打怪升级之小白的大数据之旅(五十五)<Zookeeper命令行与API应用>
Posted GaryLea
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了打怪升级之小白的大数据之旅(五十五)<Zookeeper命令行与API应用>相关的知识,希望对你有一定的参考价值。
打怪升级之小白的大数据之旅(五十五)
Zookeeper命令行与API应用
上次回顾
上一章,我们对zookeeper的基本概念以及环境搭建进行了学习与配置,有了环境,接下来就正式操作zookeeper啦
zookeeper实战
zookeeper和HDFS一样,同样分为命令行和客户端操作两种方式,主要就是各种命令和API的调用,大家需要的时候查看这篇博客即可
命令行操作
| 命令基本语法 | 功能描述 |
|---|---|
| help | 显示所有操作命令 |
| ls path 使用 ls 命令来查看当前znode的子节点 | -w 监听子节点变化 -s 附加次级信息 |
| create 普通创建 | -s 含有序列 -e 临时(重启或者超时消失) |
| get path 获得节点的值 | -w 监听节点内容变化 -s 附加次级信息 |
| set | 设置节点的具体值 |
| stat | 查看节点状态 |
| delete | 删除节点 |
| deleteall | 递归删除节点 |
具体操作方法(注意,一定先启动了zookeeper才可以开启客户端)
-
启动客户端
zkCli.sh -
help显示所有操作命令help -
ls查看当前znode总所包含的内容# 查看根节点下所有的内容 ls / -
ls2查看当前节点详细数据# 查看根节点下的详细信息 ls2 / -
create分别创建2个普通节点# 创建一个节点 sanguo 并且添加值jinlian create /sanguo "jinlian" # 在节点sanguo下创建一个shuguo,在shuguo节点下添加内容 liubei create /sanguo/shuguo "liubei" -
get获得节点的值# 获取sanguo节点中存储的节点值 jinlian get /sanguo # 获取sanguo节点下的子节点shuguo的节点值 liubei get /sanguo/shuguo -
create -e创建临时节点# 在sanguo节点下创建一个临时节点wuguo 并且添加节点值zhouyu create -e /sanguo/wuguo "zhouyu"注意:临时节点在当前客户端是可以看到的,当我们关闭客户端重新连接后,临时节点就自动销毁了
-
create -s创建带序号的节点# 先创建一个普通的根节点/sanguo/weiguo /sanguo/weiguo # 然后创建一个带序号的子节点weiguo 然后再weiguo下面创建一个子节点xiaoqiao并且添加节点值为 jinlian create -s /sanguo/weiguo/xiaoqiao "jinlian" -
set修改节点的数据值# 修改sanguo下的weiguo节点中的值为simayi set /sanguo/weiguo "simayi" -
get -w监听节点的值变化情况- 在hadoop104主机上注册监听/sanguo节点数据变化
get -w /sanguo - 在hadoop103主机上修改/sanguo节点的数据
set /sanguo "zhaoyun" - 观察hadoop104主机收到数据变化的监听,此时会显示下面的内容
WatchedEvent state:SyncConnected type:NodeDataChanged path:/sanguo
- 在hadoop104主机上注册监听/sanguo节点数据变化
-
ls -w监听节点中子节点的变化情况(路径变化)- 在hadoop104主机上注册监听/sanguo节点的子节点变化
bashls -w /sanguo - 在hadoop103主机/sanguo节点上创建子节点
create /sanguo/qinguo - 观察hadoop104主机收到子节点变化的监听
WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/sanguo
- 在hadoop104主机上注册监听/sanguo节点的子节点变化
-
delete删除节点# 删除 /sanguo/节点下的jin_guo delete /sanguo/jin_guo -
deleteall递归删除节点# 递归删除/sanguo下的shuguo中所有的内容 deleteall /sanguo/shuguo -
stat查看节点状态
# 查看/sanguo的节点状态
stat /sanguo
客户端操作
命令行模式介绍完后,下面就是如何通过代码来操作zookeeper,同样的,我们需要先在idea中配置一下
IDEA环境搭建
搭建前的准备工作,在zookeeper官网下载zookeeper的源码包,然后我们将其解压

解压后的文件

