打怪升级之小白的大数据之旅(五十四)<Zookeeper概述与部署>
Posted GaryLea
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了打怪升级之小白的大数据之旅(五十四)<Zookeeper概述与部署>相关的知识,希望对你有一定的参考价值。
打怪升级之小白的大数据之旅(五十四)
Zookeeper概述与部署
上次回顾
- 上一章,我们学习了Hadoop的最后一个模块–Yarn,然后我对整个Hadoop进行了总结,如果大家对我串讲的知识点有更好的理解,欢迎私信我哈
- 本章节开始学习zookeeper,zookeeper我会分为三个部分
- 第一部分是基本概述和环境配置
- 第二部分是具体的使用,它和HDFS一样;通过命令行和代码两种方式
- 第三部分是内部原理的分享,老样子,知道了底层的原理可以更好分辅助我们了解这个框架
Zookeeper概述
初识zookeeper
介绍Zookeeper前,还是看下面这个图
在大数据开篇介绍Hadoop的时候放过这张图,此时我们再次通过它来说明zookeeper
- hadoop是一只大象,hive是一只秘方,bigtop是马戏团,pig是一只猪,hama是一只河马…只有zookeeper是一个拿着铁锹的人
- 我们可以将zookeeper理解为动物园的管理员…它负责管理动物园中的动物,如果某个动物出现了问题,它就会第一时间知道并进行处理
此时再用官方的解释来说,zookeeper是一个开源的分布式的、为分布式应用提供服务的Apache项目
好了,这就是zookeeper,是不是很好理解
zookeeper工作机制
- 它既然是一个管理员,那么它就需要知道自己管辖范围内的各种情况,如果有问题就及时处理
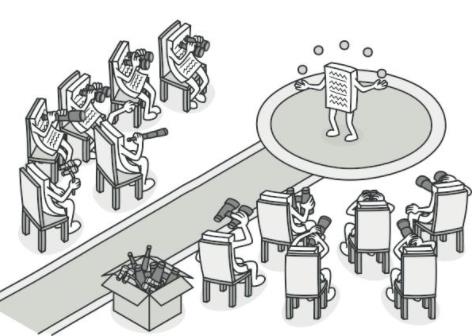
- 我们从设计模式的角度来理解:zookeeper是一个基于观察者模式设计的分布式服务管理框架
- 它负责存储和管理大家都关心的数据,然后接收观察者的注册、一旦这些数据发送了变化,zookeeper就将负责通知已经在zookeeper上注册的那些观察者做出相应的反应
- 举个栗子:
- 舞台上有一个杂技演员,它就是被观察者,台下坐的都是观察者
- 如果该演员出现了失误,那么所有的观察者都会知道这个演员失误了
zookeeper特点
