百度深度学习平台飞桨( PaddlePaddle )再放大招!端侧推理引擎全新升级,重磅发布 Paddle Lite ,旨在推动人工智能应用在端侧更好落地。该推理引擎在多硬件、多平台以及硬件混合调度的支持上更加完备,是飞桨在 Paddle Mobile 的基础上进行的一次大规模升级迭代。通过对底层架构设计的改进,扩展性和兼容性等方面实现显著提升。目前, Paddle Lite 已经支持了 ARM CPU , Mali GPU , Adreno GPU ,华为 NPU 以及 FPGA 等诸多硬件平台,是目前首个支持华为NPU 在线编译的深度学习推理框架。 随着技术进步,手机等移动设备和边缘设备已成为非常重要的本地深度学习载体。然而日趋异构化的硬件平台和复杂的终端侧的使用状况,让端侧推理引擎的架构能力颇受挑战。端侧模型的推理往往还面临着严苛的算力和内存的限制。 为了能够更完善地支持众多的硬件架构,并且实现在这些硬件之上深度学习模型性能的极致优化,百度飞桨基于 Paddle Mobile 预测库,融合 Anakin 等多个相关项目的技术优势,全新发布端侧推理引擎 Paddle Lite 。通过全新架构高扩展性和高灵活度地建模底层计算模式,加强了多种硬件支持、混合调度执行和底层实现的深度优化,更好满足人工智能应用落地不同场景。 此次升级发布, Paddle Lite 对应着架构的重大升级,在多硬件、多平台以及硬件混合调度的支持上更加完备。 不仅涵盖 ARM CPU 、 Mali GPU 、 Adreno GPU 、华为 NPU 等移动端芯片,也支持 FPGA 等边缘设备常用硬件,并具备可兼容支持云端主流芯片的能力。 Paddle Lite 还是首个华为 NPU 在线编译的深度学习推理框架。更早之前,百度和华为宣布在 AI 开发者大会上强强联手。
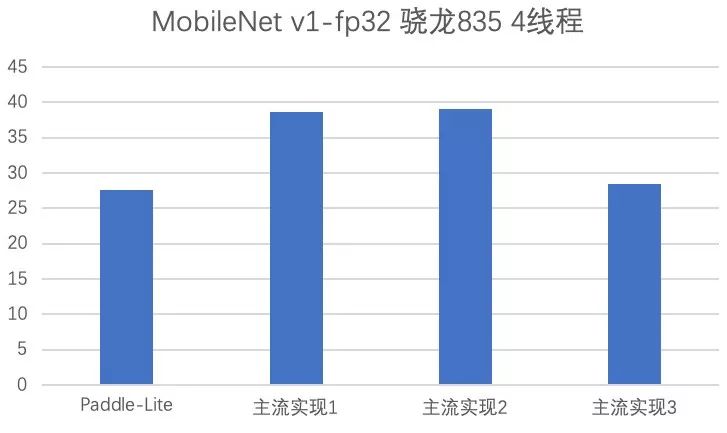
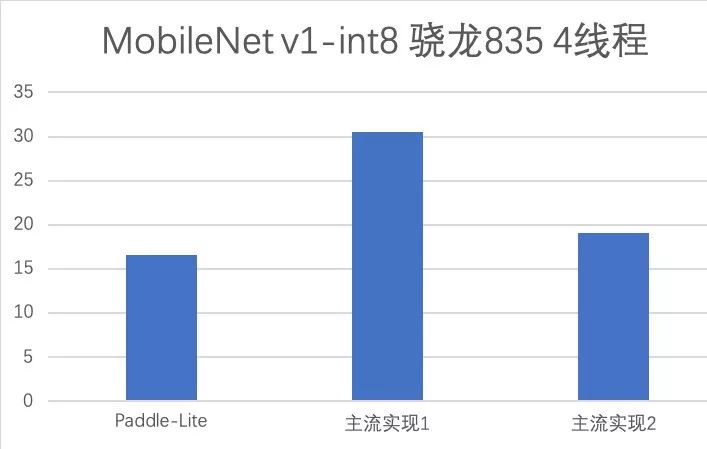
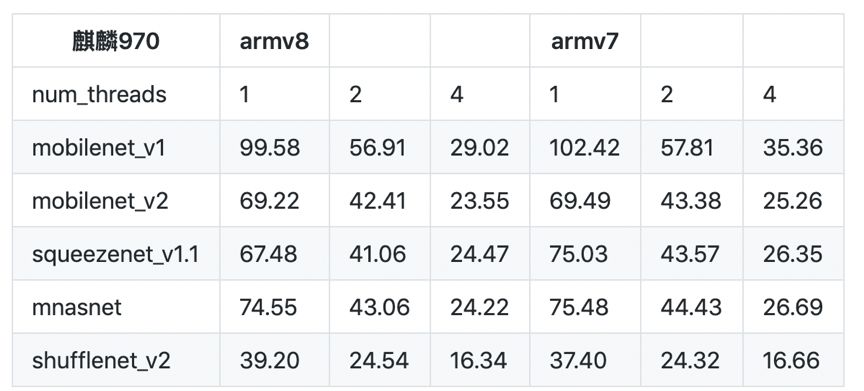
