Python+OpenCV+Tesseract实现OCR字符识别
Posted Thomas_221126
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python+OpenCV+Tesseract实现OCR字符识别相关的知识,希望对你有一定的参考价值。
目录
一、OCR是什么
光学字符识别(英语:Optical Character Recognition,OCR)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。
二、使用步骤
1.下载tesseract
首先要下载tesseract:Index of /tesseract https://digi.bib.uni-mannheim.de/tesseract/
https://digi.bib.uni-mannheim.de/tesseract/
进入下载页面,可以看到各种exe文件,其中文件名中带有dev的为开发版,不带dev的为稳定版,读者可以按需下载,我这里选择下载5.2.0的版本。

下载完成后,双击安装,值得注意的是,在安装过程到此页面时,需要勾选“Additional language data(download) ”选项来安装OCR支持识别的语言包,这样OCR便可以识别多国语言。

2.安装pytesseract
为了能在python中使用tesseract的功能,需要pip安装pytesseract:
pip install pytesseract若安装缓慢,可以使用镜像进行安装:
pip install pytesseract -i https://pypi.douban.com/simple3.验证测试
接下来,需要验证是否能正常使用OCR功能。使用如下图片为例进行测试:

测试代码:
from PIL import Image
import pytesseract
text = pytesseract.image_to_string(Image.open('OCR_test.png'), lang='chi_sim')
print(text)
我们首先利用Image读取了图片文件,然后调用了pytesseract的image_to_string()方法,再将其识别结果输出。
值得注意的是,image_to_string()方法默认只识别英文,若还要识别中文,添加lang=’chi_sim’参数即可。此外,有可能中文识别出来了,但是乱码,需要相应地将text转换为你所用的中文编码方式,如:text.decode("utf8")就可以了。
代码运行结果如下:
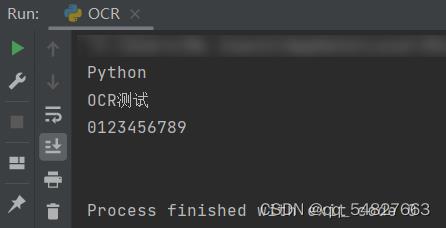
如果遇到报错找不到pytesseract,不要慌,问题不大:

解决方案1:
1.找到python的安装路径下的pytesseract:

2.用文本编辑器打开,查找tesseract_cmd
将原来的 tesseract_cmd = 'tesseract' 改为: tesseract_cmd = 'OCR的安装路径下的tessract.exe'
例如我的是 tesseract_cmd = r'D:\\software\\Tesseract-OCR\\tesseract.exe'
注意需要对路径中的斜杠进行转义。

解决方案2:
增加一句代码即可:
from PIL import Image
import pytesseract
# 使用此行代码进行设置,可以不改动pytesseract.py中的源码
pytesseract.pytesseract.tesseract_cmd = r'D:\\software\\Tesseract-OCR\\tesseract.exe'
text = pytesseract.image_to_string(Image.open('OCR_test.png'), lang='chi_sim')
print(text)
结语
至此,便完成了tesseract的安装与使用,就可以进行OCR识别了。
若识别效果不好,可二值化图像并消除噪声后再识别,此外,image_to_string()方法还有几个其它的参数,还可尝试更改参数以获得更好的识别效果,参数说明可看下面这篇文章:
参考
- 光学字符识别 - 维基百科,自由的百科全书 (wikipedia.org)
- wxPython利用pytesser模块实现图片文字识别
- Python关于tesseract 安装及使用 - 知乎 (zhihu.com)
以上是关于Python+OpenCV+Tesseract实现OCR字符识别的主要内容,如果未能解决你的问题,请参考以下文章