打怪升级之小白的大数据之旅(五十三)<Hadoop最后一个模块--Yarn>
Posted GaryLea
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了打怪升级之小白的大数据之旅(五十三)<Hadoop最后一个模块--Yarn>相关的知识,希望对你有一定的参考价值。
打怪升级之小白的大数据之旅(五十三)
Hadoop最后一个模块–Yarn
上次回顾
上一章,我们学完了整个MapReduce的知识点,至此,Hadoop的三大模块就剩下最后一个模块–Yarn了
Yarn
Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,MapReduce等运算程序相当于运行于操作系统之上的应用程序
Yarn就类似我们的Windows系统,我们的MapReduce就像我们的软件,它是运行在Yarn上的,了解清楚这个之后,我们再回想一下Hadoop集群搭建时,我们专门指定了一个服务器hadoop103运行Yarn,然后我们指定完全分布模式的时候,将MapReduce运行在Yarn的原因了吧?
Yarn基本架构
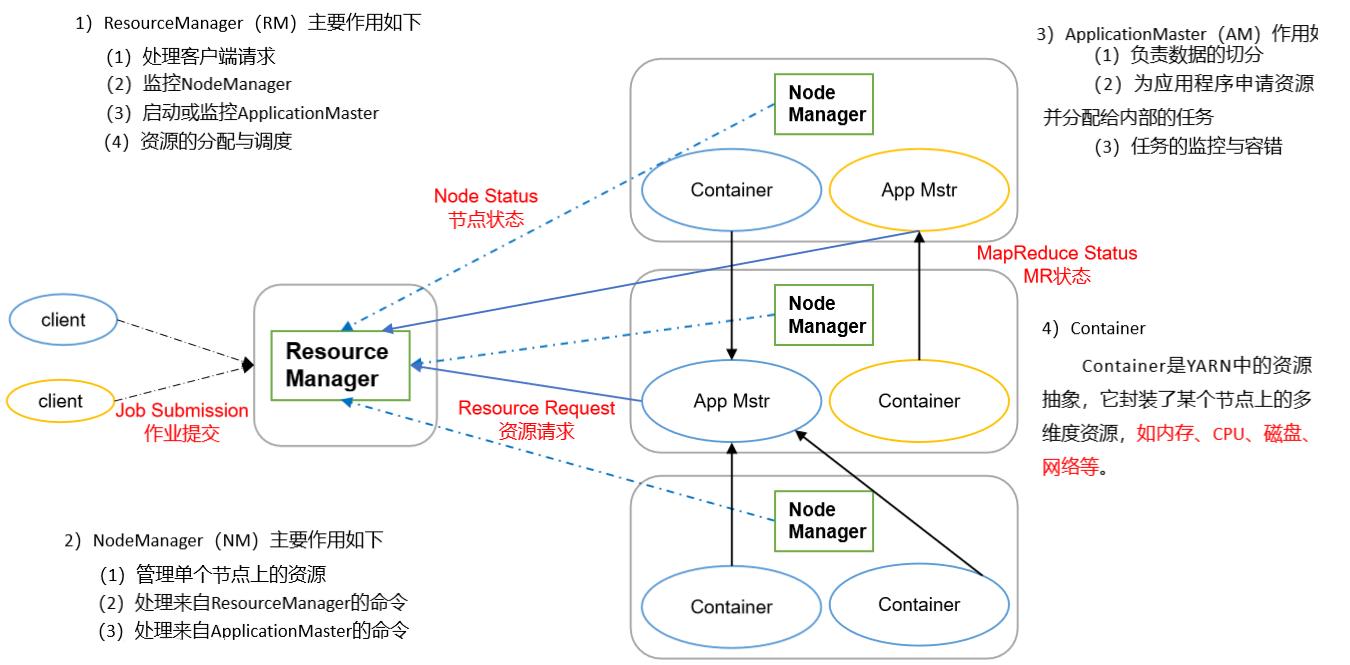
Yarn主要有ResourceManager、NodeManager、ApplicationMaster和Container等组件构成
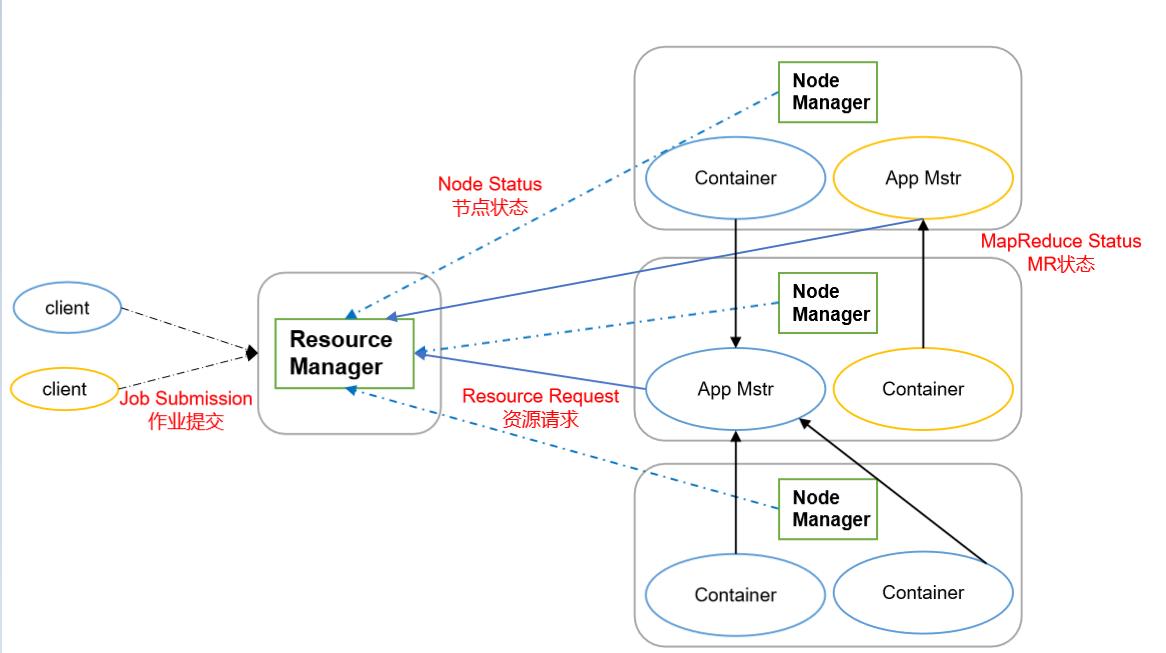
ResourceManager
- 处理客户端请求
