如何在Jetson nano上同时编译TensorRT与Paddle Lite框架
Posted 百度大脑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何在Jetson nano上同时编译TensorRT与Paddle Lite框架相关的知识,希望对你有一定的参考价值。

【飞桨开发者说】刘毅波,北京理工大学徐特立学院本科二年级,致力于模型在嵌入式设备的部署和推理加速。
指导老师:北京理工大学鲁溟峰教授

我从上学期开始逐渐接触飞桨深度学习框架,当时的飞桨逐步为广大开发者熟知。半年过去,生态不完善不再是扣在飞桨框架上的一顶帽子。如果你仍怀偏见,那么建议从现在开始深入地了解和使用它。
由于参加的百度人工智能创意赛的算法组要求了EasyDL的使用,所以我需要在嵌入式硬件上搭建Paddle框架,才能部署队友训练好的模型。目前可以实现加速模型推理的方式多种多样,但从通用性和部署简易性上讲,我认为使用低功耗GPU进行加速的Jetson系列相对更好。同时,飞桨对该系列的硬件支持较好:一方面可以通过百度针对终端发布的轻量化推理引擎PaddleLite进行部署,同时使用模型量化等操作加速推理;另一方面可以使用飞桨原生推理库Paddle Inference,通过调用Paddle-TensorRT接口,充分地利用Nvidia的软硬件资源。
考虑到比赛中模型改进的可能,需要建立一个更有普适性的部署环境,因此选择了第二种方案。
最终,在搜集了相关文档后,决定通过源码编译的方式在Jetson nano上安装Paddle框架。因为已有的教程都没有提及TensorRT的功能如何配置,我也在尝试中找到了一种合理的配置方法。本教程就在不断的失败和尝试中诞生,希望可以为各位开发者扫清配置Paddle环境的障碍。
第一部分:编译时的环境
首先确认Jetson nano环境,这里建议初学者尽量不选择最新的Jetpack。略低的版本受支持情况更好,同时有更多针对Bug的解决方案。我使用的版本如下(镜像来自Nvidia官网):
JetPack4.3
Found Paddle host system: ubuntu, version: 18.04.3
-- Found Paddle host system's CPU: 4 cores
-- CXX compiler: /usr/bin/c++, version: GNU 7.5.0
-- C compiler: /usr/bin/cc, version: GNU 7.5.0
第二部分:编译前的准备工作
这部分包括依赖的安装、以及对系统的设置来保证编译过程的顺利进行。同时修改和打包TensorRT的库文件,为后续编译做准备。
安装所需的依赖:
sudo pip install virtualenv #虚拟环境的依赖
sudo apt-get install python3.6-dev liblapack-dev gfortran libfreetype6-dev libpng-dev libjpeg-dev zlib1g-dev patchelf python3-opencv
对nano的设置:
打开性能模式加快编译速度;受制于nano硬件资源,需要增加swap空间防止编译中内存不足的情况发生;同时,需要修改Linux系统对同时打开文件的数量限制。
#打开性能模式
sudo nvpmodel -m 0 && sudo jetson_clocks
#增加swap空间,防止爆内存
swapoff -a
sudo fallocate -l 15G /swapfile
sudo chmod 600 /var/swapfile
sudo mkswap /swapfile
sudo swapon /swapfile
swapon -a
sudo swapon –show #用来修改结果
#最大的文件打开数量
ulimit -n 2048
上方对Jetson nano的设置务必要进行,swap空间的大小可以根据自己存储卡的大小设置,建议设置8G及以上的swap空间。
更改TensorRT相关库文件:
在NvInferRuntime.h中class IPluginFactory和class IGpuAllocator里分别添加虚析构函数。
virtual ~IPluginFactory() ;
virtual ~IGpuAllocator() ;
修改protected: ~IOptimizationProfile() noexcept = default为:
virtual ~IOptimizationProfile() noexcept = default;
之后的编译过程中,如果仍报没有虚析构函数的问题时,改法都是找到缺少的位置添加类的虚构函数。
整理TensorRT库文件:
