Transformer 原理讲解以及在 CV 领域的应用
Posted Charmve
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Transformer 原理讲解以及在 CV 领域的应用相关的知识,希望对你有一定的参考价值。
| 本篇文章选自GitHub《计算机视觉实战演练:算法与应用》第17章节,全文请参考
https://github.com/Charmve/computer-vision-in-action
本书主要以实战为主,基础理论篇主要讲解神经网络模型,结合常见的手写字识别、图像分类、车道线检测、人脸识别项目、实力分割等实战演练.更主要的特点在于,系统的整理了前沿的计算机视觉模型,例如注意力机制、跨界模型transformer、dert等新型深度学习模型。 适合掌握基本算法知识,一定编程能力的朋友入手。 GitHub已发布几章篇目,欢迎大家指正提issues。本资料长期更新维护,开源免费!
|

目前已经有基于Transformer在三大图像问题上的应用:分类(ViT),检测(DETR)和分割(SETR),并且都取得了不错的效果。那么未来,Transformer有可能替换CNN吗,Transformer会不会如同在NLP领域的应用一样革新CV领域?后面的研究思路可能会有哪些呢?敬请期待下一篇文章给出解答。
01
思想和框图
Transformer是由谷歌于2017年提出的具有里程碑意义的模型,同时也是语言AI革命的关键技术。在此之前的SOTA模型都是以循环神经网络为基础(RNN, LSTM等)。从本质上来讲,RNN是以串行的方式来处理数据,对应到NLP任务上,即按照句中词语的先后顺序,每一个时间步处理一个词语。
相较于这种串行模式,Transformer的巨大创新便在于并行化的语言处理:文本中的所有词语都可以在同一时间进行分析,而不是按照序列先后顺序。为了支持这种并行化的处理方式,Transformer依赖于注意力机制。注意力机制可以让模型考虑任意两个词语之间的相互关系,且不受它们在文本序列中位置的影响。通过分析词语之间的两两相互关系,来决定应该对哪些词或短语赋予更多的注意力。
Transformer采用Encoder-Decoder架构,下图就是Transformer的结构。其中左半部分是encoder,右半部分是decoder [1]:

现有的各种基于Transformer的模型基本只是与NLP任务有关。然而,最近一些文章开创性地将Transformer模型跨领域地引用到了计算机视觉任务中,并取得了不错地成果。这也被许多AI学者认为是开创了CV领域的新时代,甚至可能完全取代传统的卷积操作。
最近CV界也有很多文章将transformer迁移到CV领域,这些文章总的来说可以分为两个大类:
-
将self-attention机制与常见的CNN架构结合
-
用self-attention机制完全替代CNN
其中,ICLR 2021 under review 的《An Image Is Worth 16X16 Words: Transformers for Image Recognition at Scale》[2] 采用的是第二种思路。
02
实现细节
2.1 Encoder
Encoder层中有6个一模一样的层结构,每个层结构包含了两个子层,第一个子层是多头注意力层(Multi-Head Attention,橙色部分),第二个子层是前馈连接层(Feed Forward,浅蓝色部分)。除此之外,还有一个残差连接,直接将input embedding传给第一个Add & Norm层(黄色部分)以及第一个Add & Norm层传给第二个Add & Norm层(即图中的粉色-黄色1,黄色1-黄色2部分运用了残差连接)。
2.2 Decoder
Decoder层中也有6个一模一样的层结构,但是比Endoer层稍微复杂一点,它有三个子层结构,第一个子层结构是遮掩多头注意力层(Masked Multi-Head Attention,橙色部分),第二个子层是多头注意力结构(Multi-Head Attenion,橙色部分),第三个子层是前馈连接层(Feed Forward,浅蓝色部分)。
说明:
-
这一部分的残差连接是粉色-黄色1,黄色1-黄色2,黄色2-黄色3三个部分
-
该层的重点是第二个子层,即多头注意力层,它的输入包括两个部分,第一个部分是第一个子层的输出,第二个部分是Encoder层的输出(这是与encoder层的区别之一),这样则将encoder层和decoder层串联起来,以进行词与词之间的信息交换,这里信息交换是通过共享权重WQ,WV,WK得到的。
-
第一个子层中的mask,它的作用就是防止在训练的时候使用未来的输出的单词。比如训练时,第一个单词是不能参考第二个单词的生成结果的,此时就会将第二个单词及其之后的单词都mask掉。总体来讲,mask的作用就是用来保证预测位置i的信息只能基于比i小的输出。因此,encoder层可以并行计算,一次全部encoding出来,但是decoder层却一定要像RNN一样一个一个解出来,因为要用上一个位置的输入当做attention的query.
-
残差结构是为了解决梯度消失问题,可以增加模型的复杂性。
-
LayerNorm层是为了对attention层的输出进行分布归一化,转换成均值为0方差为1的正态分布。cv中经常会用的是batchNorm,是对一个batchsize中的样本进行一次归一化,而layernorm则是对一层进行一次归一化,二者的作用是一样的,只是针对的维度不同,一般来说输入维度是(batch_size,seq_len,embedding),batchnorm针对的是batch_size层进行处理,而layernorm则是对seq_len进行处理(即batchnorm是对一批样本中进行归一化,而layernorm是对每一个样本进行一次归一化)。
-
使用ln而不是bn的原因是因为输入序列的长度问题,每一个序列的长度不同,虽然会经过padding处理,但是padding的0值其实是无用信息,实际上有用的信息还是序列信息,而不同序列的长度不同,所以这里不能使用bn一概而论。
-
FFN是两层全连接:w * [delta(w * x + b)] + b,其中的delta是relu激活函数。这里使用FFN层的原因是:为了使用非线性函数来拟合数据。如果说只是为了非线性拟合的话,其实只用到第一层就可以了,但是这里为什么要用两层全连接呢,是因为第一层的全连接层计算后,其维度是(batch_size,seq_len,dff)(其中dff是超参数的一种,设置为2048),而使用第二层全连接层是为了进行维度变换,将dff转换为初始的d_model(512)维。
-
decoder层中中间的多头自注意力机制的输入是两个参数——encoder层的输出和decoder层中第一层masked多头自注意力机制的输出,作用在本层时是:q=encoder的输出,k=v=decoder的输出。
-
encoder的输入包含两个,是一个序列的token embedding + positional embedding,用正余弦函数对序列中的位置进行计算(偶数位置用正弦,技术位置用余弦)
2.3 Self-Attention
self-Attention是Transformer用来找到并重点关注与当前单词相关的词语的一种方法。如下述例子:
The animal didn’t cross the street because it was too tired.
这里的it究竟是指animal还是street,对于算法来说是不容易判断的,但是self-attention是能够把it和animal联系起来的,达到消歧的目的。
这里描述self-attention的具体过程如下图所示:

从上图可以看出,attention机制中主要涉及三个向量Q(Query),K(Key),V(Value),这三个向量的计算过程如下图所示:
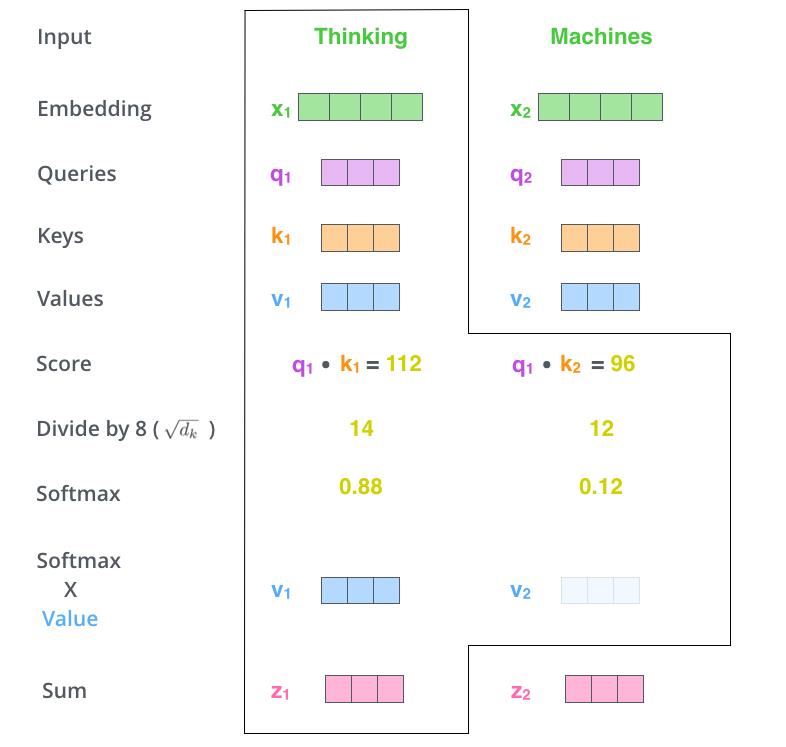
图中,WQ,WV,WK是三个随机初始化的矩阵,每个特征词的向量计算公式如下所示:

说明:
-
score表示关注单词的相关程度.
-
这种通过 query 和 key 的相似性程度来确定 value 的权重分布的方法被称为scaled dot-product attention。
-
attention与self-attention的区别:
-
self-attention是一般attention的特殊情况,在self-attention中,Q=K=V每个序列中的单元和该序列中所有单元进行attention计算。Google提出的多头attention通过计算多次来捕获不同子控件上的相关信息。
-
self-attention的特点在于无视词之间的距离直接计算依赖关系,能够学习一个句子的内部结构,实现也较为简单并且可以并行计算。从一些论文中看到,self-attention可以当成一个层和RNN,CNN,FNN等配合使用,成功应用于其他NLP任务。
-
attention中要除以8(根号d_k)的原因是为了缩放,它具备分散注意力的作用;原始注意力值均聚集在得分最高的那个值,获得了权重为1;而缩放后,注意力值就会分散一些。
-
attention中除以根号d_k具备缩放的原因是因为原始表征x1是符合均值为0方差为1的正态分布的,而与权重矩阵相乘后,结果符合均值为0方差为d_k的正态分布了,所以为了不改变原始表征的分布,需要除以根号d_k
注意力机制的优点:
-
一步到位获取全局与局部的关系,不会像RNN那样对长期依赖的捕捉会受到序列长度的限制。
-
每步的结果不依赖于上一步,可以做成并行的模式
-
相比CNN与RNN,参数少,模型复杂度低。
注意力机制的缺点:
没法捕捉位置信息,即没法学习序列中的顺序关系。这点可以通过加入位置信息,如通过位置向量来改善,具体如bert模型。
2.4 Multi-Headed Attention
多头注意力机制是指有多组Q,K,V矩阵,一组Q,K,V矩阵代表一次注意力机制的运算,transformer使用了8组,所以最终得到了8个矩阵,将这8个矩阵拼接起来后再乘以一个参数矩阵WO,即可得出最终的多注意力层的输出。全部过程如下图所示:


左图表示使用多组Q,K,V矩阵,右图表示8组Q,K,V矩阵计算会得出8个矩阵,最终我们还需将8个矩阵经过计算后输出为1个矩阵,才能作为最终多注意力层的输出。如下图所示,其中WO是随机初始化的参数矩阵。

2.5 Positional Encoding
在图figure 1中,还有一个向量positional encoding,它是为了解释输入序列中单词顺序而存在的,维度和embedding的维度一致。这个向量决定了当前词的位置,或者说是在一个句子中不同的词之间的距离。论文中的计算方法如下:
PE(pos,2 * i) = sin(pos / 100002i/dmodel)
PE(pos,2 * i + 1) = cos(pos / 100002i/dmodel)
其中pos指当前词在句子中的位置,i是指向量中每个值的index,从公式中可以看出,句子中偶数位置的词用正弦编码,奇数位置的词用余弦编码。最后把positional encoding的值与embedding的值相加作为输入传进transformer结构中,如下图所示:

2.6 Layer normalization
在transformer中,每一个子层(自注意力层,全连接层)后都会有一个Layer normalization层,如下图所示:

Normalize层的目的就是对输入数据进行归一化,将其转化成均值为0方差为1的数据。LN是在每一个样本上都计算均值和方差,如下图所示:

LN的公式如下:
LN(xi) = α * (xi - μL / √(σ2L + ε)) + β
以上是encoder层的全部内容,最后再展示一下将两个encoder叠加在一起的内部图:

03
应用任务和结果
3.1 NLP领域
在机器翻译, NLP领域, 基于attention机制的transformer模型取得了很好的结果,因侧重点在CV领域,所以这里不详细阐述。
3.2 CV领域
3.2.1 检测DETR
第一篇用transformer做端到端目标检测的论文:
End to End Object Detection With Transformer [3]
先用CNN提取特征,然后把最后特征图的每个点看成word,这样特征图就变成了a sequence words,而检测的输出恰好是a set objects,所以transformer正好适合这个任务。
这篇文章用完整的transformer构建了一个end-to-end的目标检测模型,除此外该模型舍弃了手工设计anchor的方法,还提出了一个新的loss function。但讨论重点还是在模型结构上。模型结构如下图:

这篇文章有如下亮点:
-
不用NMS 直接做set prediction
-
二分图匹配loss
-
object queries很有意思, 本身是无意义的信息
实验表明,该模型可达到与经过严格调整的Faster R-CNN基线相当的结果。DETR模型简洁直接,但缺点是训练时间过长,对小目标的检测效果不好。
3.2.2 分类ViT
An Image Is Worth 16X16 Words: Transformers for Image Recognition at Scale[2]
文章不同于以往工作的地方,就是尽可能地将NLP领域的transformer不作修改地搬到CV领域来。但是NLP处理的语言数据是序列化的,而CV中处理的图像数据是三维的(height、width和channels)。所以需要通过某种方法将图像这种三维数据转化为序列化的数据。文章中,图像被切割成一个个patch,这些patch按照一定的顺序排列,就成了序列化的数据。
在此基础上,作者提出了Vision Transformer模型。

这篇文章首先尝试在几乎不做改动的情况下将Transformer模型应用到图像分类任务中,在 ImageNet 得到的结果相较于 ResNet 较差,这是因为Transformer模型缺乏归纳偏置能力,例如并不具备CNN那样的平移不变性和局部性,因此在数据不足时不能很好的泛化到该任务上。
然而,当训练数据量得到提升时,归纳偏置的问题便能得到缓解,即如果在足够大的数据集上进行与训练,便能很好地迁移到小规模数据集上。
在实验中,作者发现,在中等规模的数据集上(例如ImageNet),transformer模型的表现不如ResNets;而当数据集的规模扩大,transformer模型的效果接近或者超过了目前的一些SOTA结果。**作者认为是大规模的训练可以鼓励transformer学到CNN结构所拥有的translation equivariance 和locality.
3.2.3 分割SETR
Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers

用ViT作为的图像的encoder,然后加一个CNN的decoder来完成语义图的预测。
大量实验表明,SETR在ADE20K(50.28%mIoU)、Pascal上下文(55.83%mIoU)和城市景观上取得了新的水平。特别是在竞争激烈的ADE20K测试服务器排行榜上,取得了第一名(44.42%mIoU)的位置。
3.2.4 Deformable-DETR
DEFORMABLE DETR: DEFORMABLE TRANSFORMERS FOR END-TO-END OBJECT DETECTION[5]
对之前DETR的改进。

