用Transformer实现OCR字符识别!
Posted Datawhale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用Transformer实现OCR字符识别!相关的知识,希望对你有一定的参考价值。
Datawhale干货
作者:安晟、袁明坤,Datawhale成员
在CV领域中,transformer除了分类还能做什么?本文将采用一个单词识别任务数据集,讲解如何使用transformer实现一个简单的OCR文字识别任务,并从中体会transformer是如何应用到除分类以外更复杂的CV任务中的。全文分为四部分:
一、数据集简介与获取
二、数据分析与关系构建
三、如何将transformer引入OCR
四、训练框架代码讲解
注:本文围绕如何设计模型和训练架构来解决OCR任务,文章含完整实践,代码很长建议收藏。不熟悉transformer的小伙伴可以点击这里回顾。
整个文字识别任务中,主要包括以下几个文件:
- analysis_recognition_dataset.py (数据集分析脚本)
- ocr_by_transformer.py (OCR任务训练脚本)
- transformer.py (transformer模型文件)
- train_utils.py (训练相关辅助函数,loss、optimizer等)
其中 ocr_by_transformer.py 为主要的训练脚本,其依托 train_utils.py 和 transformer.py 两个文件构建 transformer 来完成字符识别模型的训练
一、数据集简介与获取
本文使用的数据集基于ICDAR2015 Incidental Scene Text 中的 Task 4.3: Word Recognition,这是一个著名的自然场景下文本识别数据集,本次用来进行单词识别任务,我们去掉了其中一些图片,来简化这个实验的难度,因此本文的数据集与原始数据集略有差别。
为了能够更好的进行数据共享和版本管控,我们选择在线调用数据集,将简化后的数据集存放在专门的数据共享平台,数据开源地址: https://gas.graviti.cn/dataset/datawhale/ICDAR2015 ,有相关问题可以直接在数据集讨论区交流。
该数据集包含了众多自然场景图像中出现的文字区域,数据中训练集含有4326张图像,测试集含有1992张图像,他们都是从原始大图中依据文字区域的bounding box裁剪出来的,图像中的文字基本处于图片中心位置。
数据集中图像类似如下样式:
| word_104.png, "Optical" |
|---|
 |
数据本身以图像展示,对应的标签存储在CLASSIFICATION中,后文代码中标签获取,将直接得到一个包含所有字符的列表,这也是为了方便标签易用性进行的存储选择。
下面简单介绍数据集的快速使用:
本地下载安装 tensorbay
pip3 install tensorbay打开本文数据集链接:https://gas.graviti.cn/dataset/datawhale/ICDAR2015
将数据集fork到自己账户下
点击网页上方开发者工具 --> AccessKey --> 新建一个AccessKey --> 复制这个Key
from tensorbay import GAS
from tensorbay.dataset import Dataset
# GAS凭证
KEY = 'Accesskey-***************80a' # 添加自己的AccessKey
gas = GAS(KEY)
# 获取数据集
dataset = Dataset("ICDAR2015", gas)
# dataset.enable_cache('./data') # 开启本语句,选择将数据建立本地缓存
# 训练集和验证集
train_segment = dataset["train"]valid_segment = dataset['valid']
# 数据及标签
for data in train_segment:
# 图像数据
img = data.open()
# 图像标签
label = data.label.classification.category
break通过以上代码获取的图像及标签形式如下:
| img | label |
|---|---|
| ['C', 'A', 'U', 'T', 'I', 'O', 'N'] |

通过以上简单代码便可以快速获取图像数据及标签,但程序每次运行都会自动去平台下载数据,因此耗时较长,建议开启本地缓存,一次下载多次使用,当不再使用数据时便可以将数据删除。
二、数据分析与关系构建
开始实验前,我们先对数据进行简单分析,只有对数据的特性足够了解,才能够更好的搭建出baseline,在训练中少走弯路。
运行下面代码,即可一键完成对于数据集的简单分析:
python analysis_recognition_dataset.py
具体地,这个脚本所做的工作包括:对数据进行标签字符统计(有哪些字符、每个字符出现次数多少)、最长标签长度统计,图像尺寸分析等,并且构建字符标签的映射关系文件 lbl2id_map.txt。
下面我们来一点点看代码:
注:本文代码开源地址:
https://github.com/datawhalechina/dive-into-cv-pytorch/tree/master/code/chapter06_transformer/6.2_recognition_by_transformer(online_dataset)
首先完成准备工作,导入需要的库,并设置好相关目录或文件的路径
import os
from PIL import Image
import tqdm
from tensorbay import GAS
from tensorbay.dataset import Dataset
# GAS凭证
KEY = 'Accesskey-************************480a' # 添加自己的AccessKey
gas = GAS(KEY)
# 数据集获取并本地缓存
dataset = Dataset("ICDAR2015", gas)
dataset.enable_cache('./data') # 数据缓存地址
# 获取训练集和验证集
train_segment = dataset["train"]
valid_segment = dataset['valid']
# 中间文件存储路径,存储标签字符与其id的映射关系
base_data_dir = './'
lbl2id_map_path = os.path.join(base_data_dir, 'lbl2id_map.txt')2.1 标签最长字符个数统计
首先统计数据集最长label中包含的字符数量,此处要将训练集和验证集中的最长标签都进行统计,进而得到最长标签所含字符。
def statistics_max_len_label(segment):
"""
统计标签中最长的label所包含的字符数
"""
max_len = -1
for data in segment:
lbl_str = data.label.classification.category # 获取标签
lbl_len = len(lbl_str)
max_len = max_len if max_len > lbl_len else lbl_len
return max_len
train_max_label_len = statistics_max_len_label(train_segment) # 训练集最长label
valid_max_label_len = statistics_max_len_label(valid_segment) # 验证集最长label