我从官方文档以及提的issue找出的一种方法,即通过模仿x86_64上的TensorRT环境,来适应cmake文件的编译命令。Nvidia官方的TensorRT库呈现以下结构:
─include
│ NvCaffeParser.h
│ NvInfer.h
│ NvInferPlugin.h
│ NvOnnxConfig.h
│ NvOnnxParser.h
│ NvUffParser.h
│ NvUtils.h
│
└─lib
libnvcaffe_parser.a
libnvcaffe_parser.so
libnvcaffe_parser.so.4
libnvcaffe_parser.so.4.1.0
libnvinfer.a
libnvinfer.so
libnvinfer.so.4
libnvinfer.so.4.1.0
libnvinfer_plugin.a
libnvinfer_plugin.so
libnvinfer_plugin.so.4
libnvinfer_plugin.so.4.1.0
libnvparsers.a
libnvparsers.so
libnvparsers.so.4
libnvparsers.so.4.1.0
因为编译命令通过指定TensorRT_ROOT的方式找到include和lib中的相关文件。因此需要手动在nano的usr/文件夹中找到上述文件并整理成这种形式。个人的Jetpack 4.3 中库文件分别在在/usr/lib/aarch64-linux-gnu 和 /usr/include/aarch64-linux-gnu。由于镜像中TensorRT的库文件的位置分散在两个不同路径,不建议修改cmake文件来找相应库文件。
第三部分:编译流程
第一步:建立安装Paddle的虚拟python环境
因为JetPack4.3的nano自带相应的cv2模块,不需要再安装,只需链接即可。因此我使用的是方便找到文件夹的venv工具去创建虚拟环境,方便后续链接cv2库。创建虚拟python环境:
python3 -m venv name-of-env #在一个你可以记住的文件夹创建
链接cv2模块:这部分内容需要根据个人的配置修改。链接的前半部分是本机cv2,后面是要链接到的虚拟环境cv2。
ln -s /usr/lib/python3.6/dist-packages/cv2/python-3.6/cv2.cpython-36m-aarch64-linux-gnu.so path-to-venv/name-of-venv/lib/python3.6/site-packages/cv2.so
使TensorRT对虚拟环境python可见。如果初次使用,需要配置CUDA环境变量。
# 添加CUDA环境变量
export CUDA_HOME=/usr/local/cuda
export PATH=$CUDA_HOME/bin:$PATH
export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH
source ~/.bashrc
测试cuda是否可见:
nvcc –version
如果是如下提示,那么可以继续接下来的步骤。
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2018 NVIDIA Corporation
Built on ...
Cuda compilation tools, release 10.0, Vxxxxx
为了使Jetpack中的TensorRT对虚拟环境的python可见,需要在命令行中运行:
export PYTHONPATH=/usr/lib/python3.6/dist-packages:$PYTHONPATH
source ~/.bashrc
进入虚拟环境并测试cv2,paddle_env为虚拟python环境的文件夹名。用下方命令进入虚拟环境,成功后会在终端中出现(paddle) root@ubuntu:***的提示。
source paddle_env/bin/activate
测试cv2和tensorrt
#测试cv2和tensorrt
python
import cv2
import tensorrt
以上没有报错方可继续。
第二步:安装必要的包
首先需要在虚拟环境中安装不包括在requirements.txt但又是必要的依赖:(依赖版本没有要求,测试中没有遇到不兼容的情况)
pip install cython wheel numpy
然后克隆Paddle的Github
git clone https://github.com/paddlepaddle/paddle
进入克隆的Paddle文件夹,安装其他依赖:
cd Paddle
pip install -r python/requirements.txt
第三步:选择版本以及编译安装NCCL