- 监控NodeManager
- 启动或监控ApplicationMaster
- 资源的调度与分配
NodeManager
- 管理单个节点上的资源
- 处理来自ResourceManager的命令
- 处理来自ApplicationMaster的命令
ApplicationMaster
- 负责数据的切分(当MR中的InputFormat进行切片操作后,由ApplicationMaster告诉MapTask/ReduceTask具体的数据是哪一段)
- 为应用程序申请资源并分配给内部的任务
- 任务的监控与容错
Container
- 它就相当于一个存放资源的容器,用于运行具体的job任务
- 资源中包含了内存、CPU、磁盘、网络等
在资源管理的角度来看:
- 当我们集群启动的时候,ResourceManager与NodeManager就会启动
- NodeManager用于管理单个节点上的资源
- ResourceManager用于管理所有的NodeManager
在任务管理的角度来看
- 当客户端提交job的时候,客户端会通过ResourceManager进行job的提交,ResourceManager就会启动ApplicationMaster,ApplicationMaster是任务的老大,每一个job就会启动一个ApplicationMaster
- ApplicationMaster拿到任务后,就会向ResourceManager申请job所需的资源
- ResourceManager会将资源放到container容器中,ApplicationMaster就会将任务在container中运行MapTask或ReduceTask
Yarn工作机制
介绍完Yarn的架构,下面我们来了解一下它的工作机制
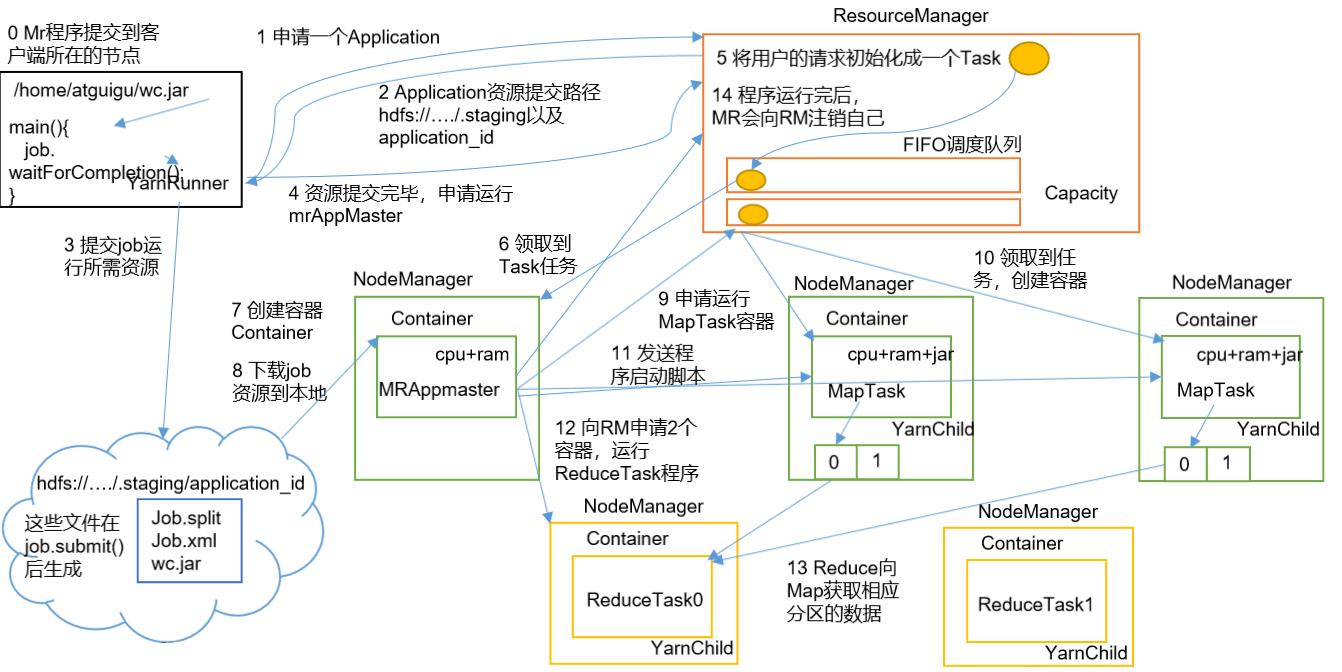
-
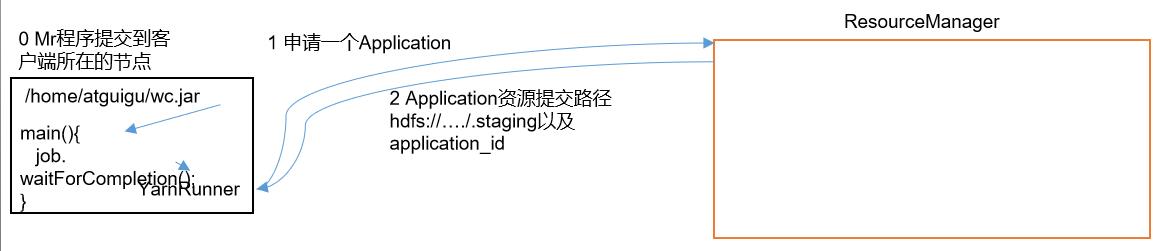
在我们的客户端中编写的MR程序,在Driver主方法进行提交后,这个程序会创建一个YarnRunner对象,通过它,向ResourceManager申请一个(Application Master,用于提交、执行job
-
ResourceManager会给YarnRunner对象一个Application Master的资源提交路径,因为是YarnRunner,所以该路径是在HDFS上
-
根据提交的路径,会将job所需的资源:程序本体(jar包)、配置文件(job.xml)、切片信息(job.split)存储到HDFS中
-
当资源提交完毕后,客户端会再次向ResourceManager申请,请求运行AppMaster(Application Master),用于提交job
-
因为客户端不止一个,需要运行的job也不止一个,所以ResourceManager会先将用户的请求初始化成一个Task,存储在调度队列中(调度队列下面会详细介绍)
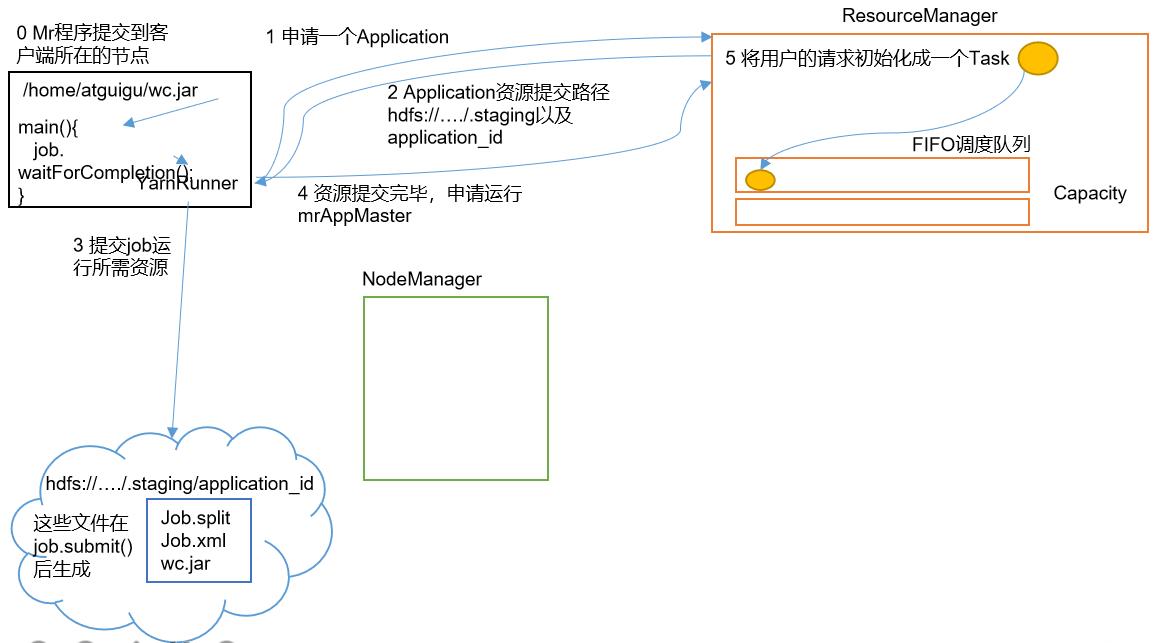
-
NodeManager根据调度队列来领取Task任务,它会创建一个Container容器,用来执行Task任务
-