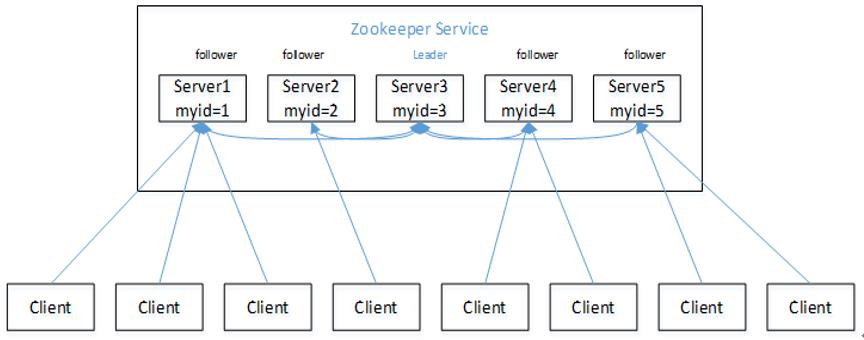
- zookeeper由一个领导者(Leader)和多个跟随者(follwer)组成(这个在原理的时候为大家具体介绍)
- 集群中只要有半数以上节点存活,zookeeper集群就能正常服务
- 全局数据一致;每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的
- 就像我们连接王者荣耀时,不论在哪里,我们创建的账号数据都是不会变的,因为它有很多台数据一致的服务器,放置在不同的区域中,这样可以加快我们的连接效率,提高我们的用户体验
- 更新请求顺序进行,来自同一个Client的更新请求按其发送顺序执行
- 数据更新原子性,一次数据更新要么都成功,要么都失败
- 这个原理就跟mysql中学习事务一样,主要是为了保证数据的完整性
- 实时性,在一定时间范围内,Client可以读取到最新的数据
- 下面这个图等我们介绍选举的时候会再次讲到,就提前让大家看一下zookeeper集群的大概构成
zookeeper的数据结构
-
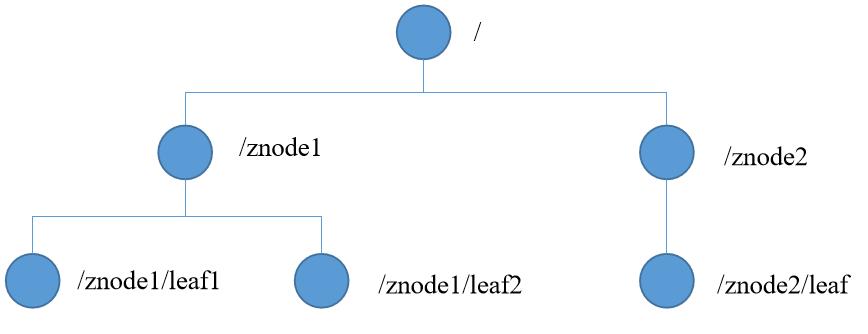
zookeeper的数据模型结构与我们学习的Unix文件系统类似,只不过它是由节点组成,Unix是由文件组成
-
zookeeper的每一个节点称作ZNode,每个节点可以存储1M的数据,看起来它很小,其实很大了,因为它只会存储关键的数据,通常情况下,每个节点ZNode中只存储的xxkb的数据
-
每个ZNode都可以通过路径做唯一的标识
应用场景
了解了zookeeper的基本概述、特点,接下来就来介绍zookeeper的几个应用场景
统一命名服务
- 以我们经常使用的百度举栗子:
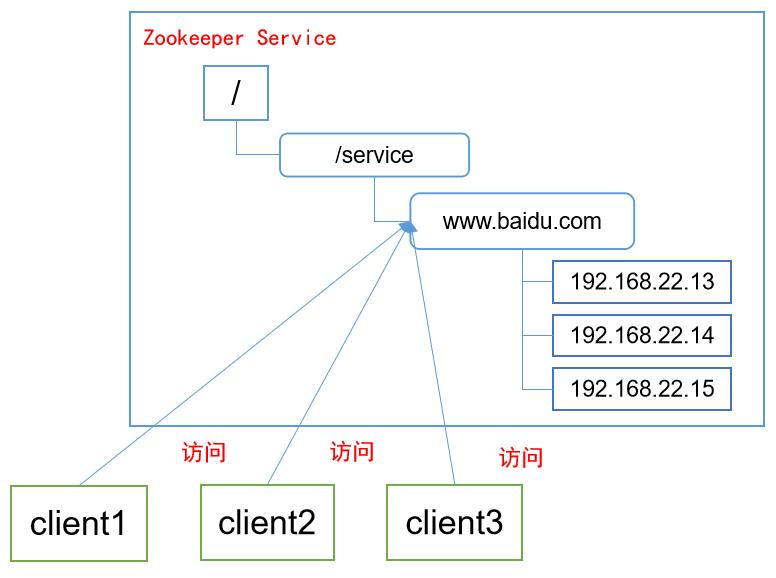
- 我们登录百度的时候并不是通过一台服务器进行登录的,它内部会有多台服务器,而我们只需要知道百度网址,它内部就可以根据实际来选择对应的服务器
统一配置管理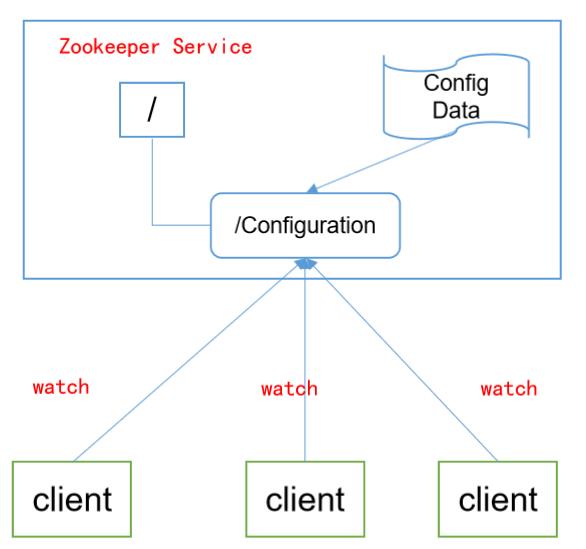
- 在我们对Hadoop集群的配置文件进行修改后,就需要进行这个操作,使用我们自定义的脚本
xsync来对配置文件进行分发 - 配置管理交由zookeeper实现
- 将配置信息写入到zookeeper上的一个ZNode节点中