查看可用的版本:
git tag
切换版本:我使用的是2.0.0,不是稳定的版本。不选择1.8.x版本的原因是在尝试中发现该系列版本都会出现报缺少cpuid.h文件的错误,该问题已经在Paddle最新版本修复。
git checkout v2.0.0-alpha0
安装NCCL依赖,此过程可能持续近1h。
git clone https://github.com/NVIDIA/nccl.git
make -j4
make install
第四步:配置cmake并开始编译Paddle
首先创建并进入build文件夹
mkdir build
cd build/
Cmake设置:
之前的准备步骤中我们已经将Paddle编译需要的TensorRT库整理成了适应cmake文件的形式,之后只需要指定TensorRT库的位置即可。接下来的cmake命令指定了编译结果所支持的功能。其他配置可以参考Paddle Inference文档中源码编译的部分。
-DWITH_PYTHON=ON使编译结果内嵌python解释器并编译whl,
-DTENSORRT_ROOT指定TensorRT库的路径,
-DCUDA_ARCH_NAME=Auto指定编译结果只适应当前的GPU架构,可以节省编译时间。
cmake .. \\
-DWITH_CONTRIB=OFF \\
-DWITH_MKL=OFF \\
-DWITH_MKLDNN=OFF \\
-DWITH_TESTING=OFF \\
-DCMAKE_BUILD_TYPE=Release \\
-DON_INFER=ON \\
-DWITH_PYTHON=ON \\
-DWITH_XBYAK=OFF \\
-DWITH_NV_JETSON=ON \\
-DPY_VERSION=3.6 \\
-DTENSORRT_ROOT=/home/dlinano/Paddle/TensorRT \\
-DCUDA_ARCH_NAME=Auto
开始编译(过程很漫长):
#使用全部核心
make -j4
# 生成预测lib
make inference_lib_dist
#安装编译好的paddlepaddle-gpu的whl
pip install -U python/dist/*.whl #还是在build文件夹
第五步:使用python预测接口运行Paddle-Inference-Demo中的yolov3例子
克隆并进入目标文件夹:
git clone https://github.com/PaddlePaddle/Paddle-Inference-Demo.git
cd Paddle-Inference-Demo/python/yolov3
运行demo前,需要下载GitHub中提供的测试图片,放入yolov3文件夹。同时也需要下载提供的训练好的模型,放入创建的yolov3_infer文件夹。最终文件结构如下:
yolov3
│ infer_yolov3.py
│ kite.jpg
│ README.md
│ utils.py
│
└─yolo3_infer
__model__
__params__
根据官方文档的介绍,预测过程主要分为以下几个步骤。
1.配置推理选项
2.创建Predictor
3.准备模型输入
4.模型推理
5.获取模型输出
在jetson nano上推理,需要修改推理配置的部分代码:
推理配置对应AnalysisConfig类,建立其对象时需要指定模型路径。所有可选配置可以参考飞桨官方文档中的python预测API介绍。使用 TensorRT加速时,需要调用Paddle提供的接口,即AnalysisConfig类的enable_tensorrt_engine()方法。之后用以上配置创建predictor。
#对infer_yolov3.py中的推理配置进行修改:
def create_predictor(args):
if args.model_dir is not "":
config = AnalysisConfig(args.model_dir)
else:
config = AnalysisConfig(args.model_file, args.params_file)
config.switch_use_feed_fetch_ops(False)
config.enable_memory_optim()
if args.use_gpu:
config.enable_use_gpu(1000, 0)
config.enable_tensorrt_engine(
precision_mode=AnalysisConfig.Precision.Half,
use_static=False,
use_calib_mode=False) #tensorrt_engine with FP16 accuracy
else:
# If not specific mkldnn, you can set the blas thread.
# The thread num should not be greater than the number of cores in the CPU.
config.set_cpu_math_library_num_threads(4)
#config.enable_mkldnn()
predictor = create_paddle_predictor(config)
return predictor
其余代码可以不做修改,再用下方的命令开始预测。该命令运行了infer_yolov3.py文件,同时指定了模型和参数的位置,以及GPU的使用情况。
python infer_yolov3.py --model_file=./yolov3_infer/__model__ params_file=./yolov3_infer/__params__ --use_gpu=1
第四部分:效果展示
打印提示使用到了TensorRT的模型优化。看到Paddle-TRT字样就可以确定我们成功使用Paddle框架调用了TensorRT进行加速。模型的优化会占用大量GPU资源,耗时也较长。

预测输出的图片:

速度测试:
比较了在6c12t的i7-8750H、4核Arm A53以及Jetson nano GPU推理单张图片的耗时。结果如下:
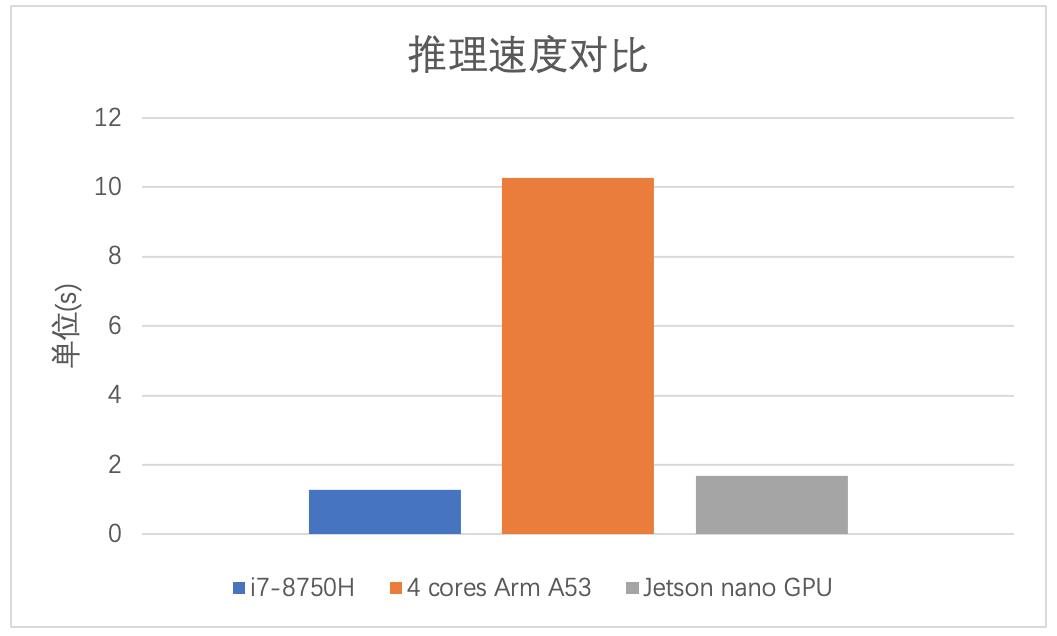
奉上遇到问题的解决方法
1. 缺少虚析构函数的问题
解决方法为第二部分“编译前的准备工作”中对TensorRT库文件的修改。
2. 编译中没有错误提示,但是编译失败
例如报错为:
paddle/fluid/operators/CMakeFiles/edit_distance_op.dir/edit_distance_op_generated_edit_distance_op.cu.o
nvcc error : 'cicc' died due to signal 9 (Kill signal)
问题在于swap区不够。解决方案参考第二部分“编译前的准备工作”中对Jetson nano设置。
3. *****:Too many files
需要修改系统打开文件最大数量的限制。解决方案参考第二部分“编译前的准备工作”中对Jetson nano设置。
参考资料:
https://www.jianshu.com/p/a352f538e4a1
https://paddle-inference.readthedocs.io/en/latest/user_guides/source_compile.html
https://www.paddlepaddle.org.cn/documentation/docs/zh/advanced_guide/inference_deployment/inference/build_and_install_lib_cn.html
https://paddle-inference.readthedocs.io/en/latest/optimize/paddle_trt.html
https://github.com/PaddlePaddle/Paddle-Inference-Demo/tree/master/python/yolov3
最后感谢飞桨技术人员在Github及时回答问题。
测试Paddle-Inference-Demo其他例子,欢迎访问项目地址:
Github:
https://github.com/PaddlePaddle/Paddle-Inference-Demo
Paddle Inference官方文档:
https://paddle-inference.readthedocs.io/en/latest/index.html
如在使用过程中有问题,可加入飞桨官方QQ群进行交流:1108045677或飞桨推理部署QQ群:959308808。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
官网地址:
https://www.paddlepaddle.org.cn
飞桨开源框架项目地址:
GitHub:
https://github.com/PaddlePaddle/Paddle
Gitee:
https://gitee.com/paddlepaddle/Paddle
END

以上是关于如何在Jetson nano上同时编译TensorRT与Paddle Lite框架的主要内容,如果未能解决你的问题,请参考以下文章