我们的APPMaster也是运行在Container中的,APPMaster启动时,会将HDFS中上传的job资源下载到本地磁盘中,然后根据job资源包中的切片信息,生成对应数量的MapTask容器
-
接着APPMaster会向ResourceManager申请运行MapTask
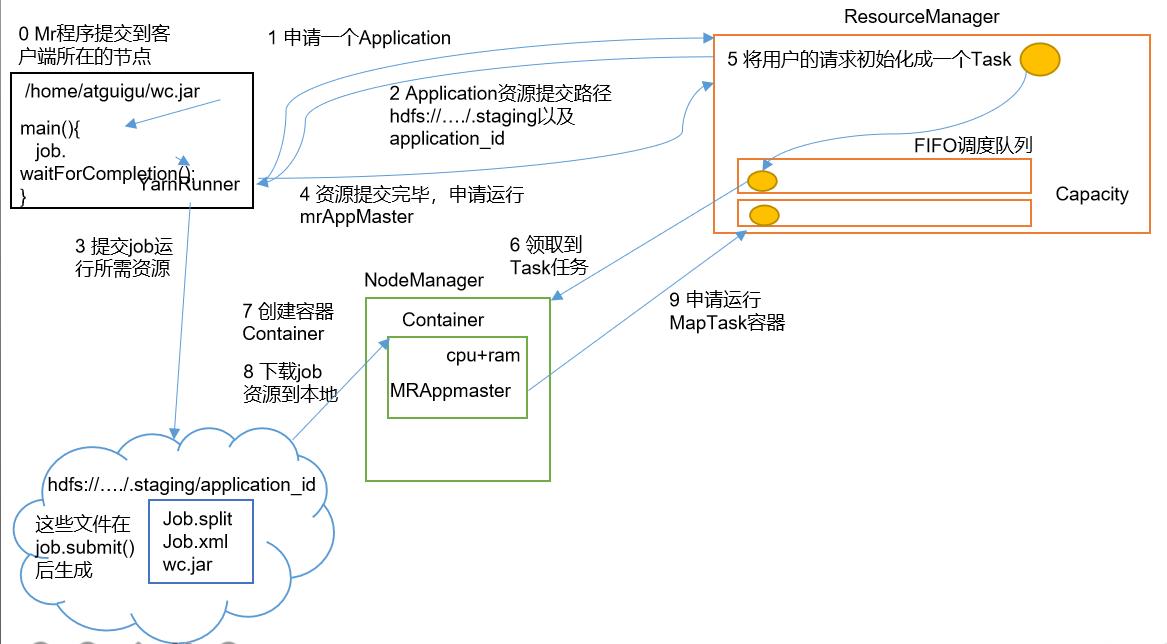
-
NodeManager会接收ResourceManager的指令,继续生成用于运行MapTask的Container
-
因为 APPMaster的管理任务的老大,所以APPMaster就可以根据自己提交的job资源向各个MapTask发送程序启动的脚本命令,此时无论是MapTask还是ReduceTask,也被称之为YarnChild
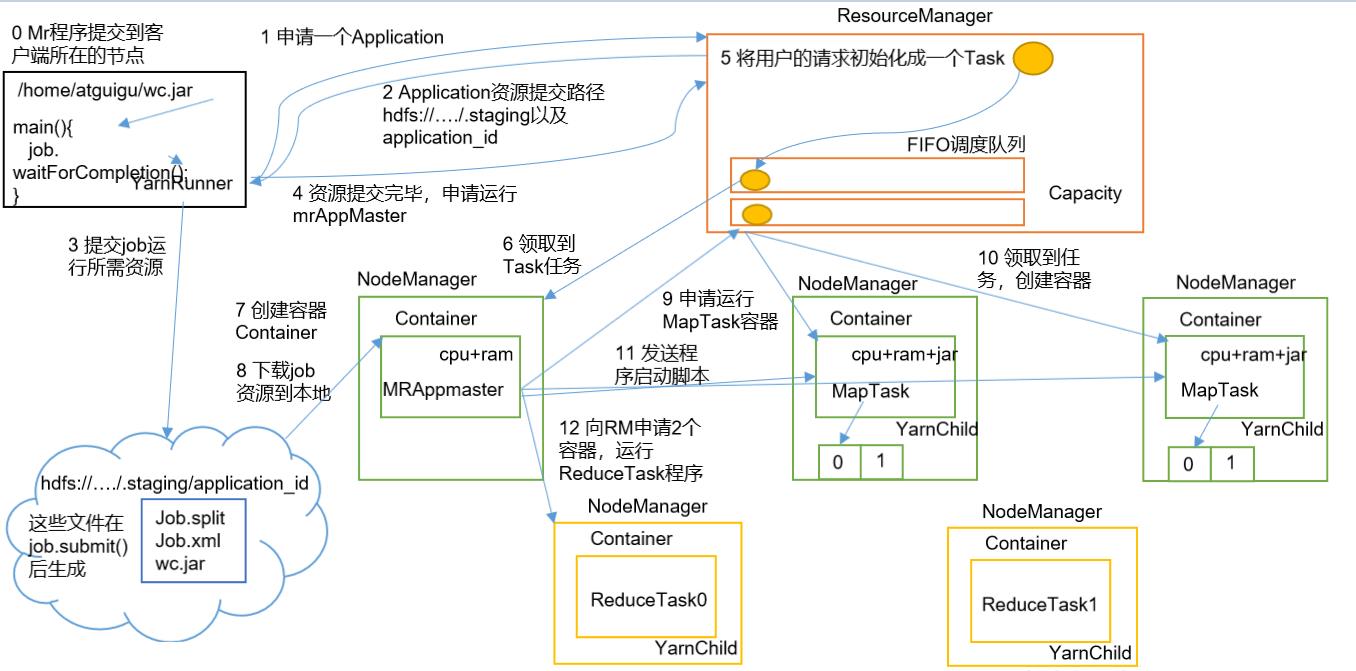
-
当MapTask运行完成,AppMaser就会再次向ResourceManager申请两个容器,用于运行ReduceTask程序
-
ReduceTask会拷贝MapTask写出的数据
-
当最后程序完成后,MapReduce就会向ResourceManager注销自己
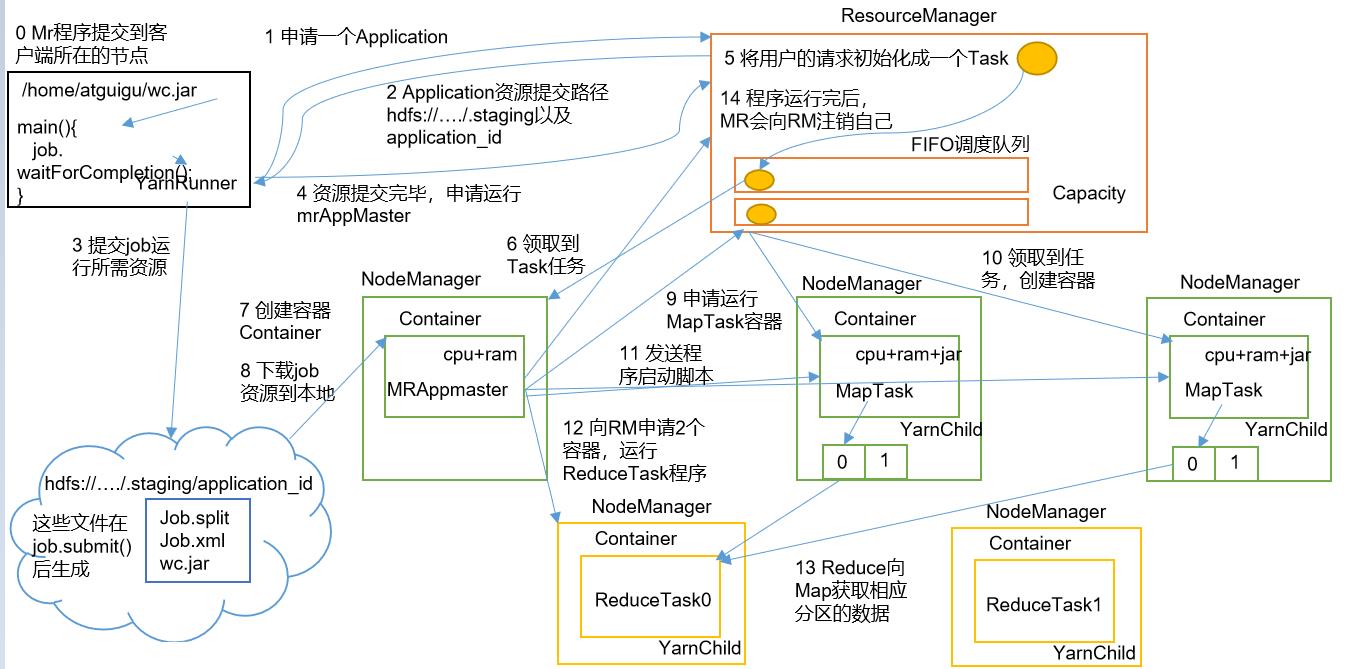
资源调度器
下面就来介绍一下Yarn工作流程中的资源调度器
- 目前,Hadoop作业调度器主要有三种:FIFO、Capacity Scheduler和Fair Scheduler。Hadoop3.1.3默认的资源调度器是Capacity Scheduler