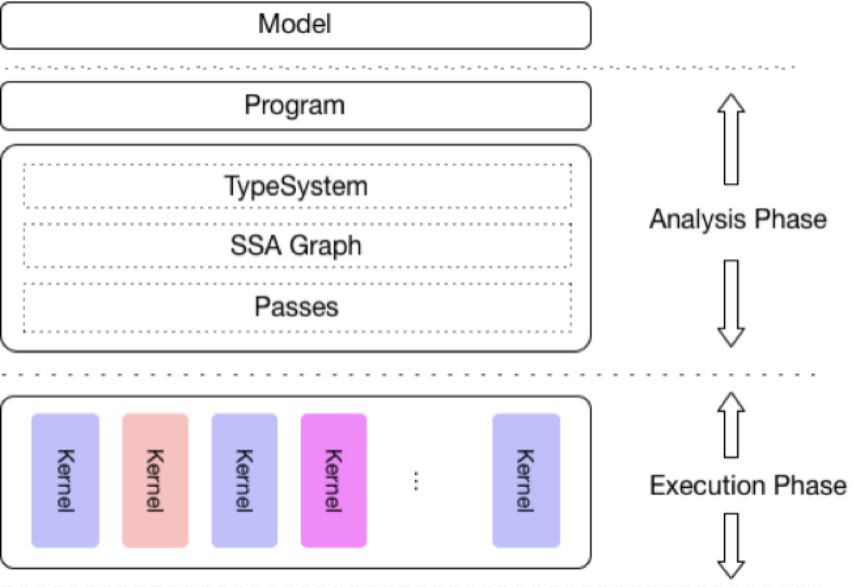
Paddle Lite 支持范围更广的 AI 硬件终端,增强了部署的普适性,并且具备明显的性能优势。 Paddle Lite 五大特性 Paddle Lite 一共有五大特性:高扩展性、训练推理无缝衔接、通用性、高性能和轻量化。1.高扩展性新架构对硬件抽象描述能力更强,可容易地在一套框架下对新硬件进行集成,具有非常好的扩展性。例如,对于 FPGA 的扩展支持变得非常简单。此外,参考了 LLVM 的 Type System 和 MIR ( Machine IR ),可以模块化地对硬件和模型进行更细致的分析和优化,可以更便捷高效地扩展优化策略,提供无限可能。目前,已经支持21种 Pass 优化策略,涵盖硬件计算模式混合调度、INT8 量化、算子融合、冗余计算裁剪等不同种类的优化。2.训练推理无缝衔接不同于其他一些独立的推理引擎, Paddle Lite 依托飞桨训练框架及其对应的丰富完整的算子库,底层算子的计算逻辑与训练严格一致,模型完全兼容无风险,并可快速支持更多模型。和飞桨的 PaddleSlim 模型压缩工具打通,直接支持 INT8 量化训练的模型,并可获得比离线量化更佳的精度。3.通用性官方发布18个模型的 benchmark ,涵盖图像分类、检测、分割及图像文字识别等领域,对应80个算子 Op +85个 Kernel,相关算子可以通用支持其他模型。兼容支持其他框架训练的模型,对于 Caffe 和 TensorFlow 训练的模型,可以通过配套的 X2Paddle 工具转换之后进行推理预测。支持多硬件,目前已支持的包括 ARM CPU , Mali GPU 、 Adreno GPU 、华为 NPU 、 FPGA 等,正在优化支持的有寒武纪、比特大陆等 AI 芯片,未来还会支持其他更多的硬件。此外,还提供 Web 前端开发接口,支持 javascript 调用 GPU ,可在网页端快捷运行深度学习模型。4.高性能在 ARM CPU 上,性能表现优异。针对不同微架构,进行了 kernel 的深度优化,在主流移动端模型上,展现出了速度优势。