大数据技术之MapReduce
Posted ProChick
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据技术之MapReduce相关的知识,希望对你有一定的参考价值。
1.什么是MapReduce?
-
基本概述
- MapReduce将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数:Map和Reduce
- MapReduce编程容易,不需要掌握分布式并行编程细节,也可以很容易把自己的程序运行在分布式系统上,完成海量数据的计算
- MapReduce采用“分而治之”策略,一个存储在分布式文件系统中的大规模数据集,会被切分成许多独立的分片(split),这些分片可以被多个Map任务并行处理
- MapReduce设计的一个理念就是“计算向数据靠拢”,而不是“数据向计算靠拢”,因为,移动数据需要大量的网络传输开销
- MapReduce框架采用了Master/Slave架构,包括一个Master和若干个Slave。Master上运行JobTracker,Slave上运行TaskTracker
-
基本优势
传统并行计算框架 MapReduce 集群架构/容错性 共享式(共享内存/共享存储),容错性差 非共享式,容错性好 硬件/价格/扩展性 刀片服务器、高速网、SAN,价格贵,扩展性差 普通PC机,便宜,扩展性好 编程/学习难度 what-how,难 what,简单 适用场景 实时、细粒度计算、计算密集型 批处理、非实时、数据密集型 -
两大函数
函数 输入 输出 说明 Map <k1,v1> 如: <行号,”a b c”> List(<k2,v2>) 如: <“a”,1> <“b”,1> <“c”,1> 1.将小数据集进一步解析成一批<key,value>对,输入Map函数中进行处理 2.每一个输入的<k1,v1>会输出一批<k2,v2>。<k2,v2>是计算的中间结果 Reduce <k2,List(v2)> 如:<“a”,<1,1,1>> <k3,v3> <“a”,3> 输入的中间结果<k2,List(v2)>中的List(v2)表示是一批属于同一个k2的value
2.体系结构
MapReduce体系结构主要由四个部分组成,分别是:Client、JobTracker、TaskTracker以及Task
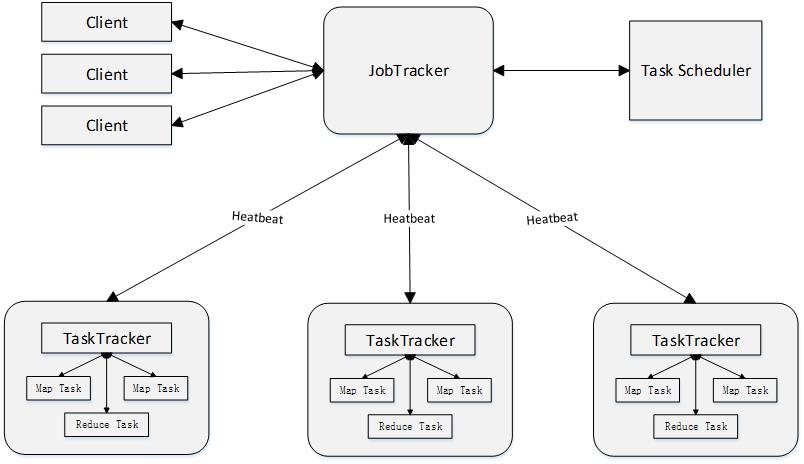
-
Client
- 用户编写的MapReduce程序通过Client提交到JobTracker端
- 用户可通过Client提供的一些接口查看作业运行状态
-
JobTracker
- JobTracker负责资源监控和作业调度
- JobTracker 监控所有TaskTracker与Job的健康状况,一旦发现失败,就将相应的任务转移到其他节点