max_label_len = max(train_max_label_len, valid_max_label_len) # 全数据集最长label
print(f"数据集中包含字符最多的label长度为max_label_len")数据集中最长label含有21个字符,这将为后面transformer模型搭建时的时间步长度的设置提供参考。
2.2 标签所含字符统计
下面代码查看数据集中出现过的所有字符:
def statistics_label_cnt(segment, lbl_cnt_map):
"""
统计标签文件中label都包含哪些字符以及各自出现的次数
lbl_cnt_map : 记录标签中字符出现次数的字典
"""
for data in segment:
lbl_str = data.label.classification.category # 获取标签
for lbl in lbl_str:
if lbl not in lbl_cnt_map.keys():
lbl_cnt_map[lbl] = 1
else:
lbl_cnt_map[lbl] += 1
lbl_cnt_map = dict() # 用于存储字符出现次数的字典
statistics_label_cnt(train_segment, lbl_cnt_map) # 训练集中字符出现次数统计
print("训练集中label中出现的字符:")
print(lbl_cnt_map)
statistics_label_cnt(valid_segment, lbl_cnt_map) # 训练集和验证集中字符出现次数统计
print("训练集+验证集label中出现的字符:")
print(lbl_cnt_map)输出结果为:
训练集中label中出现的字符:
'C': 593, 'A': 1189, 'U': 319, 'T': 896, 'I': 861, 'O': 965, 'N': 785, 'D': 383, 'W': 179, 'M': 367, 'E': 1423, 'X': 110, '$': 46, '2': 121, '4': 44, 'L': 745, 'F': 259, 'P': 389, 'R': 836, 'S': 1164, 'a': 843, 'v': 123, 'e': 1057, 'G': 345, "'": 51, 'r': 655, 'k': 96, 's': 557, 'i': 651, 'c': 318, 'V': 158, 'H': 391, '3': 50, '.': 95, '"': 8, '-': 68, ',': 19, 'Y': 229, 't': 563, 'y': 161, 'B': 332, 'u': 293, 'x': 27, 'n': 605, 'g': 171, 'o': 659, 'l': 408, 'd': 258, 'b': 88, 'p': 197, 'K': 163, 'J': 72, '5': 80, '0': 203, '1': 186, 'h': 299, '!': 51, ':': 19, 'f': 133, 'm': 202, '9': 66, '7': 45, 'j': 15, 'z': 12, '´': 3, 'Q': 19, 'Z': 29, '&': 9, ' ': 50, '8': 47, '/': 24, '#': 16, 'w': 97, '?': 5, '6': 40, '[': 2, ']': 2, 'É': 1, 'q': 3, ';': 3, '@': 4, '%': 28, '=': 1, '(': 6, ')': 5, '+': 1
训练集+验证集label中出现的字符:
'C': 893, 'A': 1827, 'U': 467, 'T': 1315, 'I': 1241, 'O': 1440, 'N': 1158, 'D': 548, 'W': 288, 'M': 536, 'E': 2215, 'X': 181, '$': 57, '2': 141, '4': 53, 'L': 1120, 'F': 402, 'P': 582, 'R': 1262, 'S': 1752, 'a': 1200, 'v': 169, 'e': 1536, 'G': 521, "'": 70, 'r': 935, 'k': 137, 's': 793, 'i': 924, 'c': 442, 'V': 224, 'H': 593, '3': 69, '.': 132, '"': 8, '-': 87, ',': 25, 'Y': 341, 't': 829, 'y': 231, 'B': 469, 'u': 415, 'x': 38, 'n': 880, 'g': 260, 'o': 955, 'l': 555, 'd': 368, 'b': 129, 'p': 317, 'K': 253, 'J': 100, '5': 105, '0': 258, '1': 231, 'h': 417, '!': 65, ':': 24, 'f': 203, 'm': 278, '9': 76, '7': 62, 'j': 19, 'z': 14, '´': 3, 'Q': 28, 'Z': 36, '&': 15, ' ': 82, '8': 58, '/': 29, '#': 24, 'w': 136, '?': 7, '6': 46, '[': 2, ']': 2, 'É': 2, 'q': 3, ';': 3, '@': 9, '%': 42, '=': 1, '(': 7, ')': 5, '+': 2, 'é': 1上方代码中,lbl_cnt_map 为字符出现次数的统计字典,后面还会用于建立字符及其id映射关系。
从数据集统计结果来看,测试集含有训练集没有出现过的字符,例如测试集中包含1个'é'未曾在训练集出现。这种情况数量不多,应该问题不大,所以此处未对数据集进行额外处理(但是有意识的进行这种训练集和测试集是否存在diff的检查是必要的)。
2.3 char和id的映射字典构建
在本文OCR任务中,需要对图片中的每个字符进行预测,为了达到这个目的,首先就需要建立一个字符与其id的映射关系,将文本信息转化为可供模型读取的数字信息,这一步类似NLP中建立语料库。
在构建映射关系时,除了记录所有标签文件中出现的字符外,还需要初始化三个特殊字符,分别用来代表一个句子起始符、句子终止符和填充(Padding)标识符(相关介绍戳这里)。后面dataset构建部分的讲解也还会再次提到。
脚本运行后,所有字符的映射关系将会保存在 lbl2id_map.txt文件中。
# 构造label中 字符--id 之间的映射
print("构造label中 字符--id 之间的映射:")
lbl2id_map = dict()
# 初始化三个特殊字符
lbl2id_map['☯'] = 0 # padding标识符
lbl2id_map['■'] = 1 # 句子起始符
lbl2id_map['□'] = 2 # 句子结束符
# 生成其余字符的id映射关系
cur_id = 3
for lbl in lbl_cnt_map.keys():
lbl2id_map[lbl] = cur_id
cur_id += 1
# 保存 字符--id 之间的映射 到txt文件
with open(lbl2id_map_path, 'w', encoding='utf-8') as writer: # 参数encoding是可选项,部分设备并未默认为utf-8
for lbl in lbl2id_map.keys():
cur_id = lbl2id_map[lbl]
print(lbl, cur_id)
line = lbl + '\\t' + str(cur_id) + '\\n'
writer.write(line)构造出的 字符-id 之间的映射:
☯ 0
■ 1
□ 2
C 3
A 4
...