第一步: 创建一个Maven工程
第二步: 添加依赖到pom.xml配置文件
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.zookeeper/zookeeper -->
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.5.7</version>
</dependency>
</dependencies>
第三步: 添加log4j.properties
- 需要在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入
log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
第四步:关联zookeeper的源码到我们的项目中

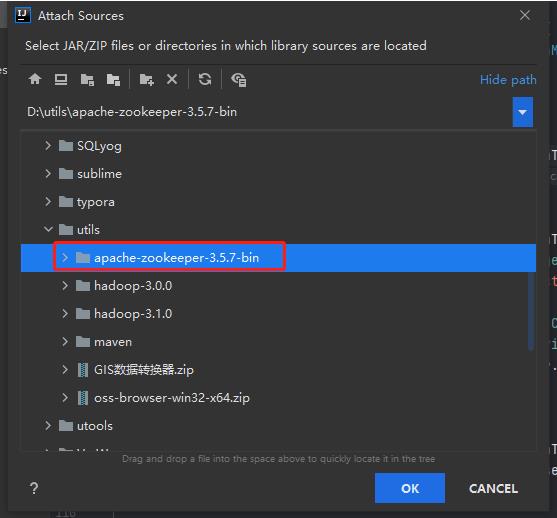
通过代码操作zookeeper
操作方式和HDFS,JDBC类似,我就直接上代码了,步骤同样是:
- 创建连接zk的连接对象
- 具体操作
- 释放资源
package com.company.zk;
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.util.List;
/*
通过代码操作ZK:
1.创建连接对象
2.具体的操作
3.关闭资源
*/
public class ZKDemo {
private ZooKeeper zk;
@Before
public void before() throws IOException {
/*
ZooKeeper(String connectString, int sessionTimeout, Watcher watcher)
connectString : zk节点的地址
sessionTimeout : 会话超时时间
watcher :监听器对象(当我们监听的节点或数据发生改变,zk就会调用该对象中的process方法
所以可以在process方法中去实现监听事件发生后的业务逻辑代码)
注意:该监听器对象是对所有事件进行监听(咱们一般不用)。
*/
String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";
//1.创建连接对象
zk = new ZooKeeper(connectString, 4000, new Watcher() {
public void process(WatchedEvent event) {
}
});
}
@After
public void after(){
//3.关资源
try {
if (zk != null) {
zk.close();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
/*
创建子节点
*/
@Test
public void test() throws IOException, KeeperException, InterruptedException {
/*
create(final String path, byte data[], List<ACL> acl,
CreateMode createMode)
path : 节点路径
data : 节点上存储的数据
acl : 访问控制权限(节点的)
createMode : 节点的类型(无序列号永久 无序列号临时 有序列号永久 有序列号临时)
*/
//2.具体的操作
String s = zk.create("/0323/canglaoshi", "mei".getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.out.println(s + "=====================================");
}
/*
判断子节点是否存在
*/
@Test
public void test2() throws KeeperException, InterruptedException {
/*
exists(String path, boolean watch)
path : 节点路径
watch : 是否监听该节点
注意 : 如果节点不存在则返回null
*/
Stat exists = zk.exists("/0323/canglaoshi1236666", false);
System.out.println((exists==null)?"不存在":"存在");
}
/*
获取子节点并监听节点变化
*/
@Test
public void test3() throws KeeperException, InterruptedException {
/*
getChildren(final String path, Watcher watcher)
path : 节点路径
watcher :监听器对象(当我们监听的节点或数据发生改变,zk就会调用该对象中的process方法
