增强半监督人脸识别噪声
Posted 苏州程序大白
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了增强半监督人脸识别噪声相关的知识,希望对你有一定的参考价值。
增强半监督人脸识别噪声
1、简介
尽管深度人脸识别从大规模训练数据显著受益,但目前的瓶颈是标签成本。解决这个问题的一个可行的解决方案是半监督学习,利用一小部分的标记数据和大量的未标记数据。然而,主要的挑战是通过自动标签累积的标签错误,损害了培训。在本文中,我们提出了一个有效的对半监督人脸识别具有鲁棒性的解决方案。具体地说,我们引入了一种名为GroupNet(GN)的多代理方法,以赋予我们的解决方案识别错误标记的样本和保存干净样本的能力。我们表明,即使有噪声的标签占据了超过50%的训练数据,仅GN在传统的监督人脸识别中也达到了领先的精度。进一步,我们开发了一种半监督人脸识别解决方案,名为噪声鲁棒学习标签(NRoLL),它是基于GN提供的鲁棒训练能力。它从少量的标签数据开始,因此对一个lar进行高可信度的标签
索引术语-半监督的人脸识别,有噪声的标签学习。
高性能深度人脸识别的关键点包括大规模的训练数据、深度卷积神经网络(CNN)和先进的训练方法。近年来,许多伟大的训练研究都具有不断发展的目标,如ArcFace、CosFace等。这些方法在监督学习的方式上得到了很好的发展,需要大量的标签训练数据来带来其优势。因此,我们还提出了许多用于深度人脸识别的大型数据集,包括CASIA-Webface、MegaFace、MSSeleb、VGGFace、VGGFace2。而数据的规模则保持不变随着身份数量的增加,数据标签的工作负荷和复杂性也大大增加。这将导致高劳动力成本和错误标签(即噪声标签)的严重问题。例如,在MSCeleb中,噪声标签的部分超过50%(图。1(a))可能损害培训。虽然有一些现有的工作,已经改进了数据集(图。1(b)),人类的沉重工作量一般是必不可少的。
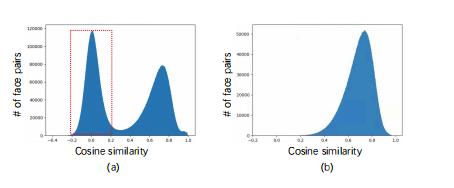
图1中示。MSSeleb(a)中类内人脸对的相似性直方图,由三百万对(b)绘制。(a)中的两个峰值表示大部分噪声标签,而手动校正则删除噪声标签样本,并在(b)中留下一个峰值。
为了减轻人类标签的工作量,适当的解决方案之一是从有限数量的标签数据开始,并通过半监督学习利用大量的无标签数据。由于深度CNN是数据驱动的,它是通过将未带标签的数据传输到有标签的数据来促进培训的有效方法。然而,由于深度学习盛行,除了共识驱动传播(CDP)之外,很少有提出了人脸识别的半监督方法。主要的挑战是通过自动标签引入的不正确的标签,因为人脸数据集通常是大规模的,这使得噪声标签问题更加严重。CDP试图通过使用委员会中介机制来提高标签的准确性,并在巨型上达到引人注目的准确性。然而,应该考虑错误的积累,特别是当标签系统遇到越来越多的未标签数据时。因此,为了解决引入的噪声标签问题,我们提出利用噪声标签学习例程的优势。提出了一些基于的方法,将噪声标签学习与半监督学习相结合,共同处理噪声标签。它们在MNIST和CIFAR-10等有限规模的基准测试上取得了很大的改进,但在大规模人脸识别中,噪声标签问题变得更加严重的情况下还没有得到验证。其他一些工作的研究,以应对人脸识别[,噪声标签,但没有讨论半建议学习。
