python机器学习之特征降维
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python机器学习之特征降维相关的知识,希望对你有一定的参考价值。
🌔上次我们学习了数据处理中的特征处理,主要包括归一化、标准化、二值化、独热编码等,对数据做完处理后,接下来就应该进行数据的降维处理了,对于数据处理感兴趣的同学可以查看👇:
- python机器学习之特征工程: python机器学习之数据探索.
- python机器学习之特征工程: python机器学习之特征处理.
🐟今天我们要学的是数据的降维部分,数据的降维主要是将高维向量空间的数据点印射到低纬空间中,当然也可以从低纬度转换到高维度中,在实际应用中,高维度空间包含较多的冗余信息与噪声信息,从而通过降维来减少冗余造成的误差,提高识别的精度。
1 基于特征选择的降维
特征选择是在数据建模过程最常用的特征降维手段,简单粗暴,即映射函数直接将不重要的特征删除,不过这样会造成特征信息的丢失,不利于模型的精度。由于数据的Fenix以抓住主要影响因素为主,变量越少越有利于分析,因此特征选择常用于统计分析模型中。
1.1特征选择的方法
- 过滤法(Filter):按照发散性或者相关性对各个特征进行评分,通过设定阈值或者待选择阈值的个数来选择特征。
- 包装法(Wrapper):根据目标函数每次选择若干特征,或者排除若干特征。
- 嵌入法(Embedded):使用机器学习的某些算法和模型进行训练,得到各个特征的权重系数,并根据权重系数的大小来选择特征,这一方法类似于过滤法,但主要区别在于他通过训练来确定特征!
我们采用思维导图图来看一下:
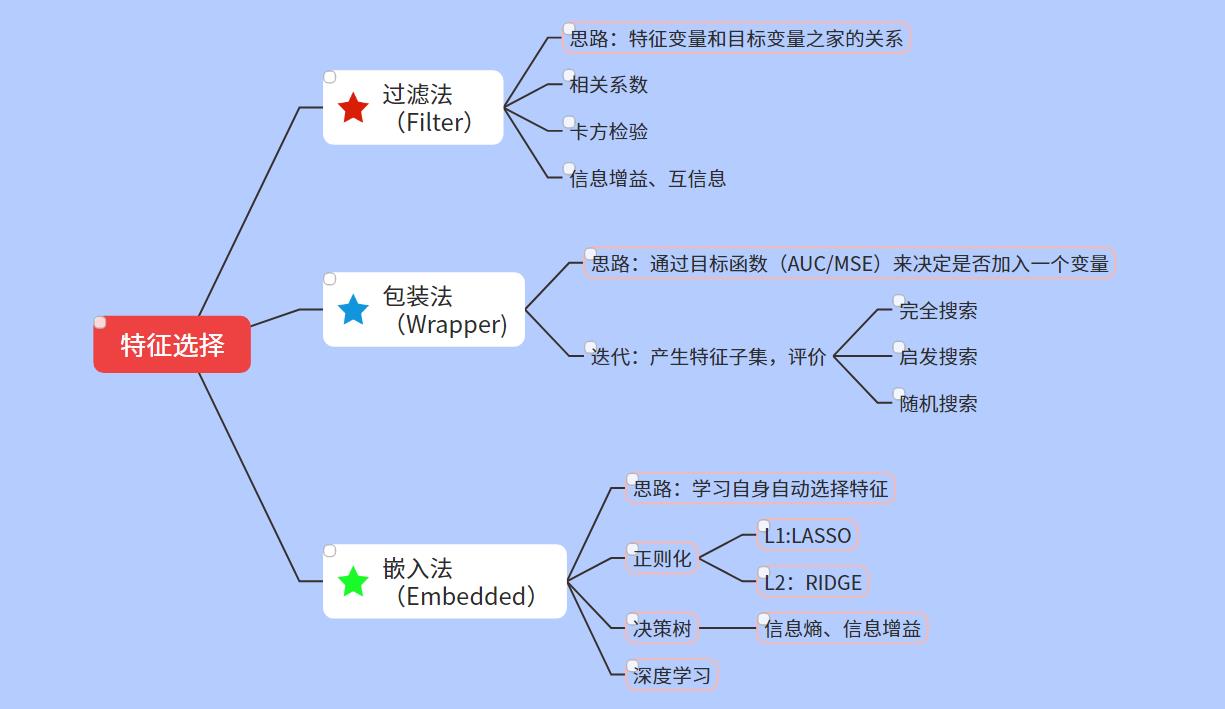
这里我们就介绍几种典型的方法!
