百面机器学习之特征工程
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了百面机器学习之特征工程相关的知识,希望对你有一定的参考价值。
🍁百面机器学习系列主要是针对面试算法的一些问题,该系列主要面对面试中的一些机器学习算法问题👇:
目录
1.统计学习和机器学习的联系
发现大家一直分不清统计学习和机器学习的关系,本文先解释这两者的联系:
- 统计学习是关于计算机基于数据构建概率统计模型并运用模型对数据进行预测和分析的一门学科。统计学习也称为统计机器学习。
- 统计机器学习的特点:统计学习以计算机及网络为平台,是建立在计算机网络上的;统计学习以数据作为研究对象,是数据驱动的学科;统计学习的目的是对数据进行预测与分析;统计学习是概率论、统计学、信息论、计算理论、最优化理论及计算机科学等多个领域的交叉学科,并且在发展中逐步形成独自的理论体系和方法论。
- 现在人们提及的机器学习往往是指统计机器学习方法。
2.为什么需要对数值类型的特征做归一化?
对数值类型的特征做归一化可以将所有特征都统一到一个大致相等的数值区内。最常用的方法主要有以下两种。
- 线性归一化(Min-Max Scaling)。它对原始数据进行线性变换,使结果映射到[0,1]的范围,实现对原始数据的等比缩放。归一化公式如下:
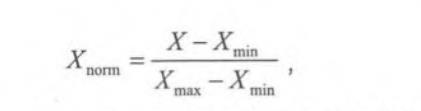
其中X为原始数据, X m a x X_{max} Xmax 和 X m i n X_{min} Xmin分别为数据的最大值和最小值。 - 零均值归一化(Z-Score Normalization)。它会将原始数据映射到0,标准差为1的分布上。具体来说,假设原始特征的均值为
μ
\\mu
μ,标准差为
σ
\\sigma
σ,那么归一化公式定义为:
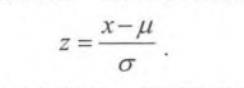
为什么需要对数值型特征做归一化呢?我们不妨借助随机梯度下降的实例来说明归一化的重要性。假设有两种数值型特征 , X 1 X_{1} X1的取值范围为[0, 10], X 2 X_{2} X2的取值范围为 [0, 3] .在学习速率相同的情况下, X 1 X_{1} X1的更新速度会大于 X 2 X_{2} X2,需要较多的迭代才能找到最优解。如果将 X 1 X_{1} X1和 X 2 X_{2} X2归一化到相同的数值区间后,优化目标的等值图会变成图中的圆形, X 1 X_{1} X1和 X 2 X_{2} X2的更新速度变得更为一致,容易更快地通过梯度下降找到最优解。
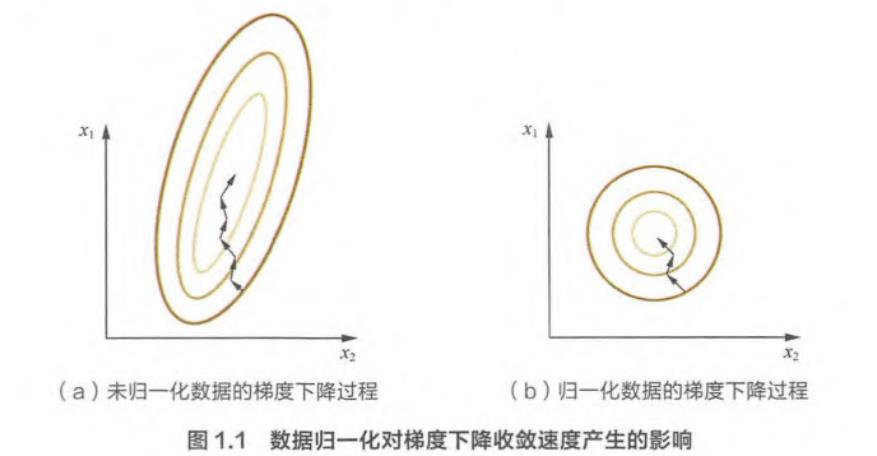
线性归一化会改变数据的分布,而零均值归一化不会改变原始数据的分布
3.类别型特征的转换
类别型特征( Categorical Feature )主要是指性别( 男、女 )、血型( A、B、AB、O)等只在有限选项内取值的特征。类别型特征原始输入通常是字符串形式,除了决策树等少数模型能直接处理字符串形式的输入,对于逻辑回归、支持向量机等模型来说,类别型特征必须经过处理转换成数值型特征才能正确工作。
3.1 序号编码( Ordinal Encoding )
序号编码通常用于处理类别间具有大小关系的数据。例如成绩,可以分为低、中、高三档,并且存在 “高>中> 低” 的排序关系。序号编码会按照大小关系对类别型特征赋予一个数值10 , 例如高表示为 3 、中表示为 2、低表示为 1 , 转换后依然保留了大小关系。
3.2 独热编码( One-hot Encoding )
独热编码通常用于处理类别间不具有大小关系的特征。例如血型, —共有 4 个取值( A型血、B型血、 AB型血、O型血 ),独热编码会把血型变成一个 4 维稀疏向量,A型血表示为( 1 ,0, 0, 0 ) , B型血表示为( 0,1,0, 0 ) , AB型表示为( 0, 0, 1,0 ) , O型血表示为( 0, 0, 0, 1 ) 。对于类别取值较多的情况下使用独热编码需要注意以下问题。
( 1 ) 使用稀疏向量来节省空间。在独热编码下,特征向量只有某一维取值为 1 ,其他位置取值均为 0。因此可以利用向量的稀疏表示有效地节省空间,并且目前大部分的算法均接受稀疏向量形式的输入。
( 2 ) 配合特征选择来降低维度。高维度特征会带来几方面的问题。一是在 K近邻算法中,高维空间下两点之间的距离很难得到有效的衡量;二是在逻辑回归模型中, 参数的数量会随着维度的增高而增加,容易引起过拟合问题;三是通常只有部分维度是对分类、预测有帮助,因此可以考虑配合特征选择来降低维度。
3.3 二进制编码( Binary Encoding )
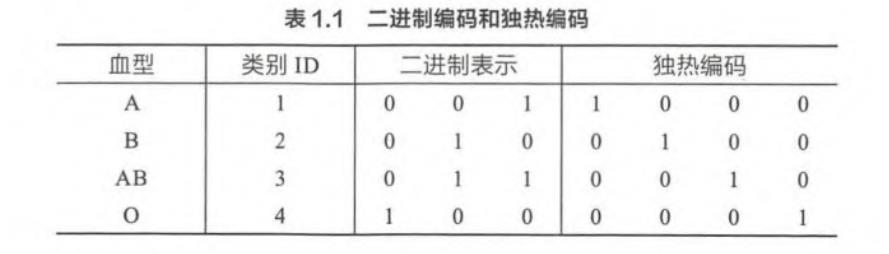
二进制编码主要分为两步,先用序号编码给每个类别赋予一个类别ID,然后将类别ID对应的二进制编码作为结果。以A,B,AB,O血型为例,下图是二进制编码的过程。A型血的ID为 1 ,二进制表示为 001 ; B型血的 ID为 2 , 二进制表示为 010 ; 以此类推可以得到AB型血和 O型血的二进制表示。可以看出,二进制编码本质上是利用二进制对ID进行哈希映射,最终得到 0/1 特征向量,且维数少于独热编码,节省了存储空间.
参考资料
1.《统计学习方法》
2.《百面机器学习》
以上是关于百面机器学习之特征工程的主要内容,如果未能解决你的问题,请参考以下文章