VRP问题基于模拟退火算法求解带时间窗的车辆路径规划问题VRPTW
Posted Matlab走起
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了VRP问题基于模拟退火算法求解带时间窗的车辆路径规划问题VRPTW相关的知识,希望对你有一定的参考价值。
模拟退火算法来源于固体退火原理,将固体加温至充分高,再让其徐徐冷却,加温时,固体内部粒子随温升变为无序状,内能增大,而徐徐冷却时粒子渐趋有序,在每个温度都达到平衡态,最后在常温时达到基态,内能减为最小。根据Metropolis准则,粒子在温度T时趋于平衡的概率为e-ΔE/(kT),其中E为温度T时的内能,ΔE为其改变量,k为Boltzmann常数。用固体退火模拟组合优化问题,将内能E模拟为目标函数值f,温度T演化成控制参数t,即得到解组合优化问题的模拟退火算法:由初始解i和控制参数初值t开始,对当前解重复“产生新解→计算目标函数差→接受或舍弃”的迭代,并逐步衰减t值,算法终止时的当前解即为所得近似最优解,这是基于蒙特卡罗迭代求解法的一种启发式随机搜索过程。退火过程由冷却进度表(Cooling Schedule)控制,包括控制参数的初值t及其衰减因子Δt、每个t值时的迭代次数L和停止条件S。
模拟退火算法的模型
模拟退火算法可以分解为解空间、目标函数和初始解三部分。
模拟退火的基本思想:
(1) 初始化:初始温度T(充分大),初始解状态S(是算法迭代的起点), 每个T值的迭代次数L
(2) 对k=1,……,L做第(3)至第6步:
(3) 产生新解S′
(4) 计算增量Δt′=C(S′)-C(S),其中C(S)为评价函数
(5) 若Δt′<0则接受S′作为新的当前解,否则以概率exp(-Δt′/T)接受S′作为新的当前解.
(6) 如果满足终止条件则输出当前解作为最优解,结束程序。 终止条件通常取为连续若干个新解都没有被接受时终止算法。
(7) T逐渐减少,且T->0,然后转第2步。
模拟退火的算法流程图如下:
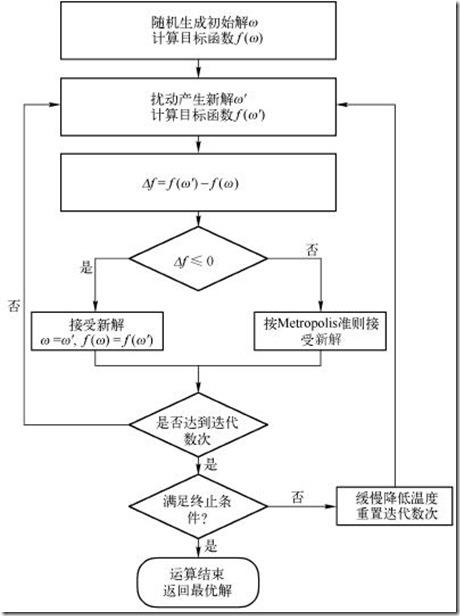
模拟退火算法新解的产生和接受可分为如下四个步骤:
第一步是由一个产生函数从当前解产生一个位于解空间的新解;为便于后续的计算和接受,减少算法耗时,通常选择由当前新解经过简单地变换即可产生新解的方法,如对构成新解的全部或部分元素进行置换、互换等,注意到产生新解的变换方法决定了当前新解的邻域结构,因而对冷却进度表的选取有一定的影响。
第二步是计算与新解所对应的目标函数差。因为目标函数差仅由变换部分产生,所以目标函数差的计算最好按增量计算。事实表明,对大多数应用而言,这是计算目标函数差的最快方法。
第三步是判断新解是否被接受,判断的依据是一个接受准则,最常用的接受准则是Metropo1is准则: 若Δt′<0则接受S′作为新的当前解S,否则以概率exp(-Δt′/T)接受S′作为新的当前解S。