亮点有:
-
加入deformable参数
-
多尺度特征融合
实验结果:训练时间减少,性能又高

04
优点及分析
1、相较于RNN必须按时间顺序进行计算,Transformer并行处理机制的显著好处便在于更高的计算效率,可以通过并行计算来大大加快训练速度,从而能在更大的数据集上进行训练。
-
例如GPT-3(Transformer的第三代)的训练数据集大约包含5000亿个词语,并且模型参数量达到1750亿,远远超越了现有的任何基于RNN的模型。
-
算法的并行性非常好,符合目前的硬件(主要指GPU)环境。
2、Transformer模型还具有良好的可扩展性和伸缩性。
-
在面对具体的任务时,常用的做法是先在大型数据集上进行训练,然后在指定任务数据集上进行微调。并且随着模型大小和数据集的增长,模型本身的性能也会跟着提升,目前为止还没有一个明显的性能天花板。
3、Transformer的特征抽取能力比RNN系列的模型要好。
4、Transforme其设计已经足够有创新,因为其抛弃了在NLP中最根本的RNN或者CNN并且取得了非常不错的效果,算法的设计非常精彩,值得每个深度学习的相关人员仔细研究和品位。
5、Transformer的设计最大的带来性能提升的关键是将任意两个单词的距离变成1,这对解决NLP中棘手的长期依赖问题是非常有效的。
6、Transformer不仅仅可以应用在NLP的机器翻译领域,甚至可以不局限于NLP领域,是非常有科研潜力的一个方向。
Transformer的特性不仅让其在NLP领域大获成功,也提供了将其迁移到其他任务上的潜力。
05
缺点及分析
1、Transformer模型缺乏归纳偏置能力,例如并不具备CNN那样的平移不变性和局部性,因此在数据不足时不能很好的泛化到该任务上。
然而,当训练数据量得到提升时,归纳偏置的问题便能得到缓解,即如果在足够大的数据集上进行与训练,便能很好地迁移到小规模数据集上。
2、粗暴的抛弃RNN和CNN虽然非常炫技,但是它也使模型丧失了捕捉局部特征的能力,RNN + CNN + Transformer的结合可能会带来更好的效果。
3、Transformer失去的位置信息其实在NLP中非常重要,而论文中在特征向量中加入Position Embedding也只是一个权宜之计,并没有改变Transformer结构上的固有缺陷。
06
参考文献
[1] Ashish Vaswani,Noam Shazeer,Niki Parmar,Jakob Uszkoreit,Llion Jones,Aidan N. Gomez,Łukasz Kaiser,Illia Polosukhin. Attention Is All You Need. 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA.
[2] Anonymous authors. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. Under review as a conference paper at ICLR 2021.
[3] Nicolas Carion, Francisco Massa,Gabriel Synnaeve,Nicolas Usunier,Alexander Kirillov,Zagoruyko. End to End Object Detection With Transformer. Paris Dauphine University, Facebook AI.
[4] Sixiao Zheng, Jiachen Lu, Hengshuang Zhao, Xiatian Zhu, Zekun Luo, Yabiao Wang, Yanwei Fu, Jianfeng Feng, Tao Xiang, Philip H.S. Torr, Li Zhang. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. Fudan University, University of Oxford, University of Surrey, Tencent Youtu Lab, Facebook AI. https://fudan-zvg.github.io/SETR
[5] Xizhou Zhu, Weijie Su2, Lewei Lu, Bin Li , Xiaogang Wang, Jifeng Dai. DEFORMABLE DETR: DEFORMABLE TRANSFORMERS FOR END-TO-END OBJECT DETECTION. SenseTime Research, University of Science and Technology of China, The Chinese University of Hong Kong
推荐阅读
(点击标题可跳转阅读)

# CV技术社群邀请函 #

△长按添加迈微官方微信号
备注:姓名-学校/公司-研究方向-城市(如:小C-北大-目标检测-北京)
△点击卡片关注迈微AI研习社,获取最新CV干货
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:yidazhang1@gmail.com

觉得有用麻烦给个三连啦~ ![]()
以上是关于Transformer 原理讲解以及在 CV 领域的应用的主要内容,如果未能解决你的问题,请参考以下文章
从ViT到Swin,10篇顶会论文看Transformer在CV领域的发展历程