- FIFO是Hadoop最初版本的资源调度器,它被称为先进先出调度器
- Capacity Scheduler是默认的资源调度器,它是多个FIFO的组合,它被称为容量调度器
- air Scheduler是在别的框架中使用的资源调度器,它被称为公平调度器
FIFO(先进先出调度器)
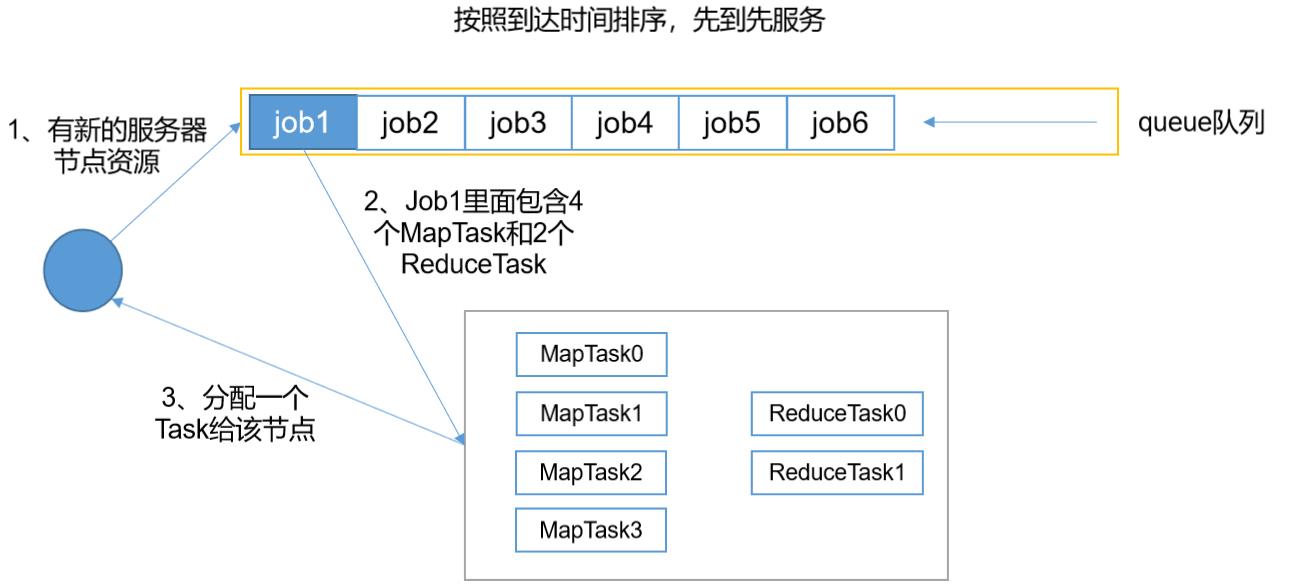
- FIFO调度器,使用的是queue队列,它按照任务的时间进行排序,先到达的任务,先执行
- 它是一个串行的调度器,当一个job完成后,才会执行下一个job,假设当我们执行第一个job时,占用了20%的资源,剩余80%的资源就会处于闲置状态
Capacity Scheduler(容量调度器)
- 为了解决FIFO上面存在的问题,Hadoop对FIFO调度器进行了优化,于是Capacity Scheduler容量调度器诞生了
- Capacity Scheduler由多个FIFO组成,这样就可以解决FIFO的第一个缺陷,串行问题,它可以并发完成多个job任务

每个FIFO中的执行顺序问题
- 首先计算每个队列中(FIFO)正在运行的任务数与其应该分得的计算资源之间的比值,然后选择一个比值最小的队列,也就说最闲的队列
- 接着按照作业的优先级和提交时间顺序,同时考虑用户资源量限制和内存限制对队列内的任务进行排序
- 三个队列同时按照任务的先后顺序依次执行,这样就可以实现并发执行了
Capacity Scheduler资源分配问题
-
既然是并发执行,就出现了一个问题,资源是有限的,并发执行的资源分配问题怎么解决呢?