= 85
( 86
) 87
+ 88
é 89此外,analysis_recognition_dataset.py 文件中还包含一个建立关系映射字典的函数,可以通过读取含有映射关系txt的文件,构建出字符到id和id到字符的映射字典。这服务于后续transformer训练过程,以方便字符关系快速实现转换。
def load_lbl2id_map(lbl2id_map_path):
"""
读取 字符-id 映射关系记录的txt文件,并返回 lbl->id 和 id->lbl 映射字典
lbl2id_map_path : 字符-id 映射关系记录的txt文件路径
"""
lbl2id_map = dict()
id2lbl_map = dict()
with open(lbl2id_map_path, 'r') as reader:
for line in reader:
items = line.rstrip().split('\\t')
label = items[0]
cur_id = int(items[1])
lbl2id_map[label] = cur_id
id2lbl_map[cur_id] = label
return lbl2id_map, id2lbl_map2.4 数据集图像尺寸分析
在进行图像分类检测等任务时,经常会查看图像的尺寸分布,进而确定合适的图像的预处理方式,例如在进行目标检测时会对图像尺寸和bounding box的尺寸进行统计,分析长宽比进而选择合适的图像裁剪策略和适当的初始anchor策略等。
因此这里通过分析图像宽度、高度和宽高比等信息来了解数据的特点,为后续实验策略制定提供参考。
def read_gas_image(data):
with data.open() as fp:
image = Image.open(fp)
return image
# 分析数据集图片尺寸
print("分析数据集图片尺寸:")
# 初始化参数
min_h = 1e10
min_w = 1e10
max_h = -1
max_w = -1
min_ratio = 1e10
max_ratio = 0
# 遍历数据集计算尺寸信息
for data in tqdm.tqdm(train_segment):
img = read_gas_image(data) # 读取图片
w, h = img.size # 提取图像宽高信息
ratio = w / h # 宽高比
min_h = min_h if min_h <= h else h # 最小图片高度
max_h = max_h if max_h >= h else h # 最大图片高度
min_w = min_w if min_w <= w else w # 最小图片宽度
max_w = max_w if max_w >= w else w # 最大图片宽度
min_ratio = min_ratio if min_ratio <= ratio else ratio # 最小宽高比
max_ratio = max_ratio if max_ratio >= ratio else ratio # 最大宽高比
# 输出信息
print('min_h:', min_h)
print('max_h:', max_h)
print('min_w:', min_w)
print('max_w:', max_w)
print('min_ratio:', min_ratio)
print('max_ratio:', max_ratio)数据集图片尺寸相关情况统计结果如下:
min_h: 9
max_h: 295
min_w: 16
max_w: 628
min_ratio: 0.6666666666666666
max_ratio: 8.619047619047619通过以上的结果,可看出图片多为卧倒的长条形,最大宽高比 > 8 可见存在极细长的图片。
以上便是对于数据集的若干简单分析,并且准备出了训练要用的char2id映射文件,下面就是重头戏了,来看看我们如何将transfomer引入,来完成OCR单词识别这样的CV任务。
三、如何将transformer引入OCR
很多算法本身并不难,难的是如何思考和定义问题,把它转化到已知的解决方案上去。因此在看代码之前,我们先要聊聊,为什么transformer可以解决OCR问题,动机是什么?
首先,我们知道,transformer被广泛应用在NLP领域中,可以解决类似机器翻译这样的sequence to sequence类的问题,如下图所示:

而OCR识别任务,如下图所示,我们希望将下图识别为"Share",本质上也可以看作是一个sequence to sequence任务,只不过输入的序列信息是由图片形式表示的。

因此,如果从把OCR问题看作是一个sequence to sequence预测问题这个角度,使用transformer解决OCR问题貌似是一个非常自然和顺畅的想法,剩下的问题只是如何将图片的信息构造成transformer想要的,类似于 word embedding 形式的输入。
回到我们的任务,既然待预测的图片都是长条状的,文字基本都是水平排列,那么我们将特征图沿水平方向进行整合,得到的每一个embedding可以认为是图片纵向的某个切片的特征,将这样的特征序列交给transformer,利用其强大的attention能力来完成预测。
因此,基于以上分析,我们将模型框架的pipeline定义为下图所示的形式:
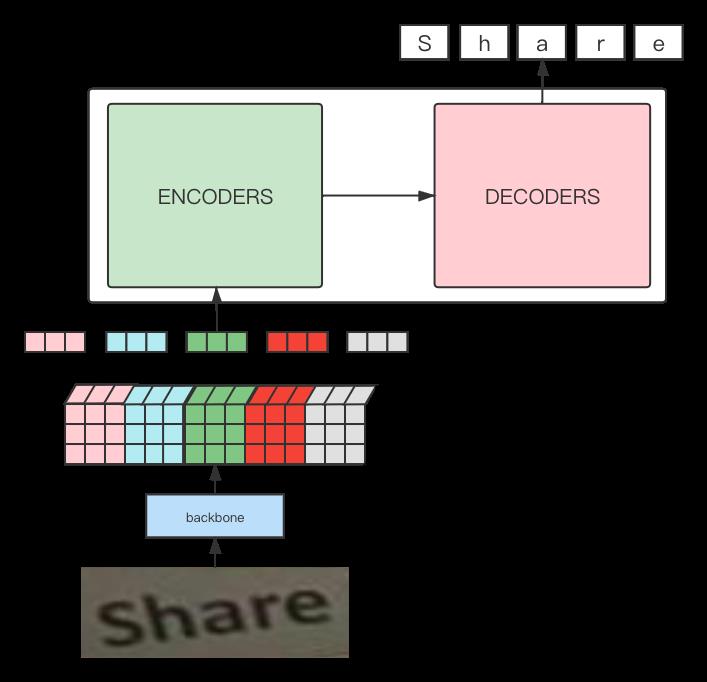