所以可以在process方法中去实现监听事件发生后的业务逻辑代码)
返回结果为所有的子节点
*/
List<String> children = zk.getChildren("/0323", new Watcher() {
/*
当节点发生变化后后被调用
注意:该方法不一定什么时候会被调用。
*/
public void process(WatchedEvent event) {
System.out.println("节点发生了变化");
}
});
//遍历所有的子节点
for (String name : children) {
System.out.println(name);
}
//让线程睡觉
Thread.sleep(Long.MAX_VALUE);
}
/*
循环监听子节点变化
*/
@Test
public void test4() throws KeeperException, InterruptedException {
listener();
//让线程睡觉
Thread.sleep(Long.MAX_VALUE);
}
public void listener() throws KeeperException, InterruptedException {
List<String> children = zk.getChildren("/0323", new Watcher() {
/*
当节点发生变化后后被调用
注意:该方法不一定什么时候会被调用。
*/
public void process(WatchedEvent event) {
System.out.println("节点发生了变化");
//再次监听
try {
listener();
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
//遍历所有的子节点
for (String name : children) {
System.out.println(name);
}
}
}
监听服务器节点动态上下线案例
下面就来模拟演示上一章zookeeper应用中服务器动态上线下的案例
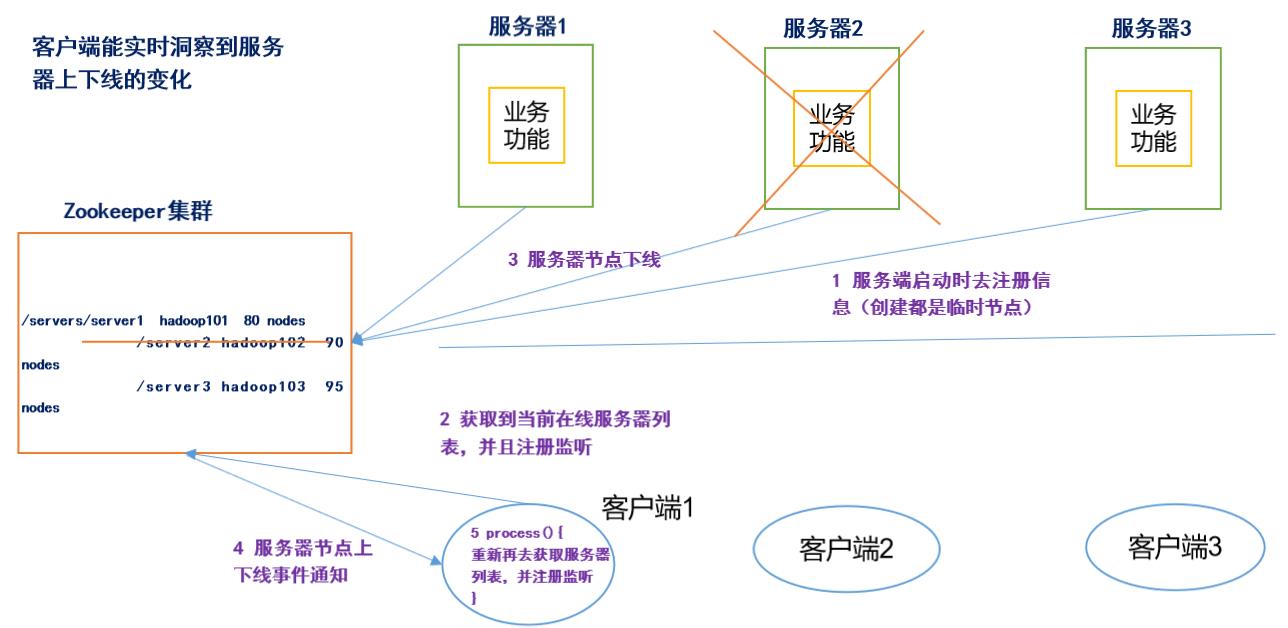
需求:某分布式系统中,主节点可以有多台,可以动态上下线,任意一台客户端都能实时感知到主节点服务器的上下线
编码步骤:
- 首先,既然是监听,我们就需要建立一个客户端和一个服务器,并且服务器在zookeeper上建立临时节点,这样,当服务器下线,zookeeper就可以通知客户端,客户端就可以知道服务器下载了
- 我们在IDEA上建立一个服务器ZKServer和客户端ZKClient,ZKClient模拟zookeeper的客户端,循环监听节点状态
- ZKServer模拟注册临时节点的服务器,为了更加逼真,我们向Main方法传参的方式,模拟出三台服务器
代码如下
- ZKClient
package com.company.zookeeperlisten;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import java.io.IOException;
import java.util.List;
/*
客户端要做的事情:
1. 创建zookeeper对象
2.监听父节点
注意:是否允许先启动客户端.(允许---也需要判断父节点是否存在)
*/
public class ZKClient {
private static ZooKeeper zk;
public static void main(String[] args) throws IOException {
try {
//1.创建连接对象
String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";
/*
ZooKeeper(String connectString, int sessionTimeout, Watcher watcher)
connectString : zk节点的地址
sessionTimeout : 会话超时时间
watcher :监听器对象(当我们监听的节点或数据发生改变,zk就会调用该对象中的process方法
所以可以在process方法中去实现监听事件发生后的业务逻辑代码)
注意:该监听器对象是对所有事件进行监听(咱们一般不用)。
*/
zk = new ZooKeeper(connectString, 4000, new Watcher() {
public void process(WatchedEvent event) {
}
});
//2.获取子节点并监听节点
listener();
Thread.sleep(Long.MAX_VALUE);
}catch (Exception e){
e.printStackTrace();
}finally {
//关闭资源
if (zk != null){
try {
zk.close();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