| 类 | 所属方法 | 具体方法 |
|---|---|---|
| Variance | Filter | 方差选择法 |
| SelectKBest | Filter | 将可选相关系数、卡方检验或者最大信息系数作为得分计算的方法 |
| RFE | Wrapper | 递归消除特征法 |
| selectFromModel | Embedded | 基于模型的特征选择法 |
1.1.1 方差选择法
使用方差选择降维,先要计算各个特征的方差,然后根据阈值选择出大于阈值的方差特征,用feature_selection库的VarianceThreshold来选择特征。
from sklearn.feature_selection import VarianceThreshold
from sklearn.datasets import load_iris
iris=load_iris()
#方差选择的值域为3,大于3的特征列保留
VarianceThreshold(threshold=3).fit_transform(iris.data)
结果如下:只选择了一列数据

1.1.2 相关系数法
相关系数选择法主要是计算特征与目标之间的相关系数及相关系数的p值,然后根据阈值筛选特征。使用feature_selection库的selectKBest类结合相关系数来选择特征。
import numpy as np
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectKBest
from scipy.stats import pearsonr
iris=load_iris()
#选择K个最好的特征,返回选择特征后的数据,该函数第一个参数为计算评估特征的函数,该函数输入特征矩阵和目标向量,输出二元组(评分,P值)的数组,数组第i项为第i个特征的评分和P值,在此定义为计算相关系数
#参数K为选择的特征个数
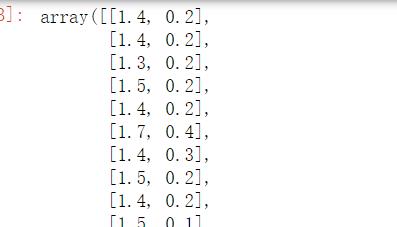
SelectKBest(lambda X,Y:np.array(list(map(lambda x: pearsonr(x,Y),X.T))).T[0],k=2).fit_transform(iris.data,iris.target)
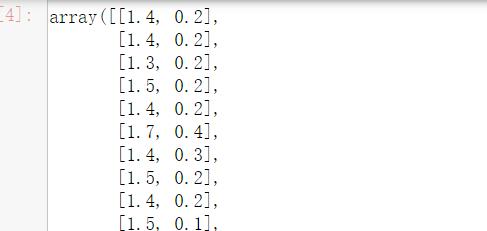
卡方检验,经典的卡方检验是检验定性变量与定性变量之间的相关性。假设自变量有N种取值,因变量有M种取值,考虑自变量等于I且因变量等于j的样本频数的观测值与期望值的差距,构建的统计量。用feature_select库中的SelectKBest类结合卡方检验来选择特征。
# 卡方检验
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
iris=load_iris()
#选择K个最好的特征返回选择特征后的数据
SelectKBest(chi2,k=2).fit_transform(iris.data,iris.target)
j结果如下:
信息系数法,经典的互信息也是评价定性自变量与定性因变量相关性的方法
import numpy as np
from sklearn.feature_selection import SelectKBest
rom minepy import MINE
#由于mine不是函数式设计,,因此需要定义mic方法将其转化为函数式返回一个二元组,二元组的第二项设置为P值,为0.5
def mic(x,y):
m=MINE()
m.compute_score(x,y)
return (m.mic(),0.5)
#选择K个最好的特征,返回特征选择后的数据
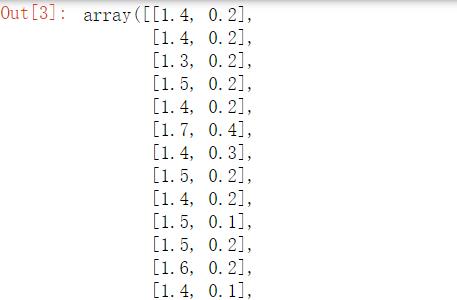
SelectKBest(lambda X,Y:np.array(list(map(lambda x:mic(x,Y),X.T))).T[0],k=2).fit_transform(iris.data,iris.target)