通过观察上图可以发现,整个pipeline和利用transformer训练机器翻译的流程是基本一致的,之间的差异主要是多了借助一个CNN网络作为backbone提取图像特征得到input embedding的过程。
关于构造transformer的输入embedding这部分的设计,是本文的重点,也是整个算法能够work的关键。后文会结合代码,对上面示意图中展示的相关细节进行展开讲解。
四、训练框架代码讲解
训练框架相关代码实现在 ocr_by_transformer.py 文件中
下面开始逐步讲解代码,主要有以下几个部分:
构建dataset → 图像预处理、label处理等;
模型构建 → backbone + transformer;
模型训练
推理 → 贪心解码
下面一步步来看
4.1 准备工作
首先导入后面需要用到的库
import os
import time
import copy
from PIL import Image
# 在线数据集相关包
from tensorbay import GAS
from tensorbay.dataset import Dataset
# torch相关包
import torch
import torch.nn as nn
from torch.autograd import Variable
import torchvision.models as models
import torchvision.transforms as transforms
# 导入工具类包
from analysis_recognition_dataset import load_lbl2id_map, statistics_max_len_label
from transformer import *
from train_utils import *然后设置一些基础的参数
device = torch.device('cuda') # 'cpu'或者'cuda'
nrof_epochs = 1500 # 迭代次数,1500,根据需求进行修正
batch_size = 64 # 批量大小,64,根据需求进行修正
model_save_path = './log/ex1_ocr_model.pth'在线获取图像数据,并读取图像label中字符与其id的映射字典,后续Dataset创建需要使用。
# GAS凭证
KEY = 'Accesskey-fd26cc098604c68a99d3bf7f87cd480a'
gas = GAS(KEY)
# 在线获取数据集
dataset_online = Dataset("ICDAR2015", gas)
dataset_online.enable_cache('./data') # 开启本地缓存
# 获取训练集和验证集
train_data_online = dataset_online["train"]
valid_data_online = dataset_online['valid']
# 读取label-id映射关系记录文件
lbl2id_map_path = os.path.join('./', 'lbl2id_map.txt')
lbl2id_map, id2lbl_map = load_lbl2id_map(lbl2id_map_path)
# 统计数据集中出现的所有的label中包含字符最多的有多少字符,数据集构造gt(ground truth)信息需要用到
train_max_label_len = statistics_max_len_label(train_data_online)
valid_max_label_len = statistics_max_len_label(valid_data_online)
# 数据集中字符数最多的一个case作为制作的gt的sequence_len
sequence_len = max(train_max_label_len, valid_max_label_len)4.2 Dataset构建
下面来介绍Dataset构建相关内容,首先思考下如何进行图片预处理比较合理。图片预处理方案
假设图片尺寸为
经过网络后的特征图尺寸为
基于之前对于数据集的分析,图片基本都是水平长条状的,图像内容是水平排列的字符组成的单词。那么图片空间上同一纵向切片的位置,基本只有一个字符,因此纵向分辨率不需要很大,那么取 即可;而横向的分辨率需要大一些,我们需要有不同的embedding来编码水平方向上不同字符的特征。
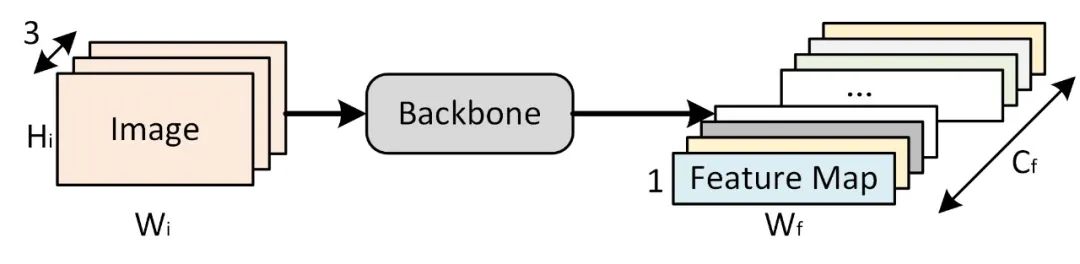
这里,我们就用最经典的resnet18网络作为backbone,由于其下采样倍数为32,最后一层特征图channel数为512,那么:
那么输入图片的宽度如何确定呢?这里给出两种方案,如下图所示:

方法一:设定一个固定尺寸,将图像保持其宽高比进行resize,右侧空余区域进行padding;
方法二:直接将原始图像强制resize到一个预设的固定尺寸。
注:这里不妨先思考下,你觉得哪种方案比较好呢?
作者选择了方法一,因为图片的宽高比和图片中单词的字符数量是大致呈正比的,如果预处理时保持住原图片的宽高比,那么特征图上每一个像素对应原图上字符区域的范围就是基本稳定的,这样或许有更好的预测效果。
这里还有个细节,观察上图你会发现,每个宽:高=1:1的区域内,基本都分布着2-3个字符,因此我们实际操作时也没有严格的保持宽高比不变,而是将宽高比提升了3倍,即先将原始图片宽度拉长到原来的3倍,再保持宽高比,将高resize到32。
注:这里建议再次停下来思考下,刚刚这个细节又是为什么?
