台
飞桨端侧推理引擎重磅升级为Paddle Lite,更高扩展性更极致性能!
关于飞桨UIE等模型预测推理时间很久的问题分析以及解决,蒸馏剪枝部署问题解决