python机器学习之特征处理
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python机器学习之特征处理相关的知识,希望对你有一定的参考价值。
☀️前面我们讲述了对数据建模之前需要对数据进行数据探索,探索完之后应该干些啥?没错,接下来就是特征工程!对数据探索感兴趣的同学可以查看下面的文章👇:
- python机器学习之特征工程: python机器学习之数据探索.
💗今天我们要学习的内容是特征工程,特征工程的好坏决定了机器学习的上限!特征工程是从原始数据提取特征的过程,这些特征可以很好地描述数据,并利用特征建立的模型在未知数据上的性能表现达到最优,特征工程主要包括特征使用、特征获取、特征处理、特征选择和特征监控。
| 类 | 功能 | 说明 |
|---|---|---|
| StandarScaler | 无量纲化 | 标准化,基于特征列,将特征值转换为服从标准正态分布 |
| MinMaxScaler | 无量纲化 | 区间缩放,基于列的最大值和最小值,将特征转化到[a,b]区间 |
| Normalizer | 归一化 | 基于特征矩阵的行,将样本向量转化为单位向量 |
| Binarizer | 定量特征二值化 | 基于给定阈值,将特征按阈值划分 |
| OneHotEncoder | 定性特征哑变量编码 | 将定性特征编码为定量特征 |
| Imputer | 缺失值处理 | 计算缺失值,缺失值可填充为均值 |
| FunctionTransformer | 自定义单元数据转换 | 使用单元函数转换数据 |
目录
1.数据预处理和特征处理
1.1 数据预处理
在提取特征之前,需要对数据进行预处理,具体包括数据采集、数据清洗、数据采样。
1.1.1数据采集
数据采集就是需要采集对预测结构有帮助的一类数据,采集到关键的数据是好的预测的关键!
1.1.2数据清洗
数据清洗也是很重要的一步,机器学习就像是一个加工机器,产品如何取决于原材料的好坏,数据清洗就是要去除“脏”数据!
1.1.3数据采样
在数据采集、清洗过后,正负样本是不均匀的,所以需要对数据进行采样。采样的方法有随机采样和分层采样。但是由于随机采样导致每次采样的数据不均匀,因此更多的是1根据特征进行分层抽样。
正样本>负样本:采用下采样。
正样本<负样本:上采样,修改损失函数设置样本的权重。
1.2 特征处理
特征处理的方式有标准化、区间缩放法、归一化、定量特征二值化、定性特征哑编码、缺失值处理和数据转换。
1.2.1标准化
标准化是依照特征矩阵的列来处理数据,即通过求标准分数的方法,将特征转化为标准正态分布,并和整体样本分布相关。每个样本点都能对标准化产生影响。标准化公式如下:
x
′
=
x
−
X
‾
S
x'=\\frac{x-\\overline{X}}{S}
x′=Sx−X 其
X
‾
\\overline{X}
X是均值,S是标准差。
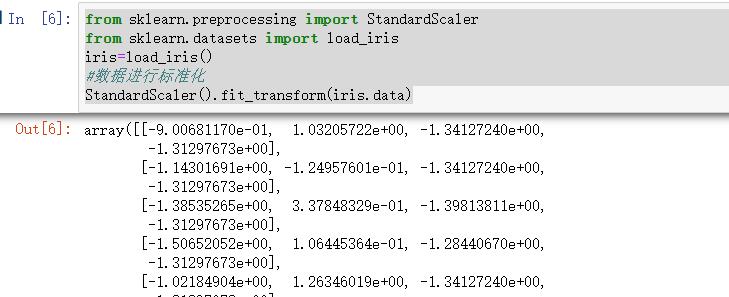
在sklearn中使用preprocessing库中的StandardScaler进行处理:
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
iris=load_iris()
#数据进行标准化
StandardScaler().fit_transform(iris.data)
结果如下:
1.2.2区间缩放法
区间缩放法常见的一种就是利用列的最大值和最小值进行缩放。公式如下:
x
′
=
x
−
M
i
n
M
a
x
−
M
i
n
x'=\\frac{x-{Min}}{Max-Min}
x′=Max−Minx−Min。
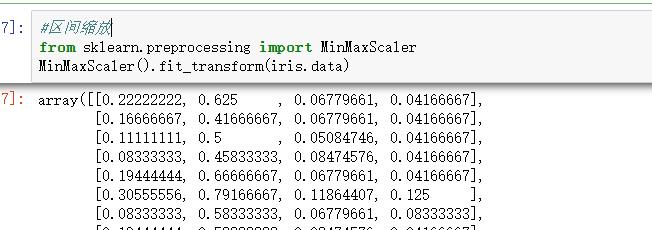
在sklearn中使用preprocessing库中的MinMaxScaler进行处理:
#区间缩放
from sklearn.preprocessing import MinMaxScaler
MinMaxScaler().fit_transform(iris.data)
1.2.3归一化
归一化是将样本的特征值转换到同一量纲下,把数据映射到[0,1]或者[a,b]区间内,由于其仅由变量的极值决定,因此区间缩放法是归一化的一种。
归一区间会改变数据的原始距离、分布和信息,但标准化不会!