这样做的目的是让图片上每一个字符,都有至少一个特征图上的像素与之对应,而不是特征图宽维度上一个像素,同时编码了原图中的多个字符的信息,这样我认为会对transformer的预测带来不必要的困难(仅是个人观点,欢迎讨论)。
确定了resize方案, 具体设置为多少呢?结合前面我们对数据集做分析时的两个重要指标,数据集label中最长字符数为21,最长的宽高比8.6,我们将最终的宽高比设置为 24:1,因此汇总一下各个参数的设置:
相关代码实现:
# ----------------
# 图片预处理
# ----------------
# load image
with img_data.open() as fp:
img = Image.open(fp).convert('RGB')
# 对图片进行大致等比例的缩放
# 将高缩放到32,宽大致等比例缩放,但要被32整除
w, h = img.size
ratio = round((w / h) * 3) # 将宽拉长3倍,然后四舍五入
if ratio == 0:
ratio = 1
if ratio > self.max_ratio:
ratio = self.max_ratio
h_new = 32
w_new = h_new * ratio
img_resize = img.resize((w_new, h_new), Image.BILINEAR)
# 对图片右半边进行padding,使得宽/高比例固定=self.max_ratio
img_padd = Image.new('RGB', (32*self.max_ratio, 32), (0,0,0))
img_padd.paste(img_resize, (0, 0))图像增广
图像增广并不是重点,这里我们除了上述的resize方案外,仅对图像进行常规的随机颜色变换和归一化操作。
完整代码
构建Dataset的完整代码如下:
class Recognition_Dataset(object):
def __init__(self, segment, lbl2id_map, sequence_len, max_ratio, pad=0): self.data = segment
self.lbl2id_map = lbl2id_map
self.pad = pad # padding标识符的id,默认0
self.sequence_len = sequence_len # 序列长度
self.max_ratio = max_ratio * 3 # 将宽拉长3倍
# 定义随机颜色变换
self.color_trans = transforms.ColorJitter(0.1, 0.1, 0.1)
# 定义 Normalize
self.trans_Normalize = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406], [0.229,0.224,0.225]),
])
def __getitem__(self, index):
"""
获取对应index的图像和ground truth label,并视情况进行数据增强
"""
img_data = self.data[index]
lbl_str = img_data.label.classification.category # 图像标签
# ----------------
# 图片预处理
# ----------------
# load image
with img_data.open() as fp:
img = Image.open(fp).convert('RGB')
# 对图片进行大致等比例的缩放
# 将高缩放到32,宽大致等比例缩放,但要被32整除
w, h = img.size
ratio = round((w / h) * 3) # 将宽拉长3倍,然后四舍五入
if ratio == 0:
ratio = 1
if ratio > self.max_ratio:
ratio = self.max_ratio
h_new = 32
w_new = h_new * ratio
img_resize = img.resize((w_new, h_new), Image.BILINEAR)
# 对图片右半边进行padding,使得宽/高比例固定=self.max_ratio
img_padd = Image.new('RGB', (32*self.max_ratio, 32), (0,0,0))
img_padd.paste(img_resize, (0, 0))
# 随机颜色变换
img_input = self.color_trans(img_padd)
# Normalize
img_input = self.trans_Normalize(img_input)
# ----------------
# label处理
# ----------------
# 构造encoder的mask
encode_mask = [1] * ratio + [0] * (self.max_ratio - ratio)
encode_mask = torch.tensor(encode_mask)
encode_mask = (encode_mask != 0).unsqueeze(0)
# 构造ground truth label
gt = []
gt.append(1) # 先添加句子起始符
for lbl in lbl_str:
gt.append(self.lbl2id_map[lbl])
gt.append(2)
for i in range(len(lbl_str), self.sequence_len): # 除去起始符终止符,lbl长度为sequence_len,剩下的padding
gt.append(0)
# 截断为预设的最大序列长度
gt = gt[:self.sequence_len]
# decoder的输入
decode_in = gt[:-1]
decode_in = torch.tensor(decode_in)
# decoder的输出
decode_out = gt[1:]
decode_out = torch.tensor(decode_out)
# decoder的mask
decode_mask = self.make_std_mask(decode_in, self.pad)
# 有效tokens数
ntokens = (decode_out != self.pad).data.sum()
return img_input, encode_mask, decode_in, decode_out, decode_mask, ntokens
@staticmethod
def make_std_mask(tgt, pad):
"""
Create a mask to hide padding and future words.
