打怪升级之小白的大数据之旅(五十一)<MapReduce框架原理三:OutputFormat&Join>
Posted GaryLea
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了打怪升级之小白的大数据之旅(五十一)<MapReduce框架原理三:OutputFormat&Join>相关的知识,希望对你有一定的参考价值。
打怪升级之小白的大数据之旅(五十一)
MapReduce框架原理三:OutputFormat&Join
上次回顾
上一章,我们学习了MapReduce框架中的shuffle机制,本章节是MapReduce中的最后一个模块OutputFormat,它的原理和前面我们学的InputFormat一样…本章还会为大家带来一个实际一点的需求:Join
OutputFormat
OutputFormat和InputFormat原理一样,底层都是流的方式来完成对数据的操作,首先介绍一下OutputFormat的继承树
OutputFormat继承树
|----OutputFormat(抽象类)
|-----FileOutputFormat(抽象类)
|-----TextOutputFormat(默认使用的OutputFormat类)
|-----SequenceFileOutputFormat(将SequenceFileOutputFormat的输出作为后续的MapReduce任务的输入)
OutputFormat同样默认使用的是子类的TextOutputFormat,TextOutputFormat使用了RecordWriter的读取方法,使用LineRecordWriter来对数据进行一行一行的写出操作,下面是各个类中的源码
-
OutputFormat(抽象类)
/* 用来获取RecordWriter对象,该对象是用来写数据的。 */ public abstract RecordWriter<K, V> getRecordWriter(TaskAttemptContext context ) throws IOException, InterruptedException; /* 用来检查输出的一些参数 :比如 ①检查输出路径是否设置了 ②输出路径是否存在 */ public abstract void checkOutputSpecs(JobContext context ) throws IOException, InterruptedException; -
FileOutputFormat(抽象类)
1.重写了checkOutputSpecs方法,在该方法中做了如下操作: ①检查输出路径是否设置了 ②输出路径是否存在 -
TextOutputFormat(默认使用的OutputFormat类
/* 重写了父类的getRecordWriter方法,该方法返回了LineRecordWriter的对象。 该对象是真正用来写数据的对象。 LineRecordWrite是RecordWrite的子类。 */ public RecordWriter<K, V> getRecordWriter(TaskAttemptContext job ) throws IOException, InterruptedException { return new LineRecordWriter<>(fileOut, keyValueSeparator); }
自定义OutputFormat
- 我们知道TextOutputFormat是默认的类,它是一行一行的完成数据的写出操作,当它不能满足我们的需求,我们就需要自定义OutputFormat
- 自定义OutputFormat步骤
- 因为是替代TextOutputFormat,所以我们自己实现继承FileOutputFormat就好了
- 继承之后,我们的数据写出也需要自定义,所以我们还需要一个自定义的类来继承RecordWriter,用于具体改写输出数据的方法,下面我通过案例来介绍自定义OutputFormat的用法
自定义OutputFormat实操
- 需求:
- 我希望将下面的log.txt通过自定义OutputFormat,将百度的网址专门用于一个文件保存(baidu.txt),其他数据用一个文件保存(other.txt)
- 测试数据: log.txt
http://www.baidu.com
http://www.google.com
http://cn.bing.com
http://www.atguigu.com
http://www.sohu.com
http://www.sina.com
http://www.sin2a.com
http://www.sin2desa.com
http://www.sindsafa.com
-
编写思路
- 我们要完成上面的文件输出,首先就要考虑在哪里进行网址的过滤,map和reduce中,其实两个模块都用不到,我们直接定义OutputFormat,在文件写出的时候进行判断即可,所以我们就可以有三个类完成这个工作
- AddressDriver 用于主程序,注册job,加载配置文件、设置OutputFormat、以及提交job等工作
- MyOutputFormat类,用于替代MapReduce的默认TextOutputFormat类
- MyRecordWriter类,用于完成写出数据的方法,在这个类中,我们完成网址的过滤以及文件的输出
-
AddressDriver