递归消除特征法是使用一个基模型来进行多轮训练,每轮训练之后,消除若干权值系数的特征,再基于特征集进行下一轮训练,使用feature_selection库的RFE类来选择特征
#RFE
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
#递归特征消除法,返回特征选择后的数据
#参数estimator
#参数n_features_to_select为选择的特征个数
iris=load_iris()
RFE(estimator=LogisticRegression(multi_class='auto',solver='lbfgs',max_iter=500),n_features_to_select=2).fit_transform(iris.data,iris.target)
结果如下:
带惩戒项的选择法
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LogisticRegression
#选择L2惩戒项的逻辑回归作为基模型的特征选择
SelectFromModel(LogisticRegression(penalty='l2',C=0.1,solver='lbfgs',multi_class='auto')).fit_transform(iris.data,iris.target)
结果如下:
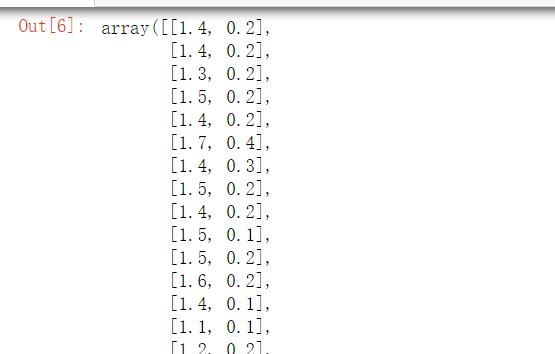
树模型选择法 主要采用GBDT进行特征选择
#基于决策时的特征选择(GBDT)
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import GradientBoostingClassifier
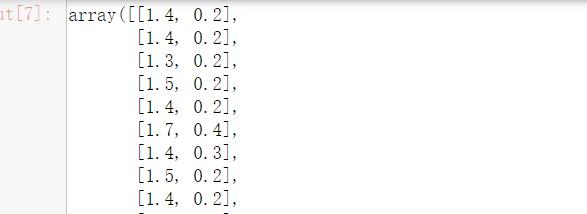
#将GBDT作为基模型的特征选择
SelectFromModel(GradientBoostingClassifier()).fit_transform(iris.data,iris.target)
结果如下:
2 基于线性方式的降维
线性降维常用的方法有主成分分析法和线性判别法分析法。
2.1 主成分分析PCA
PCA是最常用的线性降维的方法,主要原理是通过某种线性投影,将高维度的数据映射到低纬的空间中表示,并期望在所投影的维度上数据的方差最大,以此达到使用较少的数据维度来保留较多的原数据点特征的效果。
一般采用decomposition库的PCA类选择特征:
#PCA
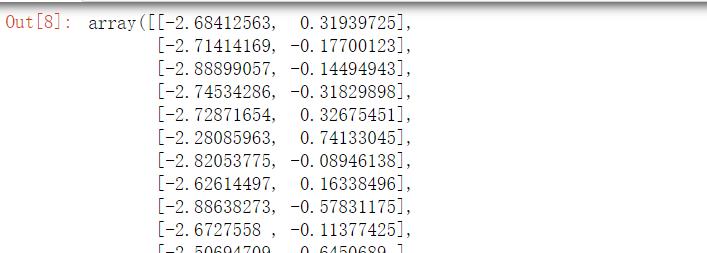
from sklearn.decomposition import PCA
#主成分分析,返回降维后的数据
#n_components为主成分的数目
PCA(n_components=2).fit_transform(iris.data)
结果如下:
2.2线性判别分析法
LDA也叫做Fisher线性判别(FLD)是一种有监督的线性降维算法。与PCA尽可能的保留数据信息不同,LDA的目标是使降维后的数据点尽可能地容易被区分,利用了其标签信息。
我们使用lda库的LDA类选择特征。
# LDA
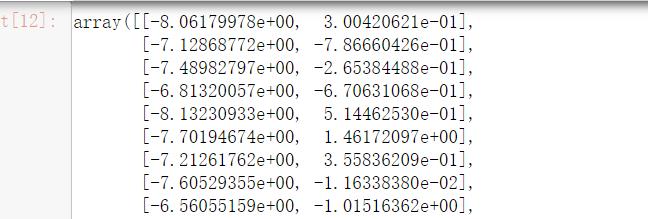
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
#线性判别分析法,返回降维后的数据
#n_components为降维后的数目
LDA(n_components=2).fit_transform(iris.data,iris.target)
结果如下:
总结一下吧,今天主要介绍了一些常见的降维方法,相信大家用的较多的还是线性方式降维。但其他的方式也是需要大致了解一下,如果对于他们的数学原理感兴趣的小伙伴可以去查查资料!
以上是关于python机器学习之特征降维的主要内容,如果未能解决你的问题,请参考以下文章