KNN分类器之NearestNeighbors详解及实践
Posted Data+Science+Insight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了KNN分类器之NearestNeighbors详解及实践相关的知识,希望对你有一定的参考价值。
KNN(K Nearest Neighbors)分类器之最近邻NearestNeighbors详解及实践
如何判断谁是最近邻?
通过距离方法、例如欧几里得距离。

KNN属于基于实例的学习方法
一个实例在特征空间中的K个最接近(即特征空间中最近邻)的实例中的大多数属于某一个类别,则该实例也属于这个类别。
所选择的邻居都是已经正确分类的实例,是先验信息。
该算法假定所有的实例对应于N维欧式空间中的点。通过计算一个点与其他所有点之间的距离,取出与该点最近的K个点,然后统计这K个点里面所属分类比例最大的,则这个点属于该分类。
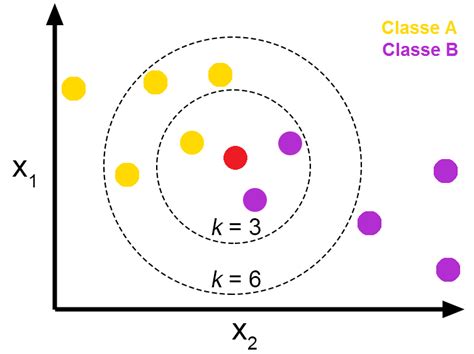
邻近算法,或者说K最近邻(KNN,K-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是K个最近的邻居的意思,说的是每个样本都可以用它最接近的K个邻近值来代表。近邻算法就是将数据集合中每一个记录进行分类的方法。
# 获取样本的最近邻
from sklearn import datasets
from sklearn.n以上是关于KNN分类器之NearestNeighbors详解及实践的主要内容,如果未能解决你的问题,请参考以下文章
KNN(K Nearest Neighbors)分类是什么学习方法?如何或者最佳的K值?RadiusneighborsClassifer分类器又是什么?KNN进行分类详解及实践