padd 和 future words 均在mask中用0表示
"""
tgt_mask = (tgt != pad)
tgt_mask = tgt_mask & Variable(subsequent_mask(tgt.size(-1)).type_as(tgt_mask.data))
tgt_mask = tgt_mask.squeeze(0) # subsequent返回值的shape是(1, N, N)
return tgt_mask
def __len__(self):
return len(self.data)上面的代码中还涉及到几个和label处理相关的细节,属于Transformer训练相关的逻辑,这里再简单提一下:
encode_mask
由于我们对图像进行了尺寸调整,并根据需求对图像进行了padding,而padding的位置是没有包含有效信息的,为此需要根据padding比例构造相应encode_mask,让transformer在计算时忽略这部分无意义的区域。
label处理
本实验使用的预测标签与机器翻译模型训练时的标签基本一致,因此在处理方式中差异较小。
标签处理中,将label中字符转换成其对应id,并在句子开始添加起始符,句子最后添加终止符,并在不满足sequence_len长度时在剩余位置进行padding(0补位)。
decode_mask
一般的在decoder中我们会根据label的sequence_len生成一个上三角阵形式的mask,mask的每一行便可以控制当前time_step时,只允许decoder获取当前步时之前的字符信息,而禁止获取未来时刻的字符信息,这防止了模型训练时的作弊行为。
decode_mask经过一个特殊的函数 make_std_mask() 进行生成。
同时,decoder的label制作同样要考虑上对padding的部分进行mask,所以decode_mask在label被padding对应的位置处也应该进行写成False。
生成的decode_mask如下图所示:

以上是构建Dataset的所有细节,进而我们可以构建出DataLoader供训练使用
# 构造 dataloader
max_ratio = 8 # 图片预处理时 宽/高的最大值,不超过就保比例resize,超过会强行压缩
train_dataset = Recognition_Dataset(train_data_online, lbl2id_map, sequence_len, max_ratio, pad=0)
valid_dataset = Recognition_Dataset(valid_data_online, lbl2id_map, sequence_len, max_ratio, pad=0)
# loader size info:
# --> img_input: [batch_size, c, h, w] --> [64, 3, 32, 32*8*3]
# --> encode_mask: [batch_size, h/32, w/32] --> [64, 1, 24] 本文backbone采用的32倍下采样,所以除以32
# --> decode_in: [bs, sequence_len-1] --> [64, 20]
# --> decode_out: [bs, sequence_len-1] --> [64, 20]
# --> decode_mask: [bs, sequence_len-1, sequence_len-1] --> [64, 20, 20]
# --> ntokens: [bs] --> [64]
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=4)
valid_loader = torch.utils.data.DataLoader(valid_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=4)4.3 模型构建
代码通过 make_ocr_model 和 OCR_EncoderDecoder 类完成模型结构搭建。
可以从 make_ocr_model 这个函数看起,该函数首先调用了pytorch中预训练的Resnet-18作为backbone以提取图像特征,此处也可以根据自己需要调整为其他的网络,但需要重点关注的是网络的下采样倍数,以及最后一层特征图的channel_num,相关模块的参数需要同步调整。之后调用了 OCR_EncoderDecoder 类完成transformer的搭建。最后对模型参数进行初始化。
在 OCR_EncoderDecoder 类中,该类相当于是一个transformer各基础组件的拼装线,包括 encoder 和 decoder 等,其初始参数是已存在的基本组件,其基本组件代码都在transformer.py文件中,本文将不在过多叙述。
这里再来回顾一下,图片经过backbone后,如何构造为Transformer的输入:
图片经过backbone后将输出一个维度为 [batch_size, 512, 1, 24] 的特征图,在不关注batch_size的前提下,每一张图像都会得到如下所示具有512个通道的1×24的特征图,如图中红色框标注所示,将不同通道相同位置的特征值拼接组成一个新的向量,并作为一个时间步的输入,此时变构造出了维度为 [batch_size, 24, 512] 的输入,满足Transformer的输入要求。

下面来看下完整的构造模型部分的代码:
# 模型结构
class OCR_EncoderDecoder(nn.Module):
"""
A standard Encoder-Decoder architecture.
Base for this and many other models.
"""
def __init__(self, encoder, decoder, src_embed, src_position, tgt_embed, generator):
super(OCR_EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed # input embedding module
self.src_position = src_position
self.tgt_embed = tgt_embed # ouput embedding module
self.generator = generator # output generation module
def forward(self, src, tgt, src_mask, tgt_mask):
"Take in and process masked src and target sequences."
# src --> [bs, 3, 32, 768] [bs, c, h, w]
# src_mask --> [bs, 1, 24] [bs, h/32, w/32]
memory = self.encode(src, src_mask)
# memory --> [bs, 24, 512]
# tgt --> decode_in [bs, 20] [bs, sequence_len-1]
# tgt_mask --> decode_mask [bs, 20] [bs, sequence_len-1]
res = self.decode(memory, src_mask, tgt, tgt_mask) # [bs, 20, 512]
return res
def encode(self, src, src_mask):
# feature extract
# src --> [bs, 3, 32, 768]
src_embedds = self.src_embed(src)
# 此处使用的resnet18作为backbone 输出-->[batchsize, c, h, w] --> [bs, 512, 1, 24]
# 将src_embedds由shape(bs, model_dim, 1, max_ratio) 处理为transformer期望的输入shape(bs, 时间步, model_dim)
# [bs, 512, 1, 24] --> [bs, 24, 512]
src_embedds = src_embedds.squeeze(-2)
src_embedds = src_embedds.permute(0, 2, 1)
# position encode
src_embedds = self.src_position(src_embedds) # [bs, 24, 512]
return self.encoder(src_embedds, src_mask) # [bs, 24, 512]
def decode(self, memory, src_mask, tgt, tgt_mask):
target_embedds = self.tgt_embed(tgt) # [bs, 20, 512]
return self.decoder(target_embedds, memory, src_mask, tgt_mask)
def make_ocr_model(tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1):
"""
构建模型
params:
tgt_vocab: 输出的词典大小
N: 编码器和解码器堆叠基础模块的个数
d_model: 模型中embedding的size,默认512
d_ff: FeedForward Layer层中embedding的size,默认2048
h: MultiHeadAttention中多头的个数,必须被d_model整除
dropout: dropout的比率
"""
c = copy.deepcopy
# torch中预训练的resnet18作为特征提取网络, backbone
backbone = models.resnet18(pretrained=True)
backbone = nn.Sequential(*list(backbone.children())[:-2]) # 去掉最后两个层 (global average pooling and fc layer)
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
# 构建模型
model = OCR_EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N),
backbone,
c(position),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab)) # 此处的generator并没有在类内调用