package com.company.outputformat; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class AddressDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { // 建立job对象 Job job = Job.getInstance(new Configuration()); // 设置新的OutputFormat子类 job.setOutputFormatClass(MyOutputFormat.class); // 设置最终的输出数据类型 job.setOutputKeyClass(LongWritable.class); job.setOutputValueClass(Text.class); // 文件输入路径 FileInputFormat.setInputPaths(job,new Path("D:\\\\io\\\\input7")); //设置输出路径 FileOutputFormat.setOutputPath(job,new Path("D:\\\\io\\\\output7")); // 提交job job.waitForCompletion(true); } } -
MyOutputFormat
package com.company.outputformat; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.*; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /* 自定义OutputFormat类 思考: 1.继承谁? FileOutputFormat<K, V> 2.泛型是什么? 因为没有Reducer和Mapper所以K,V是InputFormat的K,V */ public class MyOutputFormat extends FileOutputFormat<LongWritable, Text> { @Override public RecordWriter<LongWritable, Text> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException { //自定义RecordWriter return new MyRecordWriter(job); } } -
MyRecordWriter
package com.company.outputformat; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.RecordWriter; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /* K,V和OutputFormat的K,V相同 */ public class MyRecordWriter extends RecordWriter<LongWritable, Text> { private FSDataOutputStream other; private FSDataOutputStream atguigu; public MyRecordWriter(TaskAttemptContext job){ try { //创建流---通过FileSystem创建流 FileSystem fs = FileSystem.get(job.getConfiguration()); //获取输出路径 Path outputPath = FileOutputFormat.getOutputPath(job); //创建流 other = fs.create(new Path(outputPath, "other.log")); atguigu = fs.create(new Path(outputPath, "atguigu.log")); }catch (Exception e){ //终止程序的运行 IOUtils.closeStream(other); IOUtils.closeStream(atguigu); //将编译时异常转换为运行时异常(思想) throw new RuntimeException(e.getMessage()); }finally { //程序终止要做的工作。 } } /** * 将数据写出去 * 该方法是在被循环调用,每调用一次会传入一行数据。 * @param key 偏移量 * @param value 数据 * @throws IOException * @throws InterruptedException */ @Override public void write(LongWritable key, Text value) throws IOException, InterruptedException { String line = value.toString() + "\\n"; //1.判断 if (line.contains("atguigu")){//包含atguigu的网址 //2.将数据写出 atguigu.write(line.getBytes()); }else{//其它 other.write(line.getBytes()); } } /** * 用来关闭资源 * 该方法只会被调用一次,是在最后的时候被调用的 * @param context * @throws IOException * @throws InterruptedException */ @Override public void close(TaskAttemptContext context) throws IOException, InterruptedException { //关流 IOUtils.closeStream(atguigu); IOUtils.closeStream(other); } }