在本文中,我们提出了一种新的多智能体方法,名称GroupNet(GN),对噪声标签数据进行鲁壮训练;然后,利用对噪声标签的鲁棒性,我们进一步开发了一种半监督解决方案,名为噪声稳健学习标签(NRoLL),其功能包括对少量标签数据的健壮训练和对大量未标记数据的精确标记。我们的解决方案有两个主要的优点。
(1)GN的鲁棒性不仅有利于对噪声标签数据的训练,而且提高了标签的准确性。
(2)如果NRoLL继续标记越来越多的看不见的数据,那么由于NRoLL本身对累积数据的稳健训练,标记的准确性将会提高。在真实环境下的训练标签实验验证了它的收敛性。
总之,本文章中包括了三个主要的贡献。
(1)我们提出了一种新的多智能体学习方法,即GN,以实现对有噪声的标签数据的鲁棒训练。通过与现有的噪声标签学习方法的实验比较,我们的GN在各种基准测试中,即使噪声部分超过50%,也显示出其在训练数据上的领先精度。
(2)我们开发了一个半监督的解决方案,即NRoLL,用于很少有标记数据的深度人脸识别和充分开发无标记数据。基于GN的优势,我们的NRoLL不仅能够稳健地训练网络的噪声数据,而且能够进行准确的标签。据我们所知,这是第一次尝试结合半监督学习和噪声标签学习,以在深度人脸识别领域的八个基准上获得最先进的性能。
(3)通过实验验证了NRoLL的收敛性,其中标记精度和识别精度随着NRoLL不断处理越来越多的未标记的样本。
2、相关的简介
2.1、半监督学习
关于半监督学习有很多研究方向生成模型等技术。我们重点介绍了最近流行的半监督图像分类方法。第一个被广泛认可的实践就是一致性的正规化。它认为一个模型对于未标记的样品,应该给出一致的预测小扰动。这种艺术可以使模型平滑对噪音不敏感。这个家族的方法包括Π-Model、Mean Teacher、Virtual Adversarial Training (VAT)、UDA。半监督学习的另一个策略是最小化预测的熵对于未标记的数据。MixMatch组合一致性正则化,熵最小化和MixUp [28] aug的心态,做出一个整体的解决方案。Self-supervised学习在无标记数据上也可以增强表示学习半监督学习。不同的辅助优化目标,对伪标记[31]进行训练监督数据。它通过赋值来扩大标记数据的大小对未标记数据的可靠标签。本方法适用于人脸识别,处理大量的类数和inter类问题。然而,很少有半监督方法已在大规模人脸识别任务中得到验证深度学习占上风。最近,CDP[10]被提议深的人脸识别。提高了贴标精度使用委员会-中介机制。在这个实验中,我们将我们的解决方案与CDP和上述在每个人脸识别基准上的代表性方法。
2.2、嘈杂的标签学习
在有噪声的标签学习方面的研究正在蓬勃发展。某些方法的估计了噪声跃迁矩阵。但当类数变大时,转换矩阵很难准确、有效地估计。最近的许多作品都集中在样本选择的实践上。导师网预训练一个额外的教师网络,以为学生网络选择干净的样本。解耦和共教学同时训练两个网络。解耦选择了两个网络预测的不同的样本。如果对等网络计算的损失很小,协同教学认为样本是干净的。共教采用了两个网络之间存在分歧的小损失样本。协同挖掘的可以识别干净和有噪声的面孔,并重新计算干净的样本,并丢弃有噪声的样本。最近,提出了一种基于金属收益的方法。此外,某些方法将噪声标签学习与半监督学习相结合,进行鲁棒训练。然而,它们只在MNIST和CIFAR-10等小规模任务上得到验证。其中大多数都涉及到两个代理来共享信息。在人脸识别中,不研究如何使多个主体之间的通信实现更好的鲁棒学习。