第四步是当新解被确定接受时,用新解代替当前解,这只需将当前解中对应于产生新解时的变换部分予以实现,同时修正目标函数值即可。此时,当前解实现了一次迭代。可在此基础上开始下一轮试验。而当新解被判定为舍弃时,则在原当前解的基础上继续下一轮试验。 模拟退火算法与初始值无关,算法求得的解与初始解状态S(是算法迭代的起点)无关;模拟退火算法具有渐近收敛性,已在理论上被证明是一种以概率l 收敛于全局最优解的全局优化算法;模拟退火算法具有并行性
如果你对退火的物理意义还是晕晕的,没关系我们还有更为简单的理解方式。想象一下如果我们现在有下面这样一个函数,现在想求函数的(全局)最优解。如果采用Greedy策略,那么从A点开始试探,如果函数值继续减少,那么试探过程就会继续。而当到达点B时,显然我们的探求过程就结束了(因为无论朝哪个方向努力,结果只会越来越大)。最终我们只能找打一个局部最后解B。
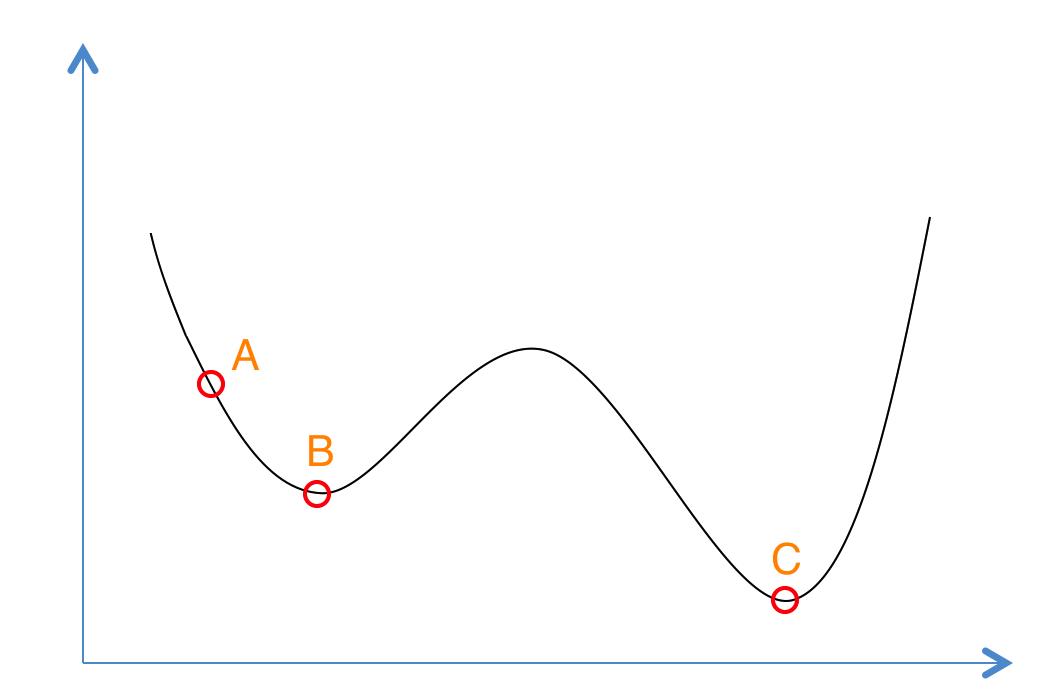
模拟退火其实也是一种Greedy算法,但是它的搜索过程引入了随机因素。模拟退火算法以一定的概率来接受一个比当前解要差的解,因此有可能会跳出这个局部的最优解,达到全局的最优解。以上图为例,模拟退火算法在搜索到局部最优解B后,会以一定的概率接受向右继续移动。也许经过几次这样的不是局部最优的移动后会到达B 和C之间的峰点,于是就跳出了局部最小值B。
根据Metropolis准则,粒子在温度T时趋于平衡的概率为exp(-ΔE/(kT)),其中E为温度T时的内能,ΔE为其改变数,k为Boltzmann常数。Metropolis准则常表示为

Metropolis准则表明,在温度为T时,出现能量差为dE的降温的概率为P(dE),表示为:P(dE) = exp( dE/(kT) )。其中k是一个常数,exp表示自然指数,且dE<0。所以P和T正相关。这条公式就表示:温度越高,出现一次能量差为dE的降温的概率就越大;温度越低,则出现降温的概率就越小。又由于dE总是小于0(因为退火的过程是温度逐渐下降的过程),因此dE/kT < 0 ,所以P(dE)的函数取值范围是(0,1) 。随着温度T的降低,P(dE)会逐渐降低。 我们将一次向较差解的移动看做一次温度跳变过程,我们以概率P(dE)来接受这样的移动。也就是说,在用固体退火模拟组合优化问题,将内能E模拟为目标函数值 f,温度T演化成控制参数 t,即得到解组合优化问题的模拟退火演算法:由初始解 i 和控制参数初值 t 开始,对当前解重复“产生新解→计算目标函数差→接受或丢弃”的迭代,并逐步衰减 t 值,算法终止时的当前解即为所得近似最优解,这是基于蒙特卡罗迭代求解法的一种启发式随机搜索过程。退火过程由冷却进度表(Cooling Schedule)控制,包括控制参数的初值 t 及其衰减因子Δt 、每个 t 值时的迭代次数L和停止条件S。
总结起来就是:
-
若f( Y(i+1) ) <= f( Y(i) ) (即移动后得到更优解),则总是接受该移动;
-
若f( Y(i+1) ) > f( Y(i) ) (即移动后的解比当前解要差),则以一定的概率接受移动,而且这个概率随着时间推移逐渐降低(逐渐降低才能趋向稳定)相当于上图中,从B移向BC之间的小波峰时,每次右移(即接受一个更糟糕值)的概率在逐渐降低。如果这个坡特别长,那么很有可能最终我们并不会翻过这个坡。如果它不太长,这很有可能会翻过它,这取决于衰减 t 值的设定。
