从火星的古海洋,读懂蓝星的数据湖之变
Posted 脑极体
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从火星的古海洋,读懂蓝星的数据湖之变相关的知识,希望对你有一定的参考价值。
大家想必都听说了天问一号探测器“祝融号”成功在火星着陆的消息。在它传回的家书中,提到科学家们为自己选择的着陆地,火星的乌托邦平原,可能是一个古海洋所在地,地形平缓,确保了安全性。
当我们将目光投回到身处的这颗“蓝星”,也时时面临着需要为产业要素选择着陆地——比如说大数据。
相比传统的数据仓库架构,数据湖(Data Lake)已经成为数字化进程中,对现代企业和组织极具吸引力的大数据“着陆地”。
简单来说,数据湖指的是如同湖泊一样,将各种业务及软硬件中源源不断产生的各类数据,全部容纳其中。
在AI+云的大趋势下,数据湖还可以与机器学习等相结合,指导企业进行效率优化及智能决策;与云计算结合,利用云服务弹性扩展、灵活部署、高可用高可靠、按使用量付费等特点,打造出投资回报更高的大数据解决方案。

如果说乌托邦平原是探测火星的绝佳地点,那么数据湖就是承载企业数据资产的最佳场所。
目前来看,数据湖有巨大的想象空间,也吸引着各大云厂商下足功夫,AWS、微软、谷歌等都推出了各自的数据湖产品。
5月13日,腾讯云也首次对外展示完整云端数据湖产品图谱,并推出两款“开箱即用”数据湖产品,数据湖计算服务DLC和数据湖构建DLF。
相比单一产品或服务,在腾讯云的数据湖版图中,可以看到概念的“拓维”:云原生智能数据湖,对产业来说意味着什么?图谱式的产品矩阵,能给企业带来哪些价值?“开箱即用”会给数据湖及数字化进程带来什么影响?
我们以数据湖的需求与挑战为开端,来探秘腾讯云带来的“致用纪元”。
数字山河,
需要怎样的大数据之湖?
先回答一个疑问,什么样的企业需要数据湖?答案是,所有。
IDC报告显示,到2025年全球数据总量将超过160ZB。数字化进程中,对大数据的管理与应用已经成为企业的竞争要素之一。飞速增长的数据规模自然也需要新的数据存储策略,数据湖的特殊之处在于:
所有数据可以一直保存,不管是实时使用的,还是可能永远不会被使用的,不仅让单位存储成本更低,也让任意时间点的数据回溯与分析成为可能;
所有类型可以全部容纳。无论是定量指标的结构化数据,还是传感器、社交网络、图像视频等等多样化数据源的非结构化数据;
所有用户可以得到支持。在数据湖中,所有数据都以原始形式存储,需要使用数据的人可以快速找到数据源的单一位置,避免了数据孤岛、数据重复、协作困难等问题。
此外,数据湖也易于适应变化。数据仓库的开发和更改都需要花费大量的时间,消耗开发人员资源。而在云端部署的数据湖,可以根据企业业务需求灵活扩展,比传统方案具有更大的灵活性,最大限度地减少雇佣专业数据运维团队的支出。