3、实战方法
在本文中,我们首先在第三-A节中引入GN,用于具有有噪声标签的鲁棒人脸识别。然后,我们在第三节-B小节中详细阐述了NRoLL解。
A.群网
B.为了实现对噪声标签数据的鲁棒训练,GN探索了必要的程序:
1)根据样本的损失值划分成不同的分区,并巧妙地利用它们来表示噪声水平;
2)处理多个代理之间的通信和信息交换;
3)引入一种新的洗牌策略来进一步提高鲁棒性。
区分有噪声的样本。GN同时使用M个对等网络(即代理)来对有噪声/干净的标签数据进行协同识别。具体来说,我们将小批量输入到每个对等网络Nm、m∈{1、2、3、·、·、M},前向损失值可以应用于区分样本的三个部分:高置信度(HC)、中等置信度(MC)和低置信度(LC),称为噪声样本。在图3中,M个agent独立地将小批样本按损失值的升序排列。损失值大的样本放弃红色LC,与真实标签的大差距将影响培训。LC的阈值是根据从源训练集估计的噪声率r%来确定的,例如,对于MSCeleb的50%。其余样本上的Nm之间的交叉点被确定为绿色的HC。例如,当且仅当所有Nm不区分为LC时,样本将被区分为HC。这些Hs通常具有非常低的损失值,这是高度可靠的用于训练。不包括LC和HC,其余分区中的样本被每个Nm区分为MC,MC包含干净和潜在的噪声样本。请注意,按NM划分的MC分区通常会相互重叠。例如,样本被N1和N2区分为LC,而不是被N3和N4区分,然后它被N3和N4区分为MC。
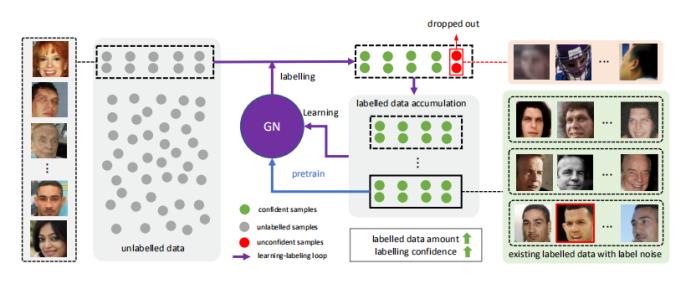
图2中示。NRoLL的概述。GN对遇到的未标记数据(灰色点)进行标签。将具有自信预测的样本附加到当前标签的数据集中,并删除不自信的样本(红点)。当新的未标签数据出现时,NRoLL会重复学习和标签循环。
信息交换。为了减少错误积累,现有的一些作品,采用了交换策略。与双代理模式相比,对于多代理(即Nm之间的MC交换)来说,的情况要复杂得多。因此,我们开发了一种新的通信策略来有效地利用MC样本。我们定义了一个参数α∈{1,2,3,···,M M1},每个Nm沿逆时针方向向其他α agent广播其MC。如图4(a)所示,我们给出了一个MC交换的例子,在M = 4种药剂和不同的α设置下。我们可以将α = MM1设为最大值,其中每个Nm与所有其他对等代理共享MC。同时,接收方需要从多个agent接收到的过多MC中选择干净的样本,形成一个训练批。这里,我们采用贪心规则来选择更可信的样本。其中,接收方Nm优先考虑推荐源数量较多的样品(最大α)。例如,在M = 4, α = 3的情况下,每个agent都可以向其他3个agent推荐和接收MC样本。每个Nm首先选择3个不同代理推荐(发送)给Nm的样本,然后再选择2个代理推荐的样本,直到选中的样本大小与该Nm广播给其他代理的大小相同。为了便于标记,我们将第m个agent Nm从其他agent收到的所有MC样本中选择的MC样本记为MCms。HC和MCms样本都用于训练Nm,但损耗函数不同。在实现中,我们选择了广泛使用的Arc-softmax来计算MC样本的损耗,而使用MV-softmax来计算HC样本的损耗。MV-softmax在出现误分类时增加了softmax公式中的负对数,并且比Arc-softmax具有更强的监管能力。为了更好地收敛,每个损失的权重根据HC和MC的大小自适应。分组样本(HC, MC)的m-thagent Nm的均衡损失为:
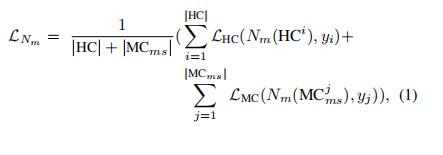
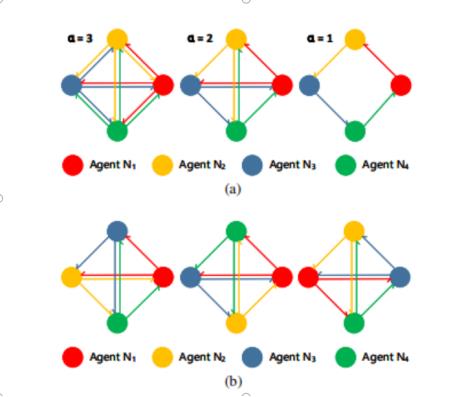
图4中示。代理之间的信息交换(M=4)。(a)每个代理都向其他α代理广播其MC。(b)洗牌策略在每次训练迭代中将代理在循环中的相对位置随机化。
其中LHC和LMC分别为中压软最大损失和弧软最大损失。请注意,所有代理都从相同的高置信样本中学习,而每个代理Nm学习的中等置信样本(MCms)可能是不同的。新的洗牌策略。此外,即使α小于MM1,我们也能使每个代理都有机会在培训过程中接收来自所有其他代理的MC。其目的是使信息源多样化,并防止模型崩溃。具体地说,我们确定了圆中每个位置的广播方向,并在每个向前传播后随机对这些位置洗牌Nm。如图所示。4(b),当M=4和α=2、N1从具有相同概率的三个组合(N3和N4、N3、N2和N2和N3、N2和N4)中的一个接收MC时。通过这种方式,当确定了M和α时,每个接收者都可以通过这种洗牌策略接收到MC的随机组合。请注意,当α=MM1时,洗牌策略等于非洗牌设置。
总结一下。根据样本的损失值,每个代理Nm保留高置信样本(HC),放弃低置信样本(LC),并广播介质保密样本(MC)。每个代理训练HC和其他代理的MC。洗牌策略将源代理随机化,以带来不同的MC建议,避免错误积累和模型崩溃。
B.噪声鲁棒学习标签
在本小节中,我们介绍了人脸识别中半监督学习的鲁棒解决方案,称为噪声鲁棒学习标签(NRoLL)。利用GN的优势,NRoLL开始于对少量标签数据的训练,即使其中存在有噪声的标签。然后,NRoLL遇到未标记的数据,并以高信心地执行精确的标签。随后,标记数据增长,以便进一步培训。当NRoLL不断遇到未标记的数据并收敛到提高人脸识别精度时,标签和训练会相互增强。

噪音,强大的预训练。给定少量的标签数据集Dl(不一定是清洁的标签),NRoLL首先使GN在Dl上进行预先检索。值得注意的是,初始标记的数据具有两个属性。首先,数据的规模比未标记的数据要小得多。其次,它通常具有大部分的标签噪声(即,在MSSeleb中,50%的标签被损坏)。在这里,我们不需要任何人类的工作量来清理标签,因为GN能够对大部分噪声进行稳健的学习。这就是使用噪声鲁棒学习方法来提高半监督人脸识别的动机。
高亮的标签。在现实世界中有许多未标记的样本杜(图中的灰点2).这些未标记的面部需要大量的劳动来进行注释(即在互联网上有数十亿张未标记的面部图片)。
为了模拟实际应用中数据积累的场景,我们设置了Du由未标记数据Dtu的S部分组成,其中Du=SSt=1Dtu。NRoLL每次都会遇到一部分未标记的样本。为了获得可靠的标签,GN中的每个M网络都将对DTu中的每个样本进行预测。
NRoLL选择具有最高对数值的预测作为GN给出的最终预测,相应的类是所得到的标签。此外,如果M预测中的日志值没有超过预定义的阈值T,NRoLL就会过滤掉不确定的样本,如图所示。
2、标签过程中去掉不确定的样本(红点)。
最后,NRoLL将具有可靠的无标签数据Dtu传输到伪标签的Dtpl。
关注苏州程序大白,持续更新技术分享。谢谢大家支持
以上是关于增强半监督人脸识别噪声的主要内容,如果未能解决你的问题,请参考以下文章