-
Capacity Scheduler为了防止同一个用户的作业,独占队列中的资源,它会对同一用户提交的job所占的资源进行限制
-
假设我们有3个job,job1和job3各有20%与30%处于闲置状态,而job3的资源不够用,在Capacity Scheduler中有一个机制,借资源
- 当某个job的资源不够用的时候,其他job中如果有闲置资源,就可以将闲置资源临时分配到该job中,使其可以正常运行
- 为了确保借资源时自己的队列中依旧可以正常完成新的Job任务,它内部会预留出一个最小资源,用于执行新的Job任务
Fair Scheduler(公平调度器)
- Fair Scheduler的组成与 Capacity Scheduler类似
- 它最大的特点是,所有job,所有的FIFO队列全部同时执行,因此,使用Fair Scheduler时,我们会发现,我们的资源利用率使用是满的

Fair Scheduler资源分配问题
- 每一个job所需的资源不同,所以并不可能简单的将每一个队列平均分配给每个job
- Fair Scheduler分配资源时使用最大最小公平算法来为队列中的每个job分配所需的资源(下面会单独来讲)
-
- 同样为了解决新的Job进来资源不够用,每个队列中会预留出一部分资源用于运行新的Job
- 当其中一个job中的资源被释放掉时,就会将释放的资源分配到其他不够用的job中,这样,就可以确保资源可以得到充分的利用

- 某一个时刻,某个job赢所需的资源与分配得到的资源差距就是缺额
- 公平调度器设计目标是:在时间的尺度上,所有的作业获得公平的资源
- 调度器会优先为缺额大的job分配资源
最大最小公平算法
- 最大最小公平算法分为加权算法和不加权算法
- 顾名思义,加权就是为某个job分配优先级
- 下面我对两种算法的原理进行案例演示,以一个队列中4个job举例
加权算法原理
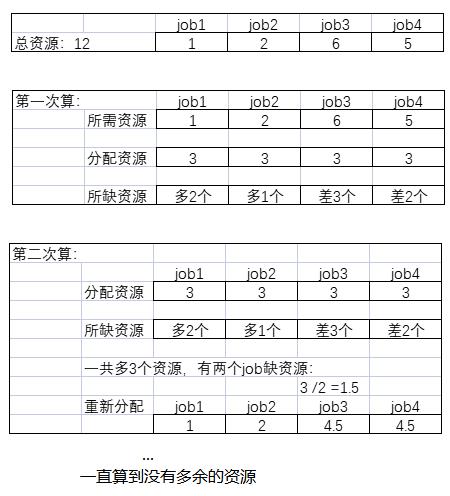
- 这个队列中,总共资源数为12%,我有4个需要执行的job
- 图中可以很明显的看到,4个job的总资源超过了队列资源
- 第一次运算的时候:每个job资源=总资源/4
- 获取每个job的缺额
- 第二次运算:根据缺额来重新分配资源,每个缺额的job获取资源=多出的资源数/缺额的job数
- 如果仍旧有剩余资源,继续重新分配资源,进行运算,知道没有多余资源可以分配为止
- 当计算完毕,此时job3和job4仍旧缺少资源也没办法,Fair Scheduler会等待前面的job释放资源后再为缺额的job分配资源,知道所有的job都不缺资源为止
不加权算法原理
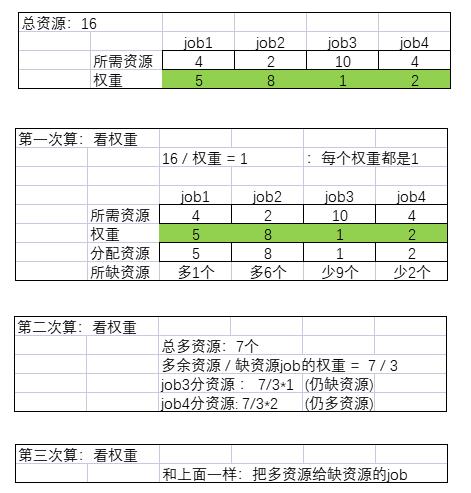
- 这个队列中,总共资源数为16%,我有4个需要执行的job
- 每个队列中的job会先根据总资源进行权重的分配,每一个权重代表一个资源
- 第一次算:首先按照权重进行资源分配,然后获取每个job多的资源和缺额
- 第二算:根据总共多出的资源数/所缺资源的权重总和来进行分配
- 每个所缺资源job所获得的资源=多出资源数/所缺资源数 * 当前job的权重
- 第三次算:如果仍旧有多的资源,重复第二次过程,继续运算,知道没有资源可供分配为止
容量调度器多队列提交案例
- 了解了调度器的知识后,下面我们进行实例演示,Yarn默认的容量调度器是一条单队列的调度器,在实际使用中会出现单个任务阻塞整个队列的情况。同时,随着业务的增长,公司需要分业务限制集群使用率。这就需要我们按照业务种类配置多条任务队列
- 默认Yarn的配置下,容量调度器只有一条Default队列。在capacity-scheduler.xml中可以配置多条队列,并降低default队列资源占比
- yarn的队列配置是在
capacity-scheduler.xml文件中,具体配置如下<!-- 下面这两个是修改的部分 --> <property> <name>yarn.scheduler.capacity.root.queues</name> <value>default,hive</value> <description> The queues at the this level (root is the root queue). </description> </property> <property> <name>yarn.scheduler.capacity.root.default.capacity</name> <value>40</value> </property> <!