# Initialize parameters with Glorot / fan_avg.
for child in model.children():
if child is backbone:
# 将backbone的权重设为不计算梯度
for param in child.parameters():
param.requires_grad = False
# 预训练好的backbone不进行随机初始化,其余模块进行随机初始化
continue
for p in child.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model通过上述的两个类,可以方便构建transformer模型:
# build model
# use transformer as ocr recognize model
# 此处构建的ocr_model不含有Generator
tgt_vocab = len(lbl2id_map.keys())
d_model = 512
ocr_model = make_ocr_model(tgt_vocab, N=5, d_model=d_model, d_ff=2048, h=8, dropout=0.1)
ocr_model.to(device)4.4 模型训练
模型训练之前,还需要定义模型评判准则、迭代优化器等。本实验在训练时,使用了标签平滑(label smoothing)、网络训练热身(warmup)等策略,以上策略的调用函数均在train_utils.py文件中,此处不涉及以上两种方法的原理及代码实现。
label smoothing可以将原始的硬标签转化为软标签,从而增加模型的容错率,提升模型泛化能力。代码中 LabelSmoothing() 函数实现了label smoothing,同时内部使用了相对熵函数计算了预测值与真实值之间的损失。
warmup策略能够有效控制模型训练过程中的优化器学习率,自动化的实现模型学习率由小增大再逐渐下降的控制,帮助模型在训练时更加稳定,实现损失的快速收敛。代码中 NoamOpt() 函数实现了warmup控制,采用的Adam优化器,实现学习率随迭代次数的自动调整。
# train prepare
criterion = LabelSmoothing(size=tgt_vocab, padding_idx=0, smoothing=0.0) # label smoothing
optimizer = torch.optim.Adam(ocr_model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9)
model_opt = NoamOpt(d_model, 1, 400, optimizer) # warmup模型训练过程的代码如下所示,每训练10个epoch便进行一次验证,单个epoch的计算过程封装在 run_epoch() 函数中。
# train & valid ...
for epoch in range(nrof_epochs):
print(f"\\nepoch epoch")
print("train...") # 训练
ocr_model.train()
loss_compute = SimpleLossCompute(ocr_model.generator, criterion, model_opt)
train_mean_loss = run_epoch(train_loader, ocr_model, loss_compute, device)
if epoch % 10 == 0:
print("valid...") # 验证
ocr_model.eval()
valid_loss_compute = SimpleLossCompute(ocr_model.generator, criterion, None)
valid_mean_loss = run_epoch(valid_loader, ocr_model, valid_loss_compute, device)
print(f"valid loss: valid_mean_loss")
# save model
torch.save(ocr_model.state_dict(), './trained_model/ocr_model.pt')SimpleLossCompute() 类实现了transformer输出结果的loss计算。在使用该类直接计算时,类需要接收(x, y, norm)三个参数,x为decoder输出的结果,y为标签数据,norm为loss的归一化系数,用batch中所有有效token数即可。由此可见,此处才正完成transformer所有网络的构建,实现数据计算流的流通。
run_epoch() 函数内部完成了一个epoch训练的所有工作,包括数据加载、模型推理、损失计算与方向传播,同时将训练过程信息进行打印。
def run_epoch(data_loader, model, loss_compute, device=None):
"Standard Training and Logging Function"
start = time.time()
total_tokens = 0
total_loss = 0
tokens = 0
for i, batch in enumerate(data_loader):
img_input, encode_mask, decode_in, decode_out, decode_mask, ntokens = batch
img_input = img_input.to(device)
encode_mask = encode_mask.to(device)
decode_in = decode_in.to(device)
decode_out = decode_out.to(device)
decode_mask = decode_mask.to(device)
ntokens = torch.sum(ntokens).to(device)
out = model.forward(img_input, decode_in, encode_mask, decode_mask)
# out --> [bs, 20, 512] 预测结果
# decode_out --> [bs, 20] 实际结果
# ntokens --> 标签中实际有效字符
loss = loss_compute(out, decode_out, ntokens) # 损失计算
total_loss += loss
total_tokens += ntokens
tokens += ntokens
if i % 50 == 1:
elapsed = time.time() - start
print("Epoch Step: %d Loss: %f Tokens per Sec: %f" %
(i, loss / ntokens, tokens / elapsed))
start = time.time()
tokens = 0
return total_loss / total_tokens
class SimpleLossCompute:
"A simple loss compute and train function."
def __init__(self, generator, criterion, opt=None):
self.generator = generator
self.criterion = criterion
self.opt = opt
def __call__(self, x, y, norm):
"""
norm: loss的归一化系数,用batch中所有有效token数即可
"""
# x --> out --> [bs, 20, 512] 预测结果
# y --> decode_out --> [bs, 20] 实际结果
# norm --> ntokens --> 标签中实际有效字符
x = self.generator(x)
# label smoothing需要对应维度变化
x_ = x.contiguous().view(-1, x.size(-1)) # [20bs, 512]
y_ = y.contiguous().view(-1) # [20bs]
loss = self.criterion(x_, y_)
loss /= norm
loss.backward()
if self.opt is not None:
self.opt.step()
self.opt.optimizer.zero_grad()
#return loss.data[0] * norm
return loss.item() * norm4.5 贪心解码
方便起见,我们使用最简单的贪心解码直接进行OCR结果预测。因为模型每一次只会产生一个输出,我们选择输出的概率分布中的最高概率对应的字符为本次预测的结果,然后预测下一个字符,这就是所谓的贪心解码,见代码中 greedy_decode() 函数。
实验中分别将每一张图像作为模型的输入,逐张进行贪心解码统计正确率,并最终给出了训练集和验证集各自的预测准确率。
# 训练结束,使用贪心的解码方式推理训练集和验证集,统计正确率
ocr_model.eval()
print("\\n------------------------------------------------")
print("greedy decode trainset")
total_img_num = 0
total_correct_num = 0
for batch_idx, batch in enumerate(train_loader):
img_input, encode_mask, decode_in, decode_out, decode_mask, ntokens = batch
img_input = img_input.to(device)
encode_mask = encode_mask.to(device)
# 获取单张图像信息
bs = img_input.shape[0]
for i in range(bs):