- 各个客户端服务器监听这个ZNode节点
- 一旦ZNode节点中的配置信息进行了修改,zookeeper就会通知到各个客户端服务器中
统一集群管理
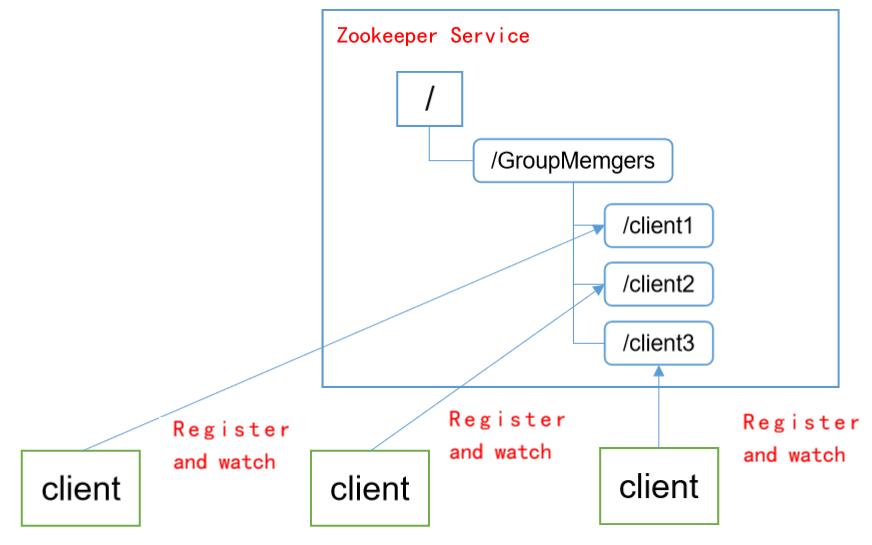
- 在分布式中,我们需要监控每一个节点中的状态,比如在Hadoop中,NameNode与DataNode中的心跳机制就是一种实现方法
- zookeeper可以实现实时监控节点的状态变化
- 将各个节点信息写入zookeeper上的一个ZNode节点中
- 监听这个ZNode节点就可获取它的实时状态变化
服务器动态上下线
以下面这个栗子来说明
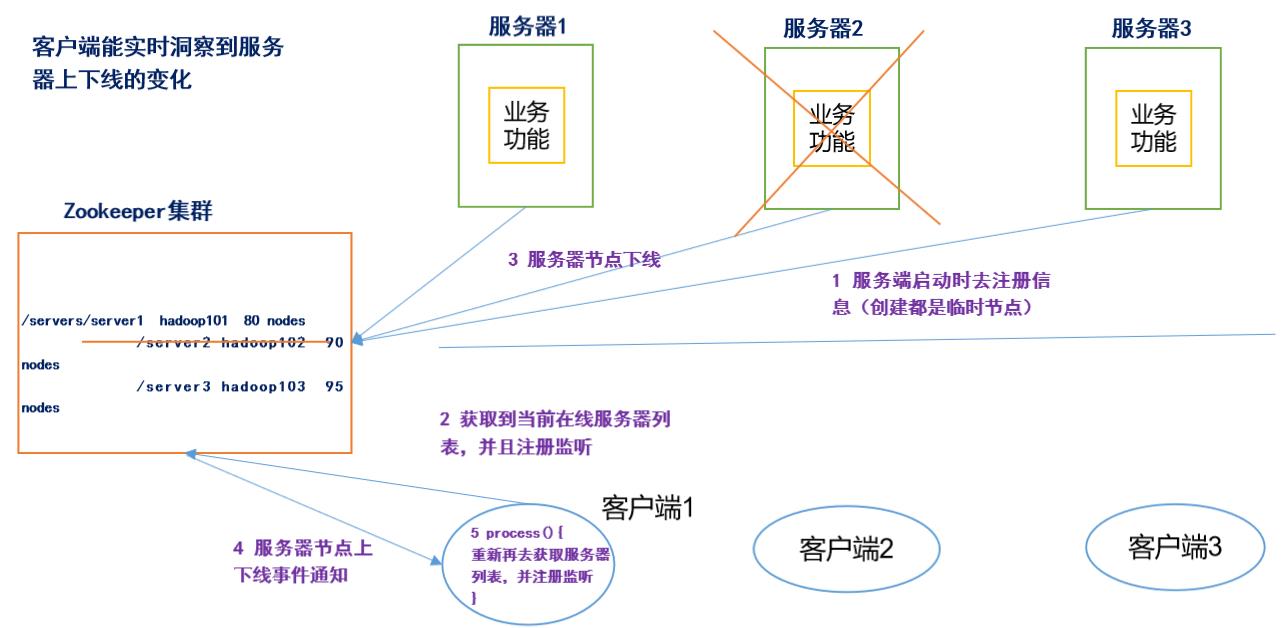
我们假设这个是某个聊天器的架构图
- 假设它有三台服务器1,2,3理解为我们的好友
- 每台服务器都在zookeeper上进行注册(注册的是临时节点)
- 我们客户端可以通过它查看对应的好友是否在线
- 如果其中一个好友服务器2下线了,我们就可以通过zookeeper知道,它下线了
- 这个案例我在后面会通过代码的形式为大家说明,大家先提前了解一下
软负载均衡
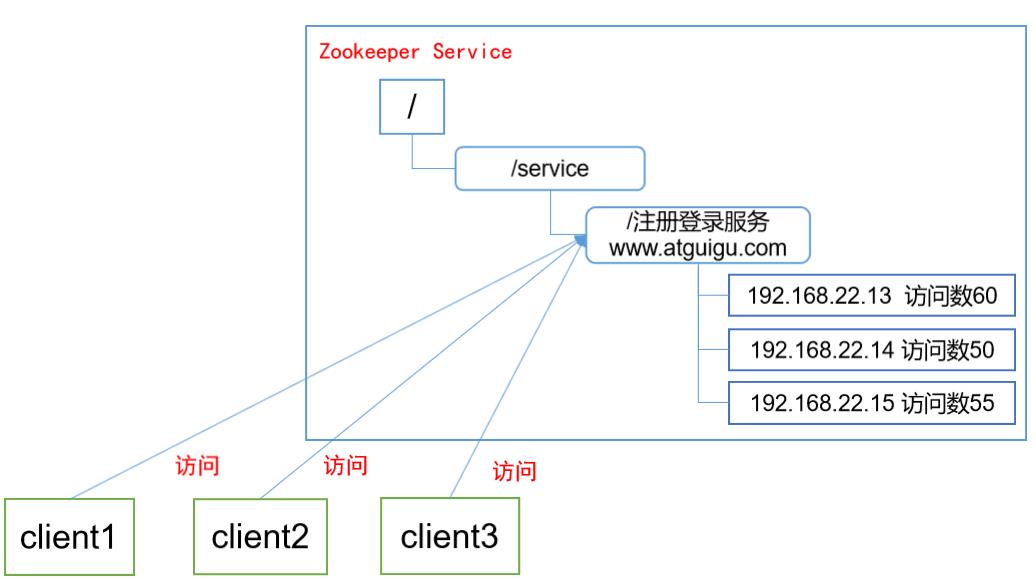
以登录尚硅谷的官网举栗子
- 尚硅谷的官网也有多个服务器来进行客户端的访问
- 当某一个服务器访问过大而其他服务器闲置时,此时就需要负载均衡技术,分担承受压力服务器
- 在zookeeper中会记录每台服务器的访问数、放访问数最少的服务器去处理最新的客户端请求
Zookeeper环境搭建
zookeeper下载地址:https://zookeeper.apache.org/
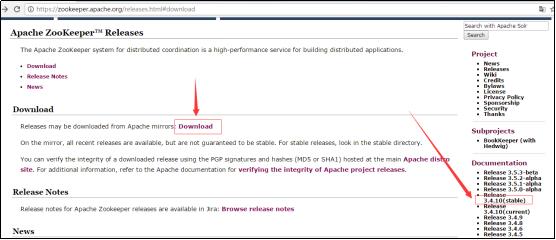
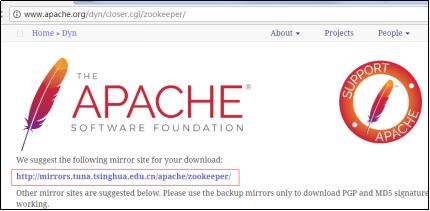
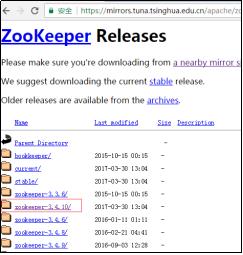
本地模式部署
第一步:安装前准备:
- 安装JDK
- 这个在我们搭建Hadoop的时候说过,下载Javalinux版本的jdk,然后直接解压即可
- 安装zookeeper
- 将我们下载好的zookeeper拖进我们的服务器中
- 拷贝Zookeeper安装包到Linux系统下
- 我们还是安装到/opt/moudle文件夹下
