MapReduce编程实战-词频统计结果存入mysql数据库
Posted toFuture
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce编程实战-词频统计结果存入mysql数据库相关的知识,希望对你有一定的参考价值。
摘要
通过实现MapReduce计算结果保存到MySql数据库过程,掌握多种方式保存计算结果的技术,加深了对MapReduce的理解;
Api 文档地址:http://hadoop.apache.org/docs/current/api/index.html
maven资源库:https://mvnrepository.com/repos/central ##用于配置pom.xml的时候查询资源
1.master主机安装mysql
参见文章:https://www.cnblogs.com/hemomo/p/11942661.html
创建maven项目,项目名称hdfs,这里不再说明。
2.修改pom.xml文件
红色部分为增加内容:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.scitc</groupId> <artifactId>hdfs</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>jar</packaging> <name>hdfs</name> <url>http://maven.apache.org</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <hadoop.version>2.7.5</hadoop.version> </properties> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>3.8.1</version> <scope>test</scope> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-common</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-jobclient</artifactId> <version>${hadoop.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-yarn-common</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.27</version> <scope>compile</scope> <optional>true</optional> </dependency> <dependency> <groupId>jdk.tools</groupId> <artifactId>jdk.tools</artifactId> <version>1.8</version> <scope>system</scope> <systemPath>${JAVA_HOME}/lib/tools.jar</systemPath> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> <archive> <manifest> <mainClass></mainClass> </manifest> </archive> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build> </project>
2. 自定义数据类型(WordCountTb)
Hadoop给封装了许多输入输出的类型,如LongWritable、Text、 IntWritable、NullWritable等基础类型,这些类型和Java的基本数据类型一样,不能满足实际的业务需求;因此,我们可以通关过自定义输入输出类型来实现。
在com.scitc.hdfs下新建WordCountTb.java类:
代码如下:
package com.scitc.hdfs;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.lib.db.DBWritable;
public class WordCountTb implements Writable, DBWritable {
//定义字段和构造函数
String name;
int value;
public WordCountTb(String name, int value) {
this.name = name;
this.value = value;
}
//获取数据库表的字段值
@Override
public void readFields(ResultSet resultSet) throws SQLException {
// TODO Auto-generated method stub
this.name = resultSet.getString(1);
this.value = resultSet.getInt(2);
}
@Override
public void write(PreparedStatement statement) throws SQLException {
// TODO Auto-generated method stub
statement.setString(1, this.name);
statement.setInt(2, this.value);
}
@Override
public void write(DataOutput out) throws IOException {
// TODO Auto-generated method stub
out.writeUTF(name);
out.writeInt(value);
}
@Override
public void readFields(DataInput in) throws IOException {
// TODO Auto-generated method stub
name = in.readUTF();
value = in.readInt();
}
}
3.数据库属性类StaticConstant
普通类中定义常量://参考https://blog.csdn.net/rlnlo2pnefx9c/article/details/81277528
在com.scitc.hdfs下新建StaticConstant.java类
代码如下:
package com.scitc.hdfs; public class StaticConstant { public static final String jdbcDriver = "com.mysql.jdbc.Driver"; public static final String jdbcUrl = "jdbc:mysql://192.168.56.110:3306/test?useUnicode=true&characterEncoding=utf8"; public static final String jdbcUser = "root"; public static final String jdbcPassword = "bigData@123"; }
3.编写MapReduce类WordCountToDb
在com.scitc.hdfs下新建WordCountToDb.java类
代码如下:
package com.scitc.hdfs;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
public class WordCountToDb {
static class Maps extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 将读入的每行数据按空格切分
String[] dataArr = value.toString().split(" ");
if(dataArr.length>0){
// 将每个单词作为map的key,value设置为1
for (String word : dataArr) {
context.write(new Text(word), one);}
}
}
}
static class Reduces extends Reducer<Text, IntWritable, WordCountTb, WordCountTb> {
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
context.write(new WordCountTb(key.toString(), sum), null);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1:实例化Configuration类、配置数据库类DBConfiguration、新建一个job任务
Configuration conf = new Configuration();
DBConfiguration.configureDB(conf, StaticConstant.jdbcDriver,
StaticConstant.jdbcUrl, StaticConstant.jdbcUser, StaticConstant.jdbcPassword);
Job job = Job.getInstance(conf, "word-count");
//2:设置jar加载的路径
job.setJarByClass(WordCountToDb.class);
//3:设置Map类和reduce类
job.setMapperClass(Maps.class);
job.setReducerClass(Reduces.class);
//4:设置Map输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5:设置reduce最终输出kv类型
job.setOutputKeyClass(WordCountTb.class);
job.setOutputValueClass(WordCountTb.class);
//6:设置输入路径
String inputPath = "hdfs://master:9000/he/input/wordcount.txt";
// 如果有传入文件地址,接收参数为输入文件地址
if(args != null && args.length > 0){
inputPath = args[0];
}
FileInputFormat.addInputPath(job, new Path(inputPath));
//7:设置数据库输出格式、输出到哪些表、字段
job.setOutputFormatClass(DBOutputFormat.class);
DBOutputFormat.setOutput(job, "wordcount", "name", "value");
//本地提交没问题,在集群提交会出现,Error: java.io.IOException: com.mysql.jdbc.Driver
job.addArchiveToClassPath(new Path("hdfs://master:9000/lib/mysql/mysql-connector-java-5.1.27.jar"));
//8:提交任务
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}
4:本地运行程序
本地测试非常方便调试。省去排除错误的时候,来回打包在集群运行。
在WordCountToDb类的编辑界面上右击鼠标,在弹出的菜单中选中Run As -> Java Application开始运行该类。
eclipse的console输出如下:
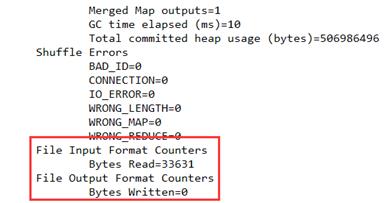
打开数据库wordcount表查看运行结果:

5:打包、上传、在集群中运行
运行之前记得删除掉mysql中表wordcount里之前本地运行生成的数据
1.打包
项目名hdfs上右键>>Run As>>Maven clean
项目名hdfs上右键>>Run As>>Maven install
2.上传
项目根目录下的target文件夹中找到hdfs-0.0.1-SNAPSHOT.jar,改文件名为hdfs1.jar,上传到master的/opt/data/目录中
3.用hadoop jar 命令运行hdfs1.jar包
cd /opt/data
hadoop jar hdfs1.jar com.scitc.hdfs. WordCountToDb
##命令语法:hadoop jar jar包 类的全名称
查看结果:
在集群中运行,出现问题:Error: java.io.IOException: com.mysql.jdbc.Driver
解决方法1:
pom配置的插件maven-assembly-plugin
在mavne install之后有两个jar包
一个hdfs-0.0.1-SNAPSHOT-jar-with-dependencies.jar 包含所有依赖
因此在集群运行这个jar包,也会正常执行。 ##测试通过
但是这样jar包40多M,太大了。
解决方法2:(推荐)
把jar包传到集群上,命令如下
hadoop fs –mkdir –p /lib/mysql ##创建目录
hadoop fs -put mysql-connector-java-5.1.27.jar /lib/mysql ##上传驱动到hdfs的lib/mysql目录中
在WordCountToDb.java中提交任务代码前。添加如下代码:
job.addArchiveToClassPath(new Path("hdfs://master:9000/lib/mysql/mysql-connector-java-5.1.27.jar"));
//8:提交任务
boolean result = job.waitForCompletion(true);
查看结果:
查看集群执行结果:没问题,输出为0字节,因为我们是输出到mysql的。

查看mysql数据库:

============================
问题集:
问题1:集群中运行jar包,报错:Error: java.io.IOException: com.mysql.jdbc.Driver
解决参考资料:https://www.cnblogs.com/codeOfLife/p/5464613.html
修改说明:
2020-02-22,增加WordCountToDb代码
以上是关于MapReduce编程实战-词频统计结果存入mysql数据库的主要内容,如果未能解决你的问题,请参考以下文章