Aberdeen 的一项调查表明,实施数据湖的组织比同类公司在收入增长方面高出 9%。
看到这里,是不是已经心动想要拿起电话订购了?别急!并不是将所有数据一股脑丢进湖中就大功告成了。
正如Gartner分析师尼克·休德克所说,将数据湖看做是大数据项目的灵丹妙药,是一个谬论,数据湖是一个概念,而不是一种技术。
也就是说,企业在引入数据湖时,要注重从搭建、效益到应用的整体平衡。
比如,如果没有适当的工具,数据湖可能会遭遇数据可靠性的问题,出现数据损坏、脏数据等等,让数据科学家、AI工程师难以利用数据进行推理,或是训练出不准确的业务模型;
再比如,一直往数据湖里面存储数据,而缺乏数据治理及应用输出,就会形成“数据沼泽”,随着时间的推移变得混乱、低质量;
最关键的是,目前市场上大多数数据湖产品都在强调对数据的存储及计算,在具体业务场景之中究竟该怎样去应用数据湖,并没有清晰一致的答案。不解决技术的致用问题,就会让很多企业望而却步。
这种局面该怎么办?中国人的智慧早有提示,流水不腐户枢不蠹,比起挖坑引水的“单向湖”,从山川河流的源头、湖泊的常规治理,再到流向产业田野的应用,这样的一整套数据湖解决方案,显然更符合产业用户的期待。
开启纪元,
腾讯云的多米诺骨牌
技术产业周期的开启,从来不是一蹴而就的。云原生的数据湖,需要在存储、计算、应用等层面解决诸多挑战才能完成。
而腾讯云首次披露的云端数据湖产品矩阵,就是这样一套组合式的产品,包括了数据湖存储、数据湖算力调度、数据湖大数据分析、数据湖AI能力、数据湖应用、云上基础服务等六个层面,如同一副多米诺骨牌,将企业应用数据湖过程中可能遇到的阶段性问题一一推倒。
我们可以从三个层面来看腾讯云数据湖的新纪元打开:
1.数据底座。
数据湖的本质是为企业乃至全社会的数字化转型提供坚实可靠的数据基础设施架构,对高性能、高安全、高可靠、低成本等综合实力提出了高要求。
对此,腾讯云数据湖在整个数据生命周期都进行了周全的设计。在存储层,以对象存储COS服务为核心,理论上可以存储任意规模的异构数据,也支持将其他云端数据设施,为企业打消后顾之忧;
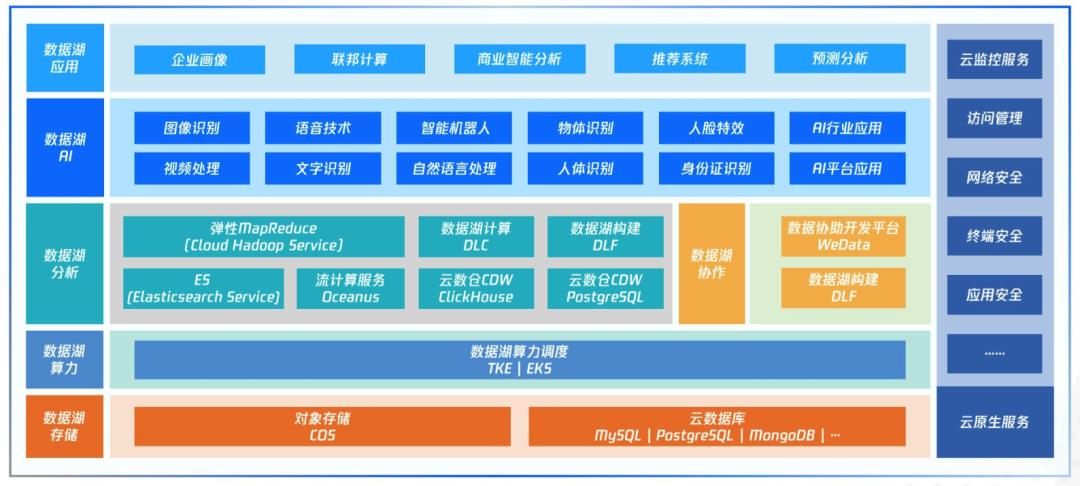
(腾讯云原生智能数据湖产品图谱)
在数据分析层,既提供半托管的泛Hadoop服务,满足用户自定义需求,也提供全托管的数据服务,便于用户获取海量数据的洞察力。
此外,用户还可利用腾讯云提供的数据协作工具对计算服务进行编排和调用,提升企业数据的便捷性和敏捷度。
2.智能源头。
今天,企业选择数据湖的考量与上云有着异曲同工之处,那就是为业务增长引入AI能力,达到提质增效的目的。腾讯云也没有令人失望,给出了一系列助力数据智能的解决方案。
比如在算力调度上,基于腾讯云弹性容器服务EKS,开放的容器化的分析架构让数据分析功能可组合性更强,扩展性更强,降低企业训练AI、应用AI的综合成本;
此外,腾讯云数据湖也提供丰富的AI服务,为图像处理、音频处理、自然语言处理、视频处理等提供有力的数据支撑,当企业想要引入这些音视频能力时,更加简单快捷。
3.致用工具。
和所有新技术一样,数据湖的最终评价标准是要落进现实。这就需要降低企业应用门槛,让技术价值能够从真实业务场景中生长出来。
为此,腾讯云在数据湖产品图谱中,推出了企业画像、联邦计算、商业智能分析等数据应用服务,企业直接选择自身所需要的能力,就可以把数据湖应用构建起来。