-- 同时为新加队列添加必要属性:--> <property> <name>yarn.scheduler.capacity.root.hive.capacity</name> <value>60</value> </property> <property> <name>yarn.scheduler.capacity.root.hive.user-limit-factor</name> <value>1</value> </property> <property> <name>yarn.scheduler.capacity.root.hive.maximum-capacity</name> <value>80</value> </property> <property> <name>yarn.scheduler.capacity.root.hive.state</name> <value>RUNNING</value> </property> <property> <name>yarn.scheduler.capacity.root.hive.acl_submit_applications</name> <value>*</value> </property> <property> <name>yarn.scheduler.capacity.root.hive.acl_administer_queue</name> <value>*</value> </property> <property> <name>yarn.scheduler.capacity.root.hive.acl_application_max_priority</name> <value>*</value> </property> <property> <name>yarn.scheduler.capacity.root.hive.maximum-application-lifetime</name> <value>-1</value> </property> <property> <name>yarn.scheduler.capacity.root.hive.default-application-lifetime</name> <value>-1</value> </property> - 一定记得修改完配置文件后,进行分发,然后在Yarn所在的节点上,重启一下节点
# 分发配置信息到各个节点中 xsync $HADOOP_HOME/etc/hadoop/./ $HADOOP_HOME/etc/hadoop/./ # 在Yarn所在的节点上,重启Yarn服务 yarn --daemon stop resoucemanager yarn --daemon start resoucemanager
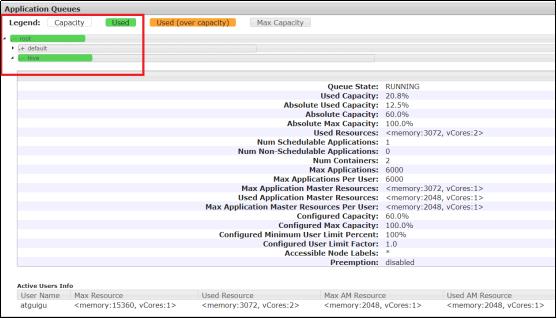
修改好之后,就可以在浏览器中看到:hadoop102:8088
默认的任务提交都是提交到default队列的。如果希望向其他队列提交任务,需要在Driver中声明
//Driver.java文件
Configuration configuration = new Configuration();
configuration.set("mapred.job.queue.name", "hive");
注意一下哈,我们启动了两个job,一个job使用的默认队列,一个job是我们指定的这个队列,下面看一下效果
Hadoop作业提交全过程
Yarn的知识点到这里就结束了,下面我来将整个Hadoop串讲一下,当然了,Hadoop还有一个扩展知识点–HA,等我讲完zookeepeer之后再分享它
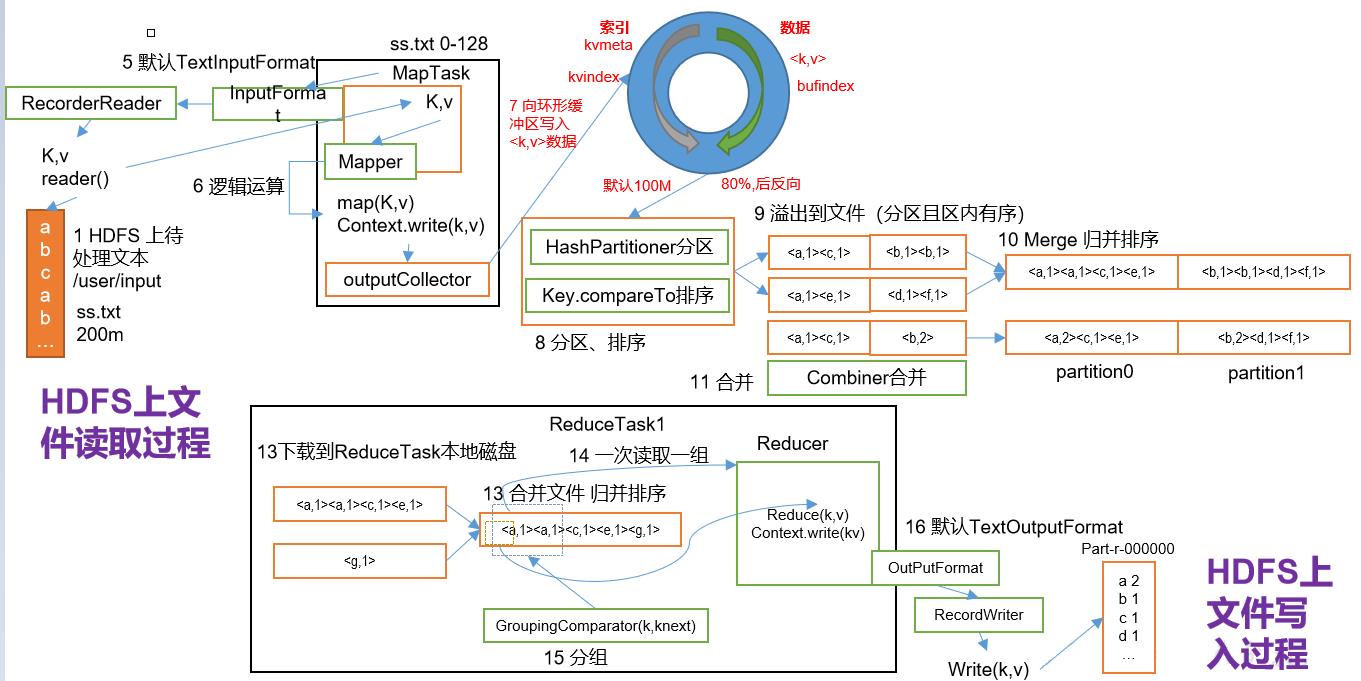
上面这两张图,我们前面已经介绍过,现在将这两张图合并,就是整个Hadoop作业运行全过程
- 作业提交
第1步:Client调用job.waitForCompletion方法,向整个集群提交MapReduce作业。
第2步:Client向RM申请一个作业id。
第3步:RM给Client返回该job资源的提交路径和作业id。
第4步:Client提交jar包、切片信息和配置文件到指定的资源提交路径。
第5步:Client提交完资源后,向RM申请运行MrAppMaster。 - 作业初始化