关于普通Greedy算法与模拟退火,有一个有趣的比喻:
-
-
普通Greedy算法:兔子朝着比现在低的地方跳去。它找到了不远处的最低的山谷。但是这座山谷不一定最低的。这就是普通Greedy算法,它不能保证局部最优值就是全局最优值。
-
模拟退火:兔子喝醉了。它随机地跳了很长时间。这期间,它可能走向低处,也可能踏入平地。但是,它渐渐清醒了并朝最低的方向跳去。这就是模拟退火。
-
VRP模型
(1)车辆路径规划问题介绍
车辆路径规划问题,经过60年来的研究与发展,研究的目标对象,限制条件等均有所变化,已经从最初的简单车辆安排调度问题转变为复杂的系统问题。最初的车辆路径规划问题可以描述为:有一个起点和若干个客户点,已知各点的地理位置和需求,在满足各种约束的条件下,如何规划最优的路径,使其能服务到每个客户点,最后返回起点。通过施加不同的约束条件,改变优化的目标,可以衍生出不同种类的车辆路径规划问题。同时车辆路径规划问题属于典型的NP-hard问题,其精确算法能求解的规模很小,故启发式算法也就成了研究热点。
(2)VRPTW简介
VRPTW(Vehicle routing problem with time windows)即带时间窗的车辆路径规划问题,其对于每一需求点加入了时间窗的约束,即对于每一个需求点,设定服务开始的最早时间和最晚时间,要求车辆在时间窗内开始服务顾客。
需求点的时窗限制可以分为两种,一种是硬时间窗(Hard Time Window),即要求车辆必须在时间窗内开始服务顾客,早到必须等待,迟到就拒收,另一种是软时间窗(Soft Time Window),不一定要在时间窗内开始服务顾客,但是在时间窗外开始服务必须要惩罚,以惩罚代替等待与拒收是软时间窗和硬时时间窗的最大的区别。
VRPTW的数学模型如下:
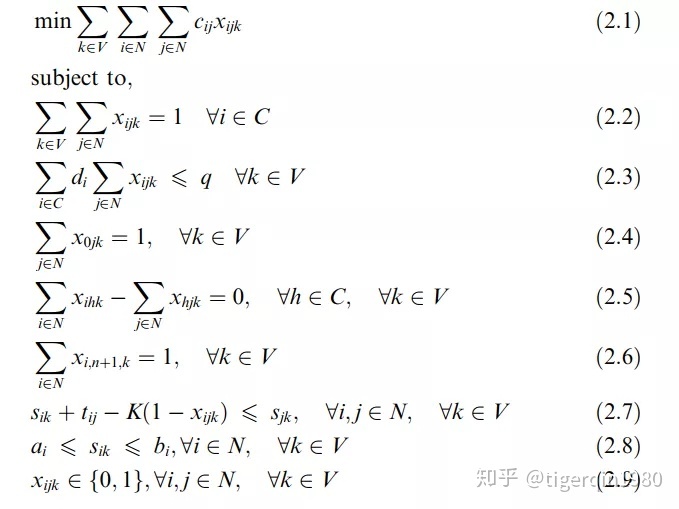
(2.2)保证了每个顾客只被访问1次
(2.3)保证了装载的货物不超过容量
(2.4)(2.5)(2.6)确保了每辆车从depot出发最后回到depot
(2.7)(2.8)确保在时间窗内开始服务
-
tic
clear
clc
%% 用importdata这个函数来读取文件
c101=importdata('c101.txt');
cap=200;
%% 提取数据信息
E=c101(1,5); %配送中心时间窗开始时间
L=c101(1,6); %配送中心时间窗结束时间
vertexs=c101(:,2:3); %所有点的坐标x和y
customer=vertexs(2:end,:); %顾客坐标
cusnum=size(customer,1); %顾客数
v_num=5; %车辆最多使用数目
demands=c101(2:end,4); %需求量
a=c101(2:end,5); %顾客时间窗开始时间[a[i],b[i]]
b=c101(2:end,6); %顾客时间窗结束时间[a[i],b[i]]