tar -zxvf zookeeper-3.5.7.tar.gz -C /opt/module/
第二步:配置环境变量(记得source一下)
- 还是在我们那个环境变量的文件中进行添加即可
# 打开环境变量的配置文件 vim /etc/profile.d/my_env.sh # 配置zookeeper环境变量 #JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_212 # Hadoop_home export HADOOP_HOME=/opt/module/hadoop-3.1.3 # zookeeper export ZOOKEPEER_HOME=/opt/module/zookeeper-3.5.7 export PATH=$PATH:$JAVA_HOME/bin export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin export PATH=$PATH:$ZOOKEPEER_HOME/bin
第三步:配置修改
- 将zookeeper根目录下conf文件中zoo_sample.cfg修改成zoo.cfg
- 在zoo.cfg中修改datadir
# 需要修改为下面的内容 dataDir=/opt/module/zookeeper-3.5.7/zkData
第三步:在zookeeper根目中创建zkData(因为datadir指向它)
mkdir /opt/module/zookeeper-3.5.7/zkData
第四步:测试zookeeper是否成功安装
# 启动zookeeper服务 :
zkServer.sh start|stop|status|restart
第五步:启动zookeeper客户端
# 启动zookeeper客户端
zkCli.sh
# 使用quit退出客户端
quit
注意: 本地模式完成后,记得将zookeeper分发到我们的服务器中
xsync /opt/module/zookeeper-3.5.7 /opt/module/zookeeper-3.5.7
配置参数解读
Zookeeper中的配置文件zoo.cfg中参数含义解读如下:
tickTime =2000:通信心跳数,Zookeeper服务器与客户端心跳时间,单位毫秒- Zookeeper使用的基本时间,服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime时间就会发送一个心跳,时间单位为毫秒。