第6步:当RM收到Client的请求后,将该job添加到容量调度器中。
第7步:某一个空闲的NM领取到该Job。
第8步:该NM创建Container,并产生MRAppmaster。
第9步:下载Client提交的资源到本地。 - 任务分配
第10步:MrAppMaster向RM申请运行多个MapTask任务资源。
第11步:RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器。 - 任务运行
第12步:MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序。
第13步:MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。
第14步:ReduceTask向MapTask获取相应分区的数据。
第15步:程序运行完毕后,MR会向RM申请注销自己。 - 进度和状态更新
YARN中的任务将其进度和状态(包括counter)返回给应用管理器, 客户端每秒(通过mapreduce.client.progressmonitor.pollinterval设置)向应用管理器请求进度更新, 展示给用户。 - 作业完成
除了向应用管理器请求作业进度外, 客户端每5秒都会通过调用waitForCompletion()来检查作业是否完成。时间间隔可以通过mapreduce.client.completion.pollinterval来设置。作业完成之后, 应用管理器和Container会清理工作状态。作业的信息会被作业历史服务器存储以备之后用户核查。
总结
- 到此时,Hadoop框架的内容基本上就介绍完毕了,下面我来对整个Hadoop的内容做一个总结、梳理
Hadoop的组成:
- Hadoop由HDFS、MapReduce和Yarn组成
- HDFS主要用于数据的存储和读取
- MapReduce主要用于对数据的运算、分析
- 我们的程序(job)需要运行在Yarn上,Yarn是一个资源管理模块,用于为我们的job分配资源
Hadoop的运行:
- HDFS阶段
- HDFS的数据存储是以块的形式进行的,注意,这个块不是一个容器,它是一个限制,当超过这个限制,就会创建一个新的块
- HDFS在数据存储时,会为数据创建副本,避免因节点异常导致数据的丢失,默认会创建3个副本
- MapReduce阶段
- 为了便于计算,MapReduce对数据读取时会采用切片的方式,切片的大小默认等于块大小,这样可以尽量避免网络直接的跨节点读取数据,每个切片默认就是一个MapTask
- MapReduce分为MapTask和Reduce两个部分,每个Task都是通过Mapper、Redrcer这个类来完成,具体实现方法是通过map和reduce方法
- 数据的读取和写出都是通过流的形式,具体实现是通过InputFormat和OutputFormat的对象来实现
- 它们会将数据通过k,v的形式来传递,如果要进行数据的传输,免不了对数据进行序列化
- map阶段对数据进行处理后,默认对数据的key进行了随机分区,我们可以自定义分区,分区后,会对数据进行快速排序、合并、然后对所有的数据进行归并排序后交给reduce
- reduce会将数据复制到内存中,内存不够再写到磁盘中,对数据进行再次归并排序,然后根据key来分组,这个阶段就是shuffle
- reduceTask的数量默认根据分区的决定,如果我们自定义了分区,可以手动进行reduceTask的数量设置
- Yarn阶段
- 集群默认会在配置Yarn的节点上启动ResourceManager,并且每个节点会启动nodeManager,ResourceManager用于接收任务,nodeManager用于获取并启动job
- 如果是在集群中运行,那么就需要将MapReduce的执行位置配置在Yarn上,否则它默认会运行在本地服务器中
- 当有job来时,ResourceManager就会为该job创建一个APPMater,APPMater用于执行job和监控job
以上是关于打怪升级之小白的大数据之旅(五十三)<Hadoop最后一个模块--Yarn>的主要内容,如果未能解决你的问题,请参考以下文章
打怪升级之小白的大数据之旅(五十九)<Hadoop优化方案>
打怪升级之小白的大数据之旅(四十三)<Hadoop运行模式(集群搭建)>
打怪升级之小白的大数据之旅(五十四)<Zookeeper概述与部署>