// 循环监听子节点
public static void listen(){
List<String> children = null;
try {
// 判断父节点是否存在
Stat exists = zooKeeper.exists("/parent",false);
if (exists == null){
// 如果不存在就添加
zooKeeper.create("/parent","fu".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);
}
//获取子节点并监听,并返回所有的子节点
children = zooKeeper.getChildren("/parent", watchedEvent -> {
System.out.println("========="+"parent节点发生了变化"+"========");
listen();
});
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
if (children != null){
// 循环打印出所有的子节点
for (String child : children) {
System.out.println(child);
}
}
}
}
- ZKServer
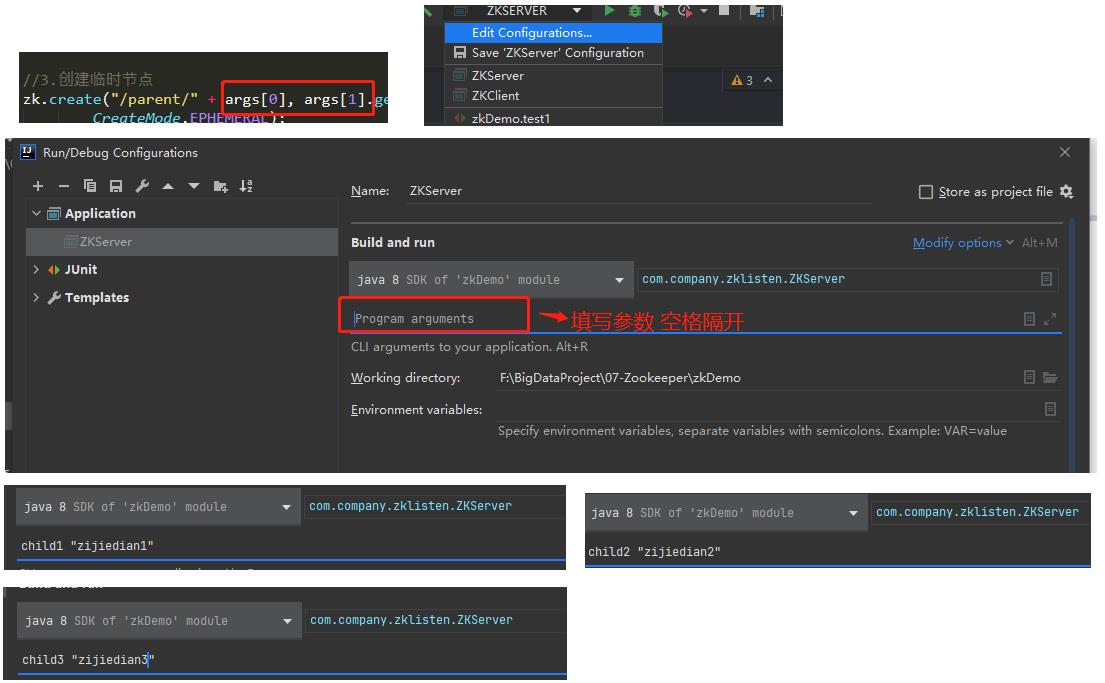
package com.company.zookeeperlisten; import org.apache.zookeeper.*; import org.apache.zookeeper.data.Stat; import java.io.IOException; /* 服务器要做的事情: 1.创建zookeeper对象 2.创建临时节点 注意 : ①判断父节点是否存在-不在需要创建 */ public class ZKServer { public static void main(String[] args){ ZooKeeper zk = null; try { //1.创建连接对象 String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181"; /* ZooKeeper(String connectString, int sessionTimeout, Watcher watcher) connectString : zk节点的地址 sessionTimeout : 会话超时时间 watcher :监听器对象(当我们监听的节点或数据发生改变,zk就会调用该对象中的process方法 所以可以在process方法中去实现监听事件发生后的业务逻辑代码) 注意:该监听器对象是对所有事件进行监听(咱们一般不用)。 */ zk = new ZooKeeper(connectString, 4000, new Watcher() { public void process(WatchedEvent event) { } }); //2.判断父节点是否存在-不在需要创建 Stat exists = zk.exists("/parent", false); if (exists == null) {//不存在 zk.create("/parent", "aa".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); } //3.创建临时节点 zk.create("/parent/" + args[0], args[1].getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL); Thread.sleep(Long.MAX_VALUE); }catch (Exception e){ e.printStackTrace(); }finally { //要关资源 if (zk != null){ try { zk.close(); } catch (InterruptedException e) { e.printStackTrace(); } } } } }
IDEA传参方式
- 服务器指定传参
总结
本章节介绍了如何简单的通过命令行(shell)和代码操作zookeeper,操作方法和JDBC、HDFS相同,只是API不一样…大家根据这篇博客的案例即可轻松掌握如何使用zookeeper,当然了,zookeeper深挖了也有很多的东西,不过我们只需要知道大概,因为学习它是为了我们下一步Hadoop的HA做准备的,好了,下一章,我为大家带来zookeeper的内部原理
以上是关于打怪升级之小白的大数据之旅(五十五)<Zookeeper命令行与API应用>的主要内容,如果未能解决你的问题,请参考以下文章
打怪升级之小白的大数据之旅(五十六)<Zookeeper内部原理>
打怪升级之小白的大数据之旅(五十)<MapReduce框架原理二:shuffle>
打怪升级之小白的大数据之旅(五十九)<Hadoop优化方案>