Spark---宽窄依赖
Posted Shall潇
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark---宽窄依赖相关的知识,希望对你有一定的参考价值。
RDD论文:第11页
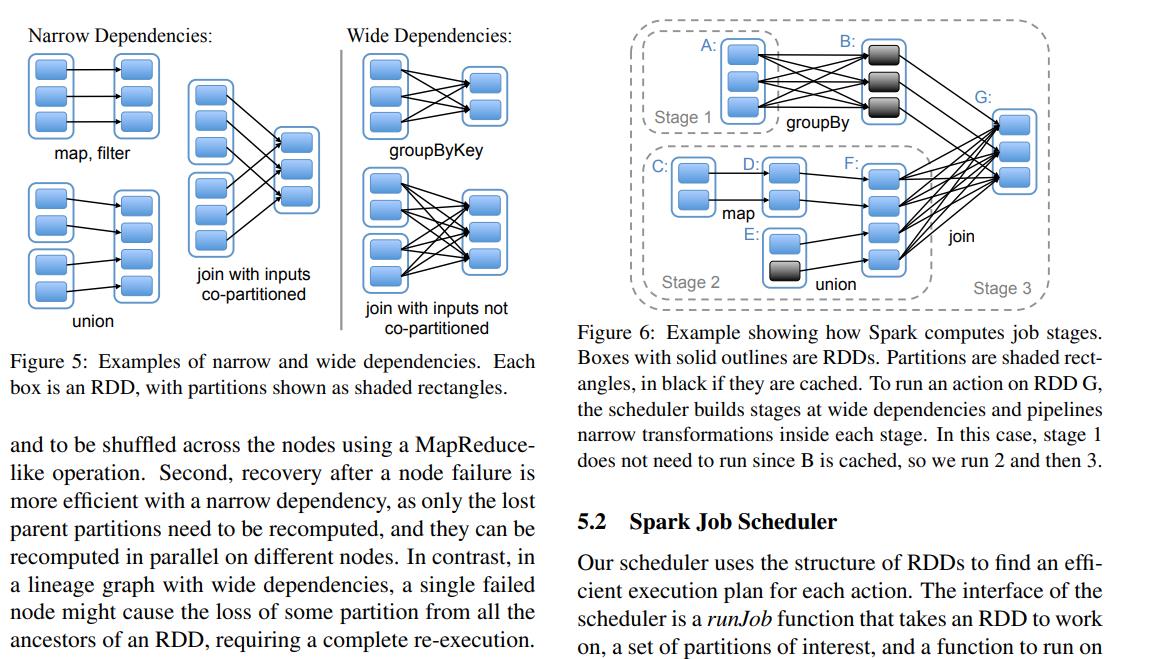
原文摘录
This distinction is useful for two reasons. First, narrow dependencies allow for pipelined execution on one cluster node, which can compute all the parent partitions. For example, one can apply a map followed by a filter on an element-by-element basis. In contrast, wide dependencies require data from all parent partitions to be availableand to be shuffled across the nodes using a MapReducelike operation. Second, recovery after a node failure is more efficient with a narrow dependency, as only the lost parent partitions need to be recomputed, and they can be recomputed in parallel on different nodes. In contrast, in a lineage graph with wide dependencies, a single failed node might cause the loss of some partition from all the ancestors of an RDD, requiring a complete re-execution. Thanks to our choice of common interface for RDDs, we could implement most transformations in Spark in less than 20 lines of code. We sketch some examples in §5.1. We then discuss how we use the RDD interface for scheduling (§5.2). Lastly, we discuss when it makes sense to checkpoint data in RDD-based programs (§5.3).
简单总结如下:
| 依赖关系 | 父RDD—>子RDD |
|---|---|
| 宽依赖 | 1 —> N |
| 窄依赖 | 1 —> 1,N —> 1 |
有shuffle过程就是宽依赖
DAG(有向无环图)
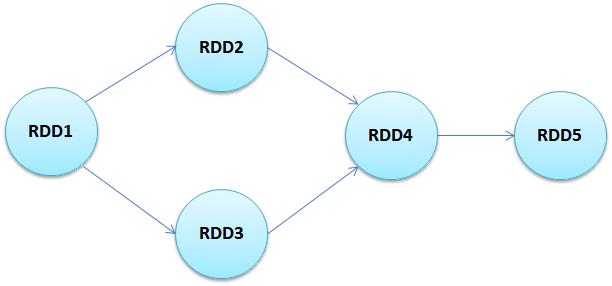
RDD1->RDD2,RDD1->RDD3属于宽依赖
RDD2,RDD3->RDD4属于窄依赖
RDD4->RDD5属于窄依赖
RDD中常见算子分类
宽依赖:groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition、distinct(很多文章说distinct是窄依赖,是不对的)
distinct源码
/**
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
}
【注意:都是用reduceByKey了,还窄依赖?】
窄依赖:map,fiter,union,flatMap
join 操作有两种情况,如果 join 操作中使用的每个 Partition 仅仅和固定个 Partition 进行 join,则该 join 操作是窄依赖,其他情况下的 join 操作是宽依赖。
Stage划分规则:从后往前,遇到宽依赖切割为新的Stage
以上是关于Spark---宽窄依赖的主要内容,如果未能解决你的问题,请参考以下文章