数据湖之Hudi源码编译
Posted 不知名的。。。
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据湖之Hudi源码编译相关的知识,希望对你有一定的参考价值。
一、Maven安装
在centos系统上安装Maven,直接将Maven解压,然后配置系统环境变量即可,配置完Maven环境变量以后,执行mvn -version。
二、下载源码包
到Apache软件归档目录下载Hudi 0.8源码包: http://archive.apache.org/dist/hudi/0.9.0/
wget https://archive.apache.org/dist/hudi/0.9.0/hudi-0.9.0.src.tgz
编译Hudi源码步骤
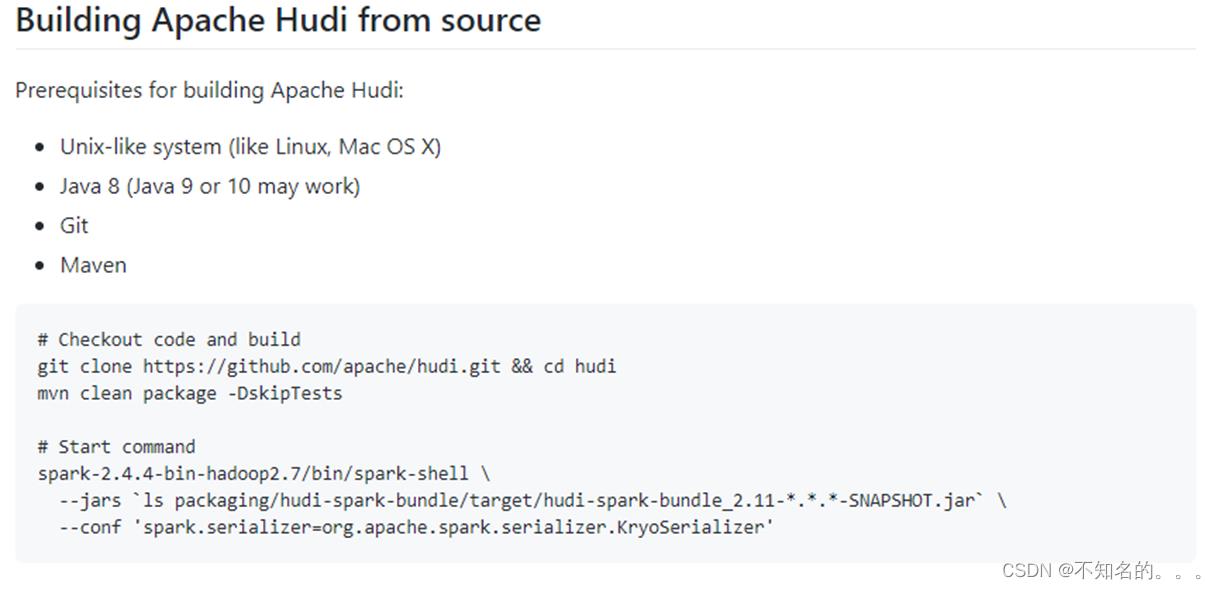
三、执行编译命令
集成spark2
mvn clean package -DskipTests -Dspark2.4
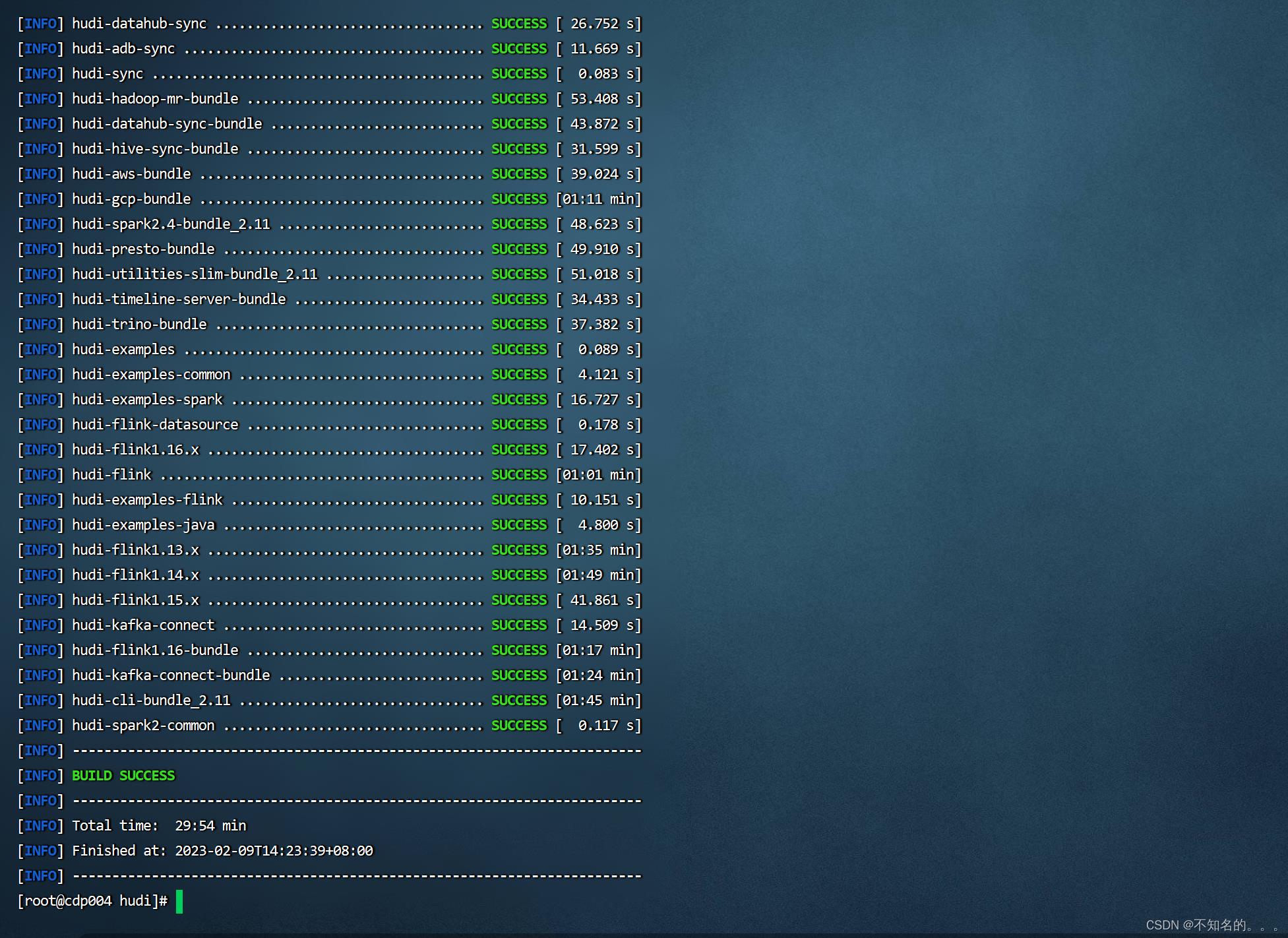
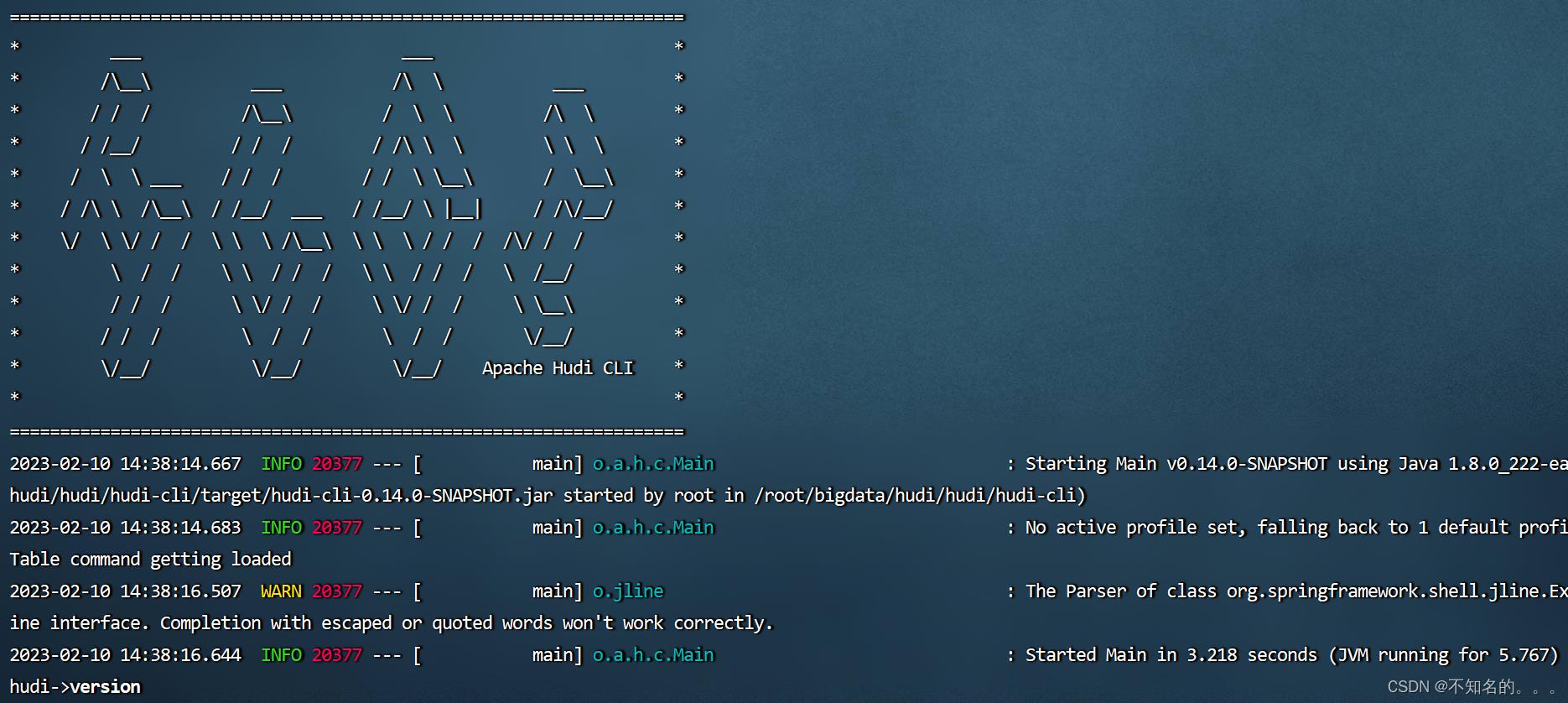
四、Hudi CLI测试
编译完成以后,进入hudi-cli目录,运行hudi-cli脚本,如果可以运行,说明编译成功。
五、通过spark-shell来访问hudi,读取hudi表的数据
编译出的spark包在 packaging/hudi-spark-bundle/target 目录下面:
spark-shell \\
> --master local[2] \\
> --jars /root/bigdata/hudi/hudi/packaging/hudi-spark-bundle/target/hudi-spark2.4-bundle_2.11-0.14.0-SNAPSHOT.jar \\
> --conf "spark.serializer=org.apache.spark.serializer.KryoSerializer"spark.read.format("hudi").load("/hudi/hudi_tbl/").show()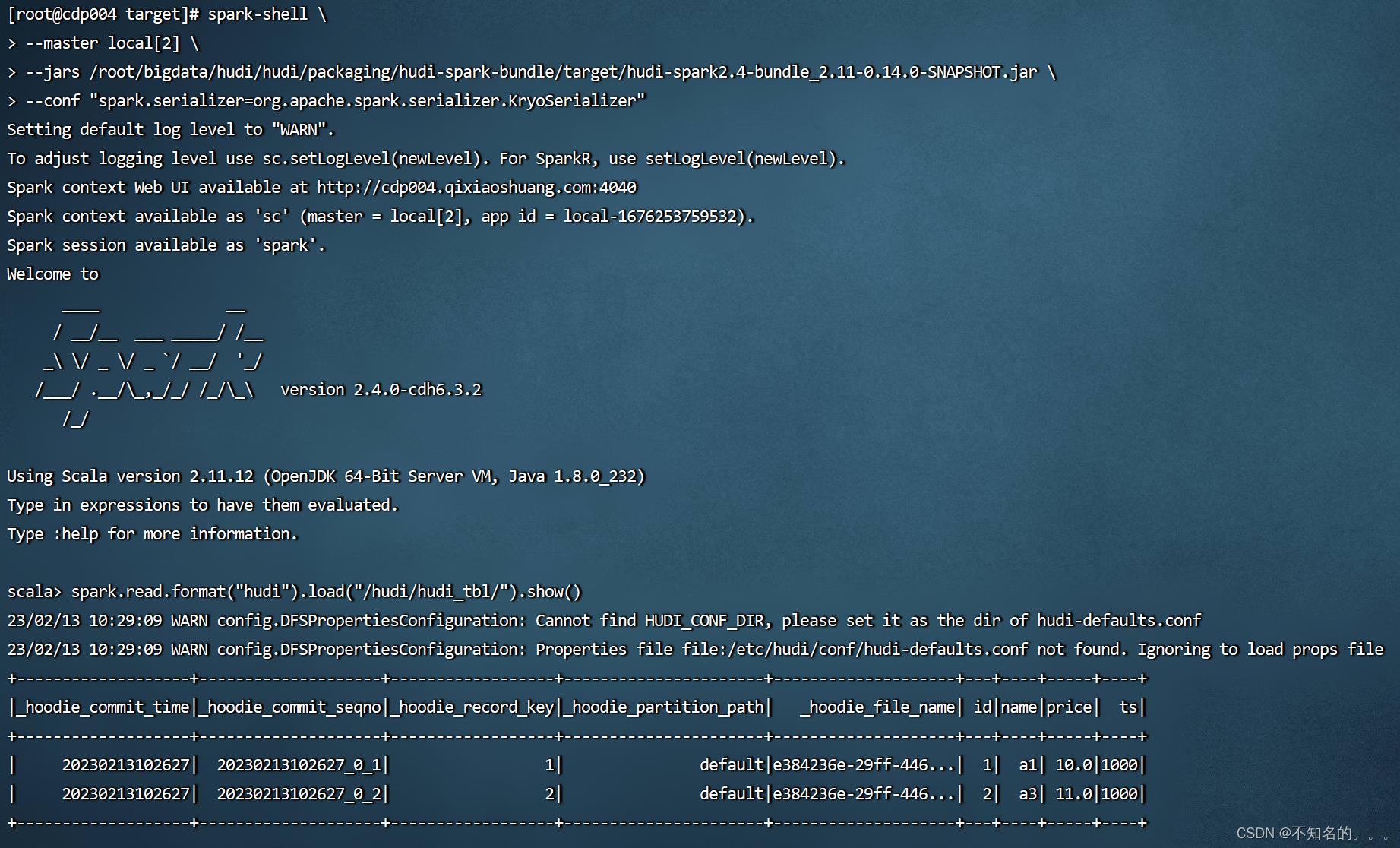
六、Hudi表数据结构
Hudi表的数据文件,可以使用操作系统的文件系统存储,也可以使用HDFS这种分布式的文件存储系统。为了后续分析性能和数据和可靠性,一般使用HDFS进行存储。以HDFS存储来看,一个Hudi表的存储文件分为两类。

.hoodie文件:由于CRUD的零散性,每一次的操作都会生成一个文件,这些小文件越来越多后,会严重影响HDFS的性能,Hudi设计了一套文件合并机制。.hoodie文件夹中存放了对应的文件合并操作相关的日志文件。
amricas和asia相关的路径是实际的数据文件,按分区存储,分区的路径key是可以指定的。
以上是关于数据湖之Hudi源码编译的主要内容,如果未能解决你的问题,请参考以下文章