Join多种应用
在学习mysql的时候,我们学习了join这个函数,它可以连接两张表,如果我们在开发中也需要对表进行合并呢?在MapReduce中有两种实现的方法,一种是在map阶段进行join,一种是在reduce阶段进行join
Reduce Join
工作原理
- Map阶段
- 为来自不同表或文件的key/value对,打上标签来区分不同来源,然后用连接字段作为key,其余部分和新加的标志作为value.然后输出k,v交给reduce
- reduce阶段
- reduce接收的数据,其以连接字段作为key的分组工作已经完成了,所以我们只需要在每一个分组中,将前面打上标签的不同文件记录区分开,最后进行合并就可以了
- 表述有些抽象,我们根据案例来说明
Reduce Join实例
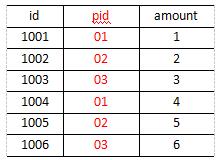
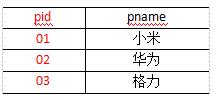
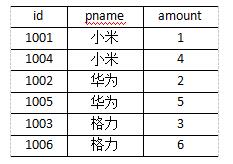
需求,将下面的order.txt与pd.txt两个数据进行合并,并按照下面的最终数据进行输出
- order.txt
- pd.txt
- 我们最终的效果如下:
测试数据:
-
order.txt
1001 01 1 1002 02 2 1003 03 3 1004 01 4 1005 02 5 1006 03 6 -
pd.txt
01 小米 02 华为 03 格力 -
编写步骤
- 我们并不能像mysql一样,一条join in语句就搞定,所以我们的编写思路很重要,通过观察,我们发现在上面的两张表中,pid可以作为连接字段,那么我们可以根据pid来获取到对应的pname从而对两个表进行合并
- 所以我们可以通过将关联条件作为Map输出的key,将两表满足Join条件的数据并携带数据所来源的文件信息,发往同一个ReduceTask,在Reduce中进行数据的串联
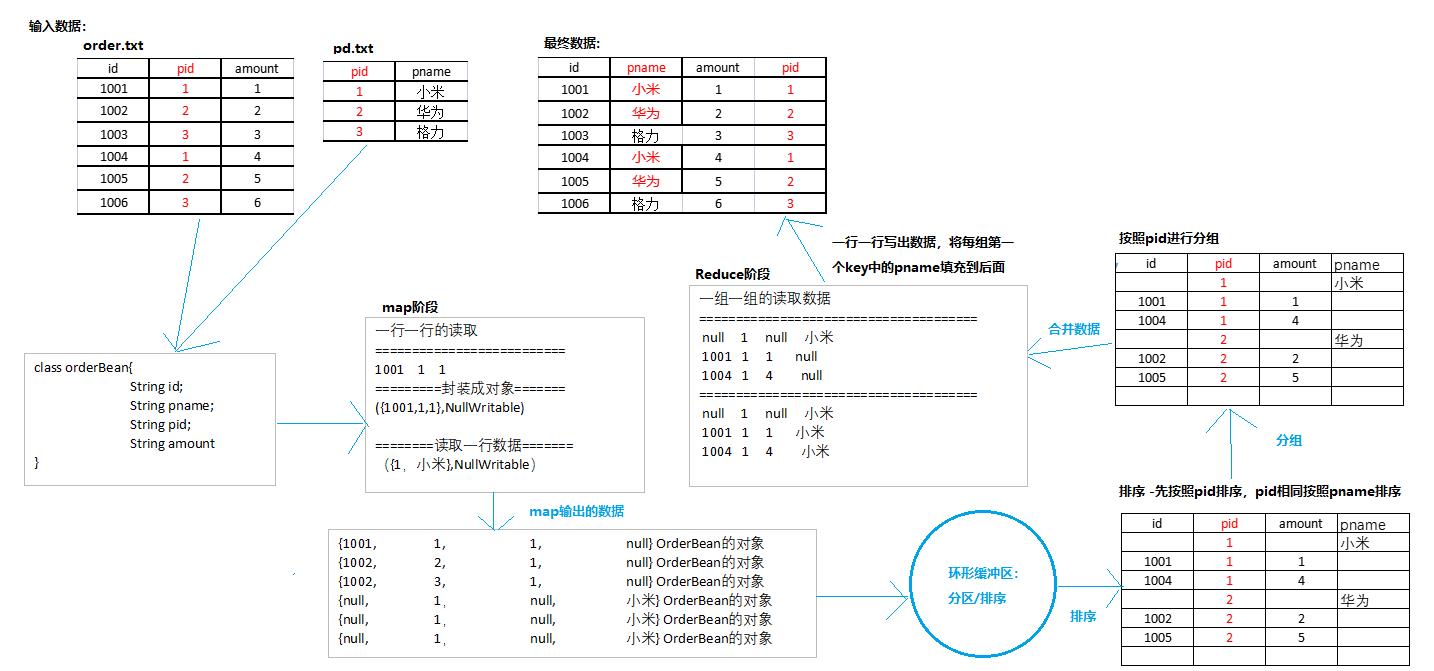
-
这里面核心的就是,我们建立一个对象,里面存放两张表中所有的数据,没有的使用0或
" "来填充,然后将这个对象存放到数据的key中,值使用Null类型来替代 -
当Reduce阶段时,我们根据iterator迭代器学到的知识,来完成数据填充工作
- 迭代器内部类似一个指针,它每next()的时候,就会将指针移动到下一个,我们迭代遍历value的时候,key的指向也会指导下一个,所以我们可以根据这个特性来完成我们需要的pname替换
-
MyGroup
package com.company.reducejoin; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; /* 自定义分组: 1.如果不自定义分组,那么默认分组的方式和排序的方式相同。 2.自定义一个类并继承WritableComparator 3.调用父类指定构造器 */ public class MyGroup extends WritableComparator { public MyGroup(){ /* 调用父类构造器 WritableComparator(Class<? extends WritableComparable> keyClass, boolean createInstances) keyClass : key的数据的运行时类的类型。 createInstances :是否创建实例(对象) */ super(OrderBean.class,true); } @Override public int compare(WritableComparable a, WritableComparable b) { //指定分组方式(排序---pid) OrderBean oa = (OrderBean) a; OrderBean ob = (OrderBean) b; return Long.compare(oa.getPid(),ob.getPid()); } } -
OrderBean
package com.company.reducejoin; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; public class OrderBean implements WritableComparable<OrderBean> { private long pid; private long id; private String amount; private String pname; public OrderBean() { } public OrderBean( long id,long pid, String amount, String pname) { this.pid = pid; this.id = id; this.amount = amount; this.pname = pname; } @Override public int compareTo(OrderBean o) { //先按照pid排序再按照pname排序 int comparePid = Long.compare(this.pid, o.pid); if (comparePid == 0){//说明Pid相同再按照Pname排序 return -this.pname.compareTo(o.pname); } return comparePid; } @Override public void write(DataOutput