L1,L2归一化都是基于行的!

我们一般采用L2归一化的公式如下:
x
i
′
=
x
i
∑
i
=
1
n
x
i
2
x'_i=\\frac{{x_i}}{\\sqrt{\\sum_{i = 1} ^nx_i^2}}
xi′=∑i=1nxi2xi,其中下半部分为
x
i
x_i
xi的L2范式。
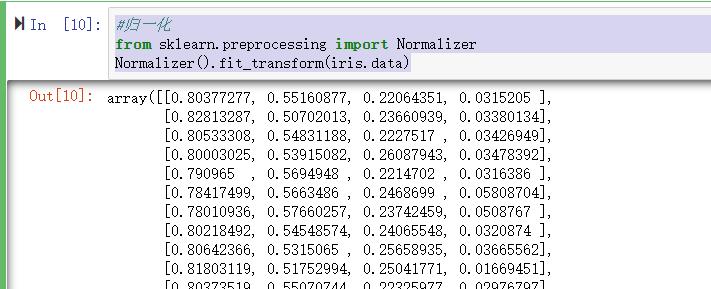
在sklearn中使用preprocessing库的Normalizer类对数据集进行归一化:
#归一化
from sklearn.preprocessing import Normalizer
Normalizer().fit_transform(iris.data)
结果如下:
使用场景
- 如果对输出结果范围有要求,则用归一化
- 如果数据较为稳定,不存在极端的最大值最小值,则用归一化
- 如果数据存在异常值和较多的噪声,则用标准化,这样可以通过中心化简介避免异常值和极端值的影响。
- SVM、KNN、PCA等模型都必须要求进行归一化或者标准化。
1.2.4定量特征二值化
定量特征二值化的核心在于设定一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0。
赋值公式如下:
x
′
=
{
1
,
x
>
t
h
r
e
s
h
o
l
d
0
,
x
<
=
t
h
r
e
s
h
o
l
d
x' = \\begin{cases} 1, \\mathrm{x>threshold} \\\\ 0,\\mathrm{x<=threshold} \\\\ \\end{cases}
x′={1,x>threshold0,x<=threshold
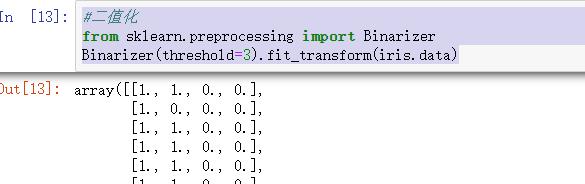
我们使用preprocessing库的Binarizer类对数据集进行二值化
#二值化
from sklearn.preprocessing import Binarizer
Binarizer(threshold=3).fit_transform(iris.data)
1.2.5 独热编码
独热编码也被成为定性哑变量编码,引入独热编码的作用是将原本不能定量处理的变量进行量化,从而评估定性因素对因变量的影响。例如:对于职位这一栏有工人、农民、学生、企业职员我们就可以将他们进行独热编码:
工人:(0,0,0,1)
农民:(0,0,1,0)
学生:(0,1,0,0)
企业职员:(1,0,0,0)
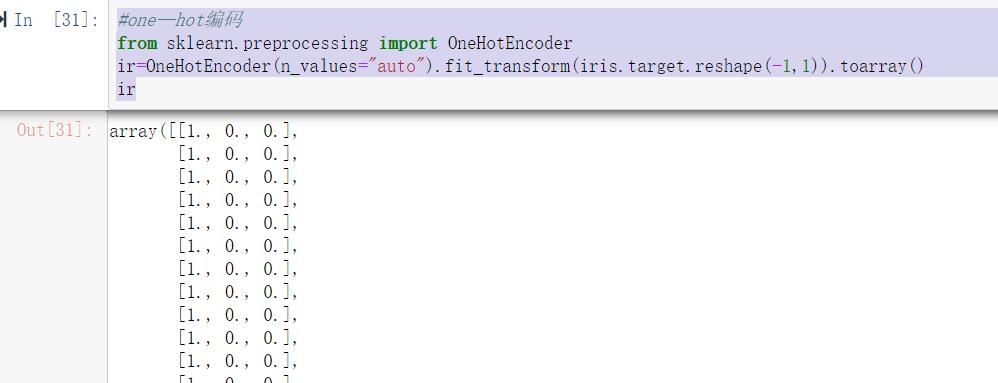
使用sklearn中的OneHotEncoder进行编码
#one—hot编码
from sklearn.preprocessing import OneHotEncoder
ir=OneHotEncoder(n_values="auto").fit_transform(iris.target.reshape(-1,1)).toarray()
ir
结果如下:
1.2.6 缺失值处理
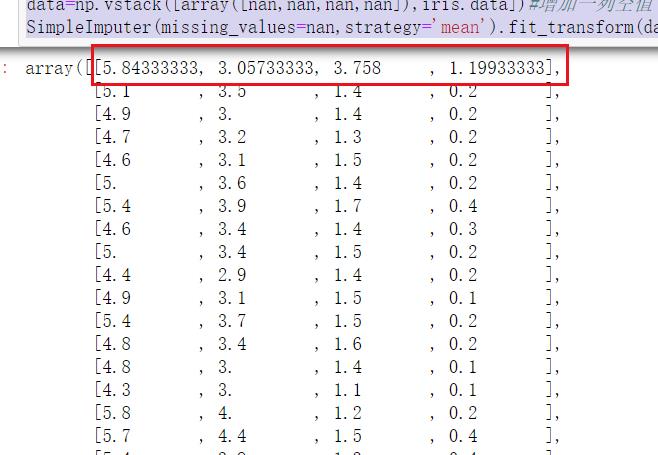
在处理缺失值时,用pandas读取数据为NaN,即表示缺失值。
可以使用sklearn中的impute中的simpleimputer对缺失值进行填充
import numpy as np
from numpy import vstack,array,nan
from sklearn.impute import SimpleImputer
data=np.vstack([array([nan,nan,nan,nan]),iris.data])#增加一列空值
SimpleImputer(missing_values=nan,strategy='mean').fit_transform(data)#missing_values代表空值形式,strategy是填充策略
填充成功:
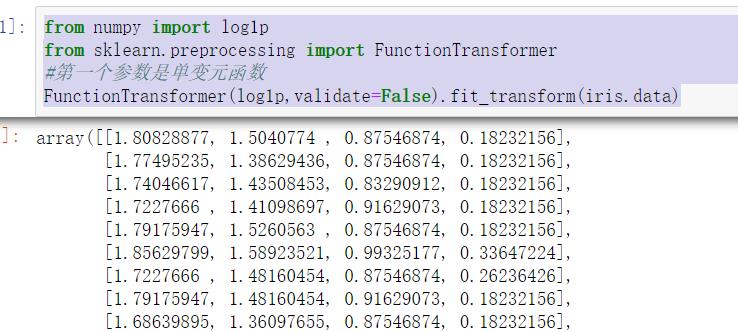
1.2.7数据转换
数据转换有很种方式,比如取对数,多项式转换等。
我们这里就举一个对数转换的例子吧。
使用sklearn中的preprocessing中的FunctionTransformer函数
from numpy import log1p
from sklearn.preprocessing import FunctionTransformer
#第一个参数是单变元函数
FunctionTransformer(log1p,validate=False).fit_transform(iris.data)
结果如下:
下一章节我们将进行讲解特征降维!
以上是关于python机器学习之特征处理的主要内容,如果未能解决你的问题,请参考以下文章