Spark算法实例:词频统计
Posted 清华计算机学堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark算法实例:词频统计相关的知识,希望对你有一定的参考价值。
Spark支持Scala、Python、Java、R等编程语言。Scala作为Spark的原生语言,代码优雅、简洁而且功能完善,很多开发者都比较认可,它是业界广泛使用的Spark程序开发语言。Spark也提供了Python的编程模型PySpark,使得Python可以作为Spark开发语言之一。尽管现在PySpark还不能支持所有的Spark API,但是以后的支持度会越来越高。Java 也可以作为Spark的开发语言之一,但是相对于前两者而已,逊色了很多,但是Java8却很好地适应了Spark的开发风格。无论使用Scala、Python还是Java编程程序都需要遵循Spark编程模型,考虑对Spark平台支持的有力程度来说,Spark对Scala语言的支持是最好的,因为它有最丰富的和最易用的编程接口。
01
词频统计描述
词频统计(WordCount)的主要功能是统计文本中某单词出现的次数,其形式如图8-5所示。
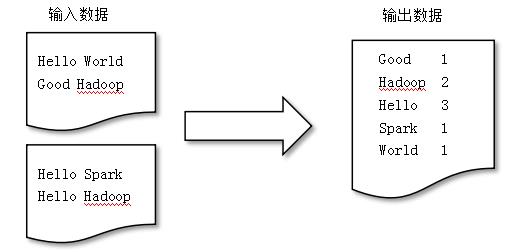
▍图8-5 词频统计
02
词频统计编程
1. 单词文件sw.txt内容如下:
Spark Python Scala
Hadoop Spark Python2. 上传sw.txt到HDFS:
# hdfs dfs -mkdir /input
# hdfs dfs -put sw.txt /input3. 运行Scala-IDE,创建项目“WCPG”和类“WordCount.scala”,如图8-6所示。
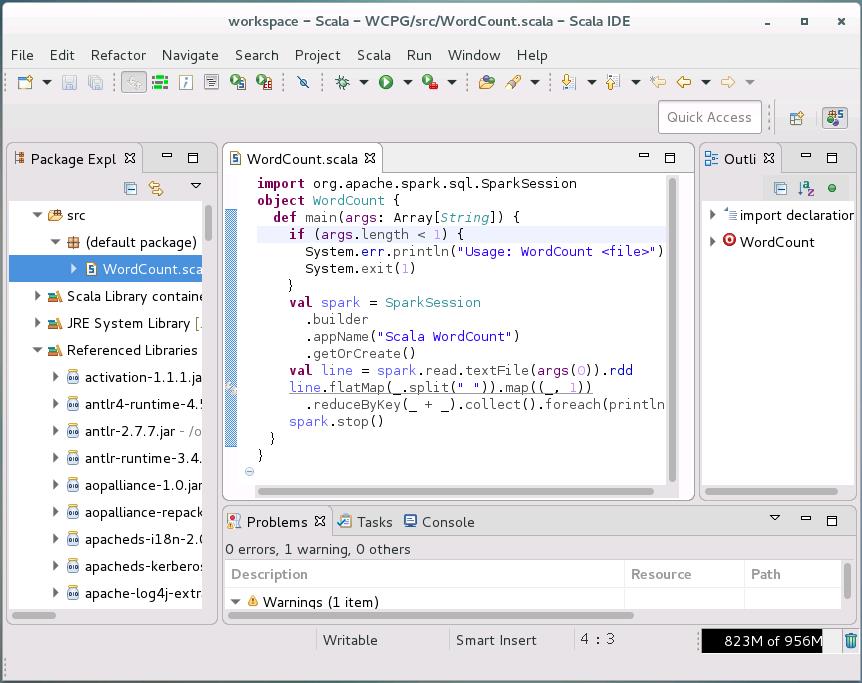
▍图8-6 Scala-IDE集成环境
Scala语言编写的WordCount.scala代码如下:
import org.apache.spark.sql.SparkSession
object WordCount {
def main(args: Array[String]) {
if (args.length < 1) {
System.err.println("Usage: WordCount <file>")
System.exit(1)
}
val spark = SparkSession
.builder
.appName("Scala WordCount")
.getOrCreate()
val line = spark.read.textFile(args(0)).rdd
line.flatMap(_.split(" ")).map((_, 1))
.reduceByKey(_ + _).collect().foreach(println)
spark.stop()
}
}4. 在Scala-IDE中导出“WCPG.jar”。
5. 运行WCPG.jar:
# spark-submit --master spark://master:7077 \
--class WordCount WCPG.jar /input \
> WordCount.txt6. 查看WordCount运行结果如下:
# cat WordCount.txt
(Spark,2)
(Python,2)
(Scala,1)
(Hadoop,1)7. Python语言编写的WordCount.py代码如下:
from __future__ import print_function
import sys
from operator import add
from pyspark.sql import SparkSession
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: wordcount <file>", file=sys.stderr)
exit(-1)
spark = SparkSession\
.builder\
.appName("PythonWordCount")\
.getOrCreate()
lines = spark.read.text(sys.argv[1]).rdd.map(lambda r: r[0])
counts = lines.flatMap(lambda x: x.split(' ')) \
.map(lambda x: (x, 1)) \
.reduceByKey(add)
output = counts.collect()
for (word, count) in output:
print("%s: %i" % (word, count))
spark.stop()8. 运行WordCount.py,操作如下:
# spark-submit --master spark://master:7077 \
--name PythonWC WordCount.py /input \
> WordCount.txt9. 查看WordCount.py运行结果如下:
# cat WordCount.txt
Python: 2
Spark: 2
Hadoop: 1
Scala: 103
参考书籍
《大数据技术与应用-微课视频版》
ISBN:978-7-302-53843-1
肖政宏 李俊杰 谢志明 编著
定价:49.80元

以上是关于Spark算法实例:词频统计的主要内容,如果未能解决你的问题,请参考以下文章