Spark宽窄依赖
Posted 常生果
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark宽窄依赖相关的知识,希望对你有一定的参考价值。
Spark中RDD的高效与DAG图有着莫大的关系,在DAG调度中需要对计算过程划分stage,而划分依据就是RDD之间的依赖关系。针对不同的转换函数,RDD之间的依赖关系分类窄依赖(narrow dependency)和宽依赖(wide dependency, 也称 shuffle dependency).
宽依赖与窄依赖
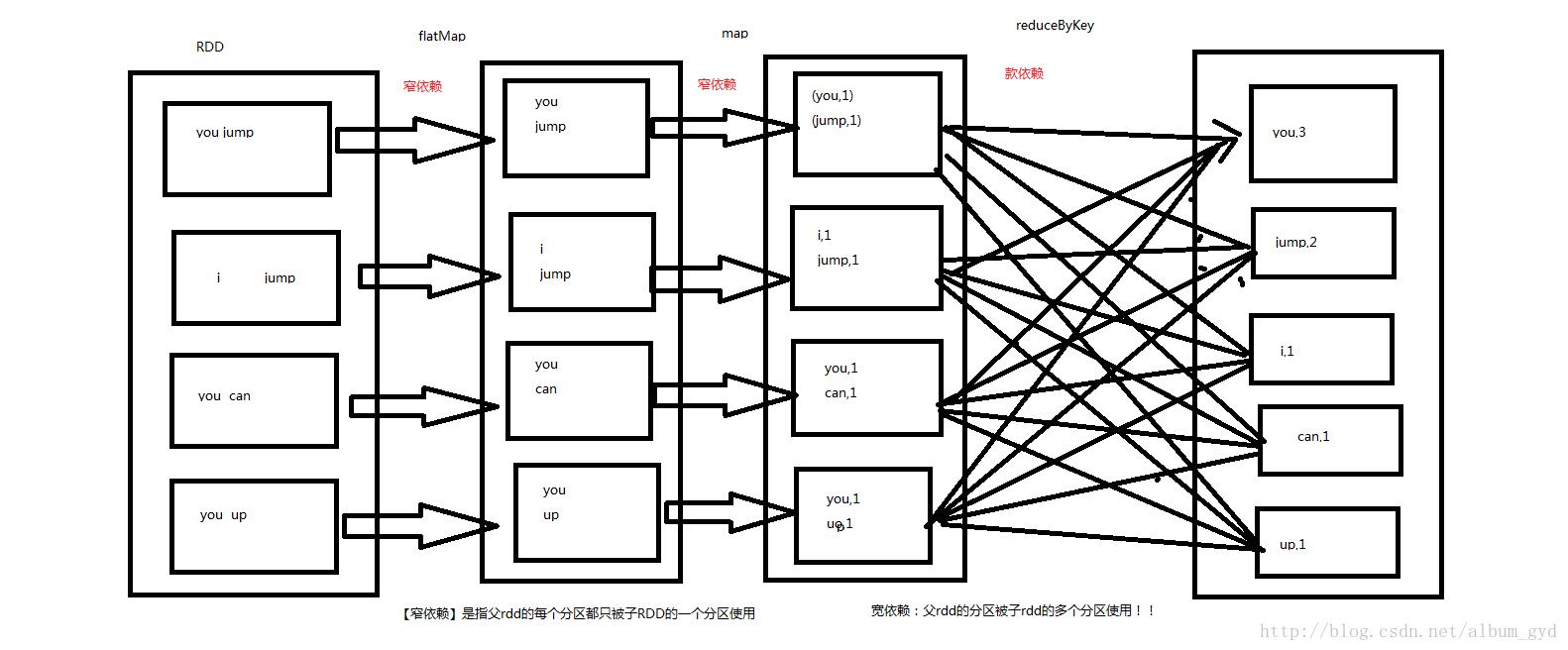
- 窄依赖是指父RDD的每个分区只被子RDD的一个分区所使用,子RDD分区通常对应常数个父RDD分区(O(1),与数据规模无关)
- 相应的,宽依赖是指父RDD的每个分区都可能被多个子RDD分区所使用,子RDD分区通常对应所有的父RDD分区(O(n),与数据规模有关)
宽依赖和窄依赖如下图所示:

宽依赖也叫shuffle dependencies,数据对应不同的分区。
相比于宽依赖,窄依赖对优化很有利 ,主要基于以下两点:
-
宽依赖往往对应着shuffle操作,需要在运行过程中将同一个父RDD的分区传入到不同的子RDD分区中,中间可能涉及多个节点之间的数据传输;而窄依赖的每个父RDD的分区只会传入到一个子RDD分区中,通常可以在一个节点内完成转换。
-
当RDD分区丢失时(某个节点故障),spark会对数据进行重算。
- 对于窄依赖,由于父RDD的一个分区只对应一个子RDD分区,这样只需要重算和子RDD分区对应的父RDD分区即可,所以这个重算对数据的利用率是100%的;
- 对于宽依赖,重算的父RDD分区对应多个子RDD分区,这样实际上父RDD 中只有一部分的数据是被用于恢复这个丢失的子RDD分区的,另一部分对应子RDD的其它未丢失分区,这就造成了多余的计算;更一般的,宽依赖中子RDD分区通常来自多个父RDD分区,极端情况下,所有的父RDD分区都要进行重新计算。
-
如下图所示,b1分区丢失,则需要重新计算a1,a2和a3,这就产生了冗余计算(a1,a2,a3中对应b2的数据)。

依赖函数:
窄依赖的函数有:map, filter, union, join(父RDD是hash-partitioned ), mapPartitions, mapValues
宽依赖的函数有:groupByKey, join(父RDD不是hash-partitioned ), partitionBy
注意:join操作有两种情况:如果两个RDD在进行join操作时,一个RDD的partition仅仅和另一个RDD中已知个数的Partition进行join,那么这种类型的join操作就是窄依赖,例如图1中左半部分的join操作(join with inputsco-partitioned);其它情况的join操作就是宽依赖,例如图1中右半部分的join操作(join with inputsnot co-partitioned),由于是需要父RDD的所有partition进行join的转换,这就涉及到了shuffle,因此这种类型的join操作也是宽依赖。

一个RDD可以包含多个分区,每个分区就是一个dataset片段。
RDD抽象出来的东西里面实际的数据,是分散在各个节点上面的,RDD可分区,分区的个数是我们可以指定的。但是默认情况下,一个hdfs块就是一个分区。且大部分操作在内存里面,少部分在磁盘,例如reduceByKey操作,就需要放在磁盘,为了保证数据的安全性,然后再从磁盘被读取出到内存上面。容错性好。
为什么会有窄依赖?
1.前面已经说过了stage划分的一个很重要的原因就是有没有涉及到shuffle,如果没涉及到的被划分到一个stage里面。
2.没有涉及shuffle的任务直接运行就可以,这个也就是长提到的pipeline。这种面向的就是窄依赖。
√ 每个分区里的数据都被加载到机器的内存里,我们逐一的调用 map, filter, map 函数到这些分区里,Job 就很好的完成。 √ 更重要的是,由于数据没有转移到别的机器,我们避免了 Network IO 或者 Disk IO. 唯一的任务就是把 map / filter 的运行环境搬到这些机器上运行,这对现代计算机来说,overhead 几乎可以忽略不计。 √ 这种把多个操作合并到一起,在数据上一口气运行的方法在 Spark 里叫 pipeline (其实 pipeline 被广泛应用的很多领域,比如 CPU)。这时候不同就出现了:只有 narrow transformation 才可以进行 pipleline 操作。对于 wide transformation, RDD 转换需要很多分区运算,包括数据在机器间搬动,所以失去了 pipeline 的前提。 √ 总结起来一句话:数据和算是否在一起,计算的性能是不一样的,为了区分,就有了宽依赖和窄依赖。
3.一提到shuffle如果之前对mapreduce有过了解的人都知道,这个对分布式影响巨大,spark也是一步步演变过来的,现在可以说spark2.x以上的shuffle可以认为和经典的mapreduce的shuffle一样了,到现在可以说spark完全比mp有优势了。这之前,在一些场景下spark还是比不过mp的。(这个地方会写一个专门的文章来阐述变化过程)。
以上是关于Spark宽窄依赖的主要内容,如果未能解决你的问题,请参考以下文章