out) throws IOException { out.writeLong(id); out.writeLong(pid); out.writeUTF(pname); out.writeUTF(amount); } @Override public void readFields(DataInput in) throws IOException { id = in.readLong(); pid = in.readLong(); pname = in.readUTF(); amount = in.readUTF(); } @Override public String toString() { return id + " " + pid + " " + pname + " " + amount; } public long getPid() { return pid; } public void setPid(long pid) { this.pid = pid; } public long getId() { return id; } public void setId(long id) { this.id = id; } public String getAmount() { return amount; } public void setAmount(String amount) { this.amount = amount; } public String getPname() { return pname; } public void setPname(String pname) { this.pname = pname; } } -
ReduceDriver
package com.company.reducejoin; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class ReduceDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Job job = Job.getInstance(new Configuration()); //指定自定义分组类 job.setGroupingComparatorClass(MyGroup.class); job.setMapperClass(ReduceMapper.class); job.setReducerClass(ReduceReducer.class); job.setMapOutputKeyClass(OrderBean.class); job.setMapOutputValueClass(NullWritable.class); job.setOutputKeyClass(OrderBean.class); job.setOutputValueClass(NullWritable.class); FileInputFormat.setInputPaths(job,new Path("D:\\\\io\\\\input9")); FileOutputFormat.setOutputPath(job,new Path("D:\\\\io\\\\output9")); job.waitForCompletion(true); } } -
ReduceMapper
package com.company.reducejoin; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import java.io.IOException; public class ReduceMapper extends Mapper<LongWritable, Text,OrderBean, NullWritable> { private String fileName; /* setup方法只会在任务开始的时候调用一次。 setup方法在map方法之前调用 作用 :初始化 */ @Override protected void setup(Context context) throws IOException, InterruptedException { //通过切片信息获取文件名 FileSplit fileSplit = (FileSplit) context.getInputSplit(); fileName = fileSplit.getPath().getName(); } /* cleanup方法只会在任务结束的时候调用一次 cleanup方法在map方法后面调用 作用 :关闭资源 */ @Override protected void cleanup(Context context) throws IOException, InterruptedException { super.cleanup(context); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //1.切割数据 String line = value.toString(); String[] lineSplit = line.split("\\t"); //2.封装K,V OrderBean outkey = null;以上是关于打怪升级之小白的大数据之旅(五十一)<MapReduce框架原理三:OutputFormat&Join>的主要内容,如果未能解决你的问题,请参考以下文章
打怪升级之小白的大数据之旅(五十六)<Zookeeper内部原理>
打怪升级之小白的大数据之旅(五十)<MapReduce框架原理二:shuffle>
打怪升级之小白的大数据之旅(五十九)<Hadoop优化方案>