cur_img_input = img_input[i].unsqueeze(0)
cur_encode_mask = encode_mask[i].unsqueeze(0)
cur_decode_out = decode_out[i]
# 贪心解码
pred_result = greedy_decode(ocr_model, cur_img_input, cur_encode_mask, max_len=sequence_len, start_symbol=1, end_symbol=2)
pred_result = pred_result.cpu()
# 判断预测是否正确
is_correct = judge_is_correct(pred_result, cur_decode_out)
total_correct_num += is_correct
total_img_num += 1
if not is_correct:
# 预测错误的case进行打印
print("----")
print(cur_decode_out)
print(pred_result)
total_correct_rate = total_correct_num / total_img_num * 100
print(f"total correct rate of trainset: total_correct_rate%")
# 与训练集解码代码相同
print("\\n------------------------------------------------")
print("greedy decode validset")
total_img_num = 0
total_correct_num = 0
for batch_idx, batch in enumerate(valid_loader):
img_input, encode_mask, decode_in, decode_out, decode_mask, ntokens = batch
img_input = img_input.to(device)
encode_mask = encode_mask.to(device)
bs = img_input.shape[0]
for i in range(bs):
cur_img_input = img_input[i].unsqueeze(0)
cur_encode_mask = encode_mask[i].unsqueeze(0)
cur_decode_out = decode_out[i]
pred_result = greedy_decode(ocr_model, cur_img_input, cur_encode_mask, max_len=sequence_len, start_symbol=1, end_symbol=2)
pred_result = pred_result.cpu()
is_correct = judge_is_correct(pred_result, cur_decode_out)
total_correct_num += is_correct
total_img_num += 1
if not is_correct:
# 预测错误的case进行打印
print("----")
print(cur_decode_out)
print(pred_result)
total_correct_rate = total_correct_num / total_img_num * 100
print(f"total correct rate of validset: total_correct_rate%")greedy_decode() 函数实现。
# greedy decode
def greedy_decode(model, src, src_mask, max_len, start_symbol, end_symbol):
memory = model.encode(src, src_mask)
# ys代表目前已生成的序列,最初为仅包含一个起始符的序列,不断将预测结果追加到序列最后
ys = torch.ones(1, 1).fill_(start_symbol).type_as(src.data).long()
for i in range(max_len-1):
out = model.decode(memory, src_mask,
Variable(ys),
Variable(subsequent_mask(ys.size(1)).type_as(src.data)))
prob = model.generator(out[:, -1])
_, next_word = torch.max(prob, dim = 1)
next_word = next_word.data[0]
next_word = torch.ones(1, 1).type_as(src.data).fill_(next_word).long()
ys = torch.cat([ys, next_word], dim=1)
next_word = int(next_word)
if next_word == end_symbol:
break
#ys = torch.cat([ys, torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=1)
ys = ys[0, 1:]
return ys
def judge_is_correct(pred, label):
# 判断模型预测结果和label是否一致
pred_len = pred.shape[0]
label = label[:pred_len]
is_correct = 1 if label.equal(pred) else 0
return is_correct运行下面的命令即可一键开启训练:
python ocr_by_transformer.py
训练日志如下所示:
epoch 0
train...
Epoch Step: 1 Loss: 5.142612 Tokens per Sec: 852.649109
Epoch Step: 51 Loss: 3.064528 Tokens per Sec: 2709.471436
valid...
Epoch Step: 1 Loss: 3.018526 Tokens per Sec: 1413.900391
valid loss: 2.7769546508789062
epoch 1
train...
Epoch Step: 1 Loss: 3.440590 Tokens per Sec: 1303.567993
Epoch Step: 51 Loss: 2.711708 Tokens per Sec: 2743.414307
...
epoch 1499
train...
Epoch Step: 1 Loss: 0.005739 Tokens per Sec: 1232.602783
Epoch Step: 51 Loss: 0.013249 Tokens per Sec: 2765.866211
------------------------------------------------
greedy decode trainset
----
tensor([17, 32, 18, 19, 31, 50, 30, 10, 30, 10, 17, 32, 41, 55, 55, 55, 2, 0,
0, 0])
tensor([17, 32, 18, 19, 31, 50, 30, 10, 30, 10, 17, 32, 41, 55, 55, 55, 55, 55,
55, 55])
----
tensor([17, 32, 18, 19, 31, 50, 30, 10, 17, 32, 41, 55, 55, 2, 0, 0, 0, 0,
0, 0])
tensor([17, 32, 18, 19, 31, 50, 30, 10, 17, 32, 41, 55, 55, 55, 55, 2])
total correct rate of trainset: 99.95376791493297%
------------------------------------------------
greedy decode validset
----
tensor([10, 11, 28, 27, 25, 11, 47, 45, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0])
tensor([10, 11, 28, 27, 25, 11, 62, 2])
...
tensor([20, 12, 24, 35, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0])
tensor([20, 12, 21, 12, 22, 23, 34, 2])
total correct rate of validset: 92.72088353413655%总结
以上便是本文的全部内容了,恭喜你阅读到了这里 !
!
本文我们首先介绍了ICDAR2015中的一个单词识别任务数据集,然后对数据的特点进行了简单分析,并构建了识别用的字符映射关系表。之后,我们重点介绍了将transformer引入来解决OCR任务的动机与思路,并结合代码详细介绍了细节,最后我们大致过了一些训练相关的逻辑和代码。
这篇主要是帮助大家打开思路,了解transformer在CV中除了作为backbone以外的其他应用点,关于Tranformer模型本身的实现代码参考了The Annotated Transformer,关于如何应用到OCR部分,完全是结合作者个人理解实现的,不能保证一定能应用到更复杂的工程问题中。关于文中的任何细节,如果有任何疑问,欢迎联系我们一起讨论,如有错误,也恳请指出。
希望大家阅读后有所收获!

阅读原文可获取数据集,和作者交流
以上是关于用Transformer实现OCR字符识别!的主要内容,如果未能解决你的问题,请参考以下文章
实战 | OpenCV+OCR实现环形文字识别实例(详细步骤 + 代码)