- 它用于心跳机制,并且设置最小的session超时时间为两倍心跳时间。(session的最小超时时间是2*tickTime)
initLimit =10:LF初始通信时限- 集群中的Follower跟随者服务器与Leader领导者服务器之间初始连接时能容忍的最多心跳数(tickTime的数量),
- 用它来限定集群中的Zookeeper服务器连接到Leader的时限。
syncLimit =5:LF同步通信时限- 集群中Leader与Follower之间的最大响应时间单位,
- 假如响应超过syncLimit * tickTime,Leader认为Follwer死掉,从服务器列表中删除Follwer。
dataDir:数据文件目录+数据持久化路径- 主要用于保存Zookeeper中的数据。
clientPort=2181:客户端连接端口- 监听客户端连接的端口
集群模式部署
集群模式部署前的准备
- 首先,集群模式要在前面本地模式没有问题并且三个节点都成功的情况下进行
- 然后我们需要先把先把zookeeper服务停掉
- logs和zkData中的数据全部删除
集群模式的部署步骤
第一步:创建myid文件
- 在zkData中创建myid文件。并在文件中写一个数值,类似我们Hadoop集群时的hostname,至于myid干嘛的,后面原理中会讲
- 该值代表zookeeper节点Id
- 注意:该值在整个集群中是唯一的
# 创建myid文件 vim /opt/module/zookeeper-3.5.7/zkData/myid # 编写内容 # hadoop102服务器中是 2 # hadoop103服务器中是 3 # hadoop104服务器中是 4
第二步:修改配置文件zoo.cfg
- 在zoo.cfg文件中添加如下内容,server.后面的数字就是我们的myid
server.2=hadoop102:2888:3888 server.3=hadoop103:2888:3888 server.4=hadoop104:2888:3888 - 说明:
- 2指的是myid的值,hadoop102指的是myid为2的机器是哪台。
- 2888是zk通信的端口。3888是leader选举端口。
第三步:将修改的内容进行分发