- JobTracker 会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器(TaskScheduler),而调度器会在资源出现空闲时,选择合适的任务去使用这些资源
-
TaskTracker
- TaskTracker 会周期性地通过“心跳”将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker 发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)
- TaskTracker 使用“slot”等量划分本节点上的资源量(CPU、内存等)。一个Task 获取到一个slot 后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用。slot 分为Map slot 和Reduce slot 两种,分别供MapTask 和Reduce Task 使用
-
Task
Task 分为Map Task 和Reduce Task 两种,均由TaskTracker 启动
3.工作流程
-
工作流程
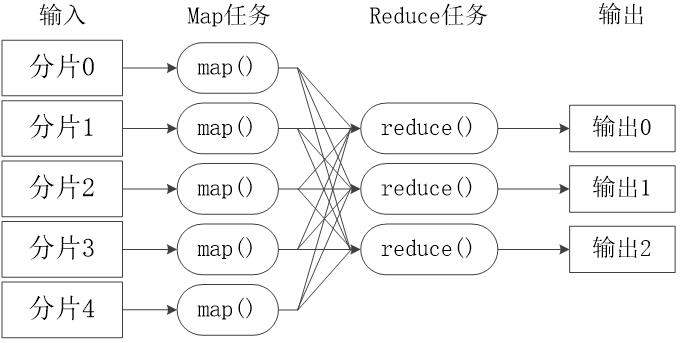
- 不同的Map任务之间不会进行通信
- 不同的Reduce任务之间也不会发生任何信息交换
- 用户不能显式地从一台机器向另一台机器发送消息
- 所有的数据交换都是通过MapReduce框架自身去实现的
-
执行阶段
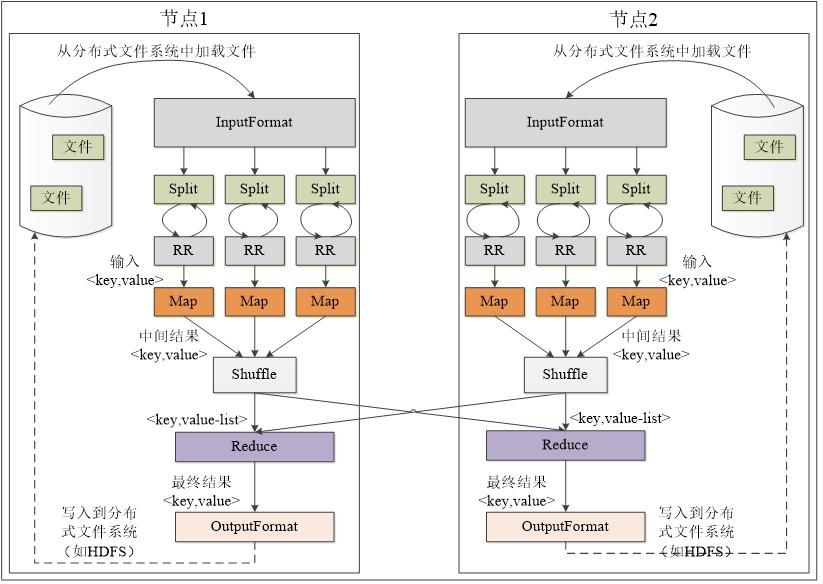
- HDFS 以固定大小的block 为基本单位存储数据,而对于MapReduce 而言,其处理单位是split。split 是一个逻辑概念,它只包含一些元数据信息,比如数据起始位置、数据长度、数据所在节点等。它的划分方法完全由用户自己决定。
- Hadoop为每个split创建一个Map任务,split 的多少决定了Map任务的数目。大多数情况下,理想的分片大小是一个HDFS块
- 最优的Reduce任务个数取决于集群中可用的reduce任务槽(slot)的数目,通常设置比reduce任务槽数目稍微小一些的Reduce任务个数(这样可以预留一些系统资源处理可能发生的错误)
-
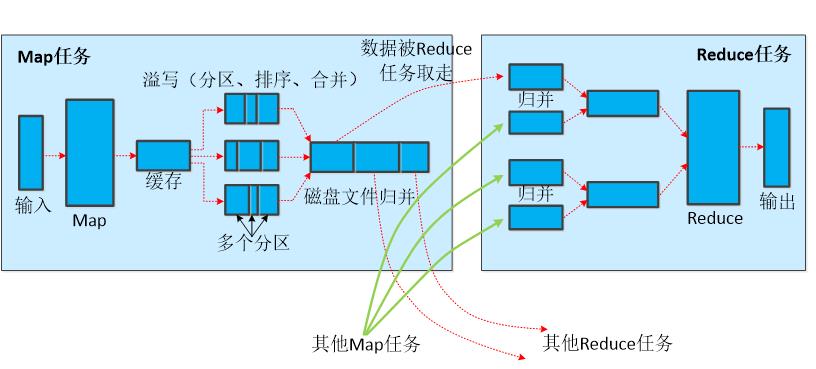
Shuffle过程
-
Map端的Shuffle过程
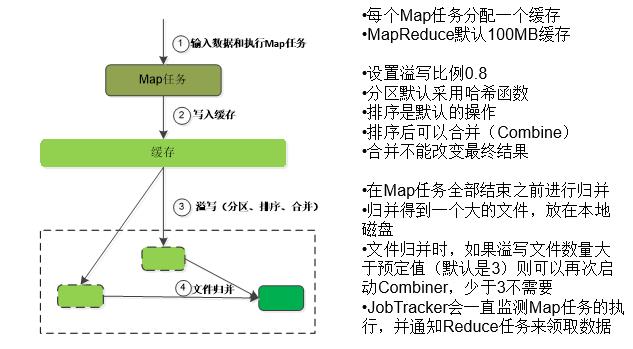
-
Reduce端的Shuffle过程
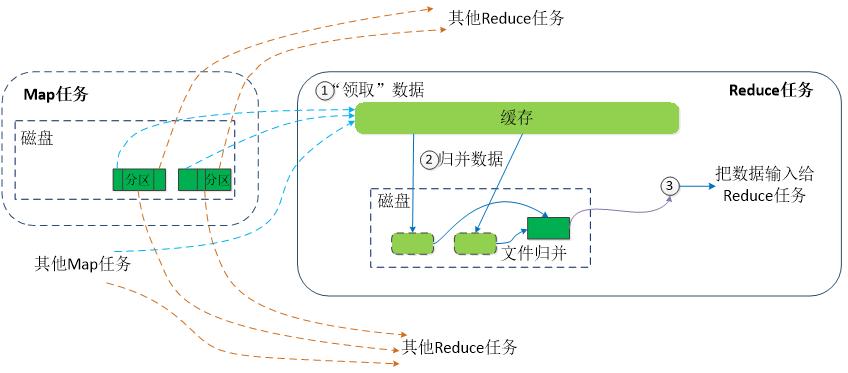
-
执行过程
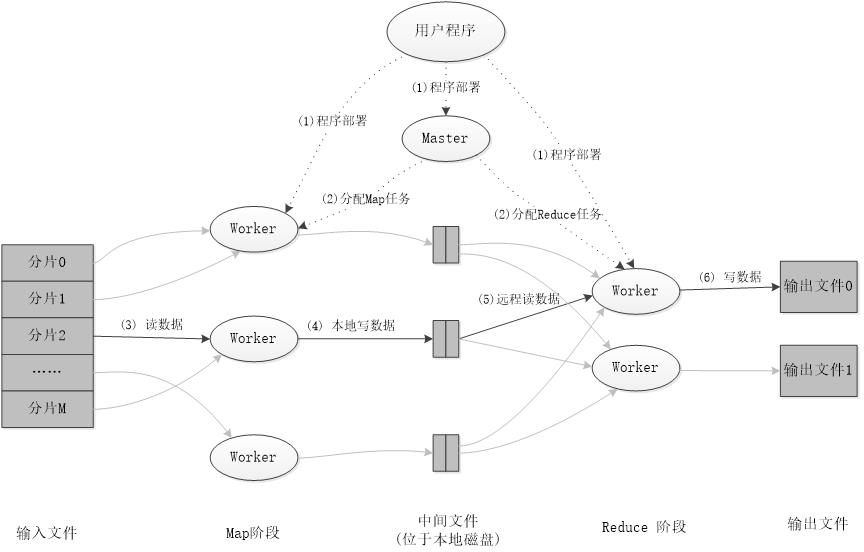
4.实例分析
-
WordCount程序任务
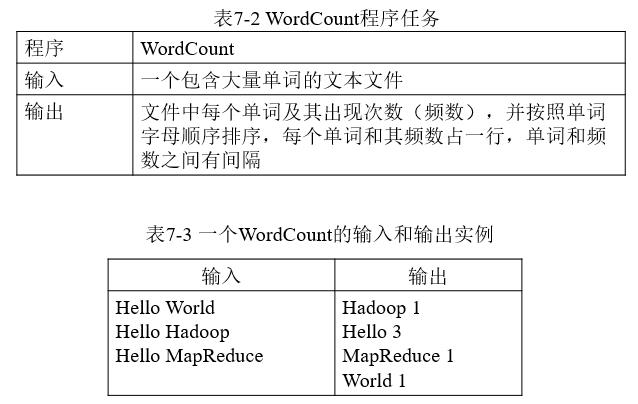
