Spark编程实战-词频统计
Posted 唔仄lo咚锵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark编程实战-词频统计相关的知识,希望对你有一定的参考价值。
文章目录

Spark安装可参考:Spark集群安装-基于hadoop集群
RDD
RDD(Rseilient Distributed Datasets)是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行运算,提供了一种高度受限的共享内存模型。
RDD是Spark的主要操作对象,RDD可以通过多种方式灵活创建,可通过导入外部数据源建立,或从其他的RDD转化而来。Spark程序中必须创建一个SparkContext对象作为程序的入口,负责创建RDD、启动任务等。启动spark-shell后会自动创建该对象,可通过sc变量访问。
RDD支持两种类型的操作:
- 行动(Action)
在数据集上进行运算,返回计算值。 - 转换(Transformation)
基于现有数据集创建一个新的数据集。
可以通过官网查看API:
http://spark.apache.org/docs/latest/api/scala/org/apache/spark/index.html
列举部分常用的:
| ActionAPI | 说明 |
|---|---|
| count() | 返回数据集中原始个数 |
| collect() | 以数组形式返回数据集中所有元素 |
| first() | 返回数据集第一个元素 |
| take(n) | 以数组形式返回数据集前n个元素 |
| reduce(func) | 通过func函数聚合数据集中元素 |
| foreach(func) | 将数据集中每个元素传递到func函数中运行 |
| TransformationAPI | 说明 |
|---|---|
| filter(func) | 筛选满足func函数的元素,并返回一个新的数据集 |
| map(func) | 将元素传递到func函数,并将结果返回为一个新的数据集 |
| flatMap(func) | 与map()相似,但每个输入元素都可以映射到0或多个输出结果 |
| groupByKey(func) | 应用于<K,V>键值对的数据集时,返回一个新的<K,Iterable<V>>形式的数据集 |
| reduceByKey(func) | 应用于<K,V>键值对的数据集时,返回一个新的(K,V)形式数据集,每个值是将key传递到func函数中进行聚合 |
(
插播反爬信息)博主CSDN地址:https://wzlodq.blog.csdn.net/
例题
用SPARK API编程(可用SCALA或者JAVA),将三个文本分别加载为RDD(或DataFrame),然后综合统计三个文本中的各个单词数量总和。
1.txt
There is no standard definition of game feel. As players and game designers, we have some beginnings of common language, but we have never collectively defined game feel above what’s necessary for discussing a specific game. We can talk about the feel of a game as being “floaty” or “responsive” or “loose,” and these descriptions may even have meaning across games, as in “We need to make our game feel more responsive, like Asteroids.” But if I ask 10 working game designers what game feel is–as I did in preparation for writing this book–I get 10 different answers. And here’s the thing: each of these answers is correct. Each answer describes a different facet, a different area, which is crucial to game feel
2.txt
To many designers, game feel is about intuitive controls. A good-feeling game is one that lets players do what they want when they want, without having to think too much about it. Good game feel is about making a game easy to learn but difficult to master. The enjoyment is in the learning, in the perfect balance between player skill and the challenge presented. Feelings of mastery bring their own intrinsic rewards.
3.txt
Another camp focuses on physical interactions with virtual objects. It’s all about timing, about making players really feel the impact, about the number of frames each move takes, or about how polished the interactions are.
spark-shell
cd /usr/local #新建上述三个文件
vi 1.txt
vi 2.txt
vi 3.txt
source /etc/profile
$HADOOP_HOME/sbin/./start-all.sh #起动hadoop集群
$SPARK_HOME/sbin/./start-all.sh #起动spark集群
$SPARK_HOME/bin/./spark-shell #进入spark-shell
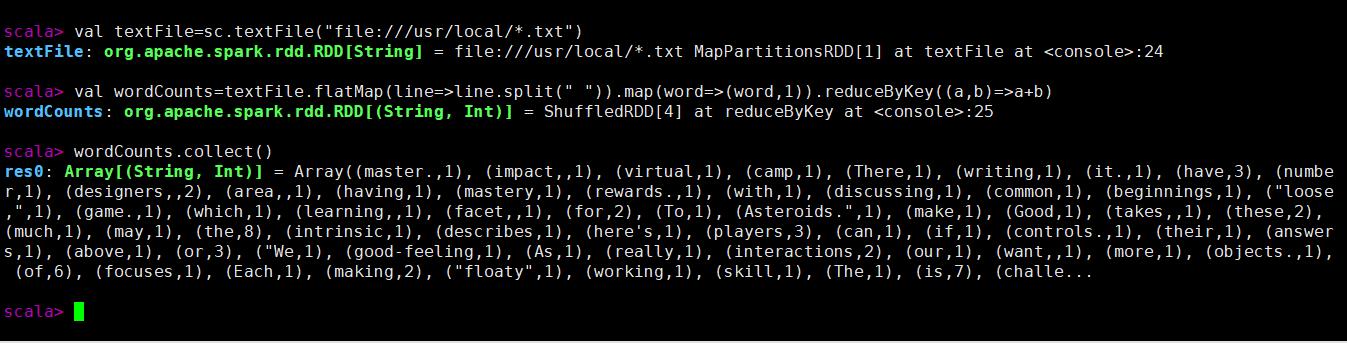
val textFile=sc.textFile("file:///usr/local/*.txt")
val wordCounts=textFile.flatMap(line=>line.split(" ")).map(word=>(word,1)).reduceByKey((a,b)=>a+b)
wordCounts.collect()
用sbt编译打包Scala和用Maven编译打包Java日后再更吧(咕咕咕)。
原创不易,请勿转载(
本不富裕的访问量雪上加霜)
博主首页:https://wzlodq.blog.csdn.net/
来都来了,不评论两句吗👀
如果文章对你有帮助,记得一键三连❤
以上是关于Spark编程实战-词频统计的主要内容,如果未能解决你的问题,请参考以下文章