xsync /opt/module/zookeeper-3.5.7/
第四步:hadoop103和hadoop104的myid值
- 一定一定记得修改,并且myid值与cfg中的值一样,并且服务器也是一 一对应
第五步:启动各节点的zookeeper服务:
zkServer.sh start
编写一键启动脚本
- 就和Hadoop集群一样,我们同样编写一个一键启动脚本,来管理我们的zookeeper集群
- 在zookeeper的bin目录下编写,因为zookeeper添加了环境变量,所以在任何地方都可以运行我们的命令
# 创建一键启动脚本 vim /opt/module/zookeeper-3.5.7/bin/myzkCluster # 编写一键启动内容 #!/bin/bash if [ $# -ne 1 ] then echo "error args,please input one args in here" exit fi zkbash="" case $1 in "start") zkbash="start" ;; "stop") zkbash="stop" ;; "status") zkbash="status" ;; "restart") zkbash="restart" ;; *) echo "error args,please input start/stop/status/restart" exit ;; esac for host in hadoop102 hadoop103 hadoop104 do echo "===============$host===============" ssh $host /opt/module/zookeeper-3.5.7/bin/zkServer.sh $zkbash done
总结
本章节介绍了zookeeper的基本概述以及环境的搭建,都比较简单,步骤就和HDFS一样,先本机、再集群、先命令行操作、再代码操作…好了,今天内容就是这些,蟹蟹大家观看
以上是关于打怪升级之小白的大数据之旅(五十四)<Zookeeper概述与部署>的主要内容,如果未能解决你的问题,请参考以下文章
打怪升级之小白的大数据之旅(五十六)<Zookeeper内部原理>
打怪升级之小白的大数据之旅(五十)<MapReduce框架原理二:shuffle>
打怪升级之小白的大数据之旅(五十九)<Hadoop优化方案>