-
WordCount设计思路
- 首先,需要检查WordCount程序任务是否可以采用MapReduce来实现
- 其次,确定MapReduce程序的设计思路
- 最后,确定MapReduce程序的执行过程
-
WordCount执行过程
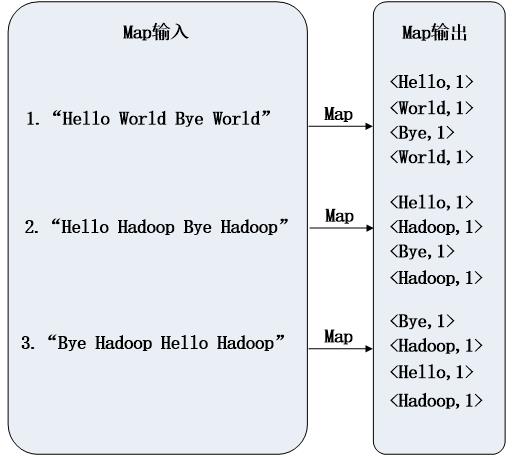
5.具体应用
- 关系代数运算(选择、投影、并、交、差、连接)
- 分组与聚合运算
- 矩阵-向量乘法
- 矩阵乘法
6.编程实践

-
编写Map处理逻辑
public static class MyMapper extends Mapper<Object,Text,Text,IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context) throws IOException,InterruptedException{ StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word,one); } } } -
编写Reduce处理逻辑
public static class MyReducer extends Reducer<Text,IntWritable,Text,IntWritable>{ private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException,InterruptedException{ int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key,result); } } -
编写主方法
public static void main(String[] args) throws Exception{ Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: wordcount <in> <out>"); System.exit(2); } Job job = new Job(conf,"word count"); job.setJarByClass(WordCount.class); job.setMapperClass(MyMapper.class); job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job,new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job,new Path(otherArgs[1])); System.exit(job.waitForCompletion(true)?0:1); }
以上是关于大数据技术之MapReduce的主要内容,如果未能解决你的问题,请参考以下文章