s=c101(2:end,7); %客户点的服务时间
h=pdist(vertexs);
dist=squareform(h); %距离矩阵
%% 模拟退火参数
belta=10; %违反的容量约束的惩罚函数系数
gama=100; %违反时间窗约束的惩罚函数系数
MaxOutIter=1000; %外层循环最大迭代次数
MaxInIter=300; %里层循环最大迭代次数
T0=100; %初始温度
alpha=0.99; %冷却因子
pSwap=0.2; %选择交换结构的概率
pReversion=0.5; %选择逆转结构的概率
pInsertion=1-pSwap-pReversion; %选择插入结构的概率
N=cusnum+v_num-1; %解长度=顾客数目+车辆最多使用数目-1
%% 随机构造初始解
currS=randperm(N); %随机构造初始解
[currVC,NV,TD,violate_num,violate_cus]=decode(currS,cusnum,cap,demands,a,b,L,s,dist); %对初始解解码
%求初始配送方案的成本=车辆行驶总成本+belta*违反的容量约束之和+gama*违反时间窗约束之和
end
%记录外层循环每次迭代的全局最优解的总成本
BestCost(outIter)=bestCost;
%显示外层循环每次迭代的信全局最优解的总成本
disp(['第',num2str(outIter),'代全局最优解:'])
[bestVC,bestNV,bestTD,best_vionum,best_viocus]=decode(Sbest,cusnum,cap,demands,a,b,L,s,dist); %对全局最优解解码
disp(['车辆使用数目:',num2str(bestNV),',车辆行驶总距离:',num2str(bestTD),',违反约束路径数目:',num2str(best_vionum),',违反约束顾客数目:',num2str(best_viocus)]);
fprintf('\\n')
%更新当前温度
T=alpha*T;
end
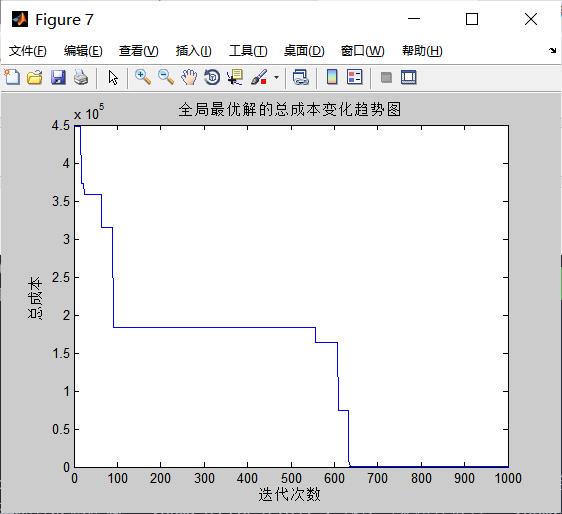
%% 打印外层循环每次迭代的全局最优解的总成本变化趋势图
figure;
plot(BestCost,'LineWidth',1);
title('全局最优解的总成本变化趋势图')
xlabel('迭代次数');
ylabel('总成本');
%% 打印全局最优解路线图
draw_Best(bestVC,vertexs);
toc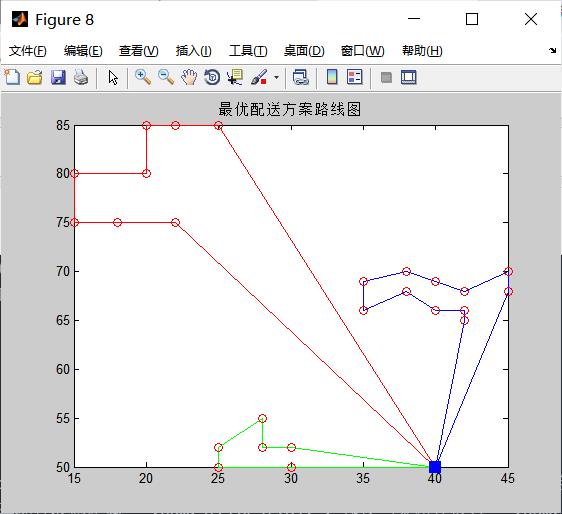
完整代码添加QQ1575304183
以上是关于VRP问题基于模拟退火算法求解带时间窗的车辆路径规划问题VRPTW的主要内容,如果未能解决你的问题,请参考以下文章
VRP问题基于模拟退火算法求解带时间窗的车辆路径规划问题VRPTW
VRP问题基于模拟退火改进遗传算法求解带时间窗含充电站的车辆路径规划问题EVRPTW