同时,通过数据湖计算(Data Lake Compute,简称DLC)和数据湖构建(Data Lake Formation ,简称DLF)这样“开箱即用”的产品,降低企业应用数据湖的难度。相比于本地自建大数据集群,基于这两款产品,数据湖构建时间减少了60%,数据分析计算性能提升35.5%。
这样一步步推导,也就连成了“从入湖到出湖”端到端的完整链路,也清晰地指出了腾讯云数据湖所带来的差异化价值:希望借数据湖产品图谱,引领数据湖进入“致用纪元”,与数字山河相映照。
向文明进发:
数据能源的里程碑
1964年,苏联天文学家尼古拉·卡尔达肖夫提出理论,根据一个文明所能够利用的能源量级,来量度文明层次及技术先进程度。
按照等级划分,地球目前正处于0.73级左右,还没有达到利用行星本身所拥有的能量规模。
换个角度思考,大数据,何尝不也是这颗蓝色星球上的新兴能源,让智能更快、产业更优、经济动力更强,对数据的利用与开发也将助推一国数字文明的加速发展。
正如同“祝融号”标志着中国人开始走出地球“摇篮”,腾讯云数据湖产品图谱也为智能时代的大数据管存用提供了一个全新的选择:在业内首先提出了“图谱式数据湖产品”,从数据入湖时怎样存、算,到在湖中如何分析与应用,满足用户的所有需求。这不正是产业一直在期待的数据“能源开采装置”吗?

这时候我们会想问,为什么率先打出连招的中国云厂商会是腾讯云?有三个背景是不可忽略的。
首先,腾讯自身庞大且多元的业务体系,无时无刻不在产生着大量的非结构化信息,这时就需要数据湖技术去解决数据分散、重复数据等问题,正是在腾讯新闻等诸多内部场景中孵化,打磨到一定程度之后,将相应能力开放给产业客户,可谓是恰逢其时。
第二,来自腾讯云的基础服务与技术积累,比如前文提到的能帮助用户快速构建企业数据湖技术架构的数据湖构建(DLF)产品,所提供的统一元数据管理与湖构建能力,就需要在数据规模很大的时候也能实现高性能的访问,来让数据存储、计算等速度更快,这就依赖于腾讯云在云服务领域的技术壁垒,为数据湖体系提供了保障。
最后,正如腾讯云大数据专家所说,要深入业务场景才会发现鲜活的痛点,方案要落在各行各业、不同企业客户的实际场景中去。
事实上,成功的数据湖采用者大都是使用“业务回头”的方法,即先确定业务可以从数据湖中获得的最大价值情境,然后将这些场景纳入到解决方案中,再逐步填充数据。这就需要做大量定制开发工作,考验着云厂商的企业服务能力与意识,也是今天数字化转型中最难的一道关卡。
在这方面,我们看到腾讯云直指现实需求和应用场景,将采用决定权交给业务,与客户的技术人员一起梳理核心需求,最终选择更适合自己的方案。腾讯云数据湖产品之所以率先选择向“技术致用”延伸,或许正来自于这一份对业务的尊重。

范仲淹曾形容洞庭湖“浩浩荡荡,横无际涯”,也是今天企业面对数据洪潮的现实写照。
对于数据湖这类新技术的出现,也容易出现了两种截然相反的情绪:过度质疑,会令企业踌躇不前,错过超越竞争者的机遇;过于乐观,又会导致对困难缺乏充足的估计。
或许更理性的态度应该是,和科技企业携手,一起去探索并撬动未知,驶向气象万千的数字文明。
以上是关于从火星的古海洋,读懂蓝星的数据湖之变的主要内容,如果未能解决你的问题,请参考以下文章