数据湖之Hudi:Apache Hudi 快速发展
Posted 电光闪烁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据湖之Hudi:Apache Hudi 快速发展相关的知识,希望对你有一定的参考价值。
目录
0. 相关文章链接
1. Hudi 诞生
- Apache Hudi由Uber开发并开源,该项目在2016年开始开发,并于2017年开源,2019年1月进入 Apache 孵化器,且2020年6月称为Apache 顶级项目,目前最新版本:0.9.0版本。
- Hudi 一开始支持Spark进行数据摄入(批量Batch和流式Streaming),从0.7.0版本开始,逐渐与Flink整合,主要在于Flink SQL 整合,还支持Flink SQL CDC。
2. 发展历史
- 2015 年:发表了增量处理的核心思想/原则(O'reilly 文章)
- 2016 年:由 Uber 创建并为所有数据库/关键业务提供支持
- 2017 年:由 Uber 开源,并支撑 100PB 数据湖
- 2018 年:吸引大量使用者,并因云计算普及
- 2019 年:成为 ASF 孵化项目,并增加更多平台组件
- 2020 年:毕业成为 Apache 顶级项目,社区、下载量、采用率增长超过 10 倍
- 2021 年:支持 Uber 500PB 数据湖,SQL DML、Flink 集成、索引、元服务器、缓存。
3. 各版本新特性
Hudi 0.5.x 版本时
Apache 顶级项目,支持Spark、Hive、Presto分析引擎
主要以Spark为主,将数据批量和流式写入Hudi中
Hudi 0.6 版本开始
逐渐添加新特性和功能
Hudi 0.7.0 版本开始
由于Flink 计算引擎成熟稳定,尤其Flink 1.12版本发布
社区开始支持Flink 计算引擎,提供工具类方式
Hudi 0.8.0 版本,支持Flink SQL Client 操作Hudi 表数据
数据入湖
数据查询
使用SQL方式
Hudi 0.9.0 版本,重构与Flink集成,更好与Flink使用
支持CDC方式,将数据流式入湖,使用Hudi进行管理
流式查询Hudi表数据,仅仅编写SQL即可
Hudi 0.10.0 版本,支持更多数据源
比如支持mysql数据源
支持Kafka 数据源4. 新架构:湖仓一体
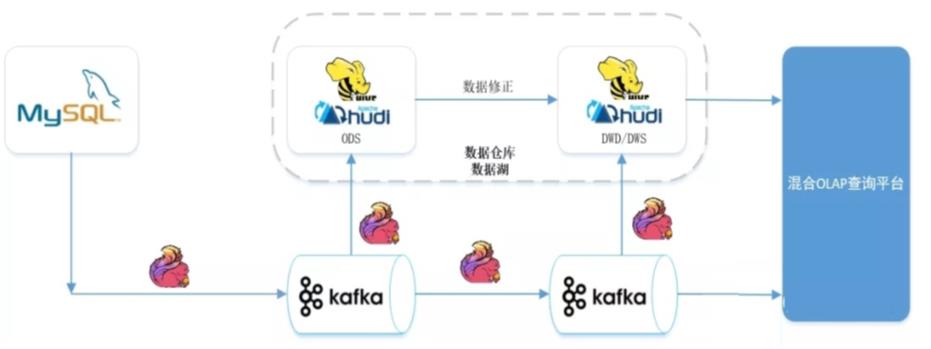
- Hudi 对于Flink友好支持以后,可以使用Flink + Hudi构建实时湖仓一体架构,数据的时效性可以到分钟级,能很好的满足业务准实时数仓的需求。
- 通过湖仓一体、流批一体,准实时场景下做到了:数据同源、同计算引擎、同存储、同计算口径。
注:Hudi系列博文为通过对Hudi官网学习记录所写,其中有加入个人理解,如有不足,请各位读者谅解☺☺☺
注:其他相关文章链接由此进(包括Hudi在内的各大数据相关博文) -> 大数据基础知识点 文章汇总
以上是关于数据湖之Hudi:Apache Hudi 快速发展的主要内容,如果